java知识体系综合面试题
目录
一、基础知识
二、JVM知识
三、开源框架知识
四、操作系统
五、多线程
六、TCP与HTTP
七、架构设计与分布式
八、算法
九、数据库知识
十、消息队列
十一、缓存
十二、搜索
一、基础知识
1.JAVA中的几种基本数据类型是什么,各自占用多少字节。
java分为两种数据类型:
1.基本数据类型
2.引用数据类型:如,类,接口,数组
基本数据类型:8种
1.byte 1个字节,-128~127
2.short 2个字节,-32768 ~ 32767
3.int 4个字节,-231-1~231 (21 亿)
4.long 8个字节,
5.float 4个字节,
6.double 8个字节,
7.char 2个字节,
8.boolean 1或4个字节,一个字节表示,至少也得用一个字节来表示,4个字节,32位的cpu每次处理4个字节,效率问题
2.String类能被继承吗,为什么。

不能。因为该类为final类,不能被继承
3.String,Stringbuffer,StringBuilder的区别。
String对象一旦被创建,里面的值便不可改变。需要改变就需要创建新的对象
而Stringbuffer和StringBuilder是可变的。里面的值改变而不需要创建新的对象。
Stringbuffer是线程安全的,性能低
StringBuilder是线程不安全的,性能高
5.ArrayList和LinkedList有什么区别。
都实现了List接口。ArrayList的底层实现原理是数組类型。数组类型代表着,查询快,但是插入和删除慢,需要查询某个值时,直接通过索引,时间复杂度O(1)。当需要插入某个值时,在这个位置后面的值都得向后移动一位,物理上是一段连续内存。
LinkedList低层实现是链表,链表则表示查询慢,新增删除快。删除,只需要改变,指针的指向,当然在java中没有指针这一概念。
6.讲讲类的实例化顺序,比如父类静态数据,构造函数,字段,子类静态数据,构造函数,字段,当new的时候,他们的执行顺序。
类的实例化顺序。最先执行的是父类的静态数据->子类的静态数据->父类的构造方法->子类的构造方法。
记住两个顺序,先静态,先父类。
7.用过哪些Map类,都有什么区别,HashMap是线程安全的吗,并发下使用的Map是什么,他们 内部原理分别是什么,比如存储方式,hashcode,扩容,默认容量等。

直接实现了map接口的主要有HashMap和AbstractMap以及Hashtable。而TreeMap和ConcurrentHashMap都继承与AbstractMap。、
区别:
1.HashMap的底层数据结构是数组加链表。每一个entry都有一个key,value,当不同的key經过hash函数运算之后得到了一个相同的值,这时候便发生了hash冲突。便会把value值存在一个数组里面。而多个entry便构成一个数组。允许key,value位null。采用链表可以有效的解决hash冲突。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //这是hashMap的默认容量。2^4为16.默认的加载因子为0.75,当数组元素的实际个数超过16 * 0.75时,便会进行扩容操作。大小为2*16,扩大一倍。
2.Hashtable方法是同步的,也就是线程安全的,key和value都不能为空。
3.CurrentHashMap是线程安全的,采用了分段锁,在java1.8之后放弃的分段锁的使用。
4.TreeMap底层的数据结构是有顺序访问的红黑树,
8.JAVA8的ConcurrentHashMap为什么放弃了分段锁,有什么问题吗,如果你来设计,你如何设计。
jdk1.8之后ConcurrentHashMap取消了segment分段锁,而采用CAS和synchronized来保证并发安全。数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。
synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
9.有没有有顺序的Map实现类,如果有,他们是怎么保证有序的。
LinkedHashMap,TreeMap便是有顺序的map实现类。LinkedHashMap继承于HashMap。
LinkedHashMap保证有序的结构是双向链表,TreeMap保证有序的结构是红黑树。
10.抽象类和接口的区别,类可以继承多个类么,接口可以继承多个接口么,类可以实现多个接口么。
抽象类,可以有默认的 方法实现。可以有构造器,不可以实例化,可以有public,protected,default。可以有main方法,可以运行main方法。
接口,没有方法的实现,没有构造器,不可以实例化,只有public。不可以有main方法。
11.继承和聚合的区别在哪。
继承:子类继承于父类
实现:类实现接口
依赖:类A在method中使用到了类B
关联:被关联类B作为一个全局属性出现在关联类A中
聚合:关联的一种特殊情况,类A Has-a 类B,一个类B的集合作为全局属性出现在类A
组合:a拥有b,a没了b也就没了
12.IO模型有哪些,讲讲你理解的nio ,他和bio,aio的区别是啥,谈谈reactor模型。
bio:同步阻塞io。意思是当进行io操作时,我们的一个线程对应一个io操作。并且时阻塞的。假如socket通信,当客服端没有发送信息到服务器端时,服务器上这个线程便一直阻塞在这里,不会向下执行。
nio:同步非阻塞,采用的原理主要是轮询。当多个io操作同时存在时,一个线程便可以解决,线程先走到一个io操作的代码处,如果此时通道并没有数据,也不需要写入,线程会继续走,访问下一个io操作,就这样不停的轮询访问,当通道有数据了,并且需要读取的时候,线程便执行读操作。
aio:异步非阻塞,也成为nio2.是nio的改进版。每一个io操作都会有一个回调函数。线程不会去轮询。当某个io需要读取或写入数据时,便会执行回调函数,线程便在此处。
reactor:基于事件处理
13.反射的原理,反射创建类实例的三种方式是什么。
原理:在jvm运行中,java文件被编译为.class文件。通过字节码找到类,以及类中的方法和属性。
1.通过已知对象s1.getClass();
2.通过类名Student.class();
3.通过Class.forName(“包名.类名”);
通过以上三种方法便可得到一个Class类,一个Class类对应着該类的.class字节码,但此时不能直接通过new来创建对象。可以通过getConstructors() 获取该类的构造器。在使用构造器类的newInstance()方法便可以得到該类的对象。
14.反射中,Class.forName和ClassLoader区别 。
Java类装载过程
加载–>验证–>准备–>解析–>初始化–>使用–>卸载
1.Class.forName(className)方法,内部实际调用的方法是Class.forName(className,true,classloader);
第二个参数表示释放需要初始化,默认为true,则需要初始化,初始化便会激活静态变量和静态代码块,并赋值。
2.ClassLoader.loadClass(className)方法,内部实际调用的方法是 ClassLoader.loadClass(className,false);第二个参数表示是否进行链接。链接包含以上的三个步骤,验证–>准备–>解析。在准备的时候便会给类的静态变量分配并初始化内存空间。false表示不进行链接,则无法执行静态代码块或静态对象。
15.描述动态代理的几种实现方式,分别说出相应的优缺点。
1.jdk动态代理;必须继承接口。
2.cglib动态代理不能使用final类。
16.动态代理与cglib实现的区别。
1.jdk动态代理;反射原理实现
2.cglib动态代理是利用asm开源包,对代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。
17.为什么CGlib方式可以对接口实现代理。
cglib动态代理是利用asm开源包,对代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。意思便是这个实现类只要不是final类,便可以创建其子类。便可以实现动态代理。
18.final的用途。
表示最终类,不能被继承。
1.final关键字提高了性能。JVM和Java应用都会缓存final变量。
2.final变量可以安全的在多线程环境下进行共享,而不需要额外的同步开销。
3.使用final关键字,JVM会对方法、变量及类进行优化。
用途:
1.常量,
2.多线程共享
19.写出三种单例模式实现 。
1.饿汉模式
package com.singlo;
public class Student {
private static final Student student=new Student();
private Student(){
}
public static Student getInstans(){
return student;
}
}2.懒汉模式
package com.singlo;
public class Student {
private static Student student=new Student();
private Student(){
}
public static Student getInstans(){
synchronized (Student.class) {
if(student==null){
return new Student();
}
return student;
}
}
}3.静态内部类实现(登记者模式)
package com.singlo;
public class Student {
private Student(){
}
private static Student getInstance(){
return Holder.student;
}
private static class Holder{
private static Student student=new Student();
}
}20.如何在父类中为子类自动完成所有的hashcode和equals实现?这么做有何优劣。
Obejct是所有类都父类,里面封装了hashcode本地方法和equals方法。
如果我们自定义父类。来重写hashcode方法和equals方法。
优势:这个不用说了,所有的类都享有父类的方法。
劣势:当面我们的子类拥有不同的属性时,而这个属性又需要作为判断是否相等时,这时候我们还是需要自己重写父类的方法,而在java中继承是不推荐使用的。
21.请结合OO设计理念,谈谈访问修饰符public、private、protected、default在应用设计中的作用。
public:
具有最大的访问权限,可以访问任何一个在classpath下的类、接口、异常等。它往往>>用于对外的情况,也就是对象或类对外的一种接口的形式。protected:
主要的作用就是用来保护子类的。它的含义在于子类可以用它修饰的成员,其他的不可以,它相当于传递给子类的一种继承的东西default:
有时候也称为friendly,它是针对本包访问而设计的,任何处于本包下的类、接口、异常等,都可以相互访问,即使是父类没有用protected修饰的成员也可以。private:
访问权限仅限于类的内部,是一种封装的体现,例如,大多数成员变量都是修饰符为private的,它们不希望被其他任何外部的类访问。
22.深拷贝和浅拷贝区别。
句柄指向了改对象的物理内存地址,
浅拷贝,句柄不一样,但是指向的物理内存地址是同一个地址。即A是B的浅拷贝对象,修改了B的属性,A的属性也跟着变了。
深拷贝,句柄不一样,指向的物理内存也不一样。
23.数组和链表数据结构描述,各自的时间复杂度。
数组:一段连续的物理内存。可通过数组下标直接获取值。通过下标查询值的时间复杂度,O(1),插入,删除操作,时间复杂度O(n)
链表:逻辑上是连续的,物理上不一定是连续的。查询的时间复杂度O(n),删除,插入的时间复杂度O(1)。
24.error和exception的区别,CheckedException,RuntimeException的区别。

简单来说,Error是系统级错误,是程序员不可控的。
Exception是应用程序的错误,分为检查异常和非检查异常。
CheckedException,检查异常也叫编译异常,必须处理,在代码中捕获或者抛出。
RuntimeException,非检查异常也叫运行时异常,不必须要求处理。
25.请列出5个运行时异常。
IndexOutOfBoundsException(下标越界异常)
NullPointerException(空指针异常)
ArithmeticException -(算术运算异常 如除数为0)
ArrayStoreException - (向数组中存放与声明类型不兼容对象异常)
SecurityException -(安全异常)
26.在自己的代码中,如果创建一个java.lang.String类,这个类是否可以被类加载器加载?为什么。
不能
