深入分析APK文件格式
前言
最近在升级项目的 Gradle 及 AGP 版本,在进行APK编辑再压缩时遇到了前后压缩比不一致的问题,所以抽空又一总结了下 APK (ZIP) 文件格式。
无论是使用 7z 进行包体积优化,或是快速构建多渠道包,又或是V2、V3签名等都是基于 APK (ZIP) 文件格式进行的,因此对 APK (ZIP) 格式的了解也颇为必要 。
ZIP文件格式
未进行(V2、V3)签名的 APK 就是一个标准的 ZIP 文件,所以本文会先介绍 ZIP 文件格式,后续再介绍签名后的 APK 与 标准 ZIP 文件有何差异。
首先看看 ZIP 文件格式预览:
[local file header 1]
[file data 1]
[data descriptor 1]
.
.
.
[local file header n]
[file data n]
[data descriptor n]
[central directory]
[end of central directory record]
对结构描述并划分一下,看起来清晰很多:
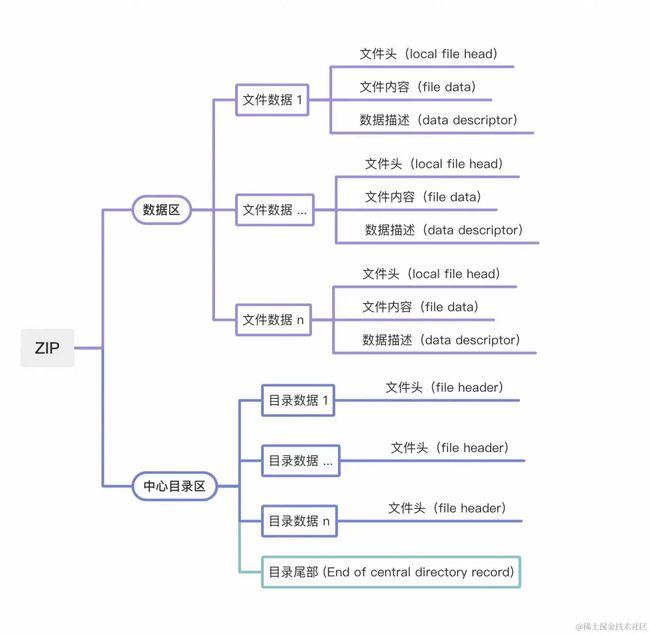
ZIP 文件由两大区块组成:数据区、中心目录区
下面分别介绍一下两大区块:
数据区
先看数据区,数据区可以理解为一个数组,数组的每一项由 [local file header][file data][data descriptor] 这三项组成。
Local file header
首先看看 local file header (文件头) 的结构定义:
| Offset | Bytes | Description | |
|---|---|---|---|
| 0 | 4 | Local file header signature | 标识 (0x04034b50) |
| 4 | 2 | Version needed to extract | 解压文件所需 pkware最低版本 |
| 6 | 2 | General purpose bit flag | 通用比特标志位 |
| 8 | 2 | Compression method | 压缩方式 |
| 10 | 2 | File last modification time | 文件最后修改时间 |
| 12 | 2 | File last modification date | 文件最后修改日期 |
| 14 | 4 | CRC-32 | CRC-32校验码 |
| 18 | 4 | Compressed size | 压缩后的大小 |
| 22 | 4 | Uncompressed size | 未压缩的大小 |
| 26 | 2 | File name length (n) | 文件名长度 |
| 28 | 2 | Extra field length (m) | 扩展区长度 |
| 30 | n | File name | 文件名 |
| 30+n | m | Extra field | 扩展区 |
这里需要注意的是每个 Entry 的文件头 都有自己的 Compression method —— 压缩方式,也就是说 ZIP 文件内的不同 Entry 可以选择不同的压缩方式,并不要求里面的文件都采用同一种压缩方式。
不同的压缩方式对应不同的值,具体如下:
compression method: (2 bytes)
(see accompanying documentation for algorithm
descriptions)
0 - The file is stored (no compression)
1 - The file is Shrunk
2 - The file is Reduced with compression factor 1
3 - The file is Reduced with compression factor 2
4 - The file is Reduced with compression factor 3
5 - The file is Reduced with compression factor 4
6 - The file is Imploded
7 - Reserved for Tokenizing compression algorithm
8 - The file is Deflated
9 - Enhanced Deflating using Deflate64(tm)
10 - PKWARE Data Compression Library Imploding
11 - Reserved by PKWARE
12 - File is compressed using BZIP2 algorithm
APK中,使用的是 0-Stored (不压缩)和 8-Deflated (Deflated 压缩算法压缩) 。
File data
Flie data 则是文件压缩或直接存储后的二进制数据。
Data descriptor
Data descriptor 区块,只有通用比特标志位的第三位bit为1时才会出现此区块。
Data descriptor:
crc-32 4 bytes
compressed size 4 bytes
uncompressed size 4 bytes
This descriptor exists only if bit 3 of the general
purpose bit flag is set (see below). It is byte aligned
and immediately follows the last byte of compressed data.
This descriptor is used only when it was not possible to
seek in the output .ZIP file, e.g., when the output .ZIP file
