10/11-10/16日短短五天,我和队友通过结对编程的方式完成了一个用来做“黄金点游戏”的小程序,项目地址:
https://github.com/ycWang9725/golden_point.git
黄金点游戏的基本规则
假设有M个玩家,P1,P2,…Pm
在 (0-100) 开区间内,所有玩家自由选择两个正有理数数字提交(可以相同或者不同)给服务器,
假设提交N11,N12,N21,N22,Nm1,Nm2等M2个数字后,服务器计算:(N11+N12+N21+N22+…+Nm1+Nm2)/(M2)*0.618 = Gnum,得到黄金点数字Gnum
查看所有玩家提交的数字与Gnum的算术差的绝对值,值最小者得M分,值最大者扣2分。其它玩家不得分
此回合结束,进行下一回合,多回合后,累计得分高者获胜。
我们的bot收到的输入是游戏当前轮和历史所有轮次的Gnum和所有玩家的预测值,输出两个对下一轮黄金点的预测值。
PSP表
在任务要求下达的当天晚上,我与队友两人便开始了讨论、设计与编码。
| PSP各个阶段 | 预估时间 | 实际记录 |
|---|---|---|
| 计划: 明确需求和其他因素, 估计以下的各个任务需要多少时间 |
30 | 20 |
| 开发(包括下面 8 项子任务) | 885 | 875 |
| ·需求分析 | 120 | 60 |
| ·生成设计文档 | 10 | 20 |
| ·设计复审 | 10 | 10 |
| ·代码规范 | 5 | 5 |
| ·具体设计 | 20 | 20 |
| ·具体编码 | 600 | 600 |
| ·代码复审 | - | - |
| ·测试 | 120 | 180 |
| 报告 | 150 | 150 |
| ·测试报告 | - | - |
| ·计算工作量 | 30 | 30 |
| ·事后总结 | 120 | 120 |
| 总共花费时间 | 1065 | 1045 |
由于采用结对编程的工作方式,我们没有计划也没有经历代码复审阶段。需求分析阶段的预估时间和实际时间较长,是因为我与队友两人对强化学习(Q-learning方法)并不熟悉,因此将查找参考资料和学习的时间算了进去。我们的具体编码阶段并非完全用于编码,事实上,其中有大约2/3的时间在修改和验证算法的策略,我们将这些时间均算作此项。由于程序中bug大多在编码和验证过程中发现并修改,在测试阶段检测并修改的bug非常少,我们没有撰写测试报告。
我们的bot
- get_numbers.py作为程序的输入输出接口,将程序外输入的历史数据传给Q-learning和IIR两个模型,获取两个模型的预测并根据两个模型的历史预测成功率选择其一输出。
- Q-learning模型(QLearning.py)。此模块维护一个Q-table,每步根据上一步的Gnum和Q-table得到概率最大的下一个Gnum,用softmax方法引入噪声后作为此模型对下一轮的预测,并根据当前轮Gnum更新Q-table。
- IIR滤波器(iir.py)。此模块根据游戏的历史黄金点对Gnum曲线进行滤波,得到平滑后的结果引入均匀分布的噪声后作为此模型对下一轮的预测。
get_numbers.py内部未定义类。
包含的函数及功能:
| 函数 | 功能 |
|---|---|
| LineToNums(line, type=float) | 处理输入的历史数据行,得到可以被get_result()使用的数据结构 |
| get_result(history) | 将history数据输入到两个model之中,分别接收两个model的输出, 用随机数的方式选择一个交给main()函数,并根据两个模型预测值的排名更新选择模型的阈值 |