java中类加载器 自定义类加载器 >> 应用程序类加载器 >> 扩展类加载器 >> 启动类加载器
应用程序类加载器 ,扩展类加载器继承自抽象类java.lang.ClassLoader。这4个加载器之间并不是继承关系,而是组合关系。
首先要知道自定义String能不能被加载,我们先来了解下类加载器采用的模式,双亲委托模式。
1.什么是双亲委托模式。
即一个类在加载过程中,会向上传递,最终到达启动类加载,启动类加载器,查看该类是否是核心库里面的类同名,如果是,只会加载核心库的类,不会加载该类。如果该类与核心库不同名,启动类加载器也不会加载该类,而会交给下一级加载器进行处理。双亲委托模式便是至下向上传递。至上往下加载。
所以我们自定义的String对象不会被加载。这种模式也更好的保护了我们的核心类不会被自定义类所替换。
27.说一说你对java.lang.Object对象中hashCode和equals方法的理解。在什么场景下需要重新实现这两个方法。
在比较两个对象的值是否相同的情况下,需要重写equals方法,而重写了equals方法就需要重写hashcode方法。
目的:先说我们重写equals之后就要重写hashcode的目的,为了我们能够在set集合或者map集合中能够正常的使用该类。
原因:在object中equals方法内容是this==obj。而hashcode也就是通过一个值,可能是一个对象或者一个内存地址。经过hash运算过后得到一个值。这个值叫hash码值。hash码值有一个特征。同一个对象经过无论多少次运算得到的结果都是一样的。而不同的对象经过运算,有可能一样,有可能不一样。而在map集合中,不能存在相同的key值。我们重写了equals方法。而不重写hashcode方法后果是怎样。我们创建该类的两个对象,两个对象赋予相同的值。然后依次put进hashmap中。hashmap中会通过对象得到hashcode。由于是两个不同的对象,hashcode并没有重写,此时有可能得到的是不同的hash值。然后存粗在了hashmap集合中不同的下标上。而在我们看来,他们两个对象的值相同,就是同一个对象,为什么还能在集合中存在两个呢。所以错误,在重写了equals方法后,并重写hashcode方法。还是上面的两个对象。由于重写了hashcode。两个对象的值相同,所以得到了同一个hash值。这时候通过equlas判断是否是同一个对象。由于重写了equals方法,所以得到的还是true。hashmap便会认为这两个对象是同一个对象。其实就是一点。当我们重写了equals方法,即在我们眼中只要这个对象的值相同,即我们把他看作了同一个对象。而你要把两个不同的对象看成是同一个对象,就必须重写他的hashcode方法。所以在我们没有重写equals方法时,哪怕两个对象的值一样,我们也看作是两个对象,在java中。String,Integer等类都重写了equals方法和hashcode方法。
28.在jdk1.5中,引入了泛型,泛型的存在是用来解决什么问题。
首先为什么要引入泛型。我们假定一种场景。有两个不同的数据类型,它们都需要做相同的业务逻辑。这时候由于数据类型不同,我们是不是得写两个方法来分别解决。
但是有了泛型,我们不需要管传入的到底是哪种数据类型,这时候可能会问,所以的类都继承于Object,使用Object可以完成同样的工作啊,为什么不使用Object呢。
1.使用Object。普通数据类型,拆箱和装箱都是需要性能的,如果是引用数据类型。Object需要与与之交互的实际数据类型进行强制转换。这个也是需要性能的
2.因为在java中,允许Object强制转换成其他任何对象,这将意味着你将失去编译期的类型安全。
29.这样的a.hashcode() 有什么用,与a.equals(b)有什么关系。
在没有重写这两个方法的情况下。同一个对象的hashcode一定相同,不同的hashcode有可能不同,也有可能相同。
equals方法即在比较两个对象是同一个对象。两点:同一个对象,equals一定为true,hashcode一定相同
不同对象,equals一定为false,hashcode有可能相同。
当然这都是建立在不重写这个两个方法的基础上
30.有没有可能2个不相等的对象有相同的hashcode。
有可能。这也是为什么,会产生hash冲突。当两个不同对象,得到了同一个hashcode。在hashmap中,即表示这两个对象的下标是相同的。解决hash冲突的方法有几种,在hash化,寻地址法。链地址法。hashmap中便采用了链地址法
31.Java中的HashSet内部是如何工作的。
HashSet继承于AbstractSet,实现了set接口。
内部实现是一个私有化的hashmap。当我们add(E)时。实际调用的是map.put(e, PRESENT)
hashmap的键值对,键由于不能重复,所以我们传入的值作了map的键,而map的值则是一个常量。
32.什么是序列化,怎么序列化,为什么序列化,反序列化会遇到什么问题,如何解决。
什么是序列化:在java中,把对象转换成字节序列的过程叫做序列化。
把字节序列转换成对象的过程叫做反序列化。
怎么序列化:在实现了Serializable接口的情况下,便可以序列化。
为什么要序列化:
1.为了我们在内存中的对象能够存储在硬盘文件或数据库需要序列化
2.为了对象在网络中通过套接字进行传输。
3.通过rmi传输对象时需要用到序列化
反序列化会遇到什么问题。
在我们实现了Serializable接口后,没有给serialVersionUID一个固定值。这时候会发生这种情况,当我们序列化之后,然后改变了类中的属性。然后再进行反序列化。这时候程序便会报错,原因在于我们序列化时候的serialVersionUID与我们反序列化时候的serialVersionUID不一致所导致的,这也是为什么我们在实现了Serializable接口后,不给serialVersionUID一个固定值,ide会给我们一个警告。因为我们没有给一个固定的值。系统会根据类的属性自动生成一个值,在我们改变了类中的属性后,这个值自然也会发生变化。
33.java8的新特性。
1.接口可以通过default关键字修饰方法,实现方法的具体内容,子类实现后,可直接调用该方法。
2.Lambda表达式。new Thread( () -> System.out.println(“In Java8, Lambda expression rocks !!”) ).start();
二、JVM知识
1.什么情况下会发生栈内存溢出。
什么是栈溢出,栈是存放方法的局部变量,参数,操作数栈,动态链接等。栈是每个线程私有的,一个方法便会创建一个栈帧。当方法执行创建的栈帧超过了栈的深度,这时候便会发生栈溢出。
常见的几种案列。
大量递归调用或无限递归
循环过多或死循环
局部变量过多
数组,List,map数据是否过大。
这些都有可能造成栈内存溢出
2.JVM的内存结构,Eden和Survivor比例。
一个Eden区和2个Survivor区,默认比例8:1
3.JVM内存为什么要分成新生代,老年代,持久代。新生代中为什么要分为Eden和Survivor。
原因:对象新创建的时候都在新生代,如果不将新生代分为Eden和Survivor区,那么当进行一次minor GC之后,存活的对象都将放入到老年代中,这样的话,老年代被对象填满的时间减短,那么进行full GC的频率增加。一次full GC,花费的时候比较长。那么我们的程序会花更多的时间进行垃圾回收。
目的:分区的目的便是让中等寿命的对象在minor GC中被回收,减少垃圾回收所占用的时间。降低垃圾回收对程序的影响。
4.JVM中一次完整的GC流程是怎样的,对象如何晋升到老年代,说说你知道的几种主要的JVM参数。
一次完整的GC流程:
一个对象出生在Eden区。当进行minor GC之后,该对象仍然存活。年龄加1,然后赚到了Survivor的from区。在一次minor GC之后,在Eden区和Survivor from区存活的对象将被复制到Survivor to区,然后from和to区颠倒,在15次minor GC之后,该对象仍然存活。该对象将进入到老年代区。
5.你知道哪几种垃圾收集器,各自的优缺点,重点讲下cms和G1,包括原理,流程,优缺点。
垃圾收集器:
1.Serial:新生代垃圾收集器,单线程。复制算法,当它在收集内存时,其他线程都要等待,直到它完成。
2.ParNew:新生代收集器,是Serial的一个多线程版,当它在收集内存时,暂停所有的用户线程,复制算法,只能配合CMS工作
3.Parallel Seaverage:新生代收集器,多线程,复制算法。自适应调节策略
吞吐量 = 用户代码运行时间/(用户代码运行时间+垃圾回收时间)
可控制的吞吐量
4.Serial Old:老年代回收器,单线程。标记-整理算法,工作时暂停用户线程。
5.Parallel Old:是Paraller Seaverage 老年代版,多线程,标记-整理算法。
6.CMS:老年代回收器,Concurrent Mark Sweep,是一种获取最短停顿时间为目标的回收器。现在很多业务场合都要求挺短时间短,CMS非常适合这种业务场景。标记清楚算法,对cpu敏感,尽可能的缩短停顿时间。无法处理浮动垃圾,产生内存碎片。
7.G1:面向服务器应用端的回收器,是可以替换掉cms的。
并行与并发,充分利用cpu,缩短stw时间。不用GC停顿操作,并发执行。分代收集。
空间整合:标志-整理算法,局部采用复制算法实现,不会产生内存碎片。可预测的停顿。
6.垃圾回收算法的实现原理。
三种垃圾回收算法:
1:标记复制算法,一般用于新生代。
原理:步骤两步,a,对eden,from区的存活对象进行标记。b,将标记的对象复制到to区,并清空eden,from区。交换from区和to区的。
一般一次ninor gc之后,存活的对象会才采用复制算法,将存活对象复制到from区。
优点:
a,相比较于标记清除算法,清除算法需要遍历所有的对象,而复制算法中的标记,只需要标记存活的对象
b,不会发生碎片化:同样相比于标记清除算法,由于存活下来的对象会在To区中连续的分配,因此不会像标记清除算法那样,需要维护碎片空间
缺点:
a,内存使用率低
b,自对象的递归复制,存在着函数栈的消耗,潜藏着栈溢出的风险2:标记清除法:用于老年代
步骤:a,遍历所有对象,对存活对象打上活动的标记。b,清除,再次遍历所有对象,对没有标记的对象进行内存释放,有活动标记的对象,去掉活动标记。
优点:实现简单,算法简单。
缺点:存活对象占用空间的不连续性,导致内存碎片化。3.引用计算。
对任意一个对象,每有一次该对象的引用,计数器加1,结束对这个对象的引用,计数器减一。一旦计数器归0,对象便被清除。
缺点:占用资源,占用内存,实现复杂。
7.当出现了内存溢出,你怎么排错。
可以在jvm中设置参数:
-XX:+HeapDumpOnOutOfMemoryError
JVM 就会在发生内存泄露时抓拍下当时的内存状态,也就是我们想要的堆转储文件。这种方式适合于生产环境。本文采用的这种方式
此时会获取到一个.hprof的文件,这个文件可以通过jmp工具,或者mat工具等查看,是一个二进制文件,
在这个文件我们可以清楚的看见,线程的个数,对象的个数,堆内存的使用。可分析出造成内存溢出是哪些对象,具体原因,根据原因来解决问题。
8.JVM内存模型的相关知识了解多少,比如重排序,内存屏障,happen-before,主内存,工作内存等。
重排序:java->.class : .class->汇编: 汇编->cpu指令。这3个过程都有可能发生重排序,java重排序的最低保障,即在单个线程内,看起来代码总是在有顺序运行的,但在其他线程看来就不一定了。
9.简单说说你了解的类加载器,可以打破双亲委派么,怎么打破。
可以打破:
打破双亲委派模式,自定义类加载不仅要重些findclass方法,还需要重写,loadclass方法。
10.讲讲JAVA的反射机制。
原理:在jvm运行中,java文件被编译为.class文件。通过字节码找到类,以及类中的方法和属性。
1.通过已知对象s1.getClass();
2.通过类名Student.class();
3.通过Class.forName(“包名.类名”);
通过以上三种方法便可得到一个Class类,一个Class类对应着該类的.class字节码,但此时不能直接通过new来创建对象。可以通过getConstructors() 获取该类的构造器。在使用构造器类的newInstance()方法便可以得到該类的对象。
11.你们线上应用的JVM参数有哪些。
堆
-Xms:520M 初始堆内存
-Xmx:1024M 最大堆内存
-Xmn:256M 新生代大小
-XX:NewSize=256M 设置新生代初始大小
-XX:MaxNewSize=256M 设置新生代最大值内存
-XX:PermSize=256M 设置永久代初始值大小
-XX:MaxPermSize=256M 设置永久最大值大小
-XX:NewRatio=4 设置老年代和新生代的比值。表示老年代比新生代为4:1
-XX:SurvivorRatio=8 设置新生代中Survivor区和eden区的比值,该比值为Eden区比Survivor区为8:2