was standard output or a non seekable device. For Zip64 format
archives, the compressed and uncompressed sizes are 8 bytes each.
案例展示
进过上面的理论学习,接下来可以找个APK瞅瞅;
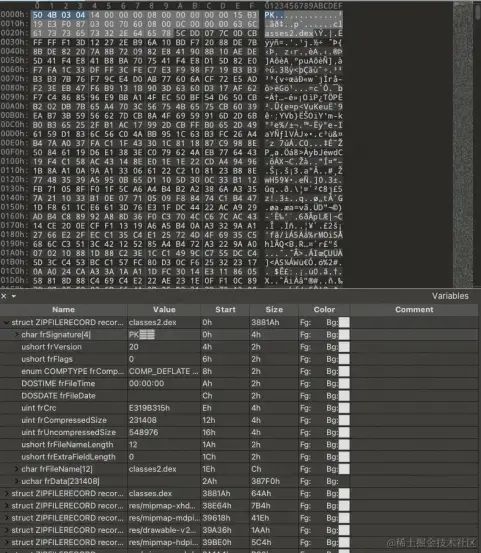
可以看出:在该APK文件中,classes2.dex 文件的压缩方式为 0x0008 (Deflated)。
中心目录区
在 ZIP 文件中,数据区后面紧接着的就是中心目录区,ZIP 里的每个文件 (Entry) 在数据区和中心目录区都分别有一条对应的数据记录 (File Record) 和目录记录 (Dir Record)。(完成V2、V3签名的 APK 中,签名区块则位于数据区与中心目录区之间,签名区块这一点单独讲,先看看中心目录区。)
中心目录区由多条目录文件头 (Fille header) 和一条目录尾部 (End of central directory record) 组成,
File header
Fille header 格式定义如下:
| Offset | Bytes | Description | |
|---|---|---|---|
| 0 | 4 | Central directory file header | 标识(0x02014b50) |
| 4 | 2 | Version made by | 压缩所用的pkware版本 |
| 6 | 2 | Version needed to extract | 解压所需pkware的最低版本 |
| 8 | 2 | General purpose bit flag | 通用位标记 |
| 10 | 2 | Compression method | 压缩方法 |
| 12 | 2 | File last modification time | 文件最后修改时间 |
| 14 | 2 | File last modification date | 文件最后修改日期 |
| 16 | 4 | CRC-32 | CRC-32校验码 |
| 20 | 4 | Compressed size | 压缩后的大小 |
| 24 | 4 | Uncompressed size | 未压缩的大小 |
| 28 | 2 | File name length (n) | 文件名长度 |
| 30 | 2 | Extra field length (m) | 扩展域长度 |
| 32 | 2 | File comment length (k) | 文件注释长度 |
| 34 | 2 | Disk number start | 文件开始位置的磁盘编号 |
| 36 | 2 | Internal file attributes | 内部文件属性 |
| 38 | 4 | External file attributes | 外部文件属性 |
| 42 | 4 | relative offset of local header | 数据文件头的偏移地址 |
| 46 | n | File name | 文件名 |
| 46+n | m | Extra field | 扩展域 |
| 46+n+m | k | File comment | 文件注释内容 |
从 File header 的格式定义中不难看出:目录区文件头比数据区文件头多了几个字段,例如:数据文件头的偏移地址。其他字段基本是重复的。
目录记录 (Dir Record) 只有文件头,因此比起 数据记录 (File Record) 要小很多,解析起来也比较快,所以通过中心目录区可以快速获取压缩文件部分信息而不用解析整个 ZIP ,例如:ZIP 中是否含有某个文件。
同时目录记录里包含了对应的文件记录的偏移量,这样能通过目录快速定位并解压 ZIP 内的单个文件,避免从数据区从头遍历解析。
案例展示
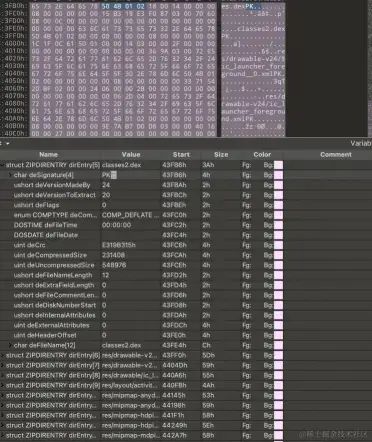
End of central directory record
上面提到,通过中心目录区可以优化数据的查找和解析过程,那如何快速知道中心目录区的起始位置呢?
目录尾部对中心目录进行了简要描述,中心目录区的起始位置就在目录尾 (End of central directory record) 当中,其格式如下:
| Offset | Bytes | Description | |
|---|---|---|---|
| 0 | 4 | End of central dir signature | 标记(0x06054b50) |
| 4 | 2 | Number of this disk | 当前磁盘编号 |
| 6 | 2 | Number of the disk with the start of the central directory | 中心目录开始位置的磁盘编号 |
| 8 | 2 | Total number of entries in the central directory on this disk | 该磁盘上所记录的中心目录数量 |
| 10 | 2 | Total number of entries in the central directory | 中心目录总数 |
| 12 | 4 | Size of central directory (bytes) | 中心目录的大小 |
| 16 | 4 | offset of start of central directory with respect to the starting disk number | 中心目录起始位置偏移量 |
| 20 | 2 | .ZIP file comment length(n) | 注释长度 |
| 22 | n | .ZIP file comment | 注释内容 |
通过目录尾部的中心目录起始位置偏移,能快速获取目录位置。
案例展示

