计算机网络传输层小结(8300字(半口语半书面语)+40张图)
目录
概述
传输层作用
两个重要协议
TCP
UDP
端口号
报文段格式
UDP报⽂段格式
TCP报文段格式
TCP服务
可靠传输
停止等待ARQ协议
连续ARQ协议 + 滑动窗⼝协议
选择性确认(SACK)
流量控制
拥塞控制
拥塞控制的算法
慢开始
拥塞避免
快重传
快恢复
建⽴连接和释放连接
三次握手
四次挥手
结束语
概述
传输层作用
1.为运⾏在不同主机上的应⽤进程提供直接的逻辑通信服务。
2.为不可靠的网络层提供可靠或者不可靠的传输。
为什么要有这两个作用呢?
其一,我们的网络层、链路层、物理层已经实现了主机到主机的通信,提高了主机之间的逻辑通信,但我们的应用层或者说应用进程需要进程之间的逻辑通信,由此,如何为运⾏在不同主机上的应⽤进程提供直接的逻辑通信服务,就是传输层的主要任务。
其二,我们的网络层等如果要提供可靠的传输服务,需要付出相当大的代价。试想一下,我们路由器转发我们的数据报(或者是报文段),需要等到收到对方确认的数据报或者报文段之后,将它从缓存中删除,否则,将一直存储,这种开销是相当大的,我们的网络也将变得臃肿!
两个重要协议
TCP
1.传输控制协议(Transmission Control Protocol,TCP)为其上层提供的是⾯向连接的可靠的数据 传输服务。
2.使⽤TCP通信的双⽅,在传送数据之前必须⾸先建⽴TCP连接(逻辑连接,⽽⾮物理连接)。数据 传输结束后必须要释放TCP连接。
3.TCP为了实现可靠传输,就必须使⽤很多措施,例如TCP连接管理、确认机制、超时重传、流量控 制以及拥塞控制等。
4.TCP的实现复杂,TCP报⽂段的⾸部⽐较⼤,占⽤处理机资源⽐较多。
UDP
1.⽤户数据报协议(User Datagram Protocol,UDP)为其上层提供的是⽆连接的不可靠的数据传输 服务。
2.使⽤UDP通信的双⽅,在传送数据之前不需要建⽴连接。
3.UDP不需要实现可靠传输,因此不需要使⽤实现可靠传输的各种机制。
4.UDP的实现简单,UDP⽤户数据报的⾸部⽐较⼩。
两个协议解决了可靠与不可靠的问题。

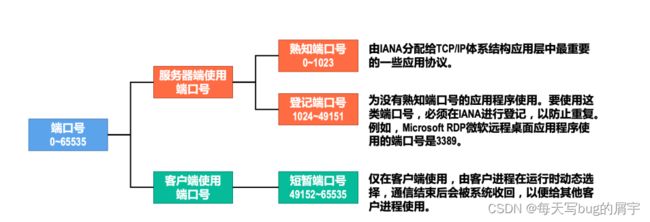
端口号
端口号解决了第一个任务。
运⾏在计算机上的进程是使⽤进程标识符(Process Identification,PID)来标识的。
然⽽,因特⽹上的计算机并不是使⽤统⼀的操作系统,⽽不同操作系统(Windows、Linux、 MacOS)⼜使⽤不同格式的进程标识符。
为了使运⾏不同操作系统的计算机的应⽤进程之间能够基于⽹络进⾏通信,就必须使⽤统⼀的 ⽅法对TCP/IP体系的应⽤进程进⾏标识。
网络系统识别一个进程:Ip:port src & dist
本机系统识别一个进程:进程号

报文段格式
UDP报⽂段格式
1.UDP是⽆连接的,减少了建⽴和释放连接的开销
2.UDP尽最⼤能⼒交付,不保证可靠交付
不需要维护复杂的参数,⾸部只有8个字节(TCP⾸部⾄少20字节)
3.UDP⻓度 占16位(2字节),⾸部的⻓度+数据⻓度
(只是为了占位。因为,UDP首部固定8个字节,在下一层中,假设IP v4,IP头部的上层协议知道了传输层用UDP协议,用数据报长度减去IPv4首部20字节和UDP首部8字节,便是应用层数据大小。)
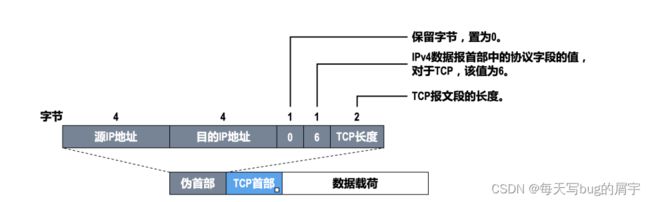
4.校验和的计算内容:伪⾸部 + ⾸部 + 数据
伪⾸部:仅在计算校验和时起作⽤,并不会传递给⽹络层