-XX:MaxTenuringThreshold=7 表示一个对象在Survivor区移动了7次还没有被回收,则进入老年代。该值可减少full GC代频率线程: -Xss:1M 设置每个线程栈大小
垃圾回收器选择
-XX:+UseSerialGC 设置为串行收集器
-XX:+UseParallelGC 设置为并行收集器。次设置仅对年轻代生效。
-XX:ParallelGCThreads=20 设置并行收集器的线程数,建议与cpu数量相同。
-XX:+UseParallelOldGC 设置老年代的收集方式为并行收集,jdk1.6后支持老年代的并行收集。
-XX:MaxGCPauseMillis=100 设置每次新生代垃圾回收的最长时间,如果无法满足次时间,jvm会自动调整新生代大小,以满足此时间。
-XX:+UseAdaptiveSizePolicy 此设置会自动调整eden区和survivor区的比例,以达到系统规定的最低响应时间或者收集频率。建议设置
-XX:+UseConcMarkSweepGC 即CMS收集,设置年老代并发收集,该收集器适合响应时间需求大于对吞吐量的需求。
-XX:+UseParnewGC 设置新生代为并发收集,可与CMS收集器同时使用。
-XX:CMSFullGCsBeforeCompaction=0 此设置为每次FUllGC后对空间进行压缩和整理
-XX:+UseCMSCompactAtFullCollection 打开内存空间压缩和整理,虽然一定程度上会影响性能,但能消除内存碎片
-XX:+CMSIncrementalMode 设置为增量收集模式,一般适用于单个CPU
-XX:CMSInitiatingOccupancyFraction=70 表示在每次老年代空间使用到70%时就开始进行CMS收集,避免full GC的发生。
-XX:+ScavengeBeforeFullGC 新生代GC优于FUll GC执行
-XX:-DisableExplicitGC 不响应 System.gc()代码
-XX:+UseThreadPriorities 启用本地线程优先级API,即java.lang.Thread.setPriority()生效
-XX:SoftRefLRUPolicyMSPerMB=0 软应用对象在最后一次被访问后能存活0秒,jvm默认为1000毫秒
-XX:TargetSurvivorRatio=90 允许Survivor区90%被占用,jvm默认为50%。可提高Surivor区的使用辅助信息参数
-XX:ClTime 打印消耗在JIT编译的时间
-XX:ErrorFile=./hs_err_pid.log 保存错误日志或数据到指定文件中
-XX:HeadDumpOnOutOfMemoryError 当每次遇到内存溢出时Dump出此时的堆内存
-XX:OnError=";" 出现致命ERROR后运行自定义命令、
-XX:OnOutOfMemoryError=";" 当堆内存溢出时执行自定义命令
-XX:-PrintClassHistogram 按下Ctrl+Break后打印堆内存中类实例的柱状图,同jdk的jmap -histo命令一样
-XX:-PrintConcurrentLocks 按下Ctrl+Break后打印线程栈中并发锁的相关信息,同jdk的jstak -l命令一样
-XX:-PrintComilation 当一个方法被编译时打印相关信息
-XX:-PrintGC 每次GC时打印相关信息
-XX:-PrintGCDetails 每次GC时打印详细信息
-XX:-PrintGCTimeStamps 打印每次GC的时间戳
-XX:-TraceClassLoading 跟踪类的加载信息
-XX:-TraceClassLoadingPreorder 跟踪被引用到的所有类的加载信息
-XX:-TraceClassResolution 跟踪常量池
-XX:-TraceClassUnloading 跟踪类的卸载信息-client 设置jvm为client模式,启动速度快,运行效率和内存性能不高。一把用于客服端或代码调试,在32位默认启动该模式
-server 设置jvm为server模式,特点启动速度慢,运行效率高。一般用于服务器。(-)标准参数,所以jvm都必须支持这些参数的功能,而且向后兼容
(-X)非标准参数,默认jvm实现这些参数功能,但不能保证所以jvm实现都满足,不保证向后兼容。
(-XX)非稳定参数,此类参数各个jvm实现有所不同,将来可能不被支持,需要谨慎使用。案列
大型网站,承受海量访问的动态web应用
服务配置:8CPU,8G MEM,JDK 1.6.x
参数:
-server -Xms3550M -Xmx3550M -Xmn1256M -Xss128k -XX:SurvivorRatio=6 -XX:MaxPermSize=256M -XX:ParallelGCThreads=8 -XX:MaxTenuringThreshold=0 -XX:+UseConcMarkSweepGC12.g1和cms区别,吞吐量优先和响应优先的垃圾收集器选择。
g1不会产生空间碎片,gc时间段,吞吐量高
cms会产生空间碎片,但是可避免发生full gc,以响应优先。
13.怎么打出线程栈信息。
public static void main(String[] args) {
List strs=new ArrayList();
strs.add(args[1]);
for (Entry stack :Thread.getAllStackTraces().entrySet()) {
Thread thread=stack.getKey();
StackTraceElement[] sta= stack.getValue();
System.out.print("\n线程:"+thread.getName()+"\t");
for (StackTraceElement el : sta) {
System.out.print("\t"+el+"\t");
}
System.out.println();
}
} 运行结果:
线程:Signal Dispatcher
线程:main
java.lang.Thread.dumpThreads(Native Method) java.lang.Thread.getAllStackTraces(Thread.java:1610) com.jvm.Test.main(Test.java:15)线程:Finalizer
java.lang.Object.wait(Native Method) java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143) java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:164) java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:212)线程:Reference Handler
java.lang.Object.wait(Native Method)
java.lang.Object.wait(Object.java:502) java.lang.ref.Reference.tryHandlePending(Reference.java:191) java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153)
14.请解释如下jvm参数的含义:
-server -Xms512m -Xmx512m -Xss1024K
-XX:PermSize=256m -XX:MaxPermSize=512m -
XX:MaxTenuringThreshold=20XX:CMSInitiatingOccupancyFraction=80 -
XX:+UseCMSInitiatingOccupancyOnly。
-server jvm以server模式启动,启动速度慢,运行效率和内存性能高
-Xms512m 初始堆大小为512m
-Xmx512m 最大堆大小为512m,这里初始和最大值一样,避免jvm去不断的申请内存
-Xss1024k 每个线程栈的大小为1024k
-XX:PermSize=256m 老年代的初始大小为256m
-XX:MaxPermSize=512m 老年代最大值为512m
-XX:MaxTeunringThreshold=20 表示对象在survivor区交换20次后还存活,便进入到老年代。
-XX:CMSInitiaitingOccupanryyFraction=80 表示老年代的CMS收集器,老年代空间使用率达到80%就开始进行CMS收集,避免full GC 的执行
-XX:+UseCMSInitiatingOccupancyOnly 如果不配置该参数,jvm会在第一次CMS收集后,自动调整CMS收集。设定了该值,加上上面的=80.则jvm不会自动调整,只会使用空间到80%时进行CMS收集
三、开源框架知识
1.简单讲讲tomcat结构,以及其类加载器流程,线程模型等。
tomcat结构
结构图


1.tomcat顶层是一个Server容器,代表着整个服务器。
2.Server容器下可以有一个或多个Service。Service代表着用于提供具体的服务
3.一个Service服务下主要包含两个组件,Connector和Container。
4.Connector的负责处理连接相关的事情,并提供Socket的Request和Response的转化
5.Container用于封装和管理Servlet。以及具体处理Request的请求。
6.一个Tomcat只有一个Server,一个Server可以有多个Service服务,一个Service服务可以有多个Connector,但是只能有一个Container。
7.Container默认有四个子接口,Engine 、Host 、Context 、Wrapper,和一个默认实现类ContainerBase。每一个接口都是一个容器。
8.一个Container只能有一个Engine,
9.Host叫做站点,也叫虚拟主机,可通过配置添加多个。
10.一个Context代表一个应用,可以有多个
11.一个Wrapper封装这一个Servlet。
tomcat类加载器流程

BootStrap类加载器
System类加载
Common类加载器
web application下的/WEB_INF/classes
web application下的/WEB_INF/lib/*.jar
2.tomcat如何调优,涉及哪些参数 。
tomcat调优
conf/server.xml文件
namePrefix="catalina-exec-"
maxThreads="500"
minSpareThreads="20"
maxSpareThreads="50"
maxIdleTime="60000"/>
maxThreads:tomcat处理请求的最大线程数500
minSpareThreads:最小空闲线程数
maxSpaceThreads:最大备用线程数,tomcat创建的线程数超过50,便会关闭不在需要的socket。
maxIdelTime:当线程空闲时间超过这个时间点,就会关闭线程。
port="8080" protocol="HTTP/1.1"
URIEncoding="UTF-8"
connectionTimeout="30000"
enableLookups="false"
disableUploadTimeout="false"
connectionUploadTimeout="150000"
acceptCount="300"
keepAliveTimeout="120000"
maxKeepAliveRequests="1"
compression="on"
compressionMinSize="2048"
compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain,image/gif,image/jpg,image/png"
redirectPort="8443" />
URIEncoding:tomcat容器的编码格式
connectionTimeout:网络连接超时,0表示永不超时
enableLookups:是否反查域名,返回远程主机的ip。false可以提高性能
disableUploadTimeout:上传是否启用超时机制
connectionUploadTimeout:文件上传超时时间
acceptCount:当所有处理请求的线程都被占用时,可传入连接请求的最大队列长度,超过这个数的请求不予处理。
keepAliveTimeout:长连接保持时间为多少,默认为connectionTimeout的值,-1表示不限制。
maxKeepAliveRequests:表示在服务器关闭之前,该连接支持的最大请求数,超过该数,连接将被关闭,1表示禁用,-1表示不限制,默认为100-200
compression:是否对响应数据进行gzip压缩,off表示不压缩,on表示压缩(文本将被压缩),force表示所有情况下都进行压缩,默认为off。压缩一般可减少1/3,节省宽度。
compressionMinSize:只有当响应报文大于这个值时,才进行压缩,默认为2048.