| main() | main()函数调用前两个函数,作为与外界的输入输出接口 |
QLearning主要含一个class QLearn,包含的函数及功能(较为重要的用红色标出):
| 函数 | 功能 |
|---|---|
| init(self, load, load_path, test, bot_num, n_steps, epsilon_th, mode, rwd_fun, state_map, coding, multi_rwd) | 初始化一个QLearing对象,根据输入的参数在npy文件中load或初始化16个变量,它们被用来保存q-table, model预测的随机程度, model计算reward和rank的模式等 |
| update_epsilon(self) | 每次调用将会更新epsilon,若在预测中使用epsilon,则减小model输出随机数的可能性 |
| next_action(self, all_last_actions, curr_state) | 输入上一轮的Gnum和所有玩家的预测,调用uptate_q_table, update_epsilon, prob2action等函数,更新model的参数并输出model的预测值 |
| prob2action(self, prob) | 根据model的不同模式,输出由q_table和上一轮Gnum决定,加或不加softmax噪声的Q-table的action |
| action2outputs(self, last_action, last_gnum) | 将Q-table的action译码成输出值 |
| update_q_table(self, all_last_actions, curr_state) | 在不同模式下调用calculate_reward或calculate_multi_reward计算模型的reward,并借助Q-learning的更新公式更新q-table |
| calculate_reward(self, all_last_actions, curr_state) | 根据上一轮所有玩家的输出和Gnum,计算自己的排名,调用my_rank2score产生得分作为reward |
| rank2score(self, rank, n_bots) | 输入一个rank,根据模式的不同生成soft/norm-soft/soft-hard-avg类型的score |
| my_rank2score(self, my_rank, n_bots) | 调用rank2score,返回输入的rank list产生的score list |
| gnum2state(self, gnum) | 根据模式的不同,将输入的Gnum用不同的方式编码成Q-table的state |
| calculate_multi_reward(self, all_last_actions, curr_state) | 根据上一轮所有玩家的输出和Gnum,计算Q-table一个state的所有action的rank, 由于action较多,采用了与calculate_reward中不同的计算排名的方法,调用my_rank2score产生得分作为reward |
| random_softmax(self, vector) | 用softmax的方法对输入的Q-table行进行加噪声的取Max,返回Q-table的action编号 |
IIR主要含一个class IIR,包含的函数及功能:
| 函数 | 功能 |
