Go语言中sync.Map、sync.Pool和Context的用法
目录
【sync.Map】
实现线程安全的 map 类型
使用 sync.Map 实现并发读写的map
【sync.Pool】
使用 带缓冲channel 实现对象池
使用 sync.Pool 创建临时对象池
【Context 上下文】
Context应用:实现带超时功能的远程调用
Context应用:监控指令
Context应用:取消关联任务
【sync.Map】
之前在 Go语言中array、slice、map的用法和细节分析_浮尘笔记的博客-CSDN博客 里面说过Go语言内置的map类型的用法,而且当时说过 map 不是并发写安全的,不支持同时并发读写,如果对 map 实例进行并发读写,程序运行时就会抛出异常。比如下面的例子中两个 goroutine 分别操作读和写:
//basic/go03/sync2/map1.go
package main
import (
"fmt"
"time"
)
func test1() {
m := map[int]int{
1: 11,
2: 12,
3: 13,
}
go func() {
for i := 0; i < 1000; i++ {
m[i] = i * i
}
}()
go func() {
for i := 0; i < 1000; i++ {
fmt.Println(m[i])
}
}()
time.Sleep(time.Second)
//执行后报错:fatal error: concurrent map read and map write
}
func main() {
test1()
}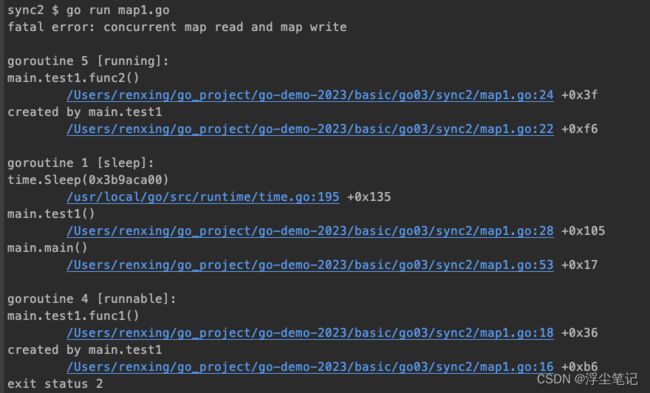
在同一时间段内,让不同的 goroutine 中的代码对同一个map进行读写操作是不安全的,因为map值本身可能会因这些操作而产生混乱,相关的程序也可能会因此发生不可预知的问题。
实现线程安全的 map 类型
在sync.Map出现之前,如果要实现并发安全的map可以使用读写锁(sync.Mutex或sync.RWMutex)来实现原生map的并发读写,比如下面的例子:
//basic/go03/sync2/map2.go
package main
import "sync"
type RWMap struct { // 一个读写锁保护的线程安全的map
sync.RWMutex // 读写锁保护下面的map字段
m map[int]int
}
// 新建一个RWMap
func NewRWMap(n int) *RWMap {
return &RWMap{
m: make(map[int]int, n),
}
}
func (m *RWMap) Get(k int) (int, bool) { //从map中读取一个值
m.RLock()
defer m.RUnlock()
v, existed := m.m[k] // 在锁的保护下从map中读取
return v, existed
}
func (m *RWMap) Set(k int, v int) { // 设置一个键值对
m.Lock() // 锁保护
defer m.Unlock()
m.m[k] = v
}
func (m *RWMap) Delete(k int) { //删除一个键
m.Lock() // 锁保护
defer m.Unlock()
delete(m.m, k)
}
func (m *RWMap) Len() int { // map的长度
m.RLock() // 锁保护
defer m.RUnlock()
return len(m.m)
}
func (m *RWMap) Each(f func(k, v int) bool) { // 遍历map
m.RLock() //遍历期间一直持有读锁
defer m.RUnlock()
for k, v := range m.m {
if !f(k, v) {
return
}
}
}
func test1() {
var m = NewRWMap(10)
go func() {
for {
m.Set(1, 1) //设置key
}
}()
go func() {
for {
m.Get(2) //访问这个map
}
}()
select {}
}
func main() {
test1()
}查询和遍历属于读操作,加读锁;增加、修改、删除属于写操作,加普通的锁。
虽然使用了读写锁可以实现线程安全的 map,但是在大量并发读写的情况下,锁的竞争会非常激烈,从而导致程序可用性下降。
使用 sync.Map 实现并发读写的map
Go 1.9 版本中引入了支持并发写安全的 sync.Map 类型,可以用来在并发读写的场景下替换掉 map。Go语言的官方文档中描述:在以下两个场景中使用 sync.Map,会比使用 map+RWMutex 的方式性能要好得多:(1)只会增长的缓存系统中,一个 key 只写入一次而被读很多次;(2)多个 goroutine 为不相交的键集读、写和重写键值对。
sync.Map 类型提供了一些常用的键值存取操作方法,并保证了这些操作的并发安全。同时它的存、取、删等操作都可以基本保证在常数时间内O(1) 执行完毕,和原生map一样。但是毕竟sync.Map本身也用到了锁,在某些情况下会降低程序的性能。sync.Map 对键的要求是 不能使用函数类型、map类型、切片类型作为键。
