Elasticsearch:多语言语义搜索
在此示例中,我们将使用多语言嵌入模型 multilingual-e5-base 对混合语言文档的 toy 数据集执行搜索。 使用这个模型,我们可以通过两种方式进行搜索:
- 跨语言,例如使用德语查询来查找英语文档
- 在非英语语言中,例如使用德语查询来查找德语文档
虽然此示例仅使用密集检索,但也可以将密集检索和传统词汇检索与混合搜索相结合。 有关词法多语言搜索的更多信息,请参阅博客文章 “在 Elasticsearch 中使用语言识别进行多语言搜索”。
使用的数据集包含 MIRACL 数据集的维基百科段落片段。
安装
Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的链接来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,我们可以选择 Elastic Stack 8.x 的安装指南来进行安装。在本博文中,我将使用最新的 Elastic Stack 8.10 来进行展示。
在安装 Elasticsearch 的过程中,我们需要记下如下的信息:

Python 安装包
在本演示中,我们将使用 Python 来进行展示。我们需要安装访问 Elasticsearch 相应的安装包 elasticsearch:
pip install elasticsearch
pip install sentence_transformers
pip install torch我们将使用 Jupyter Notebook 来进行展示。
$ pwd
/Users/liuxg/python/elser
$ jupyter notebook创建应用并演示
初始化及连接 Elasticsearch
import getpass
import textwrap
import torch
from elasticsearch import Elasticsearch
from sentence_transformers import SentenceTransformer
device = "cuda" if torch.cuda.is_available() else "cpu"
model = SentenceTransformer("intfloat/multilingual-e5-base", device=device)
然后我们创建一个客户端对象来实例化 Elasticsearch 类的实例。
ELASTCSEARCH_CERT_PATH = "/Users/liuxg/elastic/elasticsearch-8.10.0/config/certs/http_ca.crt"
client = Elasticsearch( ['https://localhost:9200'],
basic_auth = ('elastic', 'vXDWYtL*my3vnKY9zCfL'),
ca_certs = ELASTCSEARCH_CERT_PATH,
verify_certs = True)
print(client.info())
使用所需的映射创建 Elasticsearch 索引
我们需要添加一个字段来支持密集向量存储和搜索。 注意下面的 passage_embedding 字段,它用于存储 passage字段的密集向量表示。
# Define the mapping
mapping = {
"mappings": {
"properties": {
"language": {"type": "keyword"},
"id": {"type": "keyword"},
"title": {"type": "text"},
"passage": {"type": "text"},
"passage_embedding": {
"type": "dense_vector",
"dims": 768,
"index": "true",
"similarity": "cosine"
}
}
}
}
# Create the index (deleting any existing index)
client.indices.delete(index="articles", ignore_unavailable=True)
client.indices.create(index="articles", body=mapping)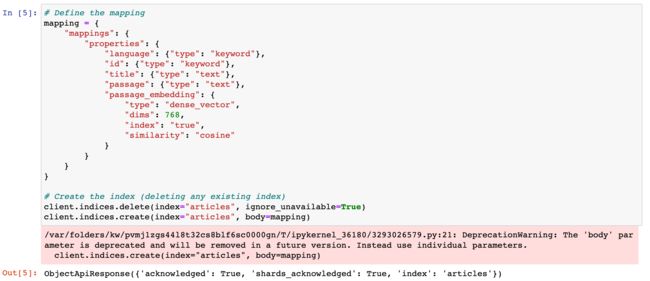
摄入数据
让我们索引一些数据。 请注意,我们使用 sentence transformer 模型嵌入 passage 字段。 建立索引后,你将看到文档包含一个 passage_embedding 字段(“type”:“dense_vector”),其中包含浮点值向量。 这就是 passage 字段在向量空间中的嵌入。 我们将使用该字段使用 kNN 执行语义搜索。
articles = [
{
"language": "en",
"id": "1643584#0",
"title": "Bloor Street",
"passage": """Bloor Street is a major east–west residential and commercial thoroughfare in Toronto, Ontario, Canada. Bloor Street runs from the Prince Edward Viaduct, which spans the Don River Valley, westward into Mississauga where it ends at Central Parkway. East of the viaduct, Danforth Avenue continues along the same right-of-way. The street, approximately long, contains a significant cross-sample of Toronto's ethnic communities. It is also home to Toronto's famous shopping street, the Mink Mile.""",