所以很有意思的一点:在某些场景下,ZIP 也可以从后往前解析的,而且能提效。常用的 ZipFile 正是使用了从后往前解析的方式。首先找到尾部,通过尾部,获取中心目录区的偏移量和长度,然后通过中心目录区域信息定位实际的数据区获取最终的数据。
ZipFile
这一步分析可能比较复杂,若阅读困难可以先略过~ 详细过程如下:
1)创建ZipFile文件
这一步主要是从目录尾部获取中心目录起始偏移等信息,并建立目录数据Hash与其起始偏移地址映射关系;
在 ZipFile 的构造函数中会调用 ZipFile#open 函数:
[java.util.zip.ZipFile#open] ->
[xref/libcore/ojluni/src/main/native/zip_util.c#ZIP_Open]->
[xref/libcore/ojluni/src/main/native/zip_util.c#ZIP_Open_Generic] ->
[xref/libcore/ojluni/src/main/native/zip_util.c#ZIP_Put_In_Cache0] ->
[xref/libcore/ojluni/src/main/native/zip_util.c#readCEN]

通过进一步阅读可以了解到 [readCEN]函数中只是对中心目录做了粗略的解析。只有在 getEntry 时才会仔细解析单条目录记录,其解析逻辑如下:
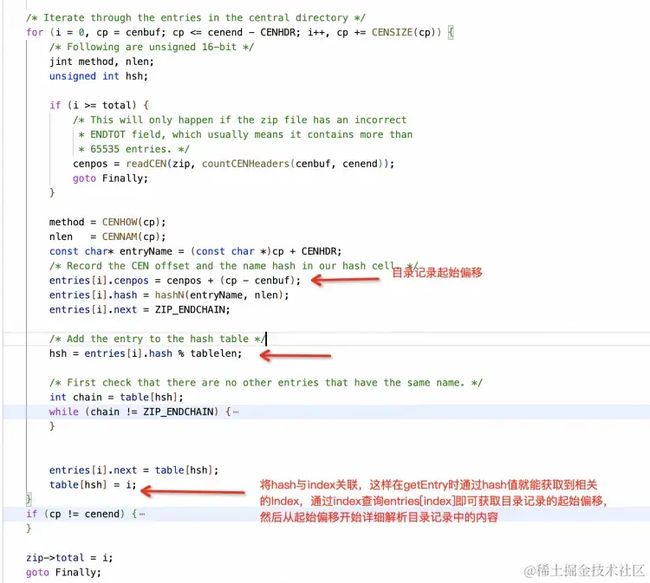
再看看尾部数据获取,从文件末尾查找能与尾部数据标志 0x06064B50 匹配的4个字节。
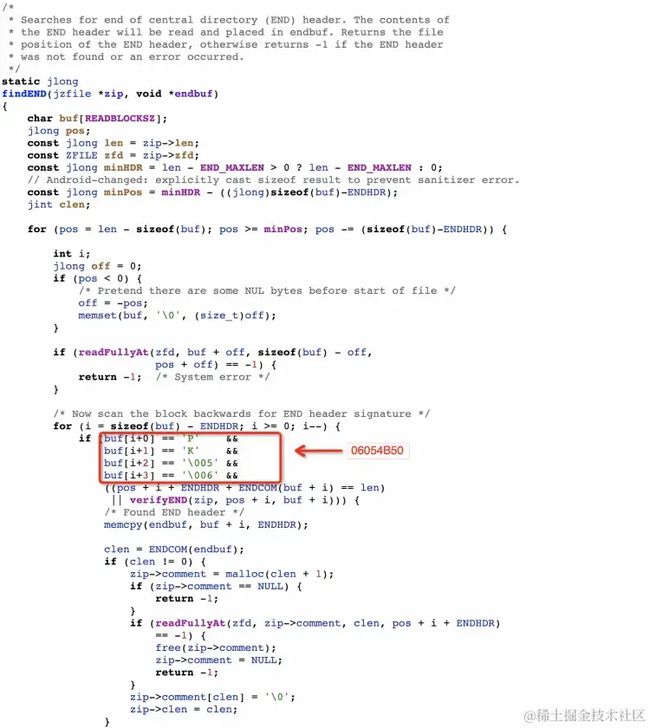
2)通过Hash查找并解析Entry
首先看下 ZipFile#getEntry(String ) 是如何查找并解析出 Entry 的:



今天周末,再深究一下,看看newEntry的解析。

这里就和我们看到头文件(File Header)的字段对应上了,头文件内容基本解析出来并放入ze 对象,ze 对象的指针做为函数的返回值。
看到这里,能体会到 ZipFile 做的优化还是挺细致的,ZipFile 创建的时候只做目录的粗解析,在获取具体 文件(Entry) 信息时只解析需要的头文件,到目前为止只获取了 Entry 基本信息,并没有去解析数据区。
3)二进制数据流读取
再看看 ZipFile 如何获取文件的二进制数据流的?
通过上面的 getEntry,我们已经能拿到 Entry 在中心目录区的头文件对象了,因此java.util.zip.ZipFile#getInputStream(ZipEntry entry)获取数据流时,通过 Entry 对应的指针获取数据记录 (File Record) 的起始地址直接读取数据即可。
[java.util.zip.ZipFile#getInputStream(ZipEntry entry)] ->
[java.util.zip.ZipFile.ZipFileInputStream#read(byte[], int, int)] ->
[xref/libcore/ojluni/src/main/native/java_util_zip_ZipFile.c#ZipFile_read>] ->
[xref/libcore/ojluni/src/main/native/zip_util.c#ZIP_Read]

APK文件格式
前文提到:未进行(V2、V3)签名的 APK 就是一个标准的 ZIP 文件,完成V2、V3签名的 APK 中,签名区块则位于数据区与中心目录区之间。

