【软件设计师01】计算机组成与体系结构
计算机组成与体系结构
1. 数据的表示
1. 进制转换
按权展开法:R进制 -> 十进制
二进制 10100.01 -> 1*2^4 + 1*2^2 + 1*2^-2
八进制 705.3 -> 7*8^2 + 5*8^0 + 3*8^-1
短除法:十进制 -> R进制
不断除R进制标记余数,当下一次余数为0时停止,从后往前连接
94转二进制
94/2 -> 0
47/2 -> 1
23/2 -> 1
11/2 -> 1
5/2 -> 1
2/2 -> 0
1
得到结果:1011110
二进制转八进制/十六进制可以分为3/4个数为一组计算
小数转换(精度丢失)
十进制小数部分转R进制会丢失精度,只有一些特定数值可以完美转换
0.125转二进制
0.125*2=0.25 取整数部分0
0.25*2=0.5. 取整数部分0
0.5*2=1 取整数部分1
从前往后连接得到结果:0.001

B
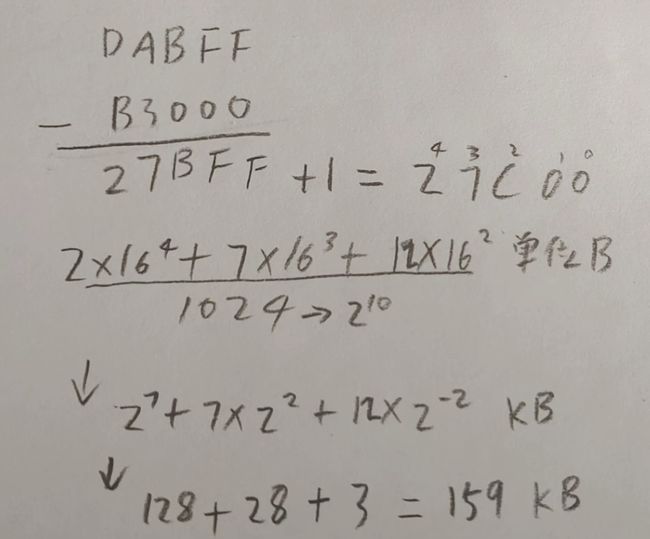

B

B

D

B、C

A

B
2. 数据编码(原/反/补/移)
一般用1个字节8位表示码值
原码(-127~127):用n个字节表示二进制数,首位为符号位(0正 1负),中间补0
反码(-127~127):正数的反码不变,负数符号位不变其他位取反
补码(-128~127):正数的补码不变,负数的补码为反码加1
移码(-128~127):补码的首位取反,其余不变;一般做浮点运算中的阶码
反码、补码、移码都能正确的做加减运算;在原码和反码中0分正负两种表示方式,因此表示范围少1位

C

B 转2进制后反推

C

B

B

B

D
3. 浮点数运算 - 科学计数法
N = M*R^e
M尾数、e指数、R基数
运算方式:对阶 -> 尾数计算 -> 结果格式化
即两个指数不同的数加减运算需要先对阶,再算尾数,再格式化成科学计数法(尾数为1位数字且不为0)
对阶:小阶向大阶对,尾数向右移
浮点数表示对范围由阶码决定,精度由尾数决定


B

C、D;规格化是指要求将尾数的绝对值限定在区间 [0.5,1],(3)D有一点争议

A

B

A

B

D
2. CPU(运算器+控制器)
计算机硬件系统:运算器、控制器、存储器、输入设备、输出设备

A

B

B、10001转原码11111,首位是符号位,其余位可表示范围24 - 1,及范围215,后面部分是求这个数所以不是之前的题型求范围用1减去
1. 运算器组成
算术逻辑单元ALU 算术和逻辑运算
累加寄存器AC 运算结果或源操作数存放区
数据缓冲寄存器DR 暂存指令或数据
状态条件寄存器PSW 暂存运算结果的相关标志位,如溢出标志
累加寄存器AC用来为算术逻辑单元ALU提供暂存运算结果

D

B
2. 控制器组成
指令寄存器IR 暂存CPU执行指令
程序计数器PC 存放下一条指令的地址
地址寄存器AR 当前CPU访问的内存单元地址
指令译码器ID 分析指令操作码
时序部件

C

B

B

B 透明是指无法访问,在汇编语言中B不可以访问

B

B

A

B

C !!!

