使用 TensorFlow 创建 DenseNet 121
一、说明
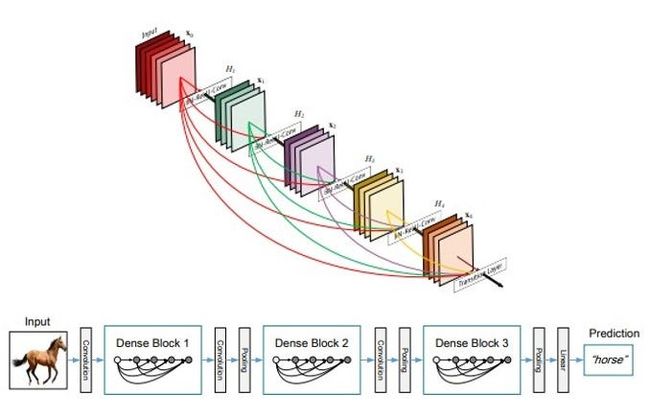
图1:DenseNet中的各种块和层(来源:原始DenseNet论文)
二、DenseNet综述
DenseNet(密集卷积网络)是一种架构,专注于使深度学习网络更深入,但同时通过在层之间使用更短的连接来提高它们的训练效率。DenseNet 是一个卷积神经网络,其中每一层都连接到网络中更深的所有其他层,即第一层连接到第 2、3、4 层等,第二层连接到第 3、4、5 层等。这样做是为了在网络各层之间实现最大的信息流。为了保持前馈特性,每一层从前面的所有层获取输入,并将自己的特征图传递给它将要到达的所有层。与 Resnets 不同,它不是通过求和来组合特征,而是通过连接它们来组合特征。因此,“ith”层具有“i”输入,并且由其所有先前卷积块的特征图组成。它自己的特征图被传递到所有下一个“I-i”层。这在网络中引入了“(I(I+1)))/2”连接,而不是像传统深度学习架构中那样只是“I”连接。因此,与传统的卷积神经网络相比,它需要的参数更少,因为不需要学习不重要的特征图。
DenseNet由两个重要的块组成,而不是基本的卷积层和池化层。它们是密集块和过渡层。
接下来,我们看看所有这些块和层的外观,以及如何在 python 中实现它们。

图2:DenseNet121框架(来源:DenseNet原始论文,由作者编辑)
DenseNet从基本的卷积和池化层开始。然后有一个密集块,然后是一个过渡层,另一个密集块后跟一个过渡层,另一个密集块后跟一个过渡层,最后是一个密集块,然后是一个分类层。
第一个卷积块有 64 个大小为 7x7 的过滤器,步幅为 2。接下来是最大池化为 3x3 且步幅为 2 的 MaxPooling 层。这两行可以在 python 中用以下代码表示。
input = Input (input_shape)
x = Conv2D(64, 7, strides = 2, padding = 'same')(input)
x = MaxPool2D(3, strides = 2, padding = 'same')(x)2.1 定义卷积块 —
输入后的每个卷积块具有以下顺序:批处理归一化,然后是 ReLU 激活,然后是实际的 Conv2D 层。为了实现这一点,我们可以编写以下函数。
#batch norm + relu + conv
def bn_rl_conv(x,filters,kernel=1,strides=1):
x = BatchNormalization()(x)
x = ReLU()(x)
x = Conv2D(filters, kernel, strides=strides,padding = 'same')(x)
return x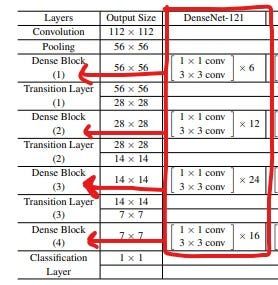
图3.密集块(来源:DenseNet论文-作者编辑)
2.2 定义密集块 —
如图 3 所示,每个密集块都有两个卷积,具有 1x1 和 3x3 大小的内核。在密集块 1 中,重复 6 次,在密集块 2 中重复 12 次,在密集块 3 中重复 24 次,最后在密集块 4 中重复 16 次。
在密集块中,每个 1x1 卷积都有 4 倍的滤波器数量。所以我们使用 4*过滤器,但 3x3 过滤器只存在一次。此外,我们必须将输入与输出张量连接起来。
每个块分别运行 6、12、24、16 次重复,使用 'for 循环'。
def dense_block(x, repetition):
for _ in range(repetition):
y = bn_rl_conv(x, 4*filters)
y = bn_rl_conv(y, filters, 3)
x = concatenate([y,x])
return x
图4:过渡层(来源:DenseNet论文,作者编辑)
2.3 定义过渡层
— 在过渡层中,我们将通道数减少到现有通道的一半。有一个 1x1 卷积层和一个 2x2 平均池化层,步幅为 2。bn_rl_conv,函数中已经设置了 1x1 的内核大小,因此我们不需要明确地再次定义它。
在过渡层中,我们必须将通道删除到现有通道的一半。我们有输入张量x,我们想找到有多少个通道,我们需要得到其中的一半。因此,我们可以使用 Keras 后端 (K) 获取张量 x 并返回一个维度为 x 的元组。而且,我们只需要该形状的最后一个数字,即过滤器的数量。所以我们加上 [-1]。最后,我们可以将这个数量的过滤器除以 2 以获得所需的结果。
def transition_layer(x):
x = bn_rl_conv(x, K.int_shape(x)[-1] //2 )
x = AvgPool2D(2, strides = 2, padding = 'same')(x)
return x因此,我们完成了定义密集块和过渡层的工作。现在我们需要将密集块和过渡层堆叠在一起。所以我们写了一个 for 循环来运行 6,12,24,16 次重复。因此,循环运行 4 次,每次使用 6、12、24 或 16 中的值之一。这样就完成了 4 个密集块和过渡层。
