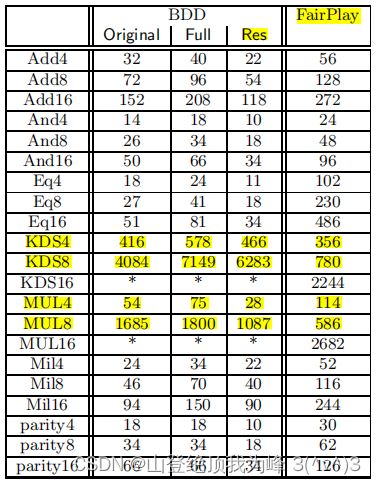
混淆 OBDD
参考文献:
- OBDD 旧版论文:Bryant R E. Graph-based algorithms for boolean function manipulation[J]. Computers, IEEE Transactions on, 1986, 100(8): 677-691.
- OBDD 新版论文:Bryant R E. Graph-Based Algorithms for Boolean Function Manipulation 12[J].
- 混淆 OBDD:Kruger L, Jha S, Goh E J, et al. Secure function evaluation with ordered binary decision diagrams[C]//Proceedings of the 13th ACM conference on Computer and communications security. 2006: 410-420.
- 2PC 综述(含电路转换):Kolesnikov V, Sadeghi A R, Schneider T. A systematic approach to practically efficient general two-party secure function evaluation protocols and their modular design[J]. Journal of Computer Security, 2013, 21(2): 283-315.
文章目录
- OBDD
-
- 图结构
- Traverse
- Reduction
- Restriction
- Apply
- Composition
- Satisfy
- 改进
- 混淆OBDD
-
- 有序输入
- 任意输入
OBDD
1986年,Bryant 提出了布尔函数的表示方法 ordered binary decision diagrams (OBDDs)。相较于布尔电路,OBDD 更加紧凑,很多常见类型(除了整数乘法,指数级)的布尔函数对应的 OBDD 的节点数量更少。并且,OBDD 由于固定了变量顺序,因此它可以有效解决 布尔函数可满足性问题 和 图同构问题。
图结构
布尔函数 f ( x 1 , ⋯ , x n ) f(x_1,\cdots,x_n) f(x1,⋯,xn)的函数图(function graph)或者说 OBDD,它是一个有根节点的有向无环图(rooted, directed, acyclic graph) G G G,其节点集合 V V V包含两类节点,
-
非终端节点(nonterminal vertex):包含属性 i n d e x ( v ) ∈ { 1 , ⋯ , n } index(v) \in \{1,\cdots,n\} index(v)∈{1,⋯,n},还有两个指针指向子节点 l o w ( v ) , h i g h ( v ) ∈ V low(v),high(v) \in V low(v),high(v)∈V,并且
i n d e x ( v ) < i n d e x ( l o w ( v ) ) , i n d e x ( v ) < i n d e x ( h i g h ( v ) ) index(v)
从根节点到终端节点的路径上,index 是严格递增的。 -
终端节点(terminal vertex):包含属性 v a l u e ( v ) ∈ { 0 , 1 } value(v) \in \{0,1\} value(v)∈{0,1},并设置 i n d e x ( v ) = n + 1 index(v)=n+1 index(v)=n+1
OBDD 的构建如下:

明显,
- 任给一组参数 ( a 1 , ⋯ , a n ) ∈ { 0 , 1 } n (a_1,\cdots,a_n) \in \{0,1\}^n (a1,⋯,an)∈{0,1}n,在 G G G中都存在唯一的路径,从根到达终端。