关于伪首部,见下图。
伪首部不是在网络层中产生的,而是在传输层中,临时用于计算校验和,并不会向下传递。

TCP报文段格式
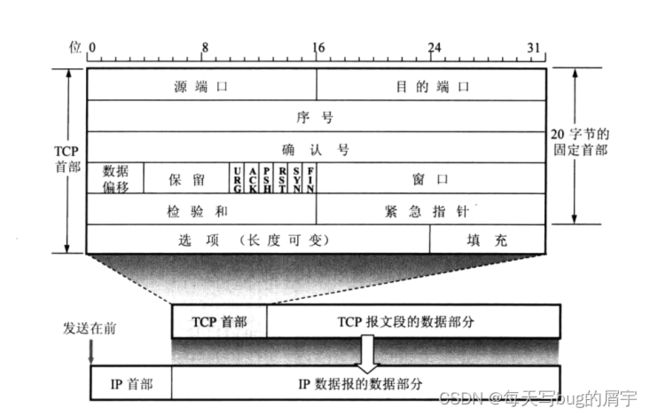
1.序号:占32⽐特,取值范围0~2 -1。当序号增加到最后⼀个时,下⼀个序号⼜回到0。⽤来指出本TCP报 ⽂段数据载荷的第⼀个字节的序号。
这里类比c语言
序号和确认号要考虑编址
c语言中,int arr[5]; 是4*5=20个字节 ,但是按0 1 2 3 4对象映射
而序号和确认号不是按包编址 而是按字节
发5B的包
0 1 2 3 4 序号:0 确认ack id :5
接着5B的包
5 6 7 8 9 序号:5
2.确认号:占32⽐特,取值范围0~2 -1。当确认号增加到最后⼀个时,下⼀个确认号⼜回到0。⽤来指出期望 收到对⽅下⼀个TCP报⽂段的数据载荷的第⼀个字节的序号,同时也是对之前收到的所有数据的确认。
确认号和序号不是表示的随便的一个字节,TCP重传不是字节重传,而是段重传。

数据偏移 :
1.占4⽐特,该字段的取值以4字节为单位。
2.指出TCP报⽂段的数据载荷部分的起始处距离TCP报⽂段的起始处有多远,这实际上指出了 TCP报⽂段的⾸部⻓度。
4个bit范围是0到15,乘以4,可以有最多60个字节的首部长。
限制了选项的长度,等于限制了一些功能。
类比IP首部头数据报长度,IP数据报长度减去首部便是数据起始位置。

这是一个TCP包,红框标记的是数据偏移长度。

我们拉下来看到,绿框的保留位,和蓝框的6个bit的状态标记。
(绿框中只有3个bit是reserved,其余不是。这是因为随着TCP的发展下面的3个是新增的标记位,但是用的不多,老版本仍是6位。)

