ChatGLM-6B 部署与 P-Tuning 微调实战
自从 ChatGPT 爆火以来,树先生一直琢磨想打造一个垂直领域的 LLM 专属模型,但学习文本大模型的技术原理,从头打造一个 LLM 模型难度极大,所以这事儿就一直搁置了。
但最近一个月,开源文本大模型如雨后春笋般接踵而至,例如 LLaMA、Alpaca、Vicuna、 ChatGLM-6B 等。树先生觉得这个事有着落了,毕竟站在巨人的肩膀上,离成功就会更近一步。
经过比较,我选择了ChatGLM-6B 作为预训练模型,一方面是它的中文支持效果好,另一方面是它的参数是 62 亿,对 GPU 性能要求相对较低,可以压缩成本。
概念科普
ChatGLM-6B 是什么?
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的 显卡 上进行本地部署(INT4 量化级别下最低只需 6GB 显存) 。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
为了方便下游开发者针对自己的应用场景定制模型,同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。
不过,由于 ChatGLM-6B 的规模较小,目前已知其具有相当多的局限性,如事实性/数学逻辑错误,可能生成有害/有偏见内容,较弱的上下文能力,自我认知混乱,以及对英文指示生成与中文指示完全矛盾的内容。更大的基于 1300 亿参数 GLM-130B 的 ChatGLM 正在内测开发中。
硬件需求
| 量化等级 | 最低 GPU 显存(推理) | 最低 GPU 显存(高效参数微调) |
|---|---|---|
| FP16(无量化) | 13 GB | 14 GB |
| INT8 | 8 GB | 9 GB |
| INT4 | 6 GB | 7 GB |
最低只需 7GB 显存即可启动微调,就问你香不香~
这样个人和小公司都可以部署自己的语言模型,用自有的数据集训练出对行业领域和业务场景有着深刻理解的语言模型,还避免了用户的数据可能泄露到第三方,公司训练自己的语言模型可以在专业性、差异性、可控性等多方面为产品和业务带来很大的优势和价值。
P-Tuning 微调是什么?
P-Tuning 是一种对预训练语言模型进行少量参数微调的技术。所谓预训练语言模型,就是指在大规模的语言数据集上训练好的、能够理解自然语言表达并从中学习语言知识的模型。P-Tuning 所做的就是根据具体的任务,对预训练的模型进行微调,让它更好地适应于具体任务。相比于重新训练一个新的模型,微调可以大大节省计算资源,同时也可以获得更好的性能表现。
ChatGLM-6B 部署
这里我们还是白嫖阿里云的机器学习 PAI 平台,使用 A10 显卡,这部分内容之前文章中有介绍。
免费部署一个开源大模型 MOSS
环境准备好了以后,就可以开始准备部署工作了。
下载源码
git clone https://github.com/THUDM/ChatGLM-6B
安装依赖
cd ChatGLM-6B
# 其中 transformers 库版本推荐为 4.27.1,但理论上不低于 4.23.1 即可
pip install -r requirements.txt
下载模型
# 这里我将下载的模型文件放到了本地的 chatglm-6b 目录下
git clone https://huggingface.co/THUDM/chatglm-6b /mnt/workspace/chatglm-6b
参数调整
# 因为前面改了模型默认下载地址,所以这里需要改下路径参数
# 分别修改 web_demo.py、cli_demo.py、api.py 文件
tokenizer = AutoTokenizer.from_pretrained("/mnt/workspace/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/mnt/workspace/chatglm-6b", trust_remote_code=True).half().cuda()
# 如果想要暴露在公网上,需要修改 web_demo.py 文件
demo.queue().launch(share=True, inbrowser=True, server_name='0.0.0.0', server_port=7860)
Web 模式启动
pip install gradio
python web_demo.py
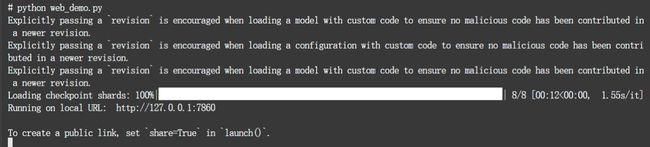
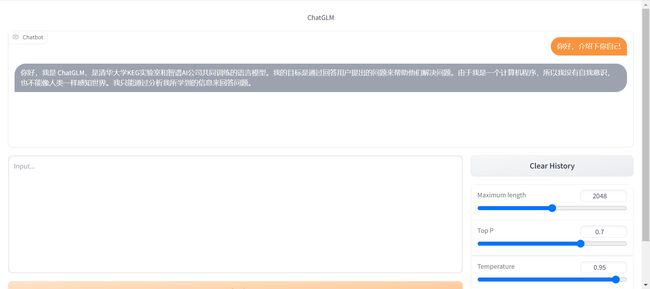
API 模式启动
pip install fastapi uvicorn
python api.py
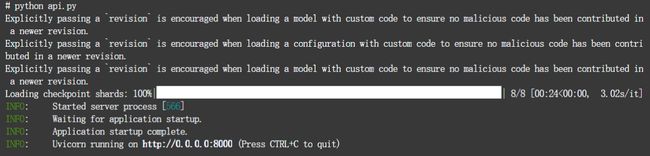
![]()
命令行模式启动
python cli_demo.py
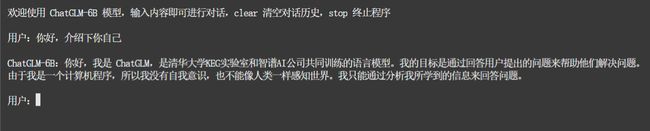
PS: 因为这里使用的是 A10 GPU,显存绰绰有余,所以使用的是 FP16(无量化)精度,INT8 与 INT4 精度的量化加载方式可以参考 Github README
基于 P-Tuning 微调 ChatGLM-6B
ChatGLM-6B 环境已经有了,接下来开始模型微调,这里我们使用官方的 P-Tuning v2 对 ChatGLM-6B 模型进行参数微调,P-Tuning v2 将需要微调的参数量减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行。
安装依赖
# 运行微调需要 4.27.1 版本的 transformers
pip install rouge_chinese nltk jieba datasets
禁用 W&B
# 禁用 W&B,如果不禁用可能会中断微调训练,以防万一,还是禁了吧
export WANDB_DISABLED=true
准备数据集
这里为了简化,我只准备了5条测试数据,分别保存为 train.json 和 dev.json,放到 ptuning 目录下,实际使用的时候肯定需要大量的训练数据。
{"content": "你好,你是谁", "summary": "你好,我是树先生的助手小6。"}
{"content": "你是谁", "summary": "你好,我是树先生的助手小6。"}