- 图 G G G的每个节点都至少落在一条路径上。
下面是 OBDD 的图示(右边是奇偶判定函数):
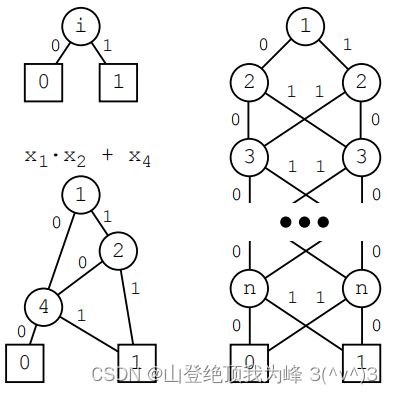
OBDD 对变量的顺序十分敏感。下图显示了这一点:
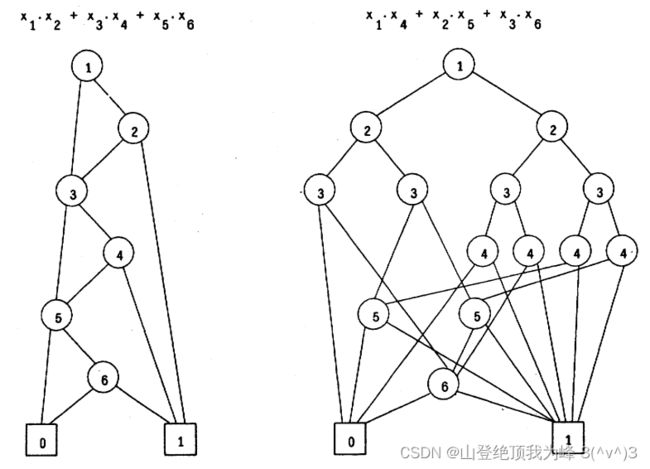
实际上,对于 x 1 x 2 + ⋯ , x 2 n − 1 x 2 n x_1x_2+\cdots,x_{2n-1}x_{2n} x1x2+⋯,x2n−1x2n只要 2 n + 2 2n+2 2n+2个点,但对于 x 1 x n + 1 + ⋯ + x n x 2 n x_1x_{n+1}+\cdots+x_nx_{2n} x1xn+1+⋯+xnx2n需要 2 n + 1 2^{n+1} 2n+1个点。因为 OBDD 中的计算中间值(intermediate information)并不是存储在内存中的,而是被编码为了所有可能的分支目标(this information is encoded in the set of possible branch destinations)。对于奇偶判定函数,中间值是 1 1 1比特,每层 O ( 2 ) O(2) O(2)个点;对于整数乘法,中间值是 n n n比特,每层 O ( 2 n ) O(2^n) O(2n)个点。
Traverse
节点类型为:

遍历 OBDD 的算法:

每个点都访问恰好一次,复杂度为 O ( ∣ G ∣ ) O(|G|) O(∣G∣)
Reduction
给定布尔函数 f ( x 1 , ⋯ , x n ) f(x_1,\cdots,x_n) f(x1,⋯,xn)的 OBDD,那么 dependency set 定义为:
I f = { i : f ∣ x i = 0 ≠ f ∣ x i = 1 } I_f = \{ i: f|_{x_i=0} \neq f|_{x_i=1} \} If={i:f∣xi=0=f∣xi=1}
否则,如果 f ∣ x i = 0 = f ∣ x i = 1 f|_{x_i=0} = f|_{x_i=1} f∣xi=0=f∣xi=1,那么 f f f就与 x i x_i xi不相关。
给定两张 OBDD G , G ′ G,G' G,G′,说它们是同构的(isomorphic),如果存在点击间的双射 σ \sigma σ,使得:如果是终端,那么 v a l u e ( v ) = v a l u e ( σ ( v ) ) value(v)=value(\sigma(v)) value(v)=value(σ(v));如果是非终端,那么 i n d e x ( v ) = i n d e x ( σ ( v ) ) index(v)=index(\sigma(v)) index(v)=index(σ(v))且 σ ( l o w ( v ) ) = l o w ( σ ( v ) ) \sigma(low(v))=low(\sigma(v)) σ(low(v))=low(σ(v))且 σ ( h i g h ( v ) ) = h i g h ( σ ( v ) ) \sigma(high(v))=high(\sigma(v)) σ(high(v))=high(σ(v))。明显的,如果图同构,那么任意子图同构。
约简图(reduce graph):OBDD G G G 不包含
- 一个节点 v v v,使得子节点 l o w ( v ) = h i g h ( v ) low(v)=high(v) low(v)=high(v)
- 两个节点 v , v ′ v,v' v,v′,使得子图 G v ≅ G v ′ G_v \cong G_{v'} Gv≅Gv′
明显的,如果图是约简的,那么任意子图都是约简的。
canonical form:任意布尔函数都存在唯一的(同构意义下)最少节点的约简图。并且,有最少节点的图一定是约简的(否则,总可以删除一些点)。
约简算法:

上述算法的复杂度为 O ( ∣ G ∣ ⋅ l o g ( ∣ G ∣ ) ) O(|G|\cdot log(|G|)) O(∣G∣⋅log(∣G∣))