|---|---|
| init(self, alpha, noise_rate) | 初始化一个QLearing对象,在npy文件中load或初始化self.mem变量,它被用来保存Gnum的历史平滑值 |
| get_next(self, last_gnum) | 根据输入的上一轮Gnum和self.mem,计算出Gnum的滑动平均值并加均匀噪声输出 |
每次调用get_numbers.get_result()都将创建一个QLearing对象和一个IIR对象。然后分别调用QLearn.next_action()和IIR.get_next()得到两个输出,再根据历史表现二选一输出。
除此之外,我们还编写了几个用于测试的模块:test.py, plot_all.py, view_npy.py
我们的算法主要依赖于Q-table的学习,因此我们为它加了几个trick。
- 每次更新Q-table时,更新同一个state的所有action的概率。
- 将Q-table的state改为0.01-50的对数编码,因此在黄金点游戏很可能收敛到小值的前提下,固定state数目的Q-table可以获得更大的纵向精度
将Q-table的action改为0.3-3的对数差分编码,使得Q-table在同一个state下获得更大的横向精度,也使model的输出保持在上一轮黄金点的0.3-3倍范围内,保证了输出的稳定性。 - 采用Q-table 和 IIR滤波两个策略相互弥补对方的短板的办法,在各种情况下都能够达到较高的精度。我们在get_numbers.get_result()中设置了一个选择阈值,根据根据两个模型的上一轮预测是否进入前三名来更新阈值,并作为选择QLearning model/IIR model的依据。
- 不同于黄金点游戏的“赢者通吃”的得分规则,我们为Q-learning设计的reward是soft-reward,即是说让玩家的排名与得到的reward成线性关系,第一名得M分,最后一名得-2分,其余名次也可以得到(-2, M)的不等的分数。
事实上,除了上面的setting,我们还尝试了不同的更新策略、编码策略、reward策略,从中选择了表现最好的作为QLearning model的最终版本。
UML

Design by Contract
契约式设计的好处在于:能够将前提条件和后继条件以及不变量分开处理,明确了调用方和被调用方的权利与义务,避免了双方的权利或义务的重叠,有助于使得整体的代码条理更清晰、功能划分更明确、避免冗余的判断。在结对编程中,假设需要我和队友各自写具有相互调用关系的类时,双方都会在函数最开始用assert指出必须满足的前置条件,并对后继条件不符的情况进行异常处理,同时对于不变量进行检查。
规范与异常处理
程序的代码规范主要是依靠Pycharm的内置代码规范,达成共识的方式非常简单,我俩都有强迫症,看着编译器里面各种黄线白线就特别不爽,所以就不惜一切代价消除这些线,因此我们两个都使用同一套代码规范。
设计规范的话,根据《构建之法》书中提到的,一个函数只干一件事情,功能划分到最小单元。这一点,我们严格执行,甚至其中一个要把两个数构成的列表转化成q-learning的奖励的函数都要拆成两个来写,其中一个rank2score负责专门将一个输入值转化为一个奖励输出、另外一个my_rank2score在此上封装,调用rank2score两次,得到一个奖励向量。这样写确实有好处,代码想要重用时在任何功能层面上都能即拿即用,改的时候也能一改全改,非常方便。