蓝框中一个bit代表一个状态(请注意他们的缩写)
URG:状态为1,说明TCP数据部分里面含有马上需要处理的紧急数据。
那我如何找到他们呢,紧急指针!
URG用的不多,了解即可。
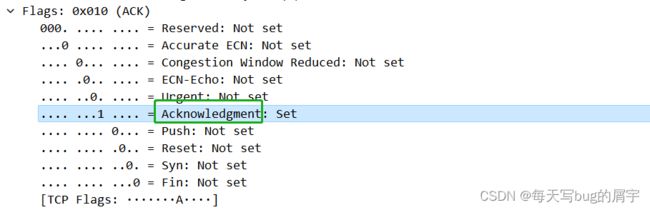
ACK:为1,确认号才有意义。
推送标志位PSH:
发送⽅TCP把PSH置1,并⽴即创建⼀个TCP报⽂段发送出去,⽽不需要积累到⾜够多的数 据再发送。
接收⽅TCP收到PSH为1的TCP报⽂段,就尽快地交付给应⽤进程,⽽不再等到接收到⾜够 多的数据才向上交付。
想象一下,你给百度发请求网页的报,但是报太小,进入百度接收的缓存区后,没有达到一定的大小,并不会处理。但是PSH为1时,会立马处理。
复位标志位RST:
⽤于复位TCP连接。
当RST=1时,表明TCP连接中出现严重差错,必须释放连接,然后再重新建⽴连接。
RST置1还⽤来拒绝⼀个⾮法的TCP报⽂段或拒绝打开⼀个TCP连接。
同步标志位SYN :
SYN为1的TCP报⽂段要么是⼀个连接请求报⽂段,要么是⼀个连接响应报⽂段。
用于建立连接。
终⽌标志位FIN:
⽤于TCP“四报⽂挥⼿”释放连接。
当FIN=1时,表明此TCP报⽂段的发送⽅已经将全部数据发送完毕,现在要求释放TCP连 接。
用于结束、释放连接。
下图红蓝绿分别是窗口、校验位、紧急指针。
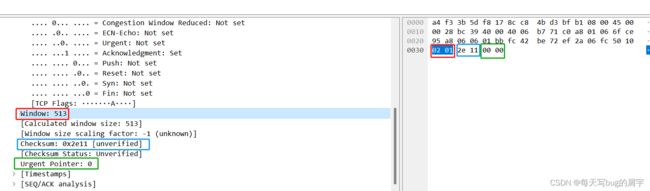
窗⼝:
1.占16⽐特,该字段的取值以字节为单位。
2.指出发送本报⽂段的⼀⽅的接收窗⼝的⼤⼩,即接收缓存的可⽤空间⼤⼩,这⽤来表征接收⽅ 的接收能⼒。
3.在计算机⽹络中,经常⽤接收⽅的接收能⼒的⼤⼩来控制发送⽅的数据发送量,这就是所谓的 流量控制。
校验和 :占16⽐特
⽤来检查整个TCP报⽂段在传输过程中是否出现了误码。
紧急指针:标记TCP数据部分偏移量,配合URG
选项(⻓度可变,最⼤40字节)
最⼤报⽂段⻓度MSS选项:指出TCP报⽂段数据载荷部分的最⼤⻓度,⽽不是整个TCP报⽂段的⻓度。
窗⼝扩⼤选项:⽤来扩⼤窗⼝,提⾼吞吐率。
时间戳选项: ⽤于计算往返时间RTT ⽤于处理序号超范围的情况,⼜称为防⽌序号绕回PAWS。
选择确认选项:⽤来实现选择确认功能。
TCP服务
可靠传输:解决丢包问题。
流量控制:解决发送端、接收端处理速度不协调的问题。
拥塞控制:处理网络集合之间的互相关系。
连接管理:处理网络资源正确的释放。
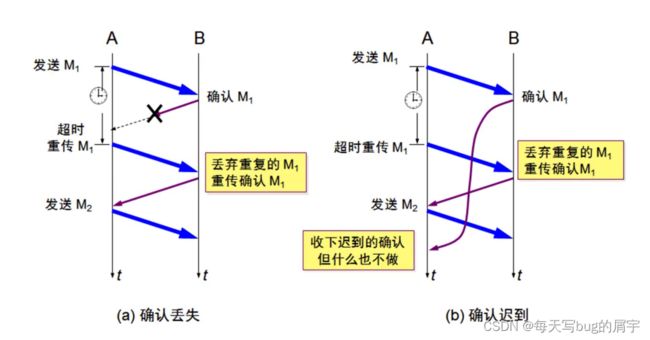
可靠传输
本质:超时重传!!!
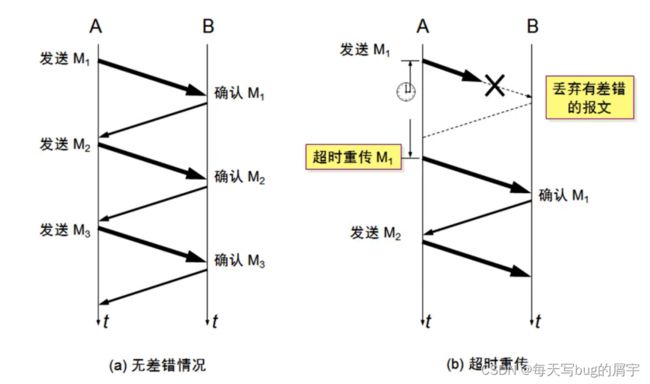
停止等待ARQ协议
ARQ(Automatic Repeat–reQuest)⾃动重传请求
一个段一个段的进行发送确认。
考虑网络中的所有情况。
连续ARQ协议 + 滑动窗⼝协议
我们考虑到,停止等待ARQ协议需要较长的等待时间,使得数据传输速度低。低速传输时频道利用率较高,高速传输时频道利用率较低。
因此产生了连续ARQ协议
一次发多个段,提高效率。
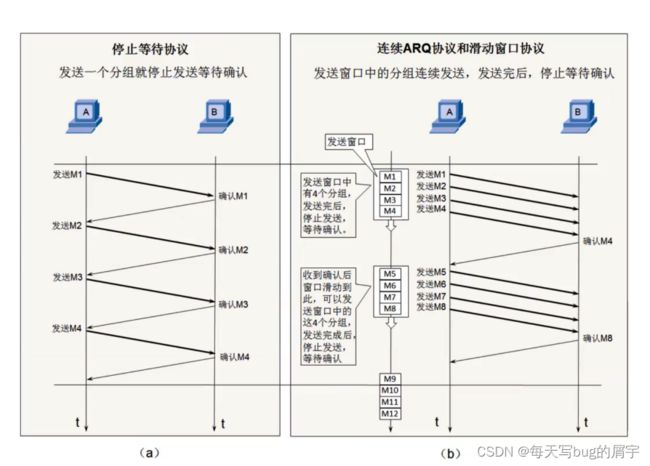
一次发送多个数据包,但是多个是多少呢?
接收端需要告诉我窗口大小。
在发送之前双方的通信中,主机B告知主机A,我的缓存区开了多大,你最多传输这么多。
收到一些分组后,主机B发现还能更大,提高效率,确认数据包再告知主机A,你再多来点,
总觉得怪怪的。见下图,MSS是最大报文段长度。


