Go语言之map
Go中的map简单理解
映射是将键映射到值。
key<->value
这样大体看就跟python中字典的定义很像
且映射有如下特点:
映射的零值为 nil 。
nil 映射既没有键,也不能添加键。
make 函数会返回给定类型的映射,并将其初始化备用。
我们先看go官方文档给出的例子:
package main
import"fmt"
type Vertex struct{
Lat,Long float64
}
var m map[string]Vertex//在里我们先将其定义
func main(){
m = make(map[string]Vertex)//将其make
m["Bell Labs"] = Vertex{//赋值
40.68433,-74.39967,
}
fmt.Printlb(m["Bell Labs"])//换行输出
}
这里的输出为{40.68433,-74.39967}
我们可以看到映射的文法与结构体相似,不过必须有键名
映射 m对其元素进行修改
在映射 m 中插入或修改元素:
m[key] = elem
获取元素:
elem = m[key]
删除元素:
delete(m, key)
通过双赋值检测某个键是否存在:
elem, ok = m[key]
若 key 在 m 中,ok 为 true ;否则,ok 为 false。
若 key 不在映射中,那么 elem 是该映射元素类型的零值。
同样的,当从映射中读取某个不存在的键时,结果是映射的元素类型的零值。
若 elem 或 ok 还未声明,你可以使用短变量声明:
elem, ok := m[key]
Go中map的深层理解
以下转自https://www.cnblogs.com/CJ-cooper/p/15150620.html
写的详细且明白
map底层是由哈希表实现的
Go使用链地址法来解决键冲突。
当两个key落在了同一个桶中,这时就发生了哈希冲突。go的解决方式是链地址法:在桶中按照顺序寻到第一个空位,若有位置,则将其置于其中;否则,判断是否存在溢出桶,若有溢出桶,则去该桶的溢出桶中寻找空位,如果没有溢出桶,则添加溢出桶,并将其置溢出桶的第一个空位。
底层结构
map本质上是一个指针,指向hmap

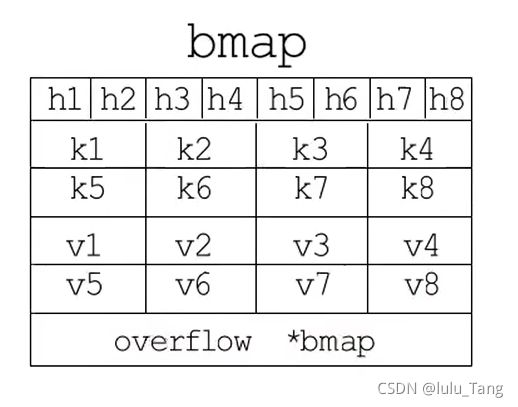
这里的buckets就是桶,bmap
每一个bucket最多可以放8个键值对,但是为了让内存排列更加紧凑,8个key放一起,8个value放一起。在8个key前面是8个tophash,每个tophash都是对应哈希值的高8位,最后由一个overflow字段指向下一个bmap,就是溢出桶。溢出桶内存布局和常规桶一样,bmap内存布局如图
如果哈希表要分配的桶的数目大于 2^4 ,就会预分配 2^(B-4)个溢出桶备用。
这些溢出桶和常规桶在内存中是连续的,前2^B个用作常规桶,后面的用作溢出桶
查找过程
1. 查找或者操作map时,首先key经过hash函数生成hash值
2. 通过哈希值的低8位来判断当前数据属于哪个桶(bucket)
3. 找到bucket以后,通过哈希值的高八位与bucket存储的高位哈希值循环比对
4. 如果相同就比较刚才找到的底层数组的key值,如果key相同,取出value。
5. 如果高八位hash值在此bucket没有,或者有,但是key不相同,就去链表中下一个溢出bucket中查找,直到查找到链表的末尾。
6. 如果查找不到,也不会返回空值,而是返回相应类型的0值。
插入过程
新元素插入过程如下:
1. 根据key值算出哈希值
2. 取哈希值低位与hmap.B取模确定bucket位置
3. 查找该key是否已经存在,如果存在则直接更新值
4. 如果没找到将key,将key插入。
map扩容机制
为了保证访问效率,当新元素将要添加进map时,都会检查是否需要扩容,扩容实际上是以空间换时间的手段。
触发扩容的条件有二个:
1. 负载因子 > 6.5时,也即平均每个bucket存储的键值对达到6.5个。
2. 溢出桶(overflow)数量 > 2^15时,也即overflow数量超过32768时。
其中:
负载因子 = 键数量/bucket数量
增量扩容
如果负载因子>6.5时,进行增量扩容。这时会新建一个桶(bucket),新的bucket长度是原来的2倍,然后旧桶数据搬迁到新桶。每个旧桶的键值对都会分流到两个新桶中
考虑到如果map存储了数以亿计的key-value,一次性搬迁将会造成比较大的延时,Go选择“渐进式扩容”,先分配2倍内存空间的新桶,然后标记当前哈希表正在扩容,每次访问map时都会触发一次搬迁,这样可以把扩容消耗的时间分散到多次操作中。
等量扩容
负载因子没超标,溢出桶较多
1. 如果常规桶数目不大于2^15,那么使用的溢出桶数目超过常规桶就算是多了;
2. 如果常规桶数目大于215,那么使用溢出桶数目一旦超过215就算多了。
所谓等量扩容,就是创建和旧桶数目一样多的新桶,然后把原来的键值对迁移到新桶中,重新做一遍类似增量扩容的搬迁动作。这样做的目的是把松散的键值对重新排列一次,能够存储的更加紧凑,进而减少溢出桶的使用,以使bucket的使用率更高,进而保证更快的存取。
为什么map输出是无序的?