本次编程中只对测试过程中出现的异常进行了处理,处理方式也特别简单,就是pass,如果是需要输出的地方就指定一个确定的值。从这个角度上来说,我们确实很欠缺。以后应该在编码的过程中就想到异常处理这一步,形成习惯。
结对编程的过程
结对编程最开始接到任务时是很紧张的,因为不仅是要参加比赛,而且还要用到自己设计的AI,更重要的是给的时间非常短,还不到一周。听到建议使用q-learning,更是比较懵逼,我们结对的两个人从来没有接触过任何强化学习。因此,从任务刚刚布置下来就开始了工作。
2018/10/11 THU 晚上
两个人找了一个休息室,架上电脑,先看了一下Q-learning 的论文,又看了一些大佬的博客,大概了解到了Q-learning是怎样一回事,然后开始写Q-learning的Python类,同时也看了一下老师给的Python接口,在公用的模拟复盘程序中试了一下能不能跑通。Q-learning类写到一半,由于时间原因,回寝室休息,第一天工作结束。
放一张图表明代码进度(真的,只写了这么几行,太慢了。。。)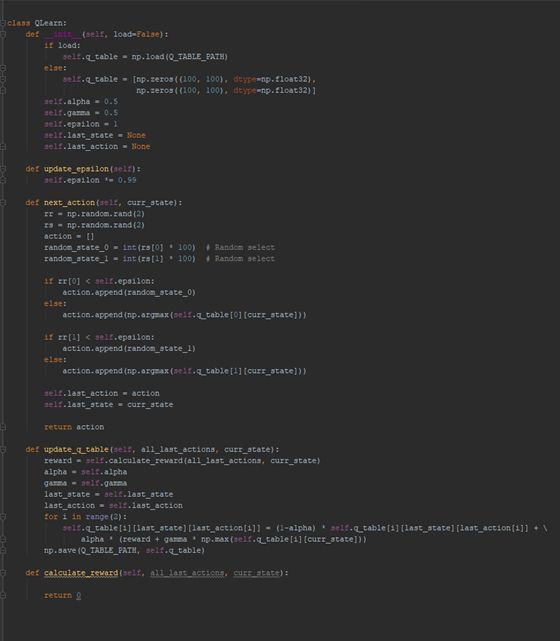
2018/10/12 FRI 晚上
既然已经熟悉了基础知识,也熟悉了接口,接下来就是闷头写实现了。这次实现的任务量也不是很大,Q-learning类的代码量扩充到了100行,同时又在这天晚上新写了一个60多行的python下的模拟复盘环境,用以实时debug。至此,一个最基础的q-table已经写好了。目标不高,能跑就行。。
再上两张图表明代码进度(把之前写的函数折叠掉了,用于增量表现)
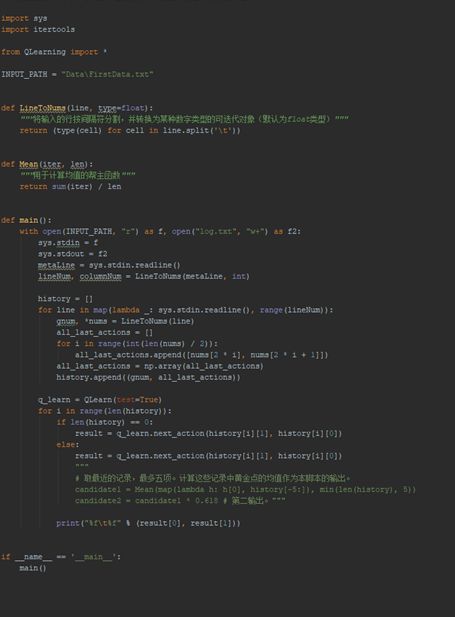
2018/10/13 SAT
和一起实习的同学去爬香山,自己长期不运动导致突然爬一次山就浑身酸痛。。。没有任何理由在这一天写任何代码。
2018/10/14 SUN
11点多才起床。。但是该码代码还得码代码。下午两点开始,两个人会面,开始试验q-learning。没的说,先让10个q-learning bots干一架再说!结果是这样的: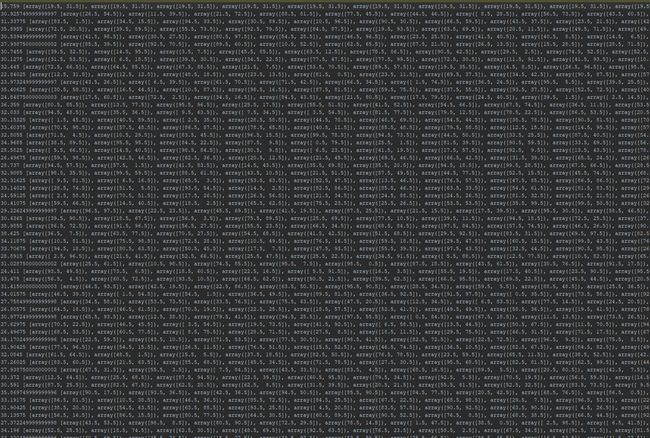
就这样对着屏幕分析了一个小时之后,觉得头昏眼花。算了,写个脚本画个图吧,于是就有了这个100多行的plot脚本(折叠了,要不看不到代码总行数)
然后每个bot都得到了一张属于他自己的计分图,如下图,是第0个bot的Hard reward走势
对比不同bot总体得分图:(这里横坐标代表不同threshold参数的bot。显然,最后一个bot被干掉了)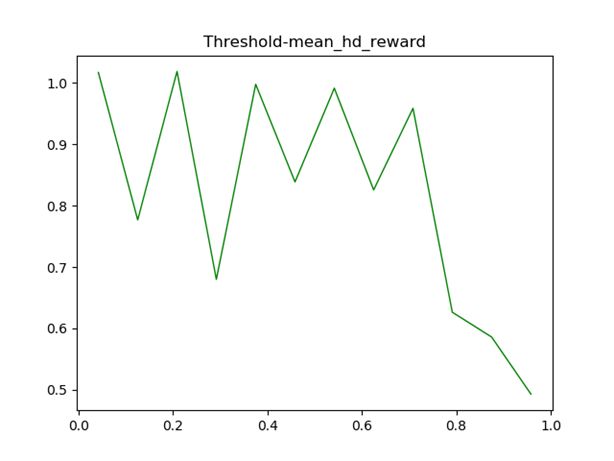
有了这些工具,妈妈再也不用担心我们分析数据了。
就这样,不停换和添加bot的参数,试验到底具有怎样个性的bot 容易赢,一直到10点,然后开始拿在前面的bot战中获胜的bot放到模拟复盘中跑,模拟它在参加那次夏令营的比赛。然而,情况不容乐观。。。成功地拿到-300多分,稳居最后一位。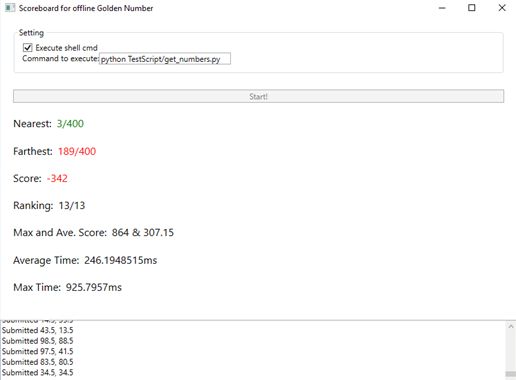
怎么办呢?分析了一下bot提交的数发现,好像bot 根本没学到大盘走势啊!!以至于到盘末大盘都已经降到4.8左右了,我们的bot还在提交80.5这样的数。。怎么办?看看q-table吧
原来如此。。训练集太小,根本更新不全q-table嘛。。另外,每个action的精度太低了,只有1的精确度,那不就是说假设黄金点是4,结果我们就算预测到在这附近,也只能提交量阶中最接近的数4.5嘛?别人如果是基于统计的模型的话很轻松就能算出类似4.11这样的数啊,所以我们轻松被超过啊。好,现在知道问题了,那就简单了,解决问题不就得了!