图中红色的框中不要与前面大写的ACK搞混,见下图
蓝色框是序号seq,红色框是确认号ack

绿框中是ACK ,前面讲过。
选择性确认(SACK)
来看图

由于发送包7丢失了,滑动窗口只能把5和6滑走。但是我们重传发送的时候,8还发吗?
我们引出一个问题,假设我们的窗口非常大,只有7丢了,后面8到100都收到了,怎么办?全部重传很浪费、效率低。
所有,我们有选择确认机制。
SACK(Selective acknowledgment,选择性确认)技术。
告诉发送⽅哪些数据丢失,哪些数据已经提前收到。
如何做到呢?
TCP首部选项!来看下图
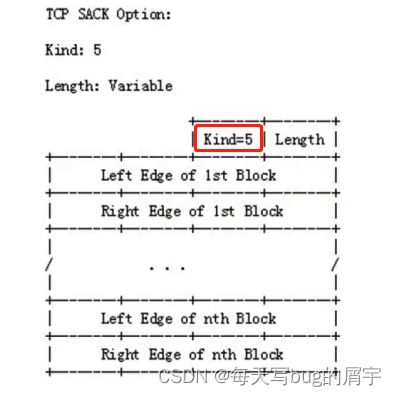
SACK信息会放在TCP⾸部的选项部分
考虑到选项中可以有多种不同的选择,所以有kind。
Kind:占1字节。值为5代表这是SACK选项
Length:占1字节。表明SACK选项⼀共占⽤多少字节
Left Edge:占4字节,左边界
Right Edge:占4字节,右边界
图中深色部分,表示收到的段,收到哪个段,就把响应的L1加入选项中,发送端收到后,哪些有就不再传了。
接下来考虑如何描述数据段呢,可不可以按位去描述呢?我的序号是4个字节,而如果L和R按位去描述,那么因为选项最多40字节,存5个块呢?5+5=10的R+L。但还要包含2个字节的kind和length。
所以,我们最多存4个块,也就是4个L,4个R。
4(一个R或L 4字节)*8(个数)+2(kind&length) = 34 < 40
也可以看出,选择确认并不是强制要求。
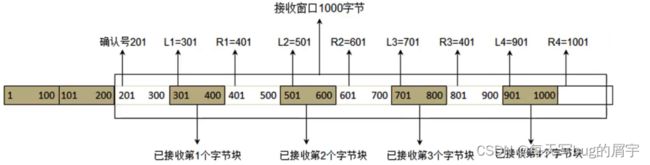
⼀对边界信息需要占⽤8字节,由于TCP⾸部的选项部分最多40字节
1.SACK选项最多携带4组边界信息
2.SACK选项的最⼤占⽤字节数 = 4 * 8 + 2 = 34
下图中MSS位1460,至于为什么,各位推一推便知
提示,链路层最大传输单元MTU位1500,网络层协议首部通常20字节,TCP首部至少20字节
MSS是最大报文段长度。