compressableMimeType:对哪些类型的文件进行压缩
noCompressionUserAgents=“gozilla, traviata”:对于以下的浏览器不进行压缩。
3.讲讲Spring加载流程。
ApplicationContext context = new ClassPathXmlApplicationContext("bean.xml");
Person person = context.getBean("person", Person.class);这两行代码便包含了Spring的整个加载流程。在new ClassPathXmlApplicationContext(“bean.xml”);会将字符串转换为资源路径,后加载的bean会覆盖先加载的bean,目的 是便于外部重写。
super(parent);
// 解析 bean.xml 文件
setConfigLocations(configLocations);
if (refresh) {
refresh();
}refresh()会刷新容器。如果存在beanFactory,则销毁,然后新创建
try {
// 创建 DefaultListableBeanFactory
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
customizeBeanFactory(beanFactory);
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
// 然后赋值给 beanFactory 变量
this.beanFactory = beanFactory;
}
}这里创建了一个DefaultListableBeanFactory对象。
4.Spring AOP的实现原理。
Aop原理,切面增强。
动态代理可以增强类,而spring用了两种方式实现动态代理,一种是jdk动态代理。一种是cglib动态代理
jdk。类必须实现接口。cglib不能是final类。前者通过聚合的方式,后者通过继承的方式。
5.讲讲Spring事务的传播属性。
propagation(传播行为)
spring事务的传播行为有7种。
1.propagation_required 当前没有事务变创建一个事务,如有有则使用
2.propagation_supports 支持当前事务,有则使用,没有则不使用
3.propagation_mandatory 支持当前事务,有则使用,没有则抛出异常
4.propagation_requires_new 无论有没有,都创建新事务
5.propagation_not_supported 非事务方式提交,有则挂起该事务
6.propagation_never 非事务提交,有则抛出异常
7.propagation_nested 存在事务,在嵌套事务内执行,没有,则创建一个事务
6.Spring如何管理事务的。
1)PlatformTransactionManager:事务管理器–主要用于平台相关事务的管理
主要有三个方法:
commit 事务提交;
rollback 事务回滚;
getTransaction 获取事务状态。
2)TransactionDefinition:事务定义信息–用来定义事务相关的属性,给事务管理器PlatformTransactionManager使用
这个接口有下面四个主要方法:
getIsolationLevel:获取隔离级别;
getPropagationBehavior:获取传播行为;
getTimeout:获取超时时间;
isReadOnly:是否只读(保存、更新、删除时属性变为false–可读写,查询时为true–只读)
事务管理器能够根据这个返回值进行优化,这些事务的配置信息,都可以通过配置文件进行配置。
3)TransactionStatus:事务具体运行状态–事务管理过程中,每个时间点事务的状态信息。
例如它的几个方法:
hasSavepoint():返回这个事务内部是否包含一个保存点,
isCompleted():返回该事务是否已完成,也就是说,是否已经提交或回滚
7.Spring怎么配置事务(具体说出一些关键的xml 元素)。
1.配置事务管理器
2.配置事务属性
3.配置事务切入点,注入事务属性
4.注解式事务
8.说说你对Spring的理解,非单例注入的原理?它的生命周期?循环注入的原理,aop的实现原理,说说aop中的几个术语,它们是怎么相互工作的。
拿到当前容器,通过context.getBean()获取新的实例。
AOP术语
1.增强(advice):对类功能的增加
2.切点(pointcut): 需要在哪里增强,这个(哪里)地点就是切点
3.连接点(JoinPoint): 某个方法的前面,后面,中间,抛出异常。时增强。前面、后面、中间、抛出异常这些都是连接点
4.切面(Aspect):由切点和增强组成
5.目标对象(tagert): 需要对某个类进行增强,加一个日志打印。这个日志打印就是目标对象。
6.AOP代理:(AOP proxy):增强后的那个结果类就是AOP代理。
7.织人(Weaving):这个增强过程就叫织入。
9.Springmvc 中DispatcherServlet初始化过程。
了解DispatcherServlet的初始化过程,来看一下他的initStrategies()方法
protected void initStrategies(ApplicationContext context) {
initMultipartResolver(context);
initLocaleResolver(context);
initThemeResolver(context);
initHandlerMappings(context);
initHandlerAdapters(context);
initHandlerExceptionResolvers(context);
initRequestToViewNameTranslator(context);
initViewResolvers(context);
initFlashMapManager(context);
}1.initMultipartResolver(context); 初始化文件上传服务。
2. initLocaleResolver(context); 初始化用于处理国际化,本地化策略
3.initThemeResolver(context); 用于定义主题
4. initHandlerMappings(context);初始化HandlerMapping
5.initHandlerAdapters(context); 初始化HandlerAdapters
6.initHandlerExceptionResolvers(context); 当handler出错时,会将错误记录在log文件上
7. initRequestToViewNameTranslator(context); 将指定的ViewName按照Translator替换成想要的格式
8.initViewResolvers(context); 初始化视图解析器
9. initFlashMapManager(context);用于生成flashMap管理器
10.netty的线程模型,netty如何基于reactor模型上实现的。
1;reactor单线程模型
用户发起io操作到事件分离器。事件分离器调用相应的处理器处理事件,事件处理完之后,事件分离器获得控制权,继续相应处理
2.reactor多线程模型
单线程中,每个io事件都在同一个线程中执行,当其中一个io出现异常时,将导致后面的io处理不了,
在多线程中,事件分离器中有reactorThreadacceptor和reactorThreadPool。reactorThreadacceptor接收到一个io事件,将io事件交于线程池处理,自己继续等待其他io事件。
3.reactor主从多线程模型。
Acceptor不再是一个线程,而是一个nio线程池。acceptor仅仅完成登录,握手,认证等,其他业务扔交给work线程池
NioEventLoop
1.作为服务端Acceptor线程,负责处理客户端的请求接入
2.作为客户端Connecor线程,负责注册监听连接操作位,用于判断异步连接结果
3.作为IO线程,监听网络读操作位,负责从SocketChannel中读取报文
4.作为IO线程,负责向SocketChannel写入报文发送给对方,如果发生写半包,会自动注册监听写事件,用于后续继续发送半包数据,直到数据全部发送完成
11.为什么选择netty。
使用io,性能跟不上,使用原生nio,复杂的API并不方便使用,搭建一套优秀的nio框架并不容易。使用现成的netty,节省开发时间,提高系统性能。
12.什么是TCP粘包,拆包。解决方式是什么。
情景
客服端发送了两个数据包,服务器端只收到了一个数据包。tcp协议不会出现丢包,说明两个数据包被粘在一起了,即为粘包。
客服端发送一个数据包,服务器端收到了两个数据包,即为拆包。
原因(为什么要粘包和拆包)
1.应用程序写入的数据大于套接字缓冲区大小,需要拆包
2.写入的数据小于套接字缓冲区大小,网卡将多次写入的数据发送到网络,发生粘包
3.接收方法不及时读取套接字缓冲区数据,发生粘包。
解决方式
1.发送端给每个数据包添加包首部。首部中应该包含数据包的长度,这样在接受端通过读取包首部,便能准确地读到有用的数据,
2.发送端将数据包封装为固定长度,不够补齐0,接受端再读取固定长度的数据,便能准确将粘包的数据进行拆包。
3.在数据包设置边界,添加特殊字符,这样便能够通过特殊字符进行拆分。
13.netty的fashwheeltimer的用法,实现原理,是否出现过调用不够准时,怎么解决。
HashedWheelTimer底层数据结构依然是使用DelayedQueue。加上一种叫做时间轮的算法来实现。
关于时间轮算法,有点类似于HashMap。在new 一个HashedWheelTimer实例的时候,可以传入几个参数。
第一,一个时间长度,这个时间长度跟具体任务何时执行没有关系,但是跟执行精度有关。这个时间可以看作手表的指针循环一圈的长度。
第二,刻度数。这个可以看作手表的刻度。比如第一个参数为24小时,刻度数为12,那么每一个刻度表示2小时。时间精度只能到两小时。时间长度/刻度数值越大,精度越大。
添加一个任务的时候,根据hash算法得到hash值并对刻度数求模得到一个下标,这个下标就是刻度的位置。
然而有一些任务的执行周期超过了第一个参数,比如超过了24小时,就会得到一个圈数round。
简点说,添加一个任务时会根据任务得到一个hash值,并根据时间轮长度和刻度得到一个商值round和模index,比如时间长度24小时,刻度为12,延迟时间为32小时,那么round=1,index=8。时间轮从开启之时起每24/12个时间走一个指针,即index+1,第一圈round=0。当走到第7个指针时,此时index=7,此时刚才的任务并不能执行,因为刚才的任务round=1,必须要等到下一轮index=7的时候才能执行。

14.netty的心跳处理在弱网下怎么办。
在一定时间内,没有数据交互,即处于 idle 状态时,客服端或服务器端会发送一个数据给对方,即ping-pong,当某一端收到消息后,即证明tcp连接仍然存在。
15.netty的通讯协议是什么样的。
16.springmvc用到的注解,作用是什么,原理。
1.@Controller 负责处理DispatcherServlet分发的请求
2.@RequestMapping 处理请求地址映射,作用于类和方法上
3.@Autowired 根据类型注入
4.@Qualifier 当一个接口存在多个实现类时,可以根据名称注入
5.@ResponseBody 用于异步请求返沪json数据
6.@PathVariable 在使用Resultful风格开发时,可使用该注解配上对应url中参数的名称来获取参数的值
7.@RequestParam 两个属性value、required,value用来指定参数名称,required用来确定参数是否必须传入。
8.@RequestHeader 可以把request请求header部分的值绑定到参数上
9.@CookieValue 把request请求header中的cookie绑定到参数上
10.@RequestBody 可指定请求数据格式application/json, application/xml
11.@ModelAttribute 为请求绑定需要从后台获取的值
17.springboot启动机制。
Spring的ApplicationContext容器内部中的所有事件类型均继承自org.springframework.context.AppliationEvent,容器中的所有监听器都实现org.springframework.context.ApplicationListener接口,并且以bean的形式注册在容器中。一旦在容器内发布ApplicationEvent及其子类型的事件,注册到容器的ApplicationListener就会对这些事件进行处理。
1.SpringBoot整个启动流程分为两个步骤:初始化一个SpringApplication对象、执行该对象的run方法。
2.通过SpringFactoriesLoader查找并加载所有的SpringApplicationRunListeners,通过调用starting()方法通知所有的SpringApplicationRunListeners:应用开始启动了。
四、操作系统
1.Linux系统下你关注过哪些内核参数,说说你知道的。
/proc/sys/net/core/netdev_max_backlog
进入包的最大设备队列.默认是300,对重负载服务器而言,该值太低,可调整到1000
/proc/sys/net/core/somaxconn
listen()的默认参数,挂起请求的最大数量.默认是128.对繁忙的服务器,增加该值有助于网络性能.可调整到256.
/proc/sys/net/core/optmem_max
socket buffer的最大初始化值,默认10K
/proc/sys/net/ipv4/tcp_max_syn_backlog
进入SYN包的最大请求队列.默认1024.对重负载服务器,可调整到2048
/proc/sys/net/ipv4/tcp_retries2
TCP失败重传次数,默认值15,意味着重传15次才彻底放弃.可减少到5,尽早释放内核资源.
/proc/sys/net/ipv4/tcp_keepalive_time
/proc/sys/net/ipv4/tcp_keepalive_intvl
/proc/sys/net/ipv4/tcp_keepalive_probes
这3个参数与TCP KeepAlive有关.默认值是:
tcp_keepalive_time = 7200 seconds (2 hours)
tcp_keepalive_probes = 9
tcp_keepalive_intvl = 75 seconds
意思是如果某个TCP连接在idle 2个小时后,内核才发起probe.如果probe 9次(每次75秒)不成功,内核才彻底放弃,认为该连接已失效.对服务器而言,显然上述值太大. 可调整到:
/proc/sys/net/ipv4/tcp_keepalive_time 1800
/proc/sys/net/ipv4/tcp_keepalive_intvl 30
/proc/sys/net/ipv4/tcp_keepalive_probes 3
/proc/sys/net/ipv4/ip_local_port_range
指定端口范围的一个配置,默认是32768 61000,已够大.