C 注意是取指令操作码,指令=操作码+地址码

B

A

A
3. 寻址方式
从快到慢可以分为:
立即寻址:操作数就包含在指令中。
寄存器寻址:操作数存放在某一寄存器中,指令中给出存放操作数的寄存器名。
直接寻址(指令中存操作数地址):操作数存放在内存单元中,指令中直接给出操作数所在的存储单元的地址。
寄存器间接寻址(寄存器中存操作数地址):操作数存放在内存单元中,操作数所在存储单元的地址在某个寄存器中。
间接寻址:指令中给出操作数地址的地址。

D

A、转移

B

C;2G/32 -> 2048 * 1024 / (32/4) -> 512MB

C

A
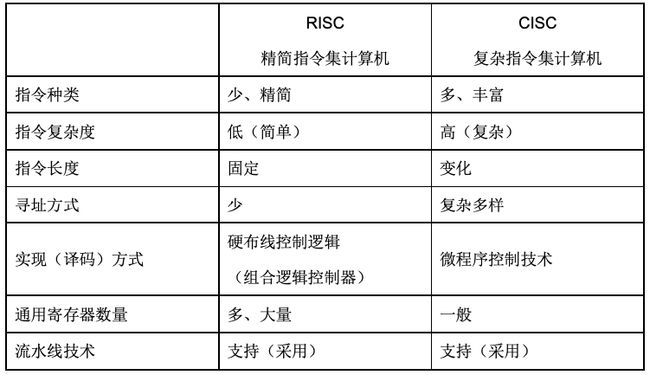
3. 计算器体系结构分类 Flynn
| 体系结构分类 | 结构 | 关键特性 | 代表 |
|---|---|---|---|
| 单指令流单数据流SISD | 控制部分:1 | 单处理器系统(单片机系统多见) | |
| 处理器:1 | |||
| 主存模块:1 | |||
| 单指令流多数据流SIMD | 控制部分:1 | 各处理器以异步形式执行同一条指令 | 并行处理机、阵列处理机(适合数组与数组之间的运算)、超级向量处理机 |
| 处理器:多 | |||
| 主存模块:多 | |||
| 多指令流单数据流MISD | 控制部分:多 | 没有实际意义 | 目前没有,有文献称流水线计算机称此类 |
| 处理器:1 | |||
| 主存模块:多 | |||
| 多指令流多数据MIMD | 控制部分:多 | 能够实现作业、任务、指令等各级全面并行 | 多处理机系统、多计算机 |
| 处理器:多 | |||
| 主存模块:多 |
| 指令系统类型 | 指令 | 寻址方式 | 实现方式 | 其他 |
|---|---|---|---|---|
| CISC(复杂) | 数量多,使用频率差别大,可变长格式 | 支持多种 | 微程序控制技术 | 研制周期长 |
| RISC(精简) | 数量少,使用频率接近,定长格式,大部分为单周期指令,操作寄存器,只有Load/Store操作内存 | 支持方式少 | 增加了通用寄存器,硬布线逻辑控制为主,适合采用流水线 | 优化编译,有效支持高级语言 |
以下关于CISC(Complex Instruction Set Computer, 复杂指令集计算机)和RISC(Reduced Instruction Set Computer, 精简指令集计算机)的叙述中,错误的是 (2) 。(2009年下半年)
A. 在CISC中,其复杂指令都采用硬布线逻辑来执行
B. 采用CISC技术的CPU,其芯片设计复杂度更髙
C. 在RISC中,更适合采用硬布线逻辑执行指令
D. 采用RISC技术,指令系统中的指令种类和寻址方式更少
A
(5) 不是RISC的特点。(2013年下半年)
A. 指令种类丰富 B. 高效的流水线操作
C. 寻址方式较少 D. 硬布线控制
A
以下关于RISC和CISC的叙述中,不正确的是 (5) 。(2014年下半年)
A. RISC通常比CISC的指令系统更复杂
B. RISC通常会比CISC配置更多的寄存器
C. RISC编译器的子程序库通常要比CISC编译器的子程序库大得多
D. RISC比CISC更加适合VLSI工艺的规整性要求
A
CISC是 (6) 的简称。(2015年下半年)
A. 复杂指令集系统计算机 B. 超大规模集成电路
C. 精简指令集系统计算机 D. 超长指令字
A
以下关于RISC(精简指令系统计算机)技术的叙述中,错误的是 (6) 。(2019年上半年)