为什么选择在传输层将数据分成多个段,⽽不是等到⽹络层分⽚传递给数据链路层?
链路层可以提高可靠传输
如果在传输层不分段,数据一旦丢失,整个数据都需要重传,而如果分段,只需要重传丢失的段就可以。
提高效率!
既然如此,网络层还需要分片干嘛?
例如:ICMP包在网络层上传递,不会经过传输层。
流量控制
应⽤程序可能正忙于其他任务,并不⼀定能够⽴刻取⾛数据。客户端持续发送⼤量数据,接收端缓存会溢出,造成数据丢失。
TCP为应⽤程序提供了流量控制(Flow Control)机制,以解决因发送⽅发送数据太快⽽导致接收 ⽅来不及接收,造成接收⽅的接收缓存溢出的问题。
流量控制的核心:窗口
流量控制的基本⽅法:接收⽅根据⾃⼰的接收能⼒(接收缓存的可⽤空间⼤⼩)控制发送⽅的发送 速率。
1.通过确认报⽂中窗⼝字段来控制发送⽅的发送速率
2.发送⽅的发送窗⼝⼤⼩不能超过接收⽅给出窗⼝⼤⼩
3.当发送⽅收到接收窗⼝的⼤⼩为0时,发送⽅就会停⽌发送数据
(但如果有能发了,那怎么知道呢?)

本图中,rwnd指明了窗口的大小,wnd通常指Window,在拥塞控制的算法时会讲到。
可以看到,第一次rwnd是400,但是只有2个100的数据段到达,所以主机B减少窗口大小,少发点,rwnd位300,A的窗口变为300,这就是流量控制。
下一次,又调整了窗口大小(可能由于缓存大小少了的问题),A继续调整。
最后,缓存满了,窗口为0。
等有缓存时,主机B再告诉主机A,来发吧,窗口大小这么多,从哪开始的(确认号)。
但是,好巧不巧,这个发给A的报文丢了,A不知道,怎么办??