},
{
"language": "en",
"id": "2190499#0",
"title": "Elphinstone College",
"passage": """Elphinstone College is an institution of higher education affiliated to the University of Mumbai. Established in 1856, it is one of the oldest colleges of the University of Mumbai. It is reputed for producing luminaries like Bal Gangadhar Tilak, Bhim Rao Ambedkar, Virchand Gandhi, Badruddin Tyabji, Pherozshah Mehta, Kashinath Trimbak Telang, Jamsetji Tata and for illustrious professors that includes Dadabhai Naoroji. It is further observed for having played a key role in spread of Western education in the Bombay Presidency.""",
},
{
"language": "en",
"id": "8881#0",
"title": "Doctor (title)",
"passage": """Doctor is an academic title that originates from the Latin word of the same spelling and meaning. The word is originally an agentive noun of the Latin verb "" 'to teach'. It has been used as an academic title in Europe since the 13th century, when the first Doctorates were awarded at the University of Bologna and the University of Paris. Having become established in European universities, this usage spread around the world. Contracted "Dr" or "Dr.", it is used as a designation for a person who has obtained a Doctorate (e.g. PhD). In many parts of the world it is also used by medical practitioners, regardless of whether or not they hold a doctoral-level degree.""",
},
{
"language": "de",
"id": "9002#0",
"title": "Gesundheits- und Krankenpflege",
"passage": """Die Gesundheits- und Krankenpflege als Berufsfeld umfasst die Versorgung und Betreuung von Menschen aller Altersgruppen, insbesondere kranke, behinderte und sterbende Erwachsene. Die Gesundheits- und Kinderkrankenpflege hat ihren Schwerpunkt in der Versorgung von Kindern und Jugendlichen. In beiden Fachrichtungen gehört die Verhütung von Krankheiten und Gesunderhaltung zum Aufgabengebiet der professionellen Pflege.""",
},
{
"language": "de",
"id": "7769762#0",
"title": "Tourismusregion (Österreich)",
"passage": """Unter Tourismusregion versteht man in Österreich die in den Landestourismusgesetzen verankerten Tourismusverbände mehrerer Gemeinden, im weiteren Sinne aller Gebietskörperschaften.""",
},
{
"language": "de",
"id": "2270104#0",
"title": "London Wall",
"passage": """London Wall ist die strategische Stadtmauer, die die Römer um Londinium gebaut haben, um die Stadt zu schützen, die über den wichtigen Hafen an der Themse verfügte. Bis ins späte Mittelalter hinein bildete diese Stadtmauer die Grenzen von London. Heute ist "London Wall" auch der Name einer Straße, die an einem noch bestehenden Abschnitt der Stadtmauer verläuft.""",