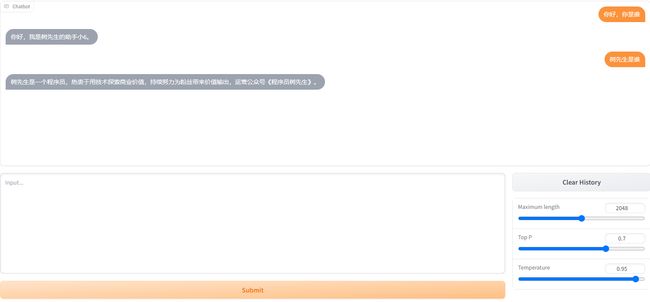
{"content": "树先生是谁", "summary": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"}
{"content": "介绍下树先生", "summary": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"}
{"content": "树先生", "summary": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"}
参数调整
修改 train.sh 和 evaluate.sh 中的 train_file、validation_file和test_file为你自己的 JSON 格式数据集路径,并将 prompt_column 和 response_column 改为 JSON 文件中输入文本和输出文本对应的 KEY。可能还需要增大 max_source_length 和 max_target_length 来匹配你自己的数据集中的最大输入输出长度。并将模型路径 THUDM/chatglm-6b 改为你本地的模型路径。
1、train.sh 文件修改
PRE_SEQ_LEN=32
LR=2e-2
CUDA_VISIBLE_DEVICES=0 python3 main.py \
--do_train \
--train_file train.json \
--validation_file dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path /mnt/workspace/chatglm-6b \
--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 128 \
--max_target_length 128 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN
train.sh 中的 PRE_SEQ_LEN 和 LR 分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。
2、evaluate.sh 文件修改
PRE_SEQ_LEN=32
CHECKPOINT=adgen-chatglm-6b-pt-32-2e-2
STEP=3000
CUDA_VISIBLE_DEVICES=0 python3 main.py \
--do_predict \
--validation_file dev.json \
--test_file dev.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path /mnt/workspace/chatglm-6b \
--ptuning_checkpoint ./output/$CHECKPOINT/checkpoint-$STEP \
--output_dir ./output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 128 \
--max_target_length 128 \
--per_device_eval_batch_size 1 \
--predict_with_generate \
--pre_seq_len $PRE_SEQ_LEN
CHECKPOINT 实际就是 train.sh 中的 output_dir。
训练
bash train.sh
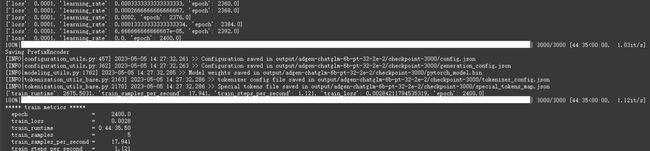
5 条数据大概训练了 40 分钟左右。
推理
bash evaluate.sh

执行完成后,会生成评测文件,评测指标为中文 Rouge score 和 BLEU-4。生成的结果保存在 ./output/adgen-chatglm-6b-pt-32-2e-2/generated_predictions.txt。我们准备了 5 条推理数据,所以相应的在文件中会有 5 条评测数据,labels 是 dev.json 中的预测输出,predict 是 ChatGLM-6B 生成的结果,对比预测输出和生成结果,评测模型训练的好坏。如果不满意调整训练的参数再次进行训练。
{"labels": "你好,我是树先生的助手小6。", "predict": "你好,我是树先生的助手小6。"}
{"labels": "你好,我是树先生的助手小6。", "predict": "你好,我是树先生的助手小6。"}
{"labels": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。", "predict": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"}
{"labels": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。", "predict": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"}
{"labels": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。", "predict": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"}
部署微调后的模型
这里我们先修改 web_demo.sh 的内容以符合实际情况,将 pre_seq_len 改成你训练时的实际值,将 THUDM/chatglm-6b 改成本地的模型路径。
PRE_SEQ_LEN=32
CUDA_VISIBLE_DEVICES=0 python3 web_demo.py \
--model_name_or_path /mnt/workspace/chatglm-6b \
--ptuning_checkpoint output/adgen-chatglm-6b-pt-32-2e-2/checkpoint-3000 \
--pre_seq_len $PRE_SEQ_LEN
然后再执行。
bash web_demo.sh
结果对比
原始模型

微调后模型
P-Tuning 微调到此结束,后续树先生还会带大家进行 Lora 微调,敬请期待~