sync.Map的数据结构源码:
// $GOROOT/src/sync/map.go
type Map struct {
mu Mutex
// 基本上你可以把它看成一个安全的只读的map
// 它包含的元素其实也是通过原子操作更新的,但是已删除的entry就需要加锁操作了
read atomic.Value // readOnly
// 包含需要加锁才能访问的元素
// 包括所有在read字段中但未被expunged(删除)的元素以及新加的元素
dirty map[interface{}]*entry
// 记录从read中读取miss的次数,一旦miss数和dirty长度一样了,就会把dirty提升为read,并把dirty置空
misses int
}
type readOnly struct {
m map[interface{}]*entry
amended bool // 当dirty中包含read没有的数据时为true,比如新增一条数据
}
// expunged是用来标识此项已经删掉的指针
// 当map中的一个项目被删除了,只是把它的值标记为expunged,以后才有机会真正删除此项
var expunged = unsafe.Pointer(new(interface{}))
// entry代表一个值
type entry struct {
p unsafe.Pointer // *interface{}
}sync.Map主要包含 Store、Load、Delete 这 3 个核心方法,它们都是先从 read 字段中处理的,因为读取 read 字段的时候不用加锁。
- Store 方法:新增或者更新一个键值对,也就是存储一个 key-value 结构的数据。
- Load 方法:根据key获取对应的value值,如果从 read 中读取到了 key 的值就不需要加锁,性能会非常好;但是如果请求的 key 不存在,就需要加锁并从 dirty 中读取,此时会因为加锁而导致性能下降。
- LoadOrStore 方法:如果key对应的value存在则返回这个value;如果不存在则存储对应的key-value数据。
- Delete 方法:读取并删除,如果项目存在就删除 并将它的值标记为 nil;如果 read 中不存在,那么就从 dirty 中寻找这个项目。需要注意 删除一个键值只是打标记,只有在提升 dirty 字段为 read 字段的时候才清理删除的数据。
- Range 方法:循环迭代 sync.Map,相当于原生map的 for ... range 操作。
接下来,使用sync.Map 对上面 basic/go03/sync2/map1.go 改造一下:
//basic/go03/sync2/map1.go
package main
import (
"fmt"
"sync"
"time"
)
func test2() {
var m sync.Map
go func() {
for i := 0; i < 1000; i++ {
m.Store(i, i*i)
}
}()
go func() {
for i := 0; i < 1000; i++ {
data, _ := m.Load(i)
fmt.Println(i, data)
}
}()
time.Sleep(time.Second)
//执行后正确输出
}
func main() {
test2()
}
细节分析:
- 如果 dirty 字段非 nil 的话,map 的 read 字段和 dirty 字段会包含相同的非 expunged 的项,所以如果通过 read 字段更改了这个项的值,从 dirty 字段中也会读取到这个项的新值,因为本来它们指向的就是同一个地址。
- dirty 包含重复项目的好处就是:一旦 miss 数达到阈值需要将 dirty 提升为 read 的话,只需简单地把 dirty 设置为 read 对象即可。不好的一点就是,当创建新的 dirty 对象的时候,需要逐条遍历 read,把非 expunged 的项复制到 dirty 对象中。
- 空间换时间。通过冗余的两个数据结构(只读的 read 字段、可写的 dirty),来减少加锁对性能的影响。对只读字段(read)的操作不需要加锁,优先从 read 字段读取、更新、删除,因为对 read 字段的读取不需要锁。
- sync.Map 所有的方法涉及的键和值的类型都是interface{},也就是空接口,这意味着可以使用任意数据类型,因此在程序中必须要自行保证键类型和值类型的正确性, Go 语言编译器无法在编译期对它们进行检查,不正确的键值实际类型肯定会引发 panic。
【sync.Pool】
Go 是一个自动垃圾回收的编程语言,一般创建对象的时候想创建就创建,用完之后它会自动回收。但是如果想使用 Go 开发一个高性能的应用程序就必须考虑垃圾回收给性能带来的影响。在对程序做性能优化的时候会采用对象池的方式,把不用的对象回收起来,避免被当成垃圾回收掉,这样使用的时候就不必再重新创建了。比如对于数据库连接、TCP 长连接、HTTP连接 这些比较耗时的操作,可以把这些连接保存下来,避免每次使用的时候都重新创建,可以提高应用程序的整体性能。
使用 带缓冲channel 实现对象池