APK Signing Block
APK 签名区块的结构如下:
| 偏移(Bytes) | 字节数 | 描述 |
|---|---|---|
| A1 | 8 | 签名区块长度(此8字节不计算在内) |
| A1 + 8 | n | 一组或多组ID-Value |
| B1 - 24 | 8 | 签名区块长度 |
| B1 -16 | 16 | 常量标识 “APK Sig Block42” |
A1: 签名区块起始偏移
B2: 中心目录区起始位置
案例展示
1)首先获取目录区域偏移量;
目录尾部标识:06 05 4B 50,中央目录区起始位置偏移量:00 04 4E 7D
2)通过中央目录区偏移量,找到常量标识"APK Sig Block42"及签名区块长度:

同时也能知道签名区块长度为:0F F8;
3)查找 ID-Valuce 的起始位置,以魔术最后一位,前移动 0F F8 :


所以图中的偏移量为 0X043E86 就是ID-Value的起始位。
4)查看 ID-Value 结构:
| 长度(bytes) | |
|---|---|
| ID-Value 字节总数 | 8字节(不包含本身) |
| ID | 4字节 |
| Value | “ID-值”对的长度 - 4 个字节 |
V2 的签名信息存放在 ID = 0x7109871a 的数据块中
V3 的签名信息存放在 ID = 0xf05368c0 的数据块中
- 第一项 ID-Value
- 偏移量:0X043E8D
- 长度:05 6E
- ID:71 09 87 1A

- 第二项 ID-Value
- 偏移量:0x0443FB
- 长度: 0A 62
- ID: 72 42 65 77
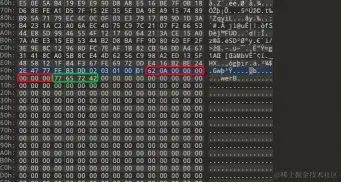
- 第二项最后一位刚好与第二位的区块长度衔接
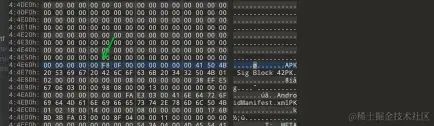
- 不难发现这里的Value字节全为0,这些 0 本身毫无含义,本以为能删除掉缩减一点包体,但是经查询,这里为了使签名区块为4096 的整数倍与内存页对齐(同时高版本 Android 会检测这个对齐规则,不可删除)。

部分团队的多渠道APK方案,则是在签名区块中加入额外的 ID-Value ,通常是固定一个 ID,Value设置为渠道信息即可。
小结
至此完成部分了 ZIP 及 APK 文件的格式分析,另外 ZIP 相关的其他知识点也比较繁多,很难说一篇文章能盖全,或全面了解,例如各类压缩算法、ZIP 版本差异以及 7z (后续计划讲下 7z ) 等等,但是能掌握到文中介绍的这些,也足以解决日常遇到的绝大多 ZIP 相关问题了。
Android 学习笔录
Android 性能优化篇:https://qr18.cn/FVlo89
Android Framework底层原理篇:https://qr18.cn/AQpN4J
Android 车载篇:https://qr18.cn/F05ZCM
Android 逆向安全学习笔记:https://qr18.cn/CQ5TcL
Android 音视频篇:https://qr18.cn/Ei3VPD
Jetpack全家桶篇(内含Compose):https://qr18.cn/A0gajp
OkHttp 源码解析笔记:https://qr18.cn/Cw0pBD
Kotlin 篇:https://qr18.cn/CdjtAF
Gradle 篇:https://qr18.cn/DzrmMB
Flutter 篇:https://qr18.cn/DIvKma
Android 八大知识体:https://qr18.cn/CyxarU
Android 核心笔记:https://qr21.cn/CaZQLo
Android 往年面试题锦:https://qr18.cn/CKV8OZ
2023年最新Android 面试题集:https://qr18.cn/CgxrRy
Android 车载开发岗位面试习题:https://qr18.cn/FTlyCJ
音视频面试题锦:https://qr18.cn/AcV6Ap