},
{
"language": "de",
"id": "2270104#1",
"title": "London Wall",
"passage": """Die Mauer wurde Ende des zweiten oder Anfang des dritten Jahrhunderts erbaut, wahrscheinlich zwischen 190 und 225, vermutlich zwischen 200 und 220. Sie entstand somit etwa achtzig Jahre nach dem im Jahr 120 erfolgten Bau der Festung, deren nördliche und westliche Mauern verstärkt und in der Höhe verdoppelt wurden, um einen Teil der neuen Stadtmauer zu bilden. Die Anlage wurde zumindest bis zum Ende des vierten Jahrhunderts weiter ausgebaut. Sie zählt zu den letzten großen Bauprojekten der Römer vor deren Rückzug aus Britannien im Jahr 410.""",
},
]我们的数据集是一个 Python 列表,其中包含两种语言的维基百科文章中的段落词典。 我们将使用 helpers.bulk 方法批量索引我们的文档。
以下代码迭代文章并创建要执行的操作列表。 每个操作都是一个字典,其中包含对 Elasticsearch 索引的 “index” 操作。 该 passage 使用我们选择的模型进行编码,并将编码向量添加到文章文档中。 请注意,E5 模型要求使用前缀指令 “passage:” 来告诉模型要嵌入 passage。 在查询方面,查询字符串将以 “query:” 为前缀。 然后,文章文档将添加到操作列表中。
最后,我们调用 bulk 方法,指定索引名称和操作列表。
actions = []
for article in articles:
actions.append({"index": {"_index": "articles"}})
passage = article["passage"]
passageEmbedding = model.encode(f"passage: {passage}").tolist()
article["passage_embedding"] = passageEmbedding
actions.append(article)
client.bulk(index="articles", operations=actions)
多语言语义搜索
接下来,我们将使用两种查询进行搜索:
- 以英语查询以查找任何语言的文档
- 以德语查询仅查找德语文档(使用过滤器),以显示模型在非英语语言中的功能
再次注意,查询以 “query:” 为前缀,模型需要它来正确编码查询。
对于不熟悉德语的人来说,可以快速翻译一下:
- "health" -> "Gesundheit"
- "wall" -> "Mauer"
def pretty_response(response):
for hit in response["hits"]["hits"]:
score = hit["_score"]
language = hit["_source"]["language"]
id = hit["_source"]["id"]
title = hit["_source"]["title"]
passage = hit["_source"]["passage"]
print()
print(f"ID: {id}")
print(f"Language: {language}")
print(f"Title: {title}")
print(f"Passage: {textwrap.fill(passage, 120)}")
print(f"Score: {score}")def query(q, language=None):
knn = {
"field": "passage_embedding",
"query_vector" : model.encode(f"query: {q}").tolist(),
"k": 2,
"num_candidates": 5
}
if language:
knn["filter"] = {
"term": {
"language": language,
}
}
return client.search(index="articles", knn=knn)pretty_response(query("health"))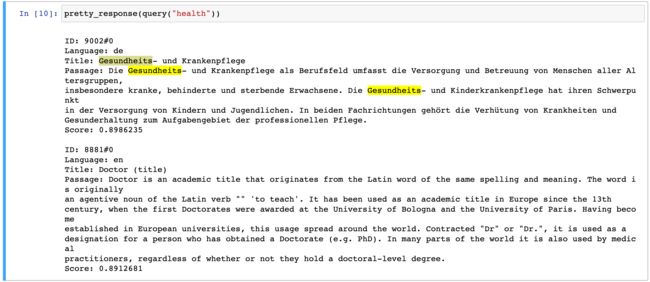
请注意,在上面的结果中,我们看到有关医疗保健的文档,即使是德语,也与查询 “health” 匹配得更好,而英语文档则没有具体谈论健康,而是更广泛地谈论医生。 这就是多语言嵌入的力量,它可以跨语言嵌入含义。
pretty_response(query("wall", language="de"))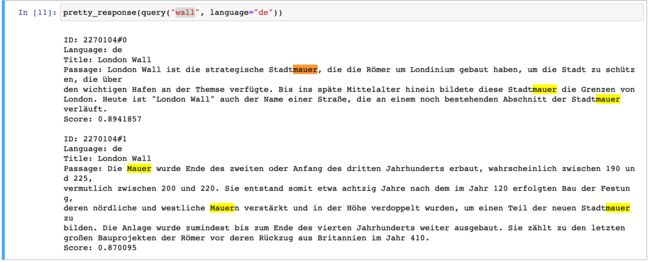
在上面,我们使用过滤器在德语的文档里搜索英文单词 wall。
pretty_response(query("Mauer", language="de"))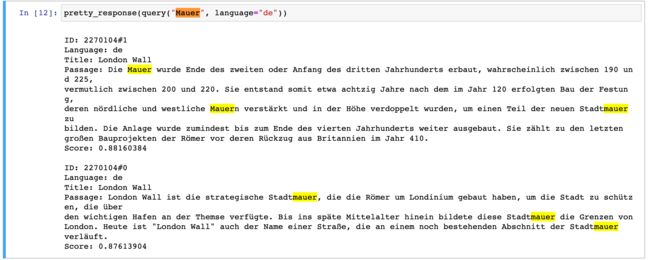
在上面,我们在德语文档里搜索德语单词 “Mauer”。我们可以看到 “London Wall” 文档也被正确搜索到了。
有关 jupyter 的文件可以在地址下载。