Restriction
给定布尔函数 f ( x 1 , ⋯ , x n ) f(x_1,\cdots,x_n) f(x1,⋯,xn)的 OBDD,构造 a restriction of f:
f ∣ x i = b ( x 1 , ⋯ , x n ) = f ( x 1 , ⋯ , x i − 1 , b , x i + 1 , ⋯ , x n ) f|_{x_i=b}(x_1,\cdots,x_n) = f(x_1,\cdots,x_{i-1},b,x_{i+1},\cdots,x_n) f∣xi=b(x1,⋯,xn)=f(x1,⋯,xi−1,b,xi+1,⋯,xn)
算法如下:
- 输入函数 f f f的OBDD G G G,根节点是 v v v
- 使用 Traverse 算法周游 OBDD,一旦遇到 i n d e x ( v ) = i index(v)=i index(v)=i,那么
- 如果 b = 0 b=0 b=0,设置 h i g h ( v ) ← l o w ( v ) high(v) \leftarrow low(v) high(v)←low(v), l o w ( v ) low(v) low(v)不变
- 如果 b = 1 b=1 b=1,设置 l o w ( v ) ← h i g h ( v ) low(v) \leftarrow high(v) low(v)←high(v), h i g h ( v ) high(v) high(v)不变
- 运行 Reduction 算法,输出约简图的根 v v v
上述算法的复杂度为 O ( ∣ G ∣ ⋅ l o g ( ∣ G ∣ ) ) O(|G|\cdot log(|G|)) O(∣G∣⋅log(∣G∣))
Apply
给定布尔函数 f 1 , f 2 f_1,f_2 f1,f2的 OBDD,构造关于布尔运算 ⊙ \odot ⊙的函数的 OBDD:
( f 1 ⊙ f 2 ) ( x 1 , ⋯ , x n ) = f 1 ( x 1 , ⋯ , x n ) ⊙ f 2 ( x 1 , ⋯ , x n ) (f_1 \odot f_2)(x_1,\cdots,x_n) = f_1(x_1,\cdots,x_n) \odot f_2(x_1,\cdots,x_n) (f1⊙f2)(x1,⋯,xn)=f1(x1,⋯,xn)⊙f2(x1,⋯,xn)
利用 Shannon expansion,写作
f 1 ⊙ f 2 = x ˉ i ⋅ ( f 1 ∣ x i = 0 ⊙ f 2 ∣ x i = 0 ) + x i ⋅ ( f 1 ∣ x i = 1 ⊙ f 2 ∣ x i = 1 ) f_1 \odot f_2 = \bar x_i \cdot (f_1|_{x_i=0} \odot f_2|_{x_i=0}) + x_i \cdot (f_1|_{x_i=1} \odot f_2|_{x_i=1}) f1⊙f2=xˉi⋅(f1∣xi=0⊙f2∣xi=0)+xi⋅(f1∣xi=1⊙f2∣xi=1)
令 f 1 ⊙ f 2 f_1 \odot f_2 f1⊙f2的 OBDD 的根为 u u u,那么上式的右边就是
l o w ( u ) = O B D D ( f 1 ∣ x i = 0 ⊙ f 2 ∣ x i = 0 ) low(u) = OBDD(f_1|_{x_i=0} \odot f_2|_{x_i=0}) low(u)=OBDD(f1∣xi=0⊙f2∣xi=0)
h i g h ( u ) = O B D D ( f 1 ∣ x i = 1 ⊙ f 2 ∣ x i = 1 ) high(u) = OBDD(f_1|_{x_i=1} \odot f_2|_{x_i=1}) high(u)=OBDD(f1∣xi=1⊙f2∣xi=1)
令 f 1 f_1 f1的 OBDD 的根为 v 1 v_1 v1,令 f 2 f_2 f2的 OBDD 的根为 v 2 v_2 v2,那么