A. 指令长度固定、指令种类尽量少
B. 指令功能强大、寻址方式复杂多样
C. 增加寄存器数目以减少访问次数
D. 用硬布线电路实现指令解码,快速完成指令译码
B
以下关于RISC和CISC计算机的叙述中,正确的是 (2) 。(2021年上半年)
A. RISC不采用流水线技术,CISC采用流水线技术
B. RISC使用复杂的指令,CISC使用简单的指令
C. RISC采用很少的通用寄存器,CISC采用很多的通用寄存器
D. RISC采用组合逻辑控制器,CISC普遍采用微程序控制器
D
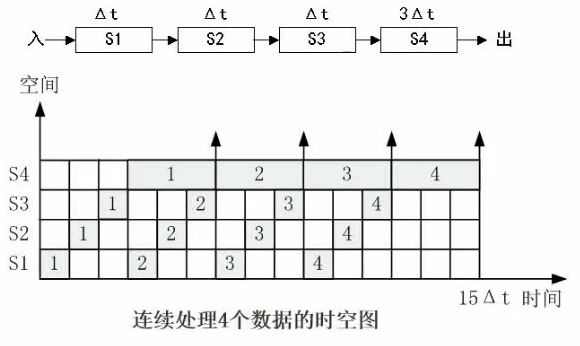
5. 流水线(必考计算)
取指➡️分析➡️执行
例:若指令流水线把一条指令分为取指、分析和执行三部分,且三部分的时间分别是取指2ns,分析2ns,执行1ns,那么流水线周期是多少?100条指令全部执行完毕需要时间?(实际做题优先算理论时间)
1. 周期/执行时间
周期 = 执行时间段最长的一段时间
执行时间:
理论公式 = 1条指令完整时间 + (指令条数 - 1) * 周期
实际公式 = (指令步骤数 + 指令条数 - 1) * 周期
周期2ns
理论时间=5+(100-1)*2=203
实际时间=(3+100-1)*2=204
2. 吞吐率
在时间单位内流水线所完成的任务数量或输出的结果数量
计算公式:TP=指令条数/流水线执行时间
最大吞吐率=1/流水线周期 (忽略了流水线建立时间比执行多消耗的时间,当指令条数n趋近无穷,n/(k+n-1)周期)=1/周期
TP=100/203
最大吞吐率=1/2
3. 加速比
不使用流水线的时间/使用流水线执行时间
500/203
4. 效率
在时空图上,使用流水线后n个任务占用时空区/k个流水段的总时空(阴影部分面积/占用总面积)
例如:效率E=24/60=0.4
6. 层次化存储结构
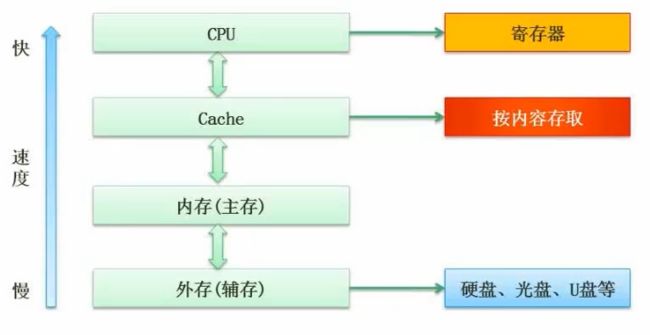
内存存储外存的部分内容,cache存储内存的部分内容,CPU处理cache中的指令,cache的作用是精简内存中重复出现的指令,大幅提高CPU的执行效率,使得计算机的运算速度得到极大的提升。结构中由上至下,速度越来越慢,但容量越来越大。
7. cache
功能:提高CPU输入输出的速率,突破冯·诺依曼瓶颈,即CPU与存储器系统间数据传送带宽限制。
在计算机的存储体系中,cache是访问速度最快的层次。
使用cache改善系统性能的依据是程序的局部性原理。
计算:h为cache访问命中率,t1为cache周期时间,t2为主存储器周期时间,以读操作为例,使用cache+主存储器的系统平均时间t3为:(1-h)又称失效率、未命中率,如果未命中cpu会再去内存调用
t3 = h*t1 + (1-h)*t2
8. 局部性原理
1. 时间局部性
例子:刚刚访问完的指令再次访问
循环体里的s+=j会执行一百万次,如果每次执行都从cache里取数据而不是内存,速度就会提升;
int i,s=0;
for(i=1;i<1000:i++)
for(j=1;j<1000;j++)
s+=j
printf("%d",s);
2. 空间局部性
数组初始化为0,操作的都是临近空间,当程序访问到了一个空间又立即访问临近空间时,称为空间局部性
3. 工作集理论:工作集是进程运行时被频繁访问的页面集合
把要频繁访问的页面集合打包,让要频繁访问的一起调用
9. 主存
随机存储器RAM:断电清除数据
只读存储器ROM:断电仍存储信息。如bios芯片
主存编址:把许多芯片组成相应的存储器

