ElasticSearch:深入搜索 QUERY API
Search API
ElasticSearch 为了搜索提供了一些原始的 API,通过 HTTP 的方式去请求服务端获取数据,我们这里介绍的是通过请求体来获取数据的API,也就是 Request Body Search API。
基于 Term 的查询
在 ElasticSearch 中,Term 词项是表达语义的最小单位,无论是倒排索引的建立以及搜索分词都有 Term 词项的概念。
基于 Term 词项的查询,意思就是将搜索条件作为一整个词项来进行查询,不会进行任何的分词处理(大小写处理也不会),比如 “Elastic Search Item” 这个搜索条件,如果是 Term 查询,那么 “Elastic Search Item” 这个文本并不会被分词,只有完全匹配的文档才会被搜索出来。
语法:POST 索引/_search/ + 请求体(“关键词 term”)
POST /movies/_search
{
"query": {
"term": {
"title": "Pompatus"
}
}
}
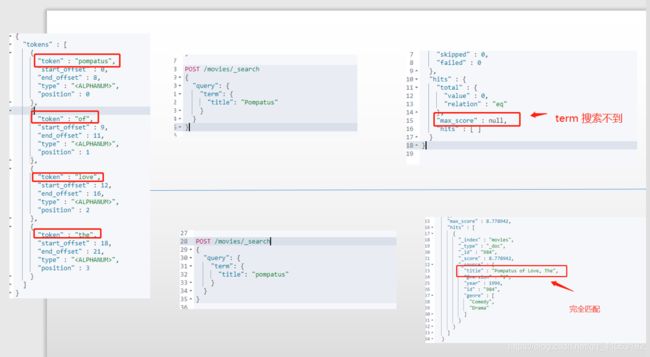
可以看到上图的搜索条件,第一条搜索语句,使用term 查询,我们并没有查询到任何信息,是因为 title的文档在索引时被分词处理为了 pompatus 小写单词,所以我们根据 Pompatus 去查询的时候不会做任何分词处理,所以查询不到,第二条语句可以查找到,是以为我们直接根据 pompatus 去查询的,所以可以找到。
term query | range query | exists query | prefix query 等查询都属于 term query的类型
全文查询
全文查询与 term 查询恰好相反,全文查询会首先对查询条件进行分词处理,然后在将分词后的词项在底层查找,只要符合条件的文本都会被返回回来。
match query 属于 全文查询的一种
POST /movies/_search
{
"query": {
"match": {
"title": "Pompatus Love"
}
}
}

可以看到,全文查询正好与 term 相反,会将很多符合条件的查询都返回回来。
range 范围查询
对于 数字日期之类的一些查询,ElasticSearch 还支持范围查询,在一个区间的内的数字,都会被搜索出来。
语法:POST 索引/_search/ + 请求体(“关键词 range”)
- gt >
- gte >=
- lt <
- lte <=
#数字 Range 查询
POST /movies/_search
{
"query" : {
"range": {
"year": {
"gte": 10,
"lte": 1995
}
}
}
}

可以看到,只要 year 这个字段符合区间 10-1995 范围内的数据都被查询出来了。
日期格式的查询还有一些特殊 dsl 语法,比如 now 代表现在时间,1y 代表一年 1d 表示一小时等
“gte”: “now-1d/d”

exists 非空查询
exists 的意思是某个字段的值是否存在的意思,ElastSearch 提供了一种查询非空字段的API,就是 exists 查询,他会查将索引中所有一个字段不为空的文档全部返回回来。
语法:POST 索引/_search/ + 请求体(“关键词 exists”)
#exists查询
POST /movies/_search
{
"query": {
"exists": {
"field": "title" # field 为你要查询的字段
}
}
}
}
prefix 前缀查询
prefix 是前缀的意思,有些时候,我们只知道某些词的一些前缀,比如 order_ ,我们要将所有以订单开头的文档全部都查询出来,这个时候就可以使用前缀查询。
语法:POST 索引/_search/ + 请求体(“关键词 prefix”)
POST /movies/_search
{
"query": {
"prefix": {
"title": {
"value": "p"
}
}
}
}