遍历map的时候,取随机数,把桶的遍历顺序随机化。原因是golang底层并没有保证这一点,或许(现在/以后)会有特殊情况出现顺序不固定的情况。担心开发者们误解这一点,golang就特意去打乱了这个顺序,让开发者们知道golang底层不保证map每次遍历都是同一个顺序。
Go的Map本质上是“无序的”
“无序”写入:
- 正常写入(非哈希冲突写入):是hash到某一个bucket上,而不是按buckets顺序写入。
- 哈希冲突写入:如果存在hash冲突,会写到同一个bucket上,更有可能写到溢出桶去
扩容导致无序
- 成倍扩容迫使元素顺序变化,等量扩容并没有改变元素顺序
总结无序原因
- 无序写入
- 成倍扩容迫使元素顺序变化
Map并发问题
原因
go语言中map并不是并发安全的,因为:
map变量为指针类型变量,同时map操作并不是原子操作,并发时多个协程操作同一内存会发生竞争关系,共享资源会遭到破环,因此出于安全考虑,会抛出错误
想要并发安全,可以使用sync.Map,通过互斥锁实现了并发安全
为什么原生map不是并发安全的?
并发安全是有代价的,如果map保证并发安全,那么一些不需要并发的场景,会有不小的性能损耗
练习
前面的知识点是很重要,但是练习是重中之重
我们还是从go的官方文档练习来先做一个简单练习
请看题目:
实现 WordCount。它应当返回一个映射,其中包含字符串 s 中每个“单词”的个数。函数 wc.Test 会对此函数执行一系列测试用例,并输出成功还是失败。
你会发现 strings.Fields 很有帮助
首先分析一下,我们传入一个string类型的字符串s,他是一句话,我们返回的是一个map,输出的是其中单词个数,所以我们的map要这么定义:
map[string]int
然后我们发现官方文档中说了一句话,“你会发现 strings.Fields 很有帮助”,那么我们也简单了解一下这个strings.Fields
func Fields(s string) []string
func main() {
s := "Hello, 世界! Hello!"
ss := strings.Fields(s)
fmt.Printf("%q\n", ss) // ["Hello," "世界!" "Hello!"]
}
那么它是做什么的呢?
Fields 以连续的空白字符为分隔符,将 s 切分成多个子串,结果中不包含空白字符本身
空白字符有:\t, \n, \v, \f, \r, ’ ', U+0085 (NEL), U+00A0 (NBSP)
如果 s 中只包含空白字符,则返回一个空列表
就像例子中输出的那样 我们将
Hello, 世界! Hello!
变成了
["Hello," "世界!" "Hello!"]
那么我们回到题目并完成它:
package main
import (
"golang.org/x/tour/wc"
"strings"
)
func WordCount(s string) map[string]int {
words := strings.Fields(s)//将所有单词全部取出 按单词分隔
m := make(map[string]int)//定义m获得对原输入语句并映射
for _, word := range words {//用range遍历words,且只拿到它的下标所对应元素的一份副本
n, ok := m[word]
//用ok:=m[word]来判断:
//若word在m中,ok 为 true ;得到n
//否则,ok 为 false。若word不在映射中,那么n是该映射元素类型的零值
if ok == false {//如果ok为false,m[word]对应的映射值为1,即单词出现次数为1
m[word] = 1
} else {//如果ok为true,m[word]对应的映射值为n+1,即单词出现次数为n+1
m[word] = n + 1
}
}
return m
}
func main() {
wc.Test(WordCount)
}
最后我们看一看leetcode中与这道题相似的题目吧,也就是第一题twosum,一样先来看题目:
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出和为目标值 target 的那两个整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
同样我们分析题目,我们的输入是一个整数数组 nums [ ]int 和一个整数目标值 target int ,输出是一个数组 [ ]int ,我们跟刚刚上面那个练习一样我们是要在nums中找所以我们需要一个map去得到nums的遍历出的key和value。
我们直接完成练习:
func twoSum(nums []int, target int) []int {//定义输入输出格式
vSet := make(map[int]int)//我们make一个vSet的map来保存遍历出来的key与value
for i1, v := range nums {//遍历nums并得到下标i1和具体值v对应的副本
if i2, ok := vSet[target - v]; ok {//进行判断,如果target-v存在于vSet中,那么我们就得到另一下标i2
return []int{i1, i2}//ok=true我们返回需要的下标i1与i2
}
vSet[v] = i1//我们要得到的是i1所以我们将key=具体值v,value=下标i1
}
return nil//返回nil
}