net.ipv4.tcp_syncookies = 1
表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1
表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1
表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
net.ipv4.tcp_fin_timeout = 30
表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间。
net.ipv4.tcp_keepalive_time = 1200
表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为20分钟。
net.ipv4.ip_local_port_range = 1024 65000
表示用于向外连接的端口范围。缺省情况下很小:32768到61000,改为1024到65000。
net.ipv4.tcp_max_syn_backlog = 8192
表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_max_tw_buckets = 5000
表示系统同时保持TIME_WAIT套接字的最大数量,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。默认为 180000,改为 5000。对于Apache、Nginx等服务器,上几行的参数可以很好地减少TIME_WAIT套接字数量,但是对于Squid,效果却不大。此项参数可以控制TIME_WAIT套接字的最大数量,避免Squid服务器被大量的TIME_WAIT套接字拖死。
Linux上的NAT与iptables
谈起Linux上的NAT,大多数人会跟你提到iptables。原因是因为iptables是目前在linux上实现NAT的一个非常好的接口。它通过和内核级直接操作网络包,效率和稳定性都非常高。这里简单列举一些NAT相关的iptables实例命令,可能对于大多数实现有多帮助。
这里说明一下,为了节省篇幅,这里把准备工作的命令略去了,仅仅列出核心步骤命令,所以如果你单单执行这些没有实现功能的话,很可能由于准备工作没有做好。如果你对整个命令细节感兴趣的话,可以直接访问我的《如何让你的Linux网关更强大》系列文章,其中对于各个脚本有详细的说明和描述。
#案例1:实现网关的MASQUERADE
#具体功能:内网网卡是eth1,外网eth0,使得内网指定本服务做网关可以访问外网
EXTERNAL=“eth0”
INTERNAL=“eth1”
#案例2:实现网关的简单端口映射
#具体功能:实现外网通过访问网关的外部ip:80,可以直接达到访问私有网络内的一台主机192.168.1.10:80效果
LOCAL_EX_IP=11.22.33.44 #设定网关的外网卡ip,对于多ip情况,参考《如何让你的Linux网关更强大》系列文章
LOCAL_IN_IP=192.168.1.1 #设定网关的内网卡ip
INTERNAL=“eth1” #设定内网卡
查看当前系统支持的最大连接数
cat /proc/sys/net/ipv4/ip_conntrack_max
查看tcp连接超时时间
cat /proc/sys/net/ipv4/netfilter/ip_conntrack_tcp_timeout_established
值:默认432000(秒),也就是5天
#影响:这个值过大将导致一些可能已经不用的连接常驻于内存中,占用大量链接资源,从而可能导致NAT ip_conntrack: table full的问题
#建议:对于NAT负载相对本机的 NAT表大小很紧张的时候,可能需要考虑缩小这个值,以尽早清除连接,保证有可用的连接资源;如果不紧张,不必修改
实际生产环境服务器内核参数:
vm.swappiness = 0
net.ipv4.neigh.default.gc_stale_time = 120
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.default.arp_announce = 2
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_announce = 2
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 1024
net.ipv4.tcp_synack_retries = 2
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
fs.file-max=65535
net.core.somaxconn = 65535
vm.max_map_count=655360
2.Linux下IO模型有几种,各自的含义是什么。
五种io模型
1.阻塞式io,调用结果返回之前,当前线程会被挂起。
2.非阻塞式io,反复调用io函数,系统多次调用,并立即返回。在数据拷贝的过程中,进程是阻塞的。
3.io复用模型,主要是select和epoll,两次调用,两次返回,能同时对多个io进行监听。可同时对多个写操作和读操作进行监听。
4.信号驱动io,两次调用,两次返回,安装一个信号处理函数,进程继续运行,并不阻塞,当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据
5.异步io模型,当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者的输入输出操作。
3.epoll和poll有什么区别。
select :它通过一个select()系统调用来监视多个文件描述符的数组,当select()返回后,该数组中就绪的文件描述符便会被内核修改标志位,使得进程可以获得这些文件描述符从而进行后续的读写操作
poll : 它和select在本质上没有多大差别,但是poll没有最大文件描述符数量的限制。
epoll:epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,这样便彻底省掉了这些文件描述符在系统调用时复制的开销。
4.平时用到哪些Linux命令。
liunux常用命令
ls ,cd,mkdir,touch,vim,less,cat,find,more,cp,scp,ssh,man,mv,rm,rmdir,tail,fdisk,unzip,zip,tar,ifconfig,ps
5.用一行命令查看文件的最后五行。
tail -n 5 filename
6.用一行命令输出正在运行的java进程。
ps -ef |grep java
7.介绍下你理解的操作系统中线程切换过程。
什么时候切换
时间片轮转
线程阻塞
线程主动放弃时间片
过程,将旧的线程从内核切出,将新的线程切入。同时切换寄存器,程序计数器,线程栈,带来上下文切换。
8.进程和线程的区别。
进程:计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配的基本单位,是操作系统结构的基础,它的执行需要系统分配资源创建实体后,才能执行。
线程:线程是系统调度的基本单位,一个进程中可有多个线程。同一个进程中多个线程可以资源共享。
9.top 命令之后有哪些内容,有什么作用。
1.当前系统的中进程数,休眠线程数,总线程数。
10.线上CPU爆高,请问你如何找到问题所在。
1.通过top指令找到占用cpu高的进程。
2.得到该进程的进程号,pstree -p pid 查看该进程的线程信息。
3.cat /proc/进程号/task/线程号/status 查看该线程的详细信息
4.分析该线程大量占用cpu的原因
五、多线程
1.多线程的几种实现方式,什么是线程安全。
创建线程有3种方式。
1.继承于Thread类
2.实现Runable接口
3.实现Callable接口(可以有返回值,并且可抛出异常)
线程安全:理解过来也就是,乐观锁就是线程安全,悲观锁就是线程不安全。
乐观锁:在多线程的情况下执行一段代码,执行结果不会改变,并且百分之百确定。
悲观锁:在多线程的情况下执行一段代码,执行结果一定会发生改变,哪怕结果和预期的一样,程序也会认为它改变了。
2.volatile的原理,作用,能代替锁么。
原理作用:原子性,可见性,有序性
原子性:要么不执行,要么执行完毕。和事物提交和回滚相似。
可见性:保证变量的值是真实的,最新的
有序性:防止jvm对指令重排序,优化排序等。
原理:在线程操作变量时,每次都会先从主存中获取改变量的值,操作完之后会马上把值刷新到主存中去,保证主存的值是最新的。也就成就了可见性。
不能替代锁。
3.画一个线程执行流程

4.sleep和wait的区别。
sleep属于Thrad类方法。当前线程暂停执行,让出cpu给其他线程。但监控状态仍然存在,不会释放对象锁。
wait属于Object方法。会释放对象锁,进入等待对象的等待锁定池。只有针对此对象调用notify()方法或notifyAll()后本线程才进入对象锁定池准备
5.sleep和sleep(0)的区别。
sleep(0)如果线程调度器的可运行队列中有大于或等于当前线程优先级的就绪线程存在,操作系统会将当前线程从处理器上移除,调度其他优先级高的就绪线程运行;如果可运行队列中的没有就绪线程或所有就绪线程的优先级均低于当前线程优先级,那么当前线程会继续执行,就像没有调用 Sleep(0)一样。
sleep(timeout)会引发线程上下文切换:调用线程会从线程调度器的可运行队列中被移除一段时间,这个时间段约等于 timeout 所指定的时间长度。不会释放锁资源。
6.Lock与Synchronized的区别 。
Lock是java.util包下的一个接口。我们只需调用即可,需要手动释放锁。也是重量级锁。lock可明确的知道是否获得了锁,而synchronized不行,Lock可手动中断等待操作,synchronized不行
synchronized属于java关键字,可作用于方法和代码块,是重量级锁,不需要手动释放锁,不必担心出现死锁的情况。
如果在不熟悉多线程的使用,可以使用synchronized,尽量使用lock,在线程较多的,资源竞争较大的情况下,ReentrantLock的性能要高于synchronized。
7.synchronized的原理是什么,一般用在什么地方(比如加在静态方法和非静态方法的区别,静 态方法和非静态方法同时执行的时候会有影响吗),解释以下名词:重排序,自旋锁,偏向锁,轻量级锁,可重入锁,公平锁,非公平锁,乐观锁,悲观锁。
一般用在需要对某个方法或者某个代码块在多线程的情况下能够保持线程安全的情况下使用。
加在非静态方法上表示对象锁。
加在静态方法上表示类锁,也就是这个类的所有对象的类。重排序:java->.class : .class->汇编: 汇编->cpu指令。在这几个过程中,重排序是在不影响代码执行结果的情况下,对代码进行优化,重新排序。提高性能,但又不影响结果。
公平锁:是指多个线程按照申请锁的顺序来获取锁。
非公平锁:是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。
可重入锁:是自己可以再次获取自己的内部锁。举个例子,比如一条线程获得了某个对象的锁,此时这个对象锁还没有 释放,当其再次想要获取这个对象的锁的时候还是可以获取的(如果不可重入的锁的话,此刻会造成死锁)。说的更高深一点可重入锁是一种递归无阻塞的同步机制。对于Java ReentrantLock而言, 他的名字就可以看出是一个可重入锁,其名字是Re entrant Lock重新进入锁。对于Synchronized而言,也是一个可重入锁。可重入锁的一个好处是可一定程度避免死锁
共享锁: 是指该锁可被多个线程所持有
独享锁:是指该锁一次只能被一个线程所持有。
对于Java ReentrantLock(互斥锁)而言,其是独享锁。但是对于Lock的另一个实现类ReadWriteLock(读写锁),其读锁是共享锁,其写锁是独享锁。读锁的共享锁可保证并发读是非常高效的,读写,写读 ,写写的过程是互斥的。对于Synchronized而言,当然是独享锁。
互斥锁:
无法获取琐时,进线程立刻放弃剩余的时间片并进入阻塞(或者说挂起)状态,同时保存寄存器和程序计数器的内容(保存现场,上下文切换的前半部分),当可以获取锁时,进线程激活,等待被调度进CPU并恢复现场(上下文切换下半部分)上下文切换会带来数十微秒的开销,不要在性能敏感的地方用互斥锁.乐观锁/悲观锁
乐观锁与悲观锁不是指具体的什么类型的锁,而是指看待并发同步的角度。
悲观锁认为对于同一个数据的并发操作,一定是会发生修改的,哪怕没有修改,也会认为修改。因此对于同一个数据的并发操作,悲观锁采取加锁的形式。悲观的认为,不加锁的并发操作一定会出问题。乐观锁则认为对于同一个数据的并发操作,是不会发生修改的。在更新数据的时候,会采用尝试更新,不断重新的方式更新数据。乐观的认为,不加锁的并发操作是没有事情的。从上面的描述我们可以看出,悲观锁适合写操作非常多的场景,乐观锁适合读操作非常多的场景,不加锁会带来大量的性能提升。
悲观锁在Java中的使用,就是利用各种锁。
乐观锁在Java中的使用,是无锁编程,常常采用的是CAS算法,典型的例子就是原子类,通过CAS自旋实现原子操作的更新。
分段锁
分段锁其实是一种锁的设计,并不是具体的一种锁。对于ConcurrentHashMap而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作。
我们以ConcurrentHashMap来说一下分段锁的含义以及设计思想,ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap(JDK7与JDK8中HashMap的实现)的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表;同时又是一个ReentrantLock(Segment继承了ReentrantLock)。当需要put元素的时候,并不是对整个hashmap进行加锁,而是先通过hashcode来知道他要放在那一个分段中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行的插入。但是,在统计size的时候,可就是获取hashmap全局信息的时候,就需要获取所有的分段锁才能统计。分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
偏向锁:一段代码加上了synchronized,当只有一个线程访问时,这时锁会偏向这个线程,便是偏向锁
在这过程中,另外一个线程也想访问该代码的锁。这时候就升级成了轻量级锁。其他线程可以通过自旋的方式等待锁的获取,不会阻塞,提高性能,因为线程阻塞是很耗性能的
当自旋了一定次数都没得到该锁,便会升级为重量级锁,重量级锁便会让其他试图获得该锁的线程进入阻塞状态,从而影响性能。自旋锁:循环一次再次获取锁
8.用过哪些原子类,他们的原理是什么。
AtomicBoolean: 原子更新布尔类型。
AtomicInteger: 原子更新整型。
AtomicLong: 原子更新长整型。
AtomicIntegerArray: 原子更新整型数组里的元素。
AtomicLongArray: 原子更新长整型数组里的元素。
AtomicReferenceArray: 原子更新引用类型数组里的元素。
AtomicReference: 原子更新引用类型。
AtomicReferenceFieldUpdater: 原子更新引用类型的字段。
AtomicMarkableReferce: 原子更新带有标记位的引用类型,可以使用构造方法更新一个布尔类型的标记位和引用类型。
AtomicIntegerFieldUpdater: 原子更新整型的字段的更新器。
AtomicLongFieldUpdater: 原子更新长整型字段的更新器。
AtomicStampedFieldUpdater: 原子更新带有版本号的引用类型。
jdk1.8
DoubleAccumulator
LongAccumulator
DoubleAdder
LongAdder原理:底层采用CAS算法
CAS原理
CAS包含3个参数CAS(V,E,N).V表示要更新的变量, E表示预期值, N表示新值.