在了解 sync.Pool 之前先看看如何使用一个普通的带缓冲channel来实现对象池,关于带缓冲channel可以参考:Go语言的并发:goroutine和channel_浮尘笔记的博客-CSDN博客
//basic/go03/sync2/pool.go
package main
import (
"errors"
"fmt"
"time"
)
// 可重复使用的对象结构体
type userStruct struct {
name string
age int
}
type ObjPool struct {
bufChan chan *userStruct //用于缓冲可重用对象
}
// 创建并初始化对象池
func NewObjPool(numOfObj int) *ObjPool {
objPool := ObjPool{}
objPool.bufChan = make(chan *userStruct, numOfObj)
for i := 0; i < numOfObj; i++ {
objPool.bufChan <- &userStruct{
//假设提前预置好指定数量的连接信息
//也可以在这里不预置,然后在 PutObj() 操作中再设置连接信息
name: fmt.Sprintf("%v_%d", "user", i),
age: 18,
}
}
return &objPool
}
// 获取对象池中的数据
func (p *ObjPool) GetObj(timeout time.Duration) (*userStruct, error) {
select {
case ret := <-p.bufChan:
return ret, nil
//超时控制,不会让获取对象的地方一直阻塞,达到设定的超时时间后会返回一个错误信息
case <-time.After(timeout):
return nil, errors.New("获取数据超时")
}
}
// 将数据放入到对象池中
func (p *ObjPool) PutObj(obj *userStruct) error {
select {
case p.bufChan <- obj:
return nil
//在某些情况下(比如size已经满了)会出现放不进去,为了防止阻塞,在default分支中抛出一个异常
default:
return errors.New("对象池容量已满")
}
}
func main() {
pool := NewObjPool(5)
//尝试给已满的对象池中继续放入对象
//if err := pool.PutObj(&userStruct{}); err != nil {
// fmt.Println("错误: ", err)
//}
for i := 0; i < 3; i++ {
//设置1秒超时
if v, err := pool.GetObj(time.Second * 1); err != nil {
fmt.Println("获取对象出错: ", err)
} else {
fmt.Printf("%T, %v,%v \n", v, v, pool.bufChan)
if err := pool.PutObj(v); err != nil {
fmt.Println("放入对象出错: ", err)
}
}
}
fmt.Println("完成")
}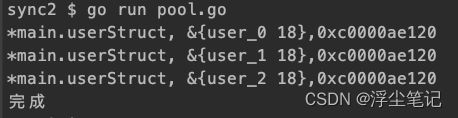
上面的例子使用channel实现了一个简单的用户信息对象池,如果尝试给已满的对象池中继续放入对象(去掉main函数上面部分 pool.PutObj 的注释),就会报错:

如果获取完对象忘记了放回去,并且获取的次数超过了预置的对象池大小,则会进入到获取数据的超时控制部分:
func main() {
pool := NewObjPool(5)
for i := 0; i < 6; i++ {
//设置1秒超时
if v, err := pool.GetObj(time.Second * 1); err != nil {
fmt.Println("获取对象出错: ", err)
} else {
fmt.Printf("%T, %v,%v \n", v, v, pool.bufChan)
//if err := pool.PutObj(v); err != nil {
// fmt.Println("放入对象出错: ", err)
//}
}
}
fmt.Println("完成")
}
使用 sync.Pool 创建临时对象池
sync.Pool 用来保存一组可独立访问的临时对象,这里的“临时对象”是指不需要持久使用的某一类值,这个“临时对象”会在未来的某个时候被移除掉,而且如果没有别的对象引用这个被移除的对象的话,这个被移除的对象就会被垃圾回收掉。sync.Pool临时对象池是线程安全的,可以主要用作数据的缓存;会有锁的开销,因此使用的时候需要衡量是“锁带来的开销大?”还是“创建一个对象池带来的开销大?”。
sync.Pool定义如下:
//$GOROOT/src/sync/pool.go
type Pool struct {
noCopy noCopy
local unsafe.Pointer
localSize uintptr
victim unsafe.Pointer