第一:训练集太小,那我就增大数据量啊!怎么在确定有限的回合中增大数据量呢?原先的q-learning是在不断试错中总结经验,每次只更新上一次对应状态和上一次对应动作那一个q-table 表项的元素。那为什么一定要等错误发生之后再总结经验呢?为什么不能学习历史,避免出错呢?于是就有了我们的第一个trick:模拟历史学习法,即根据历史的状态和历史的黄金点结果,模拟自己采取每一个可能的action,得到reward,一次对q-table中的一整行进行更新。这样数据量一下提升了100倍(100是我们每一个state的action数)
第二:action精度不够,讨论过后,我们的思路渐渐被引向了学过的差分编码,即每个action是到上一次黄金点的差量,这样基于黄金点不可能有特别大变动的假设,可以把action对应的值域缩小,在action总数不变的情况下,action的精度提高了。然而,我们不止于此,又想到:能不能让精度对黄金点的位置有自适应呢?于是想到了“对数差分编码”(这个名字我不知道有没有,是我随口说的)就是,每一次的action都对应于在上一次的黄金点基础上乘以多少,这个乘的数就对应action,并且action的下标与乘的数的对数成正比。这样,假设action对应3-0.3的数,则精度大概能达到(3/0.3)^(1/100)*gnum,其中,gnum是上一轮的黄金点。假设上一轮黄金点是4,那么精度可达0.093。如果黄金点更小,则精度更高。同理,state也可以使用对数编码达到自适应精度。这就是我们的第二个trick:对数(差分)编码
好,有了这两个点子,那就没问题了,安心睡觉了,明天再码代码
2018/10/15 MON 晚上
疯狂码代码赶ddl,把昨天的所有想法都实现进去,为此,给bot添加了许多参数输入,用于决定工作模式,到最后,q-learning bot的init函数变成了下面这样,此时一个屏已经装不下了,全是参数。。。总体代码量600-700行吧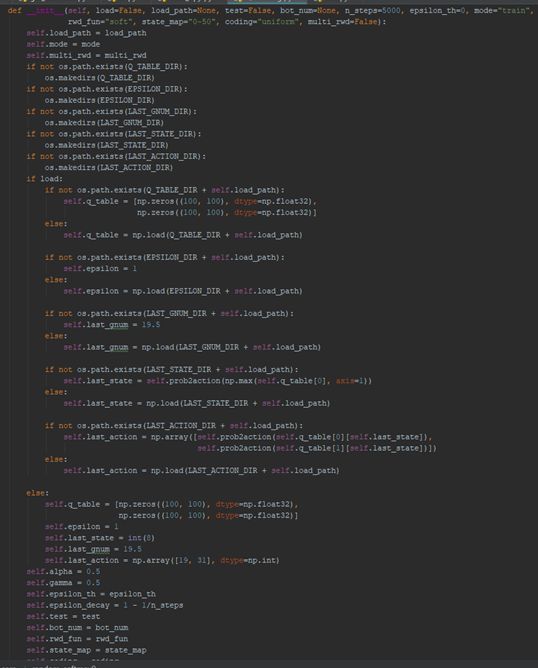
这一天工作到凌晨两点,得到了不错的成绩: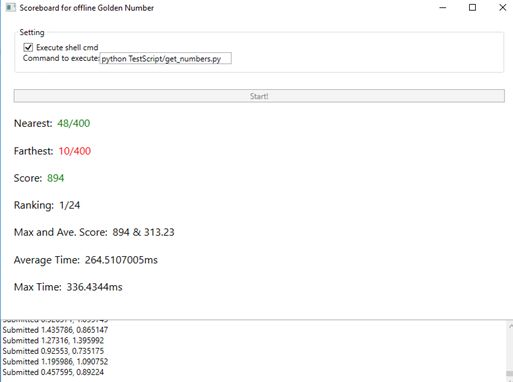
但是发现在黄金点收敛到4.8左右的那次比赛的模拟复盘中,由于黄金点始终较高,所以导致我们的自适应精度较低,导致我们没能拿第一。仔细一想,一共有400次提交,黄金点如果不单调递减的话,那就很有可多收敛到一个较大的数上,或者在其上下波动。如果上下波动的话,一般的统计模型都难以处理,反而对于我们的q-learning比较有利。然而是如果黄金点精密地收敛到一个较大的数上对我们非常不利,因为我们的精度有限,而一般的统计模型可以轻松拟合这种收敛的序列,精度要多少有多少。于是,迫不得已,再加一个与q-learning互补的统计模型吧,没剩多少时间了,那就写一个最简单的一阶IIR滤波+噪声吧。这就是我们的第三个trick。只好先睡觉了,明天就要比赛了,要保持精力。
2018/10/16 TUE 上午+下午
加了一个IIR,写了互补控制策略,中途出了几个bug,紧张死了。好在最后把bug都消除了,在两次模拟复盘中都能拿第一了。5:00,提交最终版。
2018/10/16 TUE 晚上5:30-6:00
第一轮比赛。才拿了个第六名,感觉很失落,赶紧不吃饭了,分析问题原因。