两块8*4位的芯片可以组成图2,3
**例题:**内存地址从AC000H到C7FFFH,共有?K地址单元,如果该内存地址按字(16bit)编址,由28片存储芯片构成。已知构成此内存的芯片每片由16K个存储单元,则该芯片每个存储单元存储?位。
地址单元(K=1024) = C7FFFH+1-AC000H=1C000=(1*16^4 + 12*16^3)/1024=112
设美每个存储单元存储X位
112K*16 / 28*16K*X = 1
求得每个存储单元存储X=4
10. 磁盘结构与参数
存取时间 = 寻道时间 + 等待时间(平均定位时间+转动延迟)
注意:寻道时间时指磁头移动到磁道所需的时间;等待时间为等待读写的扇区转到磁头下方所用的时间。
例题:
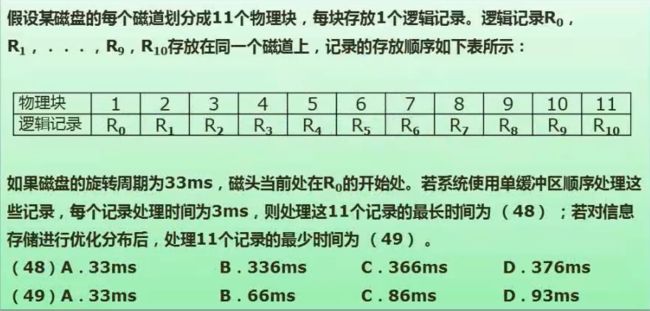
如下图顺序放置R0到R10
最长时间:转一圈为33ms,读取一个记录则是33/11=3ms;单缓冲区表示每读取一个就需要处理一次花费3ms,而在磁盘等待处理的过程中不会停止,它仍会匀速旋转运动,等R0处理完时磁盘已经转到R2位置,所以磁盘下一个要读取R1需要再转动到R2,正好一圈33ms,后面每一个记录同理知道最后一位,所以处理一个区域时间时33+3=36ms;R0到R9花费时间=36*10=360ms,最后一位R10花费6ms(因为R9已经包含了找10的时间,直接读取时间加处理时间就可以了),共366ms。
最短时间:优化后最优可以如下读取R0加处理6ms,然后正好定位到R1后面同理,共花费66ms。
11. 总线
内部总线:微机内部芯片之间
系统总线:数据总线、地址总线、控制总线;数据总线如32、64位,一次能传输到数据(地址总线则表示地址空间)为232、264
外部总线:外部设备之间
12. 系统可靠性分析与设计
1. 串联系统与并联系统
串联系统:一个子系统故障,整个系统失效
可靠度R = R1*R2*…*Rn
失效率U=U1+U2+…+Un
失效率公式是近似的,并不准确
并联系统:所有子系统同时失效才失效
可靠度R=1-(1-R1)*(1-R2)*…*(1-Rn)
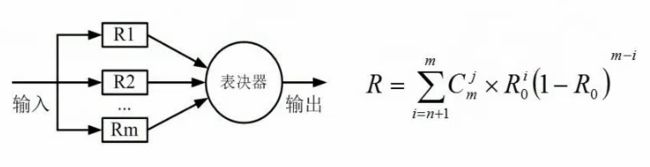
2. 冗余系统与混合系统(现在很少考)
输出结果通过表决器少数服从多数
**3. 例题:**串联和并联混合的系统求可靠度
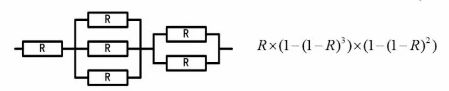
R * (1-(1-R)^3) * (1-(1-R)^2)
13. 差错控制——CRC与海明校验码
码距:整个编码系统中任意两个码字的最小距离
码距=2,检错能力;码距>=3,才可能有纠错能力
增大码距可以检错、纠错
0. 奇偶校验吗,让二进制数1的个数保持奇数或偶数个;不管哪种都只能检测出奇数位出错
1. 循环冗余校验码CRC
例:原信息编码为1010001101,多项式g(x) = x^5 + x^4 + x^2 + 1
a.多项式二进制CRC码设为:110101
b.多项式最高幂次为5,则校验码有5位,需补5位0。新原编码:101000110100000
c.新原编码除以CRC码,CRC校验码为:01110
相除采用模二除法:在出发运算过程中不计进位