l o w ( v 1 ) = O B D D ( f 1 ∣ x i = 0 ) , h i g h ( v 1 ) = O B D D ( f 1 ∣ x i = 1 ) low(v_1) = OBDD(f_1|_{x_i=0}),\, high(v_1) = OBDD(f_1|_{x_i=1}) low(v1)=OBDD(f1∣xi=0),high(v1)=OBDD(f1∣xi=1)
l o w ( v 2 ) = O B D D ( f 2 ∣ x i = 0 ) , h i g h ( v 2 ) = O B D D ( f 2 ∣ x i = 1 ) low(v_2) = OBDD(f_2|_{x_i=0}),\, high(v_2) = OBDD(f_2|_{x_i=1}) low(v2)=OBDD(f2∣xi=0),high(v2)=OBDD(f2∣xi=1)
考虑如下情形:
-
v 1 , v 2 v_1,v_2 v1,v2都是终端,那么创建终端 i n d e x ( u ) = n + 1 index(u)=n+1 index(u)=n+1,且
v a l u e ( u ) = v a l u e ( v 1 ) ⊙ v a l u e ( v 2 ) value(u) = value(v_1) \odot value(v_2) value(u)=value(v1)⊙value(v2) -
v 1 , v 2 v_1,v_2 v1,v2都不是终端,且 i n d e x ( v 1 ) = i n d e x ( v 2 ) = i index(v_1)=index(v_2)=i index(v1)=index(v2)=i,那么创建非终端 i n d e x ( u ) = i index(u)=i index(u)=i,再利用 Shannon expansion,
- 迭代计算两个子图 l o w ( v 1 ) low(v_1) low(v1)和 l o w ( v 2 ) low(v_2) low(v2)的 ⊙ \odot ⊙运算结果,它以 l o w ( u ) low(u) low(u)为根
- 迭代计算两个子图 h i g h ( v 1 ) high(v_1) high(v1)和 h i g h ( v 2 ) high(v_2) high(v2)的 ⊙ \odot ⊙运算结果,它以 h i g h ( u ) high(u) high(u)为根
-
v 1 v_1 v1不是终端,且 i n d e x ( v 2 ) > i n d e x ( v 1 ) index(v_2)>index(v_1) index(v2)>index(v1),那么明显 x i ∉ I f 2 x_i \notin I_{f_2} xi∈/If2,
f 2 ∣ x i = 0 = f 2 ∣ x i = 1 = f 2 f_2|_{x_i=0} = f_2|_{x_i=1} = f_2 f2∣xi=0=f2∣xi=1=f2
即 v 2 = l o w ( v 2 ) = h i g h ( v 2 ) v_2 = low(v_2) = high(v_2) v2=low(v2)=high(v2),因此执行- 迭代计算两个子图 l o w ( v 1 ) low(v_1) low(v1)和 v 2 v_2 v2的 ⊙ \odot ⊙运算结果,它以 l o w ( u ) low(u) low(u)为根
- 迭代计算两个子图 h i g h ( v 1 ) high(v_1) high(v1)和 v 2 v_2 v2的 ⊙ \odot ⊙运算结果,它以 h i g h ( u ) high(u) high(u)为根
-
反过来, v 2 v_2 v2不是终端,且 i n d e x ( v 1 ) > i n d e x ( v 2 ) index(v_1)>index(v_2) index(v1)>index(v2),过程类似
然而,上述算法是指数级的,因为每遇到非终端节点都要迭代。其实这些迭代有大量的冗余,使用打表法,记录已经迭代过的点对 ( v 1 , v 2 , u ) (v_1,v_2,u) (v1,v2,u)。每次迭代之前 check 表格,如果没有那么才继续执行迭代。这将复杂度降低到了 O ( ∣ G 1 ∣ ⋅ ∣ G 2 ∣ ) O(|G_1| \cdot |G_2|) O(∣G1∣⋅∣G2∣)