victimSize uintptr
New func() any
}
func (p *Pool) Put(x any) {}
func (p *Pool) Get() any {}sync.Pool类型有如下方法和字段:
- Put方法:用于在当前的池中存放临时对象,它接受一个interface{}类型的参数,存放的对象可以复用。如果存放一个nil值则会被忽略。
- Get方法:用于从当前的池中获取一个临时对象给调用者 并删除,它会返回一个interface{}类型的值。如果当前池中没有任何值,那么Get 方法会使用New字段创建一个新值并直接将其返回。
- New字段:代表创建临时对象的函数,它的类型是没有参数但有唯一结果的函数类型:func() interface{}。这个函数的结果值不会存入当前的临时对象池中,而是直接返回给Get方法的调用方。这里的New字段的实际值需要在初始化临时对象池的时候就给定,否则调用Get方法的时候就会返回 nil,表示当前没有可用的元素。
看一个简单的例子:
//basic/go03/sync2/pool2.go
package main
import (
"fmt"
"sync"
)
func test1() {
pool := &sync.Pool{
//初始化并放入一个数据
New: func() interface{} {
fmt.Println("创建一个新对象")
return "你好呀"
},
}
fmt.Println(pool.Get()) //获取初始化对象池放入的数据,输出: 你好呀
pool.Put("我很好~") //放入一个新的数据
fmt.Println(pool.Get()) //再次获取池中的数据,输出: 我很好~
}
func main() {
test1()
}
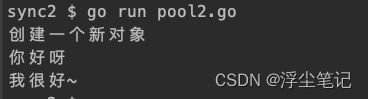
上面的例子可以理解为就是一开始使用 New字段初始化一个池中的数据,然后用 Get方法获取刚才初始化的数据,再然后使用 Put方法给池中放入一个新的数据。如果在Put数据之后使用垃圾回收机制回收了池中的资源,那么刚才Put的数据就被清除了,会再次进入初始化的流程中。代码如下:
//basic/go03/sync2/pool2.go
package main
import (
"fmt"
"sync"
)
func test1() {
pool := &sync.Pool{
//初始化并放入一个数据
New: func() interface{} {
fmt.Println("创建一个新对象")
return "你好呀"
},
}
fmt.Println(pool.Get()) //获取初始化对象池放入的数据,输出: 你好呀
pool.Put("我很好~") //放入一个新的数据
runtime.GC() //人为的触发垃圾回收,清除sync.pool中缓存的对象
fmt.Println(pool.Get()) //再次获取池中的数据,输出: 我很好~
}
func main() {
test1()
}

刚才演示的是在顺序执行的流程中加入了 sync.Pool 的用法, 下面再看看goroutine中sync.Pool 的用法:
//basic/go03/sync2/pool2.go
package main
import (
"fmt"
"sync"
)
func test2() {
pool := &sync.Pool{
New: func() interface{} {
fmt.Println("创建一个新对象")
return "hello"
},
}
pool.Put("golang")
pool.Put("php")
pool.Put("java")
var wg sync.WaitGroup
for i := 0; i < 6; i++ {
wg.Add(1)
go func(id int) {
fmt.Println(pool.Get())
wg.Done()
}(i)
}
wg.Wait()
}
func main() {
test2()
}

上面代码初始化对象池之后放入了3个数据,然后在一个6次的循环中并发的获取池中的数据,已经放入的3个数据被取出来了,另外3次会进入到初始化的流程中。这也验证了上面总结的:如果当前池中没有任何值,那么Get 方法会使用New字段创建一个新值并直接将其返回。
标准库代码包 fmt 就使用到了sync.Pool类型,这个包会创建一个用于缓存某类临时对象的sync.Pool类型值,并将这个值赋给一个名为ppFree的变量。临时对象池ppFree的New字段在被调用的时候,总是会返回一个全新的pp类型值的指针(即临时对象),这就保证了ppFree的Get方法总能返回一个可以包含需要打印内容的值。
在使用 fmt.Println、fmt.Printf 同时执行很多的打印函数调用的时候,ppFree可以及时地把它缓存的临时对象提供给它们,以加快执行的速度。而当程序在一段时间内不再执行打印函数调用时,ppFree中的临时对象又能够被及时地清理掉,以节省内存空间。
//$GOROOT/src/fmt/print.go
var ppFree = sync.Pool{
New: func() any { return new(pp) },
}【问】临时对象池中的值被回收的时机是怎样的?