可以看到,所有符合以 p 开头的文档都被搜索出来了。
IDS 根据id集合查询
ids 查询其实就是根据你给定的id去查询所有的数据。
语法:POST 索引/_search/ + 请求体(“关键词 ids”)
POST /movies/_search
{
"query": {
"ids": {
"values": ["1","3","10"]
}
}
}
Fuzzy Query
fuzzy query 是基于Levenshtein Edit Distance(莱温斯坦编辑距离)基础上,对索引文档进行模糊搜索。当用户输入有错误时,使用这个功能能在一定程度上召回一些和输入相近的文档,有些类似 URL Query 中的 ~1的这种用法,允许在一定范围内出错。
| 参数名 | 含义 |
|---|---|
| fuzziness | 定义最大的编辑距离,默认为AUTO,即按照es的默认配置。 fuzziness 可选的值为0,1,2,也就是说编辑距离最大只能设置为2.AUTO策略:在AUTO模式下,es将根据输入查询的term的长度决定编辑距离大小 |
| prefix_length | 定义最初始不会被“模糊”的term的数量。这是基于用户的输入一般不会在最开始犯错误的设定的基础上设置的参数。这个参数的设定将减少去召回限定编辑距离的的term时,检索的term的数量。默认参数为0. |
| max_expansions | 定义fuzzy query会扩展的最大term的数量。默认为50. |
| transpositions | 定义在计算编辑聚利时,是否允许term的交换(例如ab->ba),实际上,如果设置为true的话,计算的就是Damerau,F,J distance。默认参数为false。 |
语法:POST 索引/_search/ + 请求体(“关键词 fuzzy”)
POST /movies/_search
{
"query": {
"fuzzy": {
"title": {
"value": "Gumpier",
"fuzziness": "AUTO",
"max_expansions": 50,
"prefix_length": 0,
"transpositions": true,
"rewrite": "constant_score"
}
}
}
}

可以看到,Gumpier 的搜索条件也将正确的参数给查询出来了。
这个查询Api 一般不推荐使用,因为他会查询出一些无关紧要的文档来,可能是个灾难
Terms 数据查询
有些时候,我们的文档可能会有数组的字段类型,虽然 ElasticSearch 对数据类型的数据其实是处理成为了一个个简单的类型,但是他仍然支持数据方式的查询。
语法:POST 索引/_search/ + 请求体(“关键词 terms”)
POST /movies/_search
{
"query": {
"terms": {
"genre": [
"comedy",
"romance"
]
}
}
}

通过结果我们可以发现,terms 其实还是将词项一个一个去单独匹配文档的。
bool 组合查询
组合查询,就是将多种不同的查询组合在一起作为一个查询。
有这样一种场景,对于我们的 movies 数据集,要根据客户喜好查询一些电影出来:
- title 电影标题中包含 fly 关键词
- 要求 year 年份在 1999 - 2005年之间的
- 类型不包含 Romance类型的
这种情况,我们可以使用 bool 组合查询来完成搜索
语法:POST 索引/_search/ + 请求体("关键词 bool ")
- must 必须匹配,参与算分
- should 选择性匹配,至少有一个语句要匹配,与 OR 等价。参与算分
- must_not 必须不匹配 不参与算分
- filter 必须匹配,不参与算分
#基本语法
POST /movies/_search
{
"query": {
"bool" : {
"must" : {
"term" : { "title" : "fly" }
},
"filter": {
"range": { "year" : {
"lte": 2005,
"gte": 1995
}
}
},
"must_not" : {
"match" : { "genre" : "Romance"}
},
"should": [
{"match": {
"title": "fly"
}}
]
}
}
}

可以看到结果中,title 中时包含 fly的,并且 year 也在范围之内。
should 语句是可以嵌套的,嵌套会影响算分,同一层级的算分比重是一样的
dis_max 最佳字段
bool 的 should 语句查询,是 or 的关系,也就是说,两条should语句的结果都会参与算分,并且算分结果是两条语句相加,有些时候,我们并不想获取这样的一个结果,而是要获取两个中间最匹配的一个结果,这个时候可以使用 dis_max query,它会返回多个查询语句中最匹配的那个来作为算分结果,也就是匹配最佳字段。
语法:POST 索引/_search/ + 请求体("关键词 dis_max ")
POST /movies/_search
{
"query": {
"dis_max": {
"tie_breaker": 0.7,
"boost": 1.2,
"queries": [
{
"term": {
"title.keyword": "Fly Away Home"
}
},
{
"term": {
"genre.keyword": "Documentary"
}
}
]
}
}
}
multi_match 多字段搜索
multi_match 提供了一些非常方便的多字段搜索方式,他有三种不同类型的搜索方式,可以通过制定
type 来表示用哪一种方式。
- best_fields 最佳字段 一些字段关系是相互竞争的,结果只能取一个评分最高的,那么可以使用最佳字段的方式来查询,它会返回字段相关性中评分最高的那个。
- most_fields 多数字段 需要对多个字段进行搜索并且将评分相加可以使用这种搜素类型
- cross_fields 混合字段 类似 copy_to 是将几个字段合成一个大字段去搜索
语法:POST 索引/_search/ + 请求体("关键词 multi_match ")
POST movies/_search
{
"query": {
"multi_match": {
"type": "best_fields",
"query": "Fly Away Home",
"fields": ["title","genre"],
"tie_breaker": 0.2,
"minimum_should_match": "20%"
}
}
}