仅当V值等于E值时, 才会将V的值设为N, 如果V值和E值不同, 则说明已经有其他线程做了更新, 则当前线程什么
都不做. 最后, CAS返回当前V的真实值. CAS操作是抱着乐观的态度进行的, 它总是认为自己可以成功完成操作.
当多个线程同时使用CAS操作一个变量时, 只有一个会胜出, 并成功更新, 其余均会失败.失败的线程不会被挂起,
CAS整一个操作过程是一个原子操作, 它是由一条CPU指令完成的
9.JUC下研究过哪些并发工具,讲讲原理。
AQS(AbstractQueuedSynchronizer)
抽象队列同步器AQS:维护了一个volatile int state(代表共享资源)和一个FIFO线程等待队列(多线程争用资源被阻塞时会进入此队列)。
state: 来维护同步状态,
FIFO队列: 来完成资源获取线程的排队工作。
基于AQS的锁:
Reentrant
Semaphore
CountDownLatch
ReentrantReadWriteLock
SynchronousQueue
FutureTask并发容器
ConcurrentHashMap、ConcurrentSkipListMap、ConcurrentSkipListSet、 CopyOnWriteArrayList 和 CopyOnWriteArraySetCountDownLatch 闭锁
CountDownLatch是一个同步工具类,它允许一个或多个线程一直等待,直到其他线程的操作执行完后再执行Condition 控制线程通信
Condition 是需要结合具体Lock实现类使用的一种通信类接口。
Condition实例实质上被绑定到一个锁上。要为特定Lock 实例获得Condition 实例,请使用其newCondition() 方法。
10.用过线程池吗,如果用过,请说明原理,并说说newCache和newFixed有什么区别,构造函数的各个参数的含义是什么,比如coreSize,maxsize等。
任务队列:用于缓存提交的任务。
线程数量管理功能:一个线程池必须能够很好地管理和控制线程的数量。大致会有三个参数,创建线程池时的初始线程数量init;自动扩充时的最大线程数量max;在线程池空闲时需要释放资源但是也要维持一定数量的核心线程数量core。通过这三个基本参数维持好线程池中数量的合理范围,一般来说它们之间的关系是“init<=core<=max”。
任务拒绝策略:如果线程数量已达到上限且任务队列已满,则需要有相应的拒绝策略来通知任务的提交者。
线程工厂:主要用于个性化定制线程,如设置线程的名称或者将线程设置为守护线程等
newCache和newFixed区别
newCache
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue());
}
核心线程数为0,最大线程数为int的最大值, 当没有空闲线程时,任务等待的最长时间。
new Fixed
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue());
}coreSize:核心线程数;当有任务提交时,当前线程数小于coresize,即使有空闲线程,也会创建新的线程来执行u任务。
maxSize:最大线程数,当任务提交时,当前线程数等于maxsize,任务将处于等待队列,不会被执行。
11.线程池的关闭方式有几种,各自的区别是什么。
shutdown(), shutdownNow()
shutdown():当调用shutdown()之后,将不能继续添加任务,否则会抛出异常RejectedExecutionException。并且当正在执行的任务结束之后才会真正结束线程池。
shutdownNow():若线程中有执行sleep/wait/定时锁等,直接终止正在运行的线程并抛出 interrupt 异常。因为其内部是通过Thread.interrupt()实现的。 但是这种方法有很强的局限性。因为如果线程中没有执行sleep等方法的话,其无法终止线程。
先调用shutdown()使线程池状态改变为SHUTDOWN,线程池不允许继续添加线程,并且等待正在执行的线程返回。 调用awaitTermination设置定时任务,代码内的意思为 2s 后检测线程池内的线程是否均执行完毕(就像老师告诉学生,“最后给你 2s 钟时间把作业写完”),若没有执行完毕,则调用shutdownNow()方法。
12.假如有一个第三方接口,有很多个线程去调用获取数据,现在规定每秒钟最多有10个线程同时调用它,如何做到。
创建一个maxsize为10的线程池。调用一次接口,则使用线程池中的线程来执行该
13.spring的controller是单例还是多例,怎么保证并发的安全。
Java里有个API叫做ThreadLocal,spring单例模式下用它来切换不同线程之间的参数。用ThreadLocal是为了保证线程安全,实际上ThreadLoacal的key就是当前线程的Thread实例。单例模式下,spring把每个线程可能存在线程安全问题的参数值放进了ThreadLocal。这样虽然是一个实例在操作,但是不同线程下的数据互相之间都是隔离的,因为运行时创建和销毁的bean大大减少了,所以大多数场景下这种方式对内存资源的消耗较少,而且并发越高优势越明显。
14.用三个线程按顺序循环打印abc三个字母,比如abcabcabc。
public class Demo1 {
public static void main(String[] args) {
Demo1 demo1 = new Demo1();
PrintLetter printLetter = demo1.new PrintLetter();
new Thread(demo1.new PrintThread(printLetter, 'B')).start();
new Thread(demo1.new PrintThread(printLetter, 'A')).start();
new Thread(demo1.new PrintThread(printLetter, 'C')).start();
// Collections.synchronizedList()
}
private class PrintLetter {
private char letter = 'A';
public char getLetter() {
return letter;
}
public void print() {
System.out.print(letter);
if('C' == letter) {
System.out.println();
}
}
public void nextLetter() {
switch (letter) {
case 'A': {
letter = 'B';
break;
}
case 'B': {
letter = 'C';
break;
}
case 'C': {
letter = 'A';
break;
}
}
}
}
private class PrintThread implements Runnable {
private PrintLetter printLetter;
private char letter;
public PrintThread(PrintLetter printLetter, char letter) {
this.printLetter = printLetter;
this.letter = letter;
}
@Override
public void run() {
for(int i = 0; i < 10; i++) {
synchronized (printLetter) {
while(letter != printLetter.getLetter()) {
try {
printLetter.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
printLetter.print();
printLetter.nextLetter();
printLetter.notifyAll();
}
}
}
}15.ThreadLocal用过么,用途是什么,原理是什么,用的时候要注意什么。
当使用ThreadLocal存值时,首先是获取到当前线程对象,然后获取到当前线程本地变量Map,最后将当前使用的ThreadLocal和传入的值放到Map中,也就是说ThreadLocalMap中存的值是[ThreadLocal对象, 存放的值],这样做的好处是,每个线程都对应一个本地变量的Map,所以一个线程可以存在多个线程本地变量(即不同的ThreadLocal,就如1中所说,可以重写initialValue,返回不同类型的子类)。
16.如果让你实现一个并发安全的链表,你会怎么做。
细粒度锁,锁住需要修改的节点
将锁放到node里,每次需要修改的仅仅是部分节点,而不用把整个list锁住,这样能保证互不干扰的goroutine们可以同时处理list,而会互相干扰的goroutine则会被节点的mutex阻塞,以保证不存在竟态数据。
当然,为了保证不会有多个goroutine同时处理一个节点,我们需要在取得要修改节点的锁之前先取得前项节点的锁,然后才能取得修改节点的锁。这个步骤很像交叉手,它被称为锁耦合。
17.有哪些无锁数据结构,他们实现的原理是什么。
AtomicBoolean:
AtomicInteger:
AtomicLong:
AtomicIntegerArray:
AtomicLongArray:
AtomicReferenceArray:
AtomicReference:
AtomicReferenceFieldUpdater:
AtomicLongFieldUpdater:
AtomicStampedFieldUpdater:
实现原理:CAS算法,只执行cpu的一条指令,属于原子操作
18.讲讲java同步机制的wait和notify。
1.1 wait()方法,在其他线程调用notify和notifyAll方法之前,当前线程等待。
什么意思了,就是在当某一个线程在执行一个任务时,这个任务是一个方法,方法中有一个wait方法,当线程执行到这句时,就会停止执行,当前线程处于阻塞状态,但是会释放对象锁,意思就是会把钥匙交出去,这时候其他线程试图拿到了此对象锁,进行执行该任务,只有当执行到了任务里面的notify和notifyAll方法时,那个处于阻塞状态的线程才会被唤醒。
1.2 wait(long timeout)这个方法呢,和上一个方法类似,但是不同的一点是,就算没有其他线程来调用notify方法,当超过了它传入的时候后,线程也会被唤醒。2.notify和notifyAll
2.1 notify方法刚才应用上上面讲的wait()方法,调用notify方法后,便会唤醒在执行该任务的等待的单个线程。
2.2 notifyAll方法,与上面不同的便是,notify只会唤醒等待的单个线程,但如果有多个线程都是该任务的等待线程,这时便可以使用notifyAll唤醒所以的等待线程。
19.CAS机制是什么,如何解决ABA问题。
内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做
解决ABA问题
JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。如果当前引用 == 预期引用,并且当前标志等于预期标志,则以原子方式将该引用和该标志的值设置为给定的更新值。
20.多线程如果线程挂住了怎么办。
1.通过工具,如jstack,观察,各个线程的状态,找出挂掉的线程。
2.找到线程执行到的代码处,分析代码为什么会导致线程挂住
21.countdowlatch和cyclicbarrier的内部原理和用法,以及相互之间的差别(比如 countdownlatch的await方法和是怎么实现的)。
1.CountDownLatch减计数,CyclicBarrier加计数。
2.CountDownLatch是一次性的,CyclicBarrier可以重用。CountDownLatch:线程安全,内部维护一计数器,每执行一次downCount方法,计数器减一,await方法会阻塞线程执行,直到计数器为0时,才会继续await方法以后的代码。
CyclicBarrier:线程安全,内部维护一计数器,每执行一次await方法,计数器减一,await方法会阻塞当前所在线程,直到计数器为0时,会唤醒同一个Condition上所有线程,继续执行。new CyclicBarrier(3,new IntegrationData()),当使用两个参数的构造时,需要传一个线程,此时,计数器被减至0时,会执行这个线程,当线程执行完毕之后,才会唤醒同一个Condition上所有线程继续执行。
22.对AbstractQueuedSynchronizer了解多少,讲讲加锁和解锁的流程,独占锁和公平所加锁有什么不同。
队列同步器AbstractQueuedSynchronizer(以下简称同步器或AQS),是用来构建锁或者其他同步组件的基础框架,它使用了一个内置的int成员变量表示同步状态,通过内置的FIFO队列来完成资源获取线程的排队工作。
23.使用synchronized修饰静态方法和非静态方法有什么区别。
非静态:对类加锁
静态:对类型加锁
24.简述ConcurrentLinkedQueue和LinkedBlockingQueue的用处和不同之处。
ConcurrentLinkedQueue是Queue的一个安全实现.Queue中元素按FIFO原则进行排序.采用CAS操作,来保证元素的一致性。
LinkedBlockingQueue是一个线程安全的阻塞队列,它实现了BlockingQueue接口,BlockingQueue接口继承自java.util.Queue接口,并在这个接口的基础上增加了take和put方法,这两个方法正是队列操作的阻塞版本。
25.导致线程死锁的原因?怎么解除线程死锁。
产生死锁的原因:(1)竞争系统资源 (2)进程的推进顺序不当
产生死锁的必要条件:
互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
环路等待条件:在发生死锁时,必然存在一个进程–资源的环形链。解决死锁
加锁顺序(线程按照一定的顺序加锁)
加锁时限(线程尝试获取锁的时候加上一定的时限,超过时限则放弃对该锁的请求,并释放自己占有的锁)
死锁检测
26.非常多个线程(可能是不同机器),相互之间需要等待协调,才能完成某种工作,问怎么设计这种协调方案。
1.java的JUC包下有很多工具类,
2相互之间需要等待协调才能完成某中工作,这里可使用使用CountDownLatch,先初始化CountDownLatch指定一个线程数。在等待处设置CountDownlatch.await().每个线程调用一次countDown()方法,调用一次,计数减一,直到减少为0,才一起继续执行。
3.也可以使用CyclicBarraier,也给定一个初始值,所有线程在shutdown方法前进行等待,一个线程调用一次await方法计数加一,直到值加到与初始值相等时,这个几个线程才可以一起往后执行。
4.Phaser也可以完成。初始化对象,然后调用register()方法,进行注册,注册一次代表一个线程,线程调用一次arriveAndAwaitAdvance方法,代表使用一次,直到所有注册的都使用完之后,才继续往下走。
5.CyclicBrraier和Phaser是可以进行重用的。
27.用过读写锁吗,原理是什么,一般在什么场景下用。
在Java中ReadWriteLock的主要实现为ReentrantReadWriteLock,其提供了以下特性:
公平性选择:支持公平与非公平(默认)的锁获取方式,吞吐量非公平优先于公平。
可重入:读线程获取读锁之后可以再次获取读锁,写线程获取写锁之后可以再次获取写锁
可降级:写线程获取写锁之后,其还可以再次获取读锁,然后释放掉写锁,那么此时该线程是读锁状态,也就是降级操作。
28.开启多个线程,如果保证顺序执行,有哪几种实现方式,或者如何保证多个线程都执行完 再拿到结果。
1:通过调用join方法
2:通过调用Object的wait,notify和notifyAll方法。
29.延迟队列的实现方式,delayQueue和时间轮算法的异同。
DelayQueue本质是封装了一个PriorityQueue,使之线程安全,加上Delay功能,也就是说,消费者线程只能在队列中的消息“过期”之后才能返回数据获取到消息,不然只能获取到null。
六、TCP与HTTP
1.http1.0和http1.1有什么区别。
HTTP 1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。
HTTP 1.1则支持持久连接Persistent Connection, 并且默认使用persistent connection. 在同一个tcp的连接中可以传送多个HTTP请求和响应. 多个请求和响应可以重叠,多个请求和响应可以同时进行. 更加多的请求头和响应头(比如HTTP1.0没有host的字段).