解决方案:
当发送⽅收到0窗⼝通知时,这时发送⽅停⽌发送报⽂ 。
并且同时开启⼀个定时器,隔⼀段时间就发个测试报⽂去询问接收⽅最新的窗⼝⼤⼩ 。
如果接收的窗⼝⼤⼩还是为0,则发送⽅再次刷新启动定时器。
一句话:多问几次,没有什么是一蹴而就的!!!
(除了一蹴而就的)
拥塞控制
拥塞:在某段时间,若对⽹络中某⼀资源的需求超过了该资源所能提供的可⽤部分,⽹络性能就要 变坏,这种情况就叫作拥塞(congestion)。
计算机⽹络中的链路容量(带宽)、交换节点中的缓存和处理机等都是⽹络的资源。
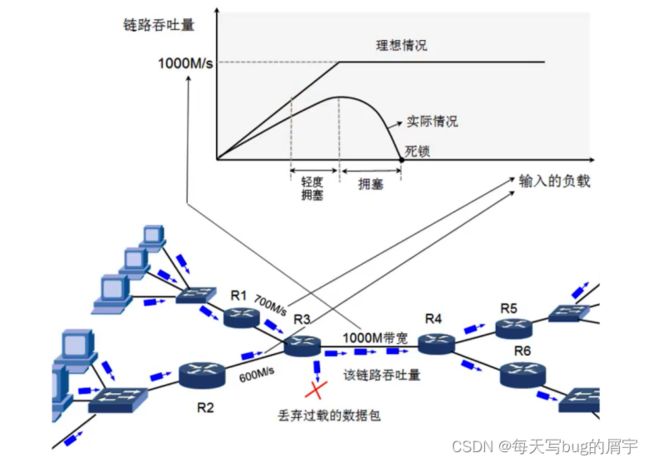
上图中,如果R1+R2传输的过多,超过了R3这一资源所能提供的可用部分,会出现堵塞、丢失情况。但是路由没有缓存,不会重传。类比早晚高峰。
拥塞控制的核心:试探
而流量控制是协商,互相告知。
拥塞控制是⼀个全局性的过程 ,
涉及到所有的主机、路由器,以及与降低⽹络传输性能有关的所有因素 。
是需要靠所有节点共同努⼒的结果 ,
防⽌过多的数据注⼊到⽹络中,使⽹络能够承受现有的⽹络负荷。
相⽐⽽⾔,流量控制是点对点通信的控制。
拥塞控制的算法
⽅法概述 :
慢开始(slow start,慢启动)、拥塞避免(congestion avoidance) 快速重传(fast retransmit)、快速恢复(fast recovery)
⼏个缩写 :
cwnd(congestion window):拥塞窗⼝
rwnd(receive window):接收窗⼝
swnd(send window):发送窗⼝, swnd = min(cwnd, rwnd)
慢开始
第一次试探,100字节,发送过去后,主机B收到并返回确认报,发送方收到了确认报,说明100字节还可以,大胆一点,增加cwnd,再收到确认报,再增加大一点.....
如果轮次2确认报只确认了M2,说明链路拥堵
,当然信号丢了也有可能(这是没有办法的事情,我们的算法无法解决),此时会降低。

cwnd的初始值⽐较⼩,然后随着数据包被接收⽅确认(收到⼀个ACK)
cwnd成倍增⻓(指数级)
细见下图
拥塞避免
开始很慢,但指数增长
到达阈值后,加法增大
第一次拥塞后,阈值乘法减小
再慢开始。

ssthresh(slow start threshold):慢开始阈值,cwnd达到阈值后,以线性⽅式增加。
拥塞避免(加法增⼤):拥塞窗⼝缓慢增⼤,以防⽌⽹络过早出现拥塞
乘法减⼩:只要⽹络出现拥塞,把ssthresh减为拥塞峰值的⼀半,同时执⾏慢开始算法(cwnd⼜恢复到初始值)
当⽹络出现频繁拥塞时,ssthresh值就下降的很快
快重传
接收⽅ :每收到⼀个失序的分组后就⽴即发出重复确认 ,
使发送⽅及时知道有分组没有到达 ,
⽽不要等待⾃⼰发送数据时才进⾏确认 。
发送⽅: 只要连续收到三个重复确认(总共4个相同的确认),就应当⽴即重传对⽅尚未收到的报⽂段 ,
⽽不必继续等待重传计时器到期后再重传。
见下图
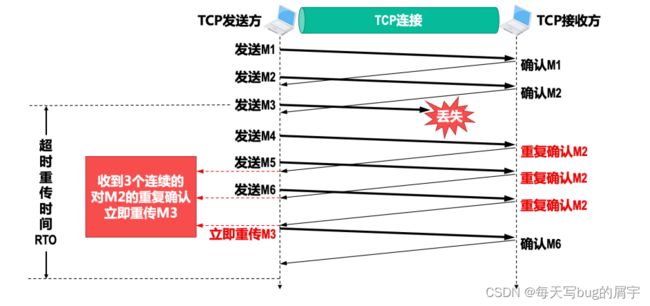
对于个别丢失的报⽂段,发送⽅不会出现超时重传,也就不会误认为出现了拥塞⽽错误地把拥塞窗 ⼝cwnd的值减为1。实践证明,使⽤快重传可以使整个⽹络的吞吐量提⾼约20%。
快恢复
当发送⽅连续收到三个重复确认,说明⽹络出现拥塞 就执⾏“乘法减⼩”算法,把ssthresh减为拥塞峰值的⼀半 。
与慢开始不同之处是现在不执⾏慢开始算法,即cwnd现在不恢复到初始值 ⽽是把cwnd值设置为新的ssthresh值(减⼩后的值), 然后开始执⾏拥塞避免算法(“加法增⼤”),使拥塞窗⼝缓慢地线性增⼤。