另外,对于布尔运算,有时其中一个变量的值就可以完全确定最终结果。这个值叫做 “controlling” value,例如 0 0 0之于 A N D AND AND, 1 1 1之于 O R OR OR
算法如下:

其中记录迭代信息的表格 T T T是稀疏的,可以用Hash表来取代,减小空间开销。
Composition
给定布尔函数 f ( x 1 , ⋯ , x n ) f(x_1,\cdots,x_n) f(x1,⋯,xn)的 OBDD,构造 a composition of f and g:
f ∣ x i = g ( x 1 , ⋯ , x n ) = f ( x 1 , ⋯ , x i − 1 , g ( x 1 , ⋯ , x n ) , x i + 1 , ⋯ , x n ) f|_{x_i=g}(x_1,\cdots,x_n) = f(x_1,\cdots,x_{i-1},g(x_1,\cdots,x_n),x_{i+1},\cdots,x_n) f∣xi=g(x1,⋯,xn)=f(x1,⋯,xi−1,g(x1,⋯,xn),xi+1,⋯,xn)
利用 Shannon expansion,写作
f ∣ x i = g = g ⋅ f ∣ x i = 1 + g ˉ ⋅ f ∣ x i = 0 f|_{x_i=g} = g \cdot f|_{x_i=1} + \bar g \cdot f|_{x_i=0} f∣xi=g=g⋅f∣xi=1+gˉ⋅f∣xi=0
由于 ⋅ \cdot ⋅和 + + +都是布尔运算,因此可以利用 2 2 2次 Restriction 算法计算 f ∣ x i = 0 , f ∣ x i = 1 f|_{x_i=0},f|_{x_i=1} f∣xi=0,f∣xi=1的 OBDD,然后将 g g g的终端 value 翻转得到 g ˉ \bar g gˉ,再利用 3 3 3次 Apply 算法分别计算 g ⋅ f ∣ x i = 1 g \cdot f|_{x_i=1} g⋅f∣xi=1, g ˉ ⋅ f ∣ x i = 0 \bar g \cdot f|_{x_i=0} gˉ⋅f∣xi=0和 ( g ⋅ f ∣ x i = 1 ) + ( g ˉ ⋅ f ∣ x i = 0 ) (g \cdot f|_{x_i=1}) + (\bar g \cdot f|_{x_i=0}) (g⋅f∣xi=1)+(gˉ⋅f∣xi=0)
然而,上述算法的复杂度为 O ( ∣ G 1 ∣ 2 ⋅ ∣ G 2 ∣ 2 ) O(|G_1|^2 \cdot |G_2|^2) O(∣G1∣2⋅∣G2∣2)。实际上,可以不再使用 3 3 3次二元运算,而是使用 1 1 1次三元运算 if-then-else:
I T E ( a , b , c ) = a b + a ˉ c ITE(a,b,c) = ab+\bar ac ITE(a,b,c)=ab+aˉc
那么可以将复杂度降低为 O ( ∣ G 1 ∣ 2 ⋅ ∣ G 2 ∣ ) O(|G_1|^2 \cdot |G_2|) O(∣G1∣2⋅∣G2∣)。在实际执行中,大多数函数组合在 O ( ∣ G 1 ∣ ⋅ ∣ G 2 ∣ ) O(|G_1| \cdot |G_2|) O(∣G1∣⋅∣G2∣)时间内就可完成。
算法如下:

Satisfy
给定布尔函数 f ( x 1 , ⋯ , x n ) f(x_1,\cdots,x_n) f(x1,⋯,xn)的 OBDD,寻找 satisfying set:
S f = { ( x 1 , ⋯ , x n ) : f ( x 1 , ⋯ , x n ) = 1 } S_f = \{(x_1,\cdots,x_n) : f(x_1,\cdots,x_n)=1 \} Sf={(x1,⋯,xn):f(x1,⋯,xn)=1}