在1.0时的会话方式:建立连接
发出请求信息
回送响应信息
关掉连接
2.TCP三次握手和四次挥手的流程,为什么断开连接要4次,如果握手只有两次,会出现什么。
第一次握手:主机A发送位码为syn=1,随机产生seq number=1234567的数据包到服务器,主机B由SYN=1知道,A要求建立联机;
第二次握手:主机B收到请求后要确认联机信息,向A发送ack number=(主机A的seq+1),syn=1,ack=1,随机产生seq=7654321的包
第三次握手:主机A收到后检查ack number是否正确,即第一次发送的seq number+1,以及位码ack是否为1,若正确,主机A会再发送ack number=(主机B的seq+1),ack=1,主机B收到后确认seq值与ack=1则连接建立成功。(1)客户端A发送一个FIN,用来关闭客户A到服务器B的数据传送。
(2)服务器B收到这个FIN,它发回一个ACK,确认序号为收到的序号加1。和SYN一样,一个FIN将占用一个序号。
(3)服务器B关闭与客户端A的连接,发送一个FIN给客户端A。
(4)客户端A发回ACK报文确认,并将确认序号设置为收到序号加1。如果不是4次握手,b服务器收到fin后,直接传fin回a,a直接返回ack,3次关闭连接,那么在b直接传fin后,此时还有一部分数据可能还在传输,关闭之后这部分数据就不会传输完成,
握手两次,a发送syn给b服务器,b服务器返回ack给a,如果没有第三次a返回adc,那么如果b给a的ack在网络中逗留了,a收不到ack,就认为连接不建立,而b觉得自己已经发出ack了,连接需要建立,这就造成了矛盾。
3.TIME_WAIT和CLOSE_WAIT的区别。
TIME_WAIT表示主动关闭,CLOSE_WAIT表示被动关闭
4.说说你知道的几种HTTP响应码,比如200, 302, 404。
200:访问成功(表示一切正常,返回的是正常请求结果)
302:临时重定向(指出被请求的文档已被临时移动到别处,此文档的新的URL在Location响应头中给出)
304:未修改(表示客户机缓存的版本是最新的,客户机应该继续使用它。)
404:访问的文件不存在(服务器上不存在客户机所请求的资源)
500:内部服务器错误(服务器端的CGI、ASP、JSP等程序发生错误)
5.当你用浏览器打开一个链接(如:http://www.javastack.cn)的时候,计算机做了哪些工作步骤。
1.在浏览器中输入该域名
2.浏览器通过DNS查找该域名的IP地址
a.浏览器先在浏览器缓存中查找,(一般默认保存2-30分钟)
b.如果在浏览器没找到记录,将在系统缓存中查找,windows系统会调用gethostbyname。
c.如果在系统缓存中没找到,会在路由缓存中查找,
d.ISP DNS 缓存 – 接下来要check的就是ISP缓存DNS的服务器。在这一般都能找到相应的缓存记录。
e.递归搜索 – 你的ISP的DNS服务器从跟域名服务器开始进行递归搜索,从.com顶级域名服务器到Facebook的域名服务器。一般DNS服务器的缓存中会有.com域名服务器中的域名,所以到顶级服务器的匹配过程不是那么必要了。
3.浏览器给web服务器发送一个HTTP请求
4.服务器响应消息到客服端
5.浏览器获取到服务端的消息,进行解析,解析成html页面,
6.TCP/IP如何保证可靠性,说说TCP头的结构。
可靠性
1.是一个长连接
2.面向流,数据按顺序投递
3.tcp发出一个报文后,会启动一个定时器,等待响应报文,如果接收不到响应报文,将重发次消息
7.如何避免浏览器缓存。
1.请求时想要禁用缓存, 可以设置请求头:Cache-Control: no-cache, no-store, must-revalidate
2.增加版本号给请求的资源增加一个版本号,这是一种常用做法,
3.使用HTML禁用缓存HTML也可以禁用缓存, 即在页面的head标签中加入meta标签。
8.如何理解HTTP协议的无状态性。
无状态,即上一次提交的请求与这次无关,下一次提交的请求与这次也无关,服务器不会保存用户的状态。
9.简述Http请求get和post的区别以及数据包格式。
>http请求数据包的格式:头部(request line + header)+ 数据(data)
>GET:url包含参数,数据长度有限,传输不够安全
>POST:url不包含参数,传输安全
10.HTTP有哪些method
>GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT
11.简述HTTP请求的报文格式。
>请求行(request line)、请求头部(header)、空行 和 请求数据(request data) 四个部分组成。
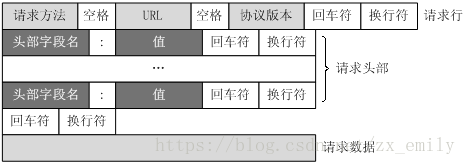
GET /admin_ui/rdx/core/images/close.png HTTP/1.1
Accept: /
Referer: http://xxx.xxx.xxx.xxx/menu/neo
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET4.0C; .NET4.0E)
Accept-Encoding: gzip, deflate
Host: xxx.xxx.xxx.xxx
Connection: Keep-Alive
Cookie: startupapp=neo; is_cisco_platform=0; rdx_pagination_size=250%20Per%20Page; SESSID=deb31b8eb9ca68a514cf55777744e339
12.HTTP的长连接是什么意思。
HTTP1.1规定了默认保持长连接(HTTP persistent connection ,也有翻译为持久连接),数据传输完成了保持TCP连接不断开(不发RST包、不四次握手),等待在同域名下继续用这个通道传输数据;相反的就是短连接。
13.HTTPS的加密方式是什么,讲讲整个加密解密流程。
HTTPS就是使用SSL/TLS协议进行加密传输,让客户端拿到服务器的公钥,然后客户端随机生成一个对称加密的秘钥,使用公钥加密,传输给服务端,后续的所有信息都通过该对称秘钥进行加密解密,完成整个HTTPS的流程。
14.Http和https的三次握手有什么区别。
1.https协议需要到ca申请证书或自制证书。
http的信息是明文传输,https则是具有安全性的ssl加密。
http是直接与TCP进行数据传输,而https是经过一层SSL(OSI表示层),用的端口也不一样,前者是80(需要国内备案),后者是443。
http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
15.什么是分块传送。
对于在发送HTTP头部前,无法计算出Content-Length的HTTP请求及回复(例如WEB服务端产生的动态内容),可以使用分块传输,使得不至于等待所有数据产生后,再发送带有Content-Length的HTTP头部,而是将已经产生的数据一块一块发送出去。
16.Session和cookie的区别。
session 在服务器端,cookie 在客户端(浏览器)
session 默认被存在在服务器的一个文件里(不是内存)
session 的运行依赖 session id,而 session id 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,同时 session 也会失效(但是可以通过其它方式实现,比如在 url 中传递 session_id)
session 可以放在 文件、数据库、或内存中都可以。
七、架构设计与分布式
1.用java自己实现一个LRU。
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
public class LRU1 {
private final int MAX_CACHE_SIZE;
private final float DEFAULT_LOAD_FACTORY = 0.75f;
LinkedHashMap map;
public LRU1(int cacheSize) {
MAX_CACHE_SIZE = cacheSize;
int capacity = (int)Math.ceil(MAX_CACHE_SIZE / DEFAULT_LOAD_FACTORY) + 1;
/*
* 第三个参数设置为true,代表linkedlist按访问顺序排序,可作为LRU缓存
* 第三个参数设置为false,代表按插入顺序排序,可作为FIFO缓存
*/
map = new LinkedHashMap(capacity, DEFAULT_LOAD_FACTORY, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_CACHE_SIZE;
}
};
}
public synchronized void put(K key, V value) {
map.put(key, value);
}
public synchronized V get(K key) {
return map.get(key);
}
public synchronized void remove(K key) {
map.remove(key);
}
public synchronized Set> getAll() {
return map.entrySet();
}
@Override
public String toString() {
StringBuilder stringBuilder = new StringBuilder();
for (Map.Entry entry : map.entrySet()) {
stringBuilder.append(String.format("%s: %s ", entry.getKey(), entry.getValue()));
}
return stringBuilder.toString();
}
public static void main(String[] args) {
LRU1 lru1 = new LRU1<>(5);
lru1.put(1, 1);
lru1.put(2, 2);
lru1.put(3, 3);
System.out.println(lru1);
lru1.get(1);
System.out.println(lru1);
lru1.put(4, 4);
lru1.put(5, 5);
lru1.put(6, 6);
System.out.println(lru1);
}
}
2.分布式集群下如何做到唯一序列号。
1、 数据库自增长序列或字段
2、UUID
3、Redis生成ID
4、Twitter的snowflake算法
5、利用zookeeper生成唯一ID
3.设计一个秒杀系统,30分钟没付款就自动关闭交易。
4.如何使用redis和zookeeper实现分布式锁?有什么区别优缺点,会有什么问题,分别适用什么场景。(延伸:如果知道redlock,讲讲他的算法实现,争议在哪里)
5.如果有人恶意创建非法连接,怎么解决。
6.分布式事务的原理,优缺点,如何使用分布式事务,2pc 3pc 的区别,解决了哪些问题,还有哪些问题没解决,如何解决,你自己项目里涉及到分布式事务是怎么处理的。
7.什么是一致性hash。
一致性hash为了解决什么问题(在分布式系统中)
1.负载均衡
2.分布式缓存
hash函数通过将原始值进行计算之后产生一个hash值。
原理:
在分布式系统中,有3台服务器,现在有20个客户端的请求。我们引入一致性hash目的就是尽量让每台服务器都能处理请求,并且处理数量想差最小。有一个hash环,hash环的值从0到最大整数,每台服务器的ip通过hash后得到一个值,这个值一定落在这个hash环上。我们的请求通过hash计算后也得到一个值,这个值同样落在hash环上。然后让这个请求值顺时针查找最近的服务器,就由这台服务器处理请求。
问题:
在这过程中,服务器在环上分配不均匀,各服务器之间处理请求数量想差较大。服务器数量较少的时候容易出现该问题,也叫hash倾斜
解决
引入虚拟节点,我们可为每台服务器引入一个虚拟节点,最后就相当于换上有6个节点。
8.什么是restful,讲讲你理解的restful。
什么是restful
一种架构风格,设计风格。
用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
使用的是标准的 HTTP 方法,比如 GET、PUT、POST 和 DELETE。
9.如何设计一个良好的API。
一 规范性建议
1.职责原则
2.单一性原则
3.协议规范
4.路径规则
5.跨域考虑
6.适度过滤信息
7.返回数据格式
8.安全性原则
9.可扩展性原则
10.定义api界限