2. 海明校验码
记住公式基本可以应付大多数真题
海明码是一种利用奇偶性来差错和纠错的校验方法。海明码的构成方法是在数据位之间的特定位置插入K个校验位,通过扩大码距来实现检错和纠错。
假设数据位是n位,校验位是k位,则n和k的关系必须满足以下关系:
2^k -1 >= n+k
依据给定的数据位,很容推断到校验位。
例子:原始数据:1011
这样 n=4 , 将 k=1,2,3,… 从小到大代入公式发现 k=3就满足条件,2^3-1 >=4+3
所以校验码位数为3位,数据和校验码一共7位。
校验码的位置都处在2的n(n=0,1,2,3…)次方中,即位于1,2,4,8,16…的位置上,其余为才能填充数据。
本例就7位数据组成:D4D3D2D1+P2P1P0
| 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|
| D4 | D3 | D2 | P2 | D1 | P1 | P0 |
| 1 | 0 | 1 | 0 | 1 | 0 | 1 |
7=4+2+1 ==> 第4位 P2,第2位P1,第1位 P0 这3个校验位共同校验
6=4+2==> 第4位 P2,第2位P1 这2个校验位共同校验
5=4+1 ==> 第4位 P2,第1位 P0 这2个校验位共同校验
3=2+1 ==> 第2位P1,第1位 P0 这2个校验位共同校验
校验码计数,异或运算:
P2 = D7D6D5=101=0
P1=D7D6D3=101=0
P0=D7D5D3=111=1
校验码为:001
传输数据为: 1 0 1 0 1 0 1
检错和纠错原理
接收方依据同样的规则重新计算三位校验码的值(由于校验码都在2^n,取数据很容易)。而后与接收到的校验码进行异或。当数据无误时,产生的校验码无误,若接收到的校验码有误,那么这不同的2个校验码异或,必然为1.
若某位的校验码最终异或结果为1,则表示产生了错误,找出错误位之后,就可以纠错了,纠错方法就时将该位逆转。
例如:收到的数据计算出校验位001,而收到的校验吗100
001异或100 = 101 -> 转为10进制5,第5位出错将其数据取反

C
以下关于校验码的叙述中,正确的是 (5) 。(2009年下半年)
A. 海明码利用多组数位的奇偶性来检错和纠错
B. 海明码的码距必须大于等于1
C. 循环冗余校验码具有很强的检错和纠错能力
D. 循环冗余校验码的码距必定为1
A
以下关于海明码的叙述中,正确的是 (5) 。(2017年下半年)
A. 海明码利用奇偶性进行检错和纠错
B. 海明码的码距为1
C. 海明码可以检错但不能纠错
D. 海明码中数据位的长度与校验位的长度必须相同
A
以下关于采用一位奇校验方法的叙述中,正确的是 (5) 。(2018年下半年)
A. 若所有奇数位出错,则可以检测出该错误但无法纠正错误
B. 若所有偶数位出错,则可以检测出该错误并加以纠正
C. 若有奇数个数据位出错,则可以检测出该错误但无法纠正错误
D. 若有偶数个数据位出错,则可以检测出该错误并加以纠正
C
海明校验码是在n个数据位之外增设k个校验位,从而形成一个k+n位的新的码字,使新的码字的码距比较均匀地拉大。n与k的关系是 (1) 。(2009年上半年)
(1) A. 2k - 1 ≥ n + k B. 2n - 1≤ n + k
C. n=k D. n-1≤k
A
海明码利用奇偶性检错和纠错,通过在n个数据位之间插入k个校验位,扩大数据编码的码距。若n=48,则k应为 (3) 。(2014年上半年)
(3) A. 4 B. 5 C. 6 D. 7
C
已知数据信息为16位,最少应附加 (4) 位校验位,以实现海明码纠错。(2016年下半年)
(4) A. 3 B. 4 C. 5 D. 6
C
己知数据信息为16位,最少应附加 (5) 位校验位,才能实现海明码纠错。(2017年上半年)
(5) A. 3 B. 4 C. 5 D. 6
C

D、B;校验位都在2n上,从右到左开始排…3,2,1,D5(10位) = P4(8位) + P2(2位)
循环冗余校验码(CRC)利用生成多项式进行编码。设数据位为k位,校验位为r位,则CRC码的格式为 (2) 。(2012年下半年)
A. k个数据位之后跟r个校验位
B. r个校验位之后跟k个数据位
C. r个校验位随机加入k个数据位中
D. r个校验位等间隔地加入k个数据位中
A
在 (5) 校验方法中,采用模2运算来构造校验位。(2019年上半年)
A. 水平奇偶 B. 垂直奇偶
C. 海明码 D. 循环冗余
D