for repetition in [6,12,24,16]:
d = dense_block(x, repetition)
x = transition_layer(d)最后,是GlobalAveragePooling,然后是最终的输出层。正如我们在上面的代码块中看到的,密集块由“d”定义,而在最后一层,在密集块 4 之后,没有过渡层 4,而是直接进入分类层。因此,“d”是应用GlobalAveragePooling的连接,而不是“x”。另一种选择是从上面的代码中删除“for”循环,并将层一个接一个地堆叠,而不使用最终的过渡层。
x = GlobalAveragePooling2D()(d)
output = Dense(n_classes, activation = 'softmax')(x)现在我们已经将所有块放在一起,让我们将它们合并以查看整个DenseNet架构。
三、完整的 DenseNet 121 架构
import tensorflow as tf
from tensorflow.keras.layers import Input, Conv2D, BatchNormalization, Dense
from tensorflow.keras.layers import AvgPool2D, GlobalAveragePooling2D, MaxPool2D
from tensorflow.keras.models import Model
from tensorflow.keras.layers import ReLU, concatenate
import tensorflow.keras.backend as K
# Creating Densenet121
def densenet(input_shape, n_classes, filters = 32):
#batch norm + relu + conv
def bn_rl_conv(x,filters,kernel=1,strides=1):
x = BatchNormalization()(x)
x = ReLU()(x)
x = Conv2D(filters, kernel, strides=strides,padding = 'same')(x)
return x
def dense_block(x, repetition):
for _ in range(repetition):
y = bn_rl_conv(x, 4*filters)
y = bn_rl_conv(y, filters, 3)
x = concatenate([y,x])
return x
def transition_layer(x):
x = bn_rl_conv(x, K.int_shape(x)[-1] //2 )
x = AvgPool2D(2, strides = 2, padding = 'same')(x)
return x
input = Input (input_shape)
x = Conv2D(64, 7, strides = 2, padding = 'same')(input)
x = MaxPool2D(3, strides = 2, padding = 'same')(x)
for repetition in [6,12,24,16]:
d = dense_block(x, repetition)
x = transition_layer(d)
x = GlobalAveragePooling2D()(d)
output = Dense(n_classes, activation = 'softmax')(x)
model = Model(input, output)
return model
input_shape = 224, 224, 3
n_classes = 3
model = densenet(input_shape,n_classes)
model.summary()输出:(假设 3 个最终类 — 模型摘要的最后几行)

四、 查看体系结构关系图
可以使用以下代码。
from tensorflow.python.keras.utils.vis_utils import model_to_dot
from IPython.display import SVG
import pydot
import graphviz
SVG(model_to_dot(
model, show_shapes=True, show_layer_names=True, rankdir='TB',
expand_nested=False, dpi=60, subgraph=False
).create(prog='dot',format='svg'))输出 — 图表的前几个块
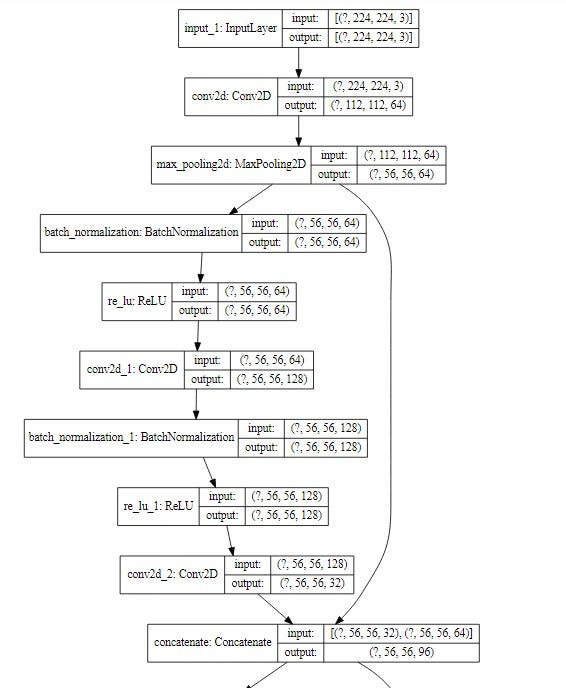
这就是我们如何实现DenseNet 121架构。
五、引用
- 黄高、刘壮、劳伦斯·范德马滕和基利安·温伯格,密集连接的卷积网络,arXiv 1608.06993 (2016)
阿琼·萨卡尔
2 密网论文链接:https://arxiv.org/pdf/1608.06993.pdf