建⽴连接和释放连接
连接、释放的过程是?为什么这么复杂?
三次握手
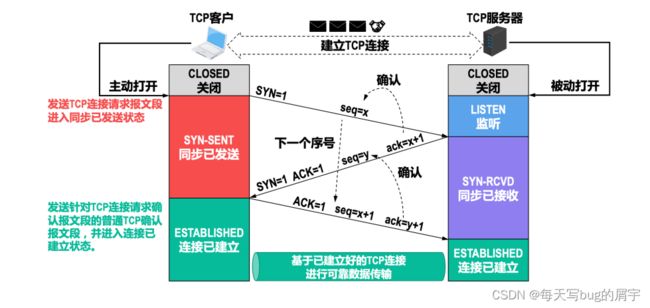
第一次握手,ACK=0,表面确认号不用。seq是序号,告诉起始位置。但不是0,为了避免包发到其他人那里看到猜测出。
第二次握手,SYN为1,用于建立连接。ACK=1,确认号用,回应x+1状态。注意第一次握手没有数据。seq=y,我的起始序号是y,但是也是没有数据的!
第三次握手,仍然没有数据,但下一次再发,还是x+1。这个包没有数据,而是为了回应上一次的信息。


第一次握手, 我们可以看到红框relative sequence number 相对seq 是0
但真是值是多少呢,没错,就是下面那个。相当于x!
最上面那个图,我们看到第一次握手有SYN,表明要求建立连接。

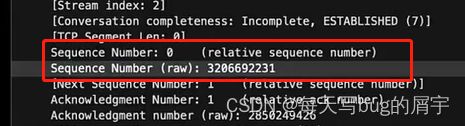
第二次握手,相对Ack为1, 真实值呢,是上面那个2850249425+1。
同时,有ACK表明确认号有用。SYN表明我连接响应你。
而服务器发送的也要有包(因为服务器可能要发一些东西,同时为第三次握手准备)
我们看到3206692231,就是y!
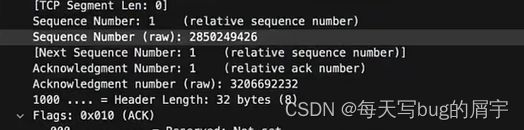
带三次握手,seq是...9426! Ack是....2232! ACK为1
那我们看看,这些真的有数据吗?
见下图

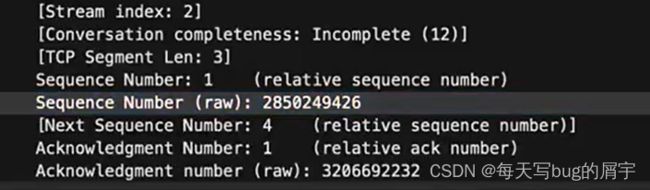
在三次握手之后,我主机在发送数据包,此时的seq就是x+1。
所以第三次握手的seq=x+1,但是是没有数据的。
而Ack仍然是第三次握手时的y+1。
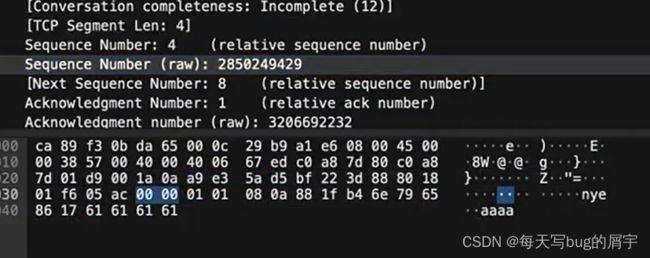
当我们再发aaaa这个报文时,我们发现相对seq变成了4,但是Ack仍然未变,还是y+1
这是因为对方未给我们发送报文,我们接收缓存还是y+1
为什么必须是三次握⼿⽽不是⼆次握⼿?
采⽤“三报⽂握⼿”⽽不是“两报⽂握⼿”来建⽴TCP连接,是为了防⽌已失效的TCP连接请求报⽂段 突然⼜传送到了TCP服务器进程,因⽽导致错误。
四次挥手