11.定义api返回码
10.如何设计建立和保持100w的长连接。
11.解释什么是MESI协议(缓存一致性)。
在cpu存在多个一级缓存时,能够保证不同缓存数据的一直性。
12.说说你知道的几种HASH算法,简单的也可以。
加法Hash;
位运算Hash;
乘法Hash;
除法Hash;
查表Hash;
混合Hash;
13.什么是paxos算法, 什么是zab协议。
Paxos算法解决的问题是在一个可能发生消息可能会延迟、丢失、重复的分布式系统中如何就某个值达成一致,保证不论发生以上任何异常,都不会破坏决议的一致性。
这 个“值”可能是一个数据的某,也可能是一条LOG等;根据不同的应用环境这个“值”也不同。
一个典型的场景是,在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点都执行相同的操作序列,那么他们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个“一致性算法”以保证每个节点看到的指令一致。ZAB协议并不像Paxos算法和Raft协议一样,是通用的分布式一致性算法,它是一种特别为ZooKeeper设计的崩溃可恢复的原子广播算法。ZAB协议的核心是定义了对应那些会改变ZooKeeper服务器数据状态的事务请求的处理方式,即:
所有事务请求必须由一个全局唯一的服务器来协调处理,这样的服务器被称为Leader服务器,而剩下的其他服务器则成为Follower服务器(当然还有Observer)。Leader服务器负责将一个客户端事务请求转换成一个事务Proposal(提案)并将该Proposal分发给集群中所有的Follower服务器。之后Leader服务器需要等待所有Follower服务器的反馈,一旦超过半数的Follower服务器进行了正确的反馈后,Leader就会再次向所有的Follower服务器分发Commit消息,要求对刚才的Proposal进行提交。
14.说说你平时用到的设计模式。
单列模式
简单工厂
工厂方法
抽象工厂
适配器模式
动态代理
责任链
八、算法
1.10亿个数字里里面找最小的10个。
首先,对于这种海量数据,我们需要进行分块处理,涉及到分布式计算。可以合理的将数据分成n个快,对每一个快作处理,找出其中最小的10个数字。再找出这10个数字时便对这10个数字排好序,最大的数字在二叉树的根节点
再将每个块的最小数取出。作为一个块,还是同样的算法,找出其中最小的10个数。
这时候我们得到所需要的数字也就只有10*10=100个数字了。从一100个数字中再用同样的算法找出10个数,对于100个数,无论采用哪种排序,时间复杂度哪怕为O(n2)也不会太长。
操作步骤如上。设计到的算法,也就是从一堆数据找出最小的10个,并进行二叉树排序。
package com.LRU;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class Test1 {
public static void main(String[] args) {
int[] arry = {21,3,12,32,12,54,65,23,959,32,124,3235,0,21,43,45,12,1,43};
List list = new ArrayList();
for(int i = 0;i < arry.length; i++) {
//如果当前链表大小小于10,则直接进行插入
if(list.size()<10) {
put(list,arry[i]);
continue;
}
//如果数字大于链表的首位。则不进行后续操作
if(arry[i] > (int)list.get(0))
continue;
put(list,arry[i]);
}
System.out.println(list.toString());
}
private static void put(List list, int num) {
if(list.size() < 10) {
list.add(num);
Collections.sort(list);
Collections.sort(list,new Comparator() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
return;
}
list.remove(0);
list.add(num);
Collections.sort(list,new Comparator() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
}
}
运行结果:[32, 23, 21, 21, 12, 12, 12, 3, 1, 0]
我这里使用的是链表,而且每次插入过后还要排序。正确的应该使用最大堆。
2.给一个不知道长度的(可能很大)输入字符串,设计一种方案,将重复的字符排重。
1.一般情况下,我们可能会想到读取一个字符,将这个字符与前面读取完成的字符进行比较,如果相同则舍去,如果不同则新曾在数组里面,但是这样的做的最坏的时间复杂度为n的阶乘。
2.其实在java 里面字符的为两个字符,我们可以自己写一个hashmap,map的容量就为1<<15,将获取hashCode的方法改一下hashcode的二进制值就为该字符的二进制值,这样每一个字符的key就都不一样,也不会产生hash冲突,value则为该字符本身,而相同的字符,必然将前面一个覆盖掉。
3.将这个字符串的所以字符都保存在map中后,通过迭代器遍历该map.得到的字符将不会有重复的了。
3.遍历二叉树。
// 前序递归
public static void preOrderRecursion(BinTreeNode top) {
if (top != null) {
System.out.println(top.data);
preOrderRecursion(top.lchild);
preOrderRecursion(top.rchild);
}
}
// 中序递归
public static void inOrderRecursion(BinTreeNode top) {
if (top != null) {
inOrderRecursion(top.lchild);
System.out.println(top.data);
inOrderRecursion(top.rchild);
}
}
// 后序递归
public static void postOrderRecursion(BinTreeNode top) {
if (top != null) {
postOrderRecursion(top.lchild);
postOrderRecursion(top.rchild);
System.out.println(top.data);
}
}4.写一个字符串(如:www.javastack.cn)反转函数。
package com.test.util;
public class Test1 {
public static void main(String[] args) {
System.out.println(reverse("www.javastack.cn"));
}
public static String reverse(String str){
char[] newStr=new char[str.length()];
//循环字符串长度的1/2.
for(int i=0;i按理来说反转字符串应该遍历整个字符串长度,单其实反转,也就是找到字符串位于最中间那个字符,然后将两边的字符进行位置交换,所以这样做时间复杂度减少了一般。为O(n/2)
5.常用的排序算法,快排,归并、冒泡。 快排的最优时间复杂度,最差复杂度。冒泡排序的优化方案。
排序方法 最坏时间复杂度 最好时间复杂度 平均时间复杂度
直接插入 O(n2) O(n) O(n2)
简单选择 O(n2) O(n2) O(n2)
起泡排序 O(n2) O(n) O(n2)
快速排序 O(n2) O(nlog2n) O(nlog2n)
堆排序 O(nlog2n) O(nlog2n) O(nlog2n)
归并排序 O(nlog2n) O(nlog2n) O(nlog2n)
6.二分查找的时间复杂度,优势。
log2(n)
优势:当然是减少了时间复杂度
7.200个有序的数组,每个数组里面100个元素,找出top20的元素。
比较每个数组的最大值,找出top20的数组为20个数组
九、数据库知识
1.数据库隔离级别有哪些,各自的含义是什么,MYSQL默认的隔离级别是是什么。
1.READ UNCIMMITTED(未提交读)
事务中的修改,即使没有提交,其他事务也可以看得到,比如说上面的两步这种现象就叫做脏读,这种隔离级别会引起很多问题,如无必要,不要随便使用
例子:还是售票系统,小明和小花是售票员,他们分别是两个不同窗口的员工,现在售票系统只剩下3张票,此时A来小华这里买3张票,B来小明买票,小华查到余票还有就给接了订单,就要执行第三步的时候,小明接到B的请求查询有没有余票。看到小华卖出了3张票,于是拒绝卖票。但是小华系统出了问题,第三步执行失败,数据库为保证原子性,数据进行了回滚,也就是说一张票都没卖出去。
总结:这就是事务还没提交,而别的事务可以看到他其中修改的数据的后果,也就是脏读。
2.READ COMMITTED(提交读)
大多数数据库系统的默认隔离级别是READ COMMITTED,这种隔离级别就是一个事务的开始,只能看到已经完成的事务的结果,正在执行的,是无法被其他事务看到的。这种级别会出现读取旧数据的现象
例子:还是小明小华销售员,余票3张,A来小华那里请求3张订票单,小华接受订单,要卖出3张票,上面的销售步骤执行中的时候,B也来小明那里买票,由于小华的销售事务执行到一半,小明事务没有看到小华的事务执行,读到的票数是3,准备接受订单的时候,小华的销售事务完成了,此时小明的系统变成显示0张票,小明刚想按下鼠标点击接受订单的手又连忙缩了回去。
总结:这就是小华的事务执行到一半,而小明看不到他执行的操作,所以看到的是旧数据,也就是无效的数据
3.REPEATABLE READ(可重复读)
REPEATABLE READ解决了脏读的问题,该级别保证了每行的记录的结果是一致的,也就是上面说的读了旧数据的问题,但是却无法解决另一个问题,幻行,顾名思义就是突然蹦出来的行数据。指的就是某个事务在读取某个范围的数据,但是另一个事务又向这个范围的数据去插入数据,导致多次读取的时候,数据的行数不一致。
例子:销售部门有规定,如果销售记录低于规定的值,要扣工资,此时经理在后端控制台查看了一下小明的销售记录,发现销售记录达不到规定的次数,心里暗喜,准备打印好销售清单,理直气壮和小明提出,没想到打印出来的时候发现销售清单里面销售数量增多了几条,刚刚好达到要求,气的经理撕了清单纸。原来是小明在就要打印的瞬间卖出了几张票,因此避过了减工资的血光之灾。
总结:虽然读取同一条数据可以保证一致性,但是却不能保证没有插入新的数据
4.SERIALIZABLE(可串行化)
SERIALIZABLE是最高的隔离级别,它通过强制事务串行执行(注意是串行),避免了前面的幻读情况,由于他大量加上锁,导致大量的请求超时,因此性能会比较底下,再特别需要数据一致性且并发量不需要那么大的时候才可能考虑这个隔离级别
mysql默认的隔离级别,repeatable-read(可重复读
2.MYSQL有哪些存储引擎,各自优缺点。
介绍5类常见的mysql存储引擎
1.MySAM
不支持事务,不支持外键,访问速度快,
2.InnoDB
健壮的事务型存储引擎,外键约束,支持自动增加AUTO_INCREMENT属性。
3.MEMORY
响应速度快,数据不可恢复
4.MERGE
meger表是几个相同的MyISAM表的聚合器
5.ARCHIVE
拥有很好的压缩机制,在记录被请求时会实时压缩,经常被用来当做仓库使用。
3.高并发下,如何做到安全的修改同一行数据。
1.悲观锁:
一旦某个线程获取了该锁,其他线程只有等到,不过当请求过多时,就会出现大量的线程等待,有可能造成连接数耗尽。
2.缓存队列
缓存队列,一次只允许一个请求,每个请求都有机会获取到该数据,但是当请求数远远大于队列的消费者的消耗数时,队列便会被撑满。
3.乐观锁
采用宽松的加锁机制,采用带版本号更新,每个请求都会获取到一个版本号,只有版本号符合的才能更新成功,其他的返回更新失败。
4.乐观锁和悲观锁是什么,INNODB的标准行级锁有哪2种,解释其含义。
1 乐观锁,就是你加不加锁,它的运行结果都一样,不会有什么改变。那还需要锁干嘛
2 悲观锁,多个线程同时执行一段代码,不加锁,一定会发生改变。
InnoDB行级锁
共享锁:允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁
排他锁:允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享锁和排他锁。
十、消息队列