【答】因为 Go 语言运行时系统中的垃圾回收器,检测到临时对象池以外的代码没有了对它们的引用,那么在稍后的垃圾回收过程中这些临时对象就会被当作垃圾销毁掉,它们占用的内存空间也会被回收。也就是说这个临时对象池的缓存有效期截止到下一次开始垃圾回收之前。
【Context 上下文】
Go 标准库中的 Context 是在 Go 1.7 版本加入到标准库的,它可以理解为一种同步工具,在实现主要业务流程的时候,还能附带着实现一些通用的信息传递,也就是上下文信息,此类值是并发安全的,可以传播给多个 goroutine。Go 标准库中的 database/sql、os/exec、net、net/http、runtime/trace 等包中都使用到了 Context。
Context 还提供了超时(Timeout)和取消(Cancel)的机制。可以使用 Context的场景:上下文信息传递 (request-scoped),比如处理 http 请求、在请求处理链路上传递信息;控制子 goroutine 的运行(比较常用);超时控制的方法调用;可以取消的方法调用。
一个任务会有很多个协程协作完成,一次HTTP请求也会触发很多个协程的启动,如果因为某些原因导致任务终止了,HTTP请求取消了,那么它们启动的协程也应该取消。Context就是用来简化解决这些问题的,并且是并发安全的。Context是一个接口,它具备手动、定时超时发出取消信号、传值等功能,主要用于控制多个协程之间的协作,尤其是取消操作。
Context 包含四个方法:Deadline、Done、Err、Value,同时实现了 2 个常用的生成顶层 Context 的方法。Context的定义如下:
//$GOROOT/src/context/context.go
type Context interface {
// 获取 Context 被取消的截止时间,如果没有设置截止时间 则 ok 的值是 false;后续每次调用这个对象的 Deadline 方法时,都会返回和第一次调用相同的结果。
Deadline() (deadline time.Time, ok bool)
// 返回一个 Channel 对象,在 Context 被取消时,此 Channel 会被 close,如果没被取消,可能会返回 nil,后续的 Done 调用总是返回相同的结果。
// 当 Done 被 close 的时候,可以通过 ctx.Err 获取错误信息。
Done() <-chan struct{}
// 如果 Done 没有被 close,Err 方法返回 nil;如果 Done 被 close,Err 方法会返回 Done 被 close 的原因。
Err() error
// 返回此 ctx 中和指定的 key 相关联的 value
Value(key interface{}) interface{}
}
// Context 中实现了 2 个常用的生成顶层 Context 的方法。
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
// 返回一个非 nil 的、空的 Context,没有任何值,不会被 cancel,不会超时,没有截止日期。
// 一般用在主函数、初始化、测试以及创建根 Context 的时候。
func Background() Context {
return background
}
// 返回一个非 nil 的、空的 Context,没有任何值,不会被 cancel,不会超时,没有截止日期。
// 当你不清楚是否该用 Context,或者目前还不知道要传递一些什么上下文信息的时候,就可以使用这个方法。
func TODO() Context {
return todo
}context 中的四个特殊方法:WithValue、WithCancel、WithTimeout、WithDeadline。
//$GOROOT/src/context/context.go
// 产生一个可撤销的parent的子值,返回 parent 的副本,只是副本中的 Done Channel 是新建的对象,它的类型是 cancelCtx。
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {}
// 基于 parent Context 生成一个新的 Context,保存了一个 key-value 键值对,常常用来传递上下文。
func WithValue(parent Context, key, val any) Context {}
// WithTimeout 是超时时间,用来产生一个会定时撤销的parent的子值。
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {}
// WithDeadline 是截止时间,超时时间 + 当前时间 = 截止时间
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc) {}
Context应用:实现带超时功能的远程调用
比如访问一个远程服务的时候出现了超时,那么可以在 Context 被 cancel 的时候断开服务器连接,这样能减少对服务调用的压力。比如下面的代码:
package main
import (
"context"
"fmt"
"time"
)
func test1() {
ctx, cancel := context.WithCancel(context.Background())
go func() {
defer func() {
fmt.Println("goroutine已退出,已断开远程服务连接")
}()
for {
select {
case <-ctx.Done():
return
default:
time.Sleep(time.Second)
}
}
}()
time.Sleep(time.Second)
cancel()
time.Sleep(2 * time.Second)
}
func main() {
test1()
}Context应用:监控指令
还有一个场景,比如有一个监控进程一直在不停的监控后台数据是否有异常,可以使用context来发送停止监控的指令。代码如下:
// basic/go03/context/demo3.go
package main
import (
"context"
"log"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
wg.Add(1)
ctx, stop := context.WithCancel(context.Background())
go func() {
defer wg.Done()
watchData(ctx, "监控1")
}()
time.Sleep(time.Second * 3) //先监控3秒钟
stop() //发送停止的信号
wg.Wait()
}
func watchData(ctx context.Context, name string) {
//死循环中一直监控后台数据
for {
select {
case <-ctx.Done():
log.Println(name, "已收到停止监控的指令,不再监控")
return
default:
log.Println(name, "正在监控中...")
}
time.Sleep(time.Second)
}
}
Context应用:取消关联任务
上面例子演示了监控单个goroutine的示例,下面再扩展一下,如何监控多个goroutine。比如有这样一个场景:在启动了多个存在父子关联关系的任务(协程)之后,取消掉某一个节点的任务,需要对应的节点和它的所有子任务都被取消,如下图所示:

使用context可以很方便的实现这个功能,代码如下:
// basic/go03/context/demo2.go
package main
import (
"context"
"fmt"
"time"
)
func isCancelled(ctx context.Context) bool {
select {
// <-ctx.Done() 表示接收到了取消的通知信号,此时所有的子Context都会被取消
case <-ctx.Done():
return true
default:
return false
}
}
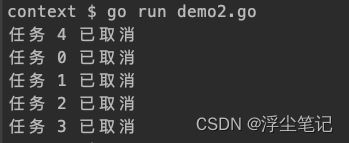
func main() {
// 通过 context.Background() 创建一个 根Context
// 通过 context.WithCancel(根Context) 创建子Context, 返回一个用于触发撤销信号的函数
ctx, cancel := context.WithCancel(context.Background())
for i := 0; i < 5; i++ {
go func(i int, ctx context.Context) {
for {
if isCancelled(ctx) {
break
}
time.Sleep(time.Millisecond * 5)
}
fmt.Println("任务", i, "已取消")
}(i, ctx)
}
//调用 触发撤销信号的函数
cancel()
time.Sleep(time.Second * 1)
}
一般使用Context的原则:
- Context不要放在结构体中,要以函数的方式传递;当函数使用 Context 的时候,会把这个参数放在第一个参数的位置。
- 使用 context.Background() 创建一个空的上下文对象(根节点),使用With系列函数生成Context树,把相关的Context关联起来。
- Context 只是用来临时做函数之间的上下文透传,不能持久化 Context 或者把 Context 长久保存,不要把 Context 持久化到数据库、本地文件或者全局变量中。
- key 的类型不应该是字符串类型或者其它内建类型,否则容易在包之间使用 Context 时候产生冲突。使用 WithValue 时,key 的类型应该是自己定义的类型。
- 常常使用 struct{} 作为底层类型定义 key 的类型,对可导出 key 的静态类型,常常是接口或者指针,这样可以尽量减少内存分配。
源代码:https://gitee.com/rxbook/go-demo-2023/tree/master/basic/go03/sync2