为了找到一个 S f S_f Sf中元素,可以在 OBDD 中按照深度优先搜索来依次尝试每个 x ∈ { 0 , 1 } n x \in \{0,1\}^n x∈{0,1}n,非约简图中在最坏情况下需要 O ( 2 n ) O(2^n) O(2n)次回溯。
但是在约简图中,第 n n n层的节点 v v v一定有 l o w ( v ) ≠ h i g h ( v ) low(v) \neq high(v) low(v)=high(v)分别指向 0 0 0终端和 1 1 1终端。所以:约简图中的任意非终端,都一定可达 1 1 1终端。那么只要从 OBDD 的根节点开始,按照深度优先遍历,然后至多回溯一次,就可以在 O ( n ) O(n) O(n)时间内找到一个 S f S_f Sf中元素。算法如下:

另外,如果需要找到全部的 S f S_f Sf,那么对于 i n d e x ( v ) = i index(v)=i index(v)=i的节点,计算如下集合:
S f v = { ( a 1 , ⋯ , a i − 1 , x i , ⋯ , x n ) : f v ( a 1 , ⋯ , a i − 1 , x i , ⋯ , x n ) = 1 } S_{f_v} = \{(a_1,\cdots,a_{i-1},x_i,\cdots,x_n): f_v(a_1,\cdots,a_{i-1},x_i,\cdots,x_n) = 1\} Sfv={(a1,⋯,ai−1,xi,⋯,xn):fv(a1,⋯,ai−1,xi,⋯,xn)=1}
迭代算法如下:

同样因为约简图的非终端都会到达 1 1 1终端,因此至少有一半的迭代将会返回一些解。复杂度为 O ( n ⋅ ∣ S f ∣ ) O(n \cdot |S_f|) O(n⋅∣Sf∣)
改进
- 自适应确定变量顺序:OBDD 的规模对变量的顺序很敏感。找到最优的顺序使得 OBDD 最小,这是 coNPC 问题。但是,如果某人熟悉组合设计,那么可以利用知识来确定一个合适的顺序。另外,除了某些类型的函数(包括整数乘法),大多数函数都存在一些很小的 OBDD 表示。可以用一系列的启发式算法有效地找到一组排列顺序,使得 OBDD 的规模合理的小。算法有: Rudell’s sifting algorithm, the window permutation algorithm, genetic algorithms(遗传算法), or algorithms based on simulated annealing(模拟退火算法).
- 将布尔函数的值域从二元域扩展到任意域: f ( x 1 , ⋯ , x n ) : { 0 , 1 } n → S ⊂ N f(x_1,\cdots,x_n): \{0,1\}^n \to S \subset \mathbb N f(x1,⋯,xn):{0,1}n→S⊂N,其中 S S S是有限集合。那么只需设置 ∣ S ∣ |S| ∣S∣个的终端节点。而 i n d e x ( v ) ≤ n index(v) \le n index(v)≤n的非终端节点依然是只有两个子节点。
混淆OBDD
与 Yao’s GC 类似,不再是布尔电路的每个门计算 4 4 4条目的混淆表,而是 OBDD 的每个非终端节点计算 2 2 2个指针的混淆表。
为了防止约简的 OBDD 的跳级(skipping)使得路径的长度不同而泄露信息,我们需要对 OBDD 填充一些虚拟节点(dummy vertex),保证每条路径都一样长。另外,可以额外再添加若干,让 OBDD 的路径延长到随机长度,进一步消除路径长度的信息。
对于布尔函数 f ( x 1 , ⋯ , x n ) f(x_1,\cdots,x_n) f(x1,⋯,xn)对应的 OBDD G G G,我们为 G G G的每个非终端节点 v v v分配一个对称密钥 s v s_v sv,同时利用 OT 协议为每个变量分配随机的密钥:
- 如果 x i = 0 x_i=0 xi=0,那么混淆值为 s i 0 s_i^0 si0
- 如果 x i = 1 x_i=1 xi=1,那么混淆值为 s i 1 s_i^1 si1
使用不可捉摸范围的对称加密,对于节点 v v v,计算混淆表