绿色是已经建立连接了。
挥手,是任何一个人都有可能发的。无论是客户端还是服务器。
我们想,每个人有发送和接收能力。我不给你发送,但是你可以给我发送。反之亦然。
第一,当我告诉你,我不给你发消息了,你需要立马关闭吗?
不行!你怎么知道我还有之前发的数据没到或者我给你发的数据还没处理完
慢死了当收到EOF之后,后面的仍何消息都不看,空间直接释放。
第二次挥手,是应用层发的还是传输层发的?
传输层!应用层读到EOF,不会再和你联系,所以是传输层发的。
第三次、四次挥手,传输层发的。
当我们有大量的FIN-WAIT-2这个状态时,我们不必担心,是对方还没处理完数据。
第一次挥手之后,对方挥手(第二次挥手),对方不会再接收发送消息(逻辑上),对方等待自己应用层处理完数据,再挥手(第三次分手)。第四此挥手,彻底结束。
第一次挥手FIN=1,表明要结束通信
(分手),确认号为v,序号为u。第二次挥手,序号为v,确认号为u+1,我知道了你要结束通信。
第三次挥手确认号仍然为u+1,同时FIN=1,告诉你,我好了,咱们分手吧。
第四次挥手,seq=u+1,确认号为w+1,ok,我看到你的消息了。
最后
为什么要等待2MSL?
因为我告诉你我看到你的消息了,但是你确认我已读之后,把我拉黑了。
但是对方又发了句,“爱看不看啊!”,还是没看到我的消息啊,那我再发一次吧。
如果一整天你都没回我,嗯,应该是把我拉黑了。
好伤心
第⼀次挥⼿
序号seq字段的值设置为u,它等于TCP客户进程之前已经传送过的数据的最后⼀个字节的序号 加1。
TCP规定终⽌标志位FIN等于1的TCP报⽂段即使不携带数据,也要消耗掉⼀个序号。
确认号ack字段的值设置为v,它等于TCP客户进程之前已收到的数据的最后⼀个字节的序号加 1。
第⼆次挥⼿
序号seq字段的值设置为v,它等于TCP服务器进程之前已传送过的数据的最后⼀个字节的序号 加1。这也与之前收到的TCP连接释放报⽂段中的确认号v匹配。
确认号ack字段的值设置为u+1,这是对TCP连接释放报⽂段的确认。
经过两次挥⼿后,从TCP客户进程到TCP服务器进程这个⽅向的连接就释放了,但TCP服务器进程 如果还有数据要发送,TCP客户进程仍要接收,也就是从TCP服务器进程到TCP客户进程这个⽅向的连 接并未关闭。
第三次挥⼿
TCP连接释放报⽂段⾸部中的终⽌标志位FIN和确认标志位ACK的值都被设置为1。表明这是⼀ 个TCP连接释放报⽂段,同时也对之前收到的TCP报⽂段进⾏确认。
序号seq字段的值假定被设置为w,这是因为在半关闭状态下TCP服务器进程可能⼜发送了⼀些 数据。
确认号ack字段的值被设置为u+1,这是对之前收到的TCP连接释放报⽂段的重复确认。
TCP服务器进⼊LAST-ACK状态
第四次挥⼿
序号seq字段的值设置为u+1,这是因为TCP客户进程之前发送的TCP连接释放报⽂段虽然不携 带数据,但要消耗掉⼀个序号。
确认号ack字段的值设置为w+1,这是对所收到的TCP连接释放报⽂段的确认。
TCP客户端进⼊TIME-WAIT状态,等待2MLS,MSL是最⻓报⽂段寿命(Maximum Segment Lifetime)的英⽂缩写词,[RFC793]建议为2分钟。也就是说,TCP客户进程进⼊时间等待 (TIME-WAIT)状态后,还要经过4分钟才能进⼊关闭(CLOSED)状态。
最后来几道题吧,


应该不难吧,哈哈 ,如果不会的话——评论区告诉我,我来补充。
结束语
还是很有意思的吧,哈哈哈哈
我觉得计网黑皮书还是很不错的,我前7章看完了,当然是跳着看的哈哈。
其他的小结会出,一些考研题我会讲解,仅为理解深刻!
拜拜,祝你AC 哎?这又不是编程题