2018/10/16 TUE 晚上6:00-7:00
复盘看了一下q-table,发现本次比赛的统计特性决定了q-table的值特别聚堆,没区分度,于是增大了softmax的指数倍数(下图中函数第三行的“vector * 150”),相当于normalize了。提交上去,听天由命了。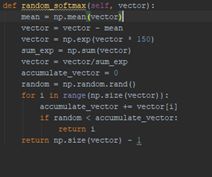
2018/10/16 TUE 晚上7:00-7:30
第二轮比赛,稳拿第一。两方面原因,一方面是我的改动,另外一方面有很多提交捣乱数字的队伍都更规矩了,当然这也是大趋势,如果很多人扰乱的话,会导致扰乱的效果下降,第二轮这种改变也符合我们的预期。
最后总评我们也是第一。很开心,没白浪费这么多时间。
总结成功的原因
从计划安排与实施过程方面,有三点原因:
1.很快确定核心算法,中途虽然遇到波折,但是始终都在以同一个算法为中心进行改动,因此在有限的时间内能够把这一个算法做到极致
2.起步过程不贪心,没有想要一口吃个胖子。
3.信心比较坚定,测试修改过程中都有一个明确的目标:至少要在模拟复盘中拿到第一。
在技术层面上,有三点原因:
1.在宏观上,我们使用的策略是“唯快不破”的想法,即:以最快速度适应大盘的变化规律,这样,不论对手采取什么手段,我们都能很快地学出来这种手段的适应办法,从而超过使用这种手段的人的得分。
2.在微观上,我们使用的模型参数量远多于其他组的模型,因此有很强的适应能力,不仅如此,我们还设计了多种不同的tricks来提高模型性能,大幅提高学习效率。
3.搭建了比较完善的调试平台,能够实时地跟踪各项参数的变化以及得分的变化,针对性地采取解决方案。这一点在比赛中场修改程序中起到了至关重要的作用。
结对编程的心得体会
在结对编程中,我对于python比较熟悉,队友对于C#比较熟悉。因此,在算法上的python代码主要由我来码,队友做领航员的角色。在复盘程序的调试中,主要由队友操作C#程序,我也从中学到了一些C#的知识。结对编程的过程中,我和队友互相实时复审代码,十分高效,提早解决了很多可能出现的问题,算是学习到了。而且我们还从零开始学习实践了不太好搞的强化学习,很有收获!
列举一下我认为本次结对编程中双方的优缺点:
队友:
优点:
1.看代码非常仔细,不论我写到那里,她都能在我的代码中提出我可能忽略的地方。
2.在我专心实现算法时,她也会查找一些资料和库的使用方法,辅助我快速实现。
3.理解代码的能力以及与我沟通的能力很强,有几次我写代码过程中忘记告诉她我的想法到底是什么了,但是她仍然能很快通过看代码意会出我到底在干什么,甚至进一步提出改进方案。
4.学习能力比较突出,在结对最开始,她好像不太熟悉numpy等库,但到结对后期,她已经能够指出我使用这些库的问题。
缺点:
可能是我很快就把解决方案都说到了吧,队友对于算法改进方案的贡献不是很多。
我:
优点:
1.对于python的常用库都比较熟悉,因此搭建python的调试、测试环境等都很快。
2.综合运用学过的知识,想到很多trick,提高了模型能力。
3.对于代码架构有着自己的一套设计,功能划分都很明确,因此编程到后期代码量较大、功能较多时仍然能够保持头脑比较清醒,把更大的精力放在算法设计和实现功能上,而非重构和管理代码上。
缺点:
比较粗心,经常被挑错,而且有的时候写代码走神,写着写着就忘记了最开始提到的某些重点。