E n c ( s v ⊕ s i 0 , l a b e l ( l o w ( v ) ) ∥ s l o w ( v ) ) Enc(s_v \oplus s_i^0,label(low(v))\| s_{low(v)}) Enc(sv⊕si0,label(low(v))∥slow(v))
E n c ( s v ⊕ s i 1 , l a b e l ( h i g h ( v ) ) ∥ s h i g h ( v ) ) Enc(s_v \oplus s_i^1,label(high(v))\| s_{high(v)}) Enc(sv⊕si1,label(high(v))∥shigh(v))
其中 l a b e l ( ⋅ ) ∈ { 0 , 1 } label(\cdot) \in \{0,1\} label(⋅)∈{0,1}是随机位置。这可以用 P&P 技术来改进。
易知,仅当计算混淆 OBDD 时到达了节点 v v v,才能够获得对应的密钥 s v s_v sv
有序输入
Alice 和 Bob 要协同计算 f ( x 1 , ⋯ , x n ) f(x_1,\cdots,x_n) f(x1,⋯,xn),其中 Alice 持有前 k k k个输入 ( a 1 , ⋯ , a k ) (a_1,\cdots,a_k) (a1,⋯,ak),Bob 持有后 n − k n-k n−k个输入 ( a k + 1 , ⋯ , a n ) (a_{k+1},\cdots,a_n) (ak+1,⋯,an),其中 i n d e x ( x 1 ) < ⋯ < i n d e x ( x n ) index(x_1)<\cdots
那么,Alice 构造 OBDD 时,可以执行 Restriction 算法,构造如下函数的 OBDD,
f ∣ x 1 = a 1 , ⋯ , x k = a k ( x k + 1 , ⋯ , x n ) f|_{x_1=a_1,\cdots,x_k=a_k}(x_{k+1},\cdots,x_n) f∣x1=a1,⋯,xk=ak(xk+1,⋯,xn)
相较于 f f f对应的 OBDD,这大大降低了图的规模。因此,在很多常见布尔函数的计算上,OBDD 比 Yao’s GC 小得多。
算法如下:

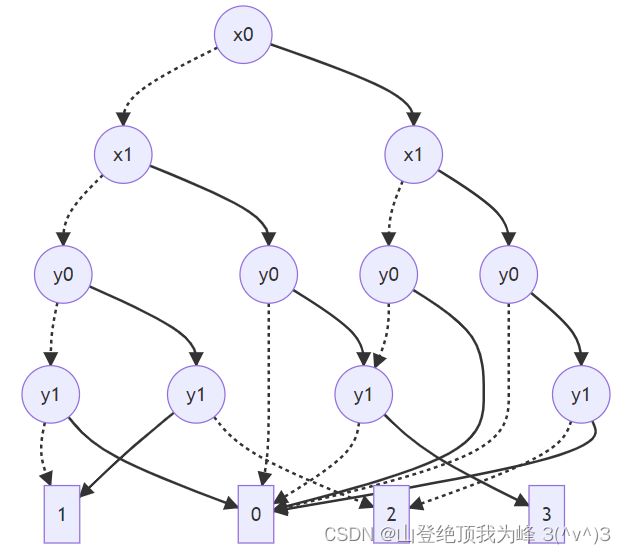
注意,在计算 f ∣ x 1 = a 1 , ⋯ , x k = a k f|_{x_1=a_1,\cdots,x_k=a_k} f∣x1=a1,⋯,xk=ak时,要保留所有 i n d e x ( v ) = k + 1 index(v)=k+1 index(v)=k+1的节点!原因如下图所示:

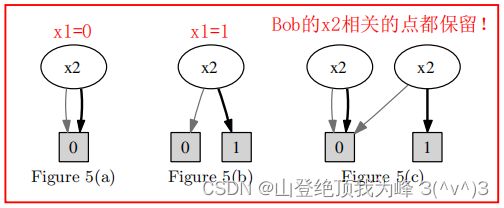
对于 Alice 的 x 1 x_1 x1的不同取值,直接调用 Restriction 算法会产生不同的 OBDD,这会泄露 x 1 x_1 x1的信息。因此,我们应当保留全部的 i n d e x ( v ) = k + 1 index(v)=k+1 index(v)=k+1的节点,得到的 OBDD 拥有若干个 root 节点。
任意输入
然而,OBDD 的规模对变量顺序很敏感,Alice 可以找到合适的顺序,使得构造的 OBDD 尽可能小,并把这个顺序告知 Bob。Alice 和 Bob 协同计算 f ( x 1 , ⋯ , x n ) f(x_1,\cdots,x_n) f(x1,⋯,xn),其中 Alice 持有其中的 k k k个输入 X A X_A XA,Bob 持有另外 n − k n-k n−k个输入 X B = { x 1 , ⋯ , x n } − X A X_B = \{x_1,\cdots,x_n\} - X_A XB={x1,⋯,xn}−XA
Alice 执行 Restriction 算法,构造如下函数的 OBDD,
f ∣ X A ( X B ) f|_{X_A}(X_B) f∣XA(XB)
这进一步降低了 OBDD 的规模。
改进算法如下:

与 FairPlay 的电路规模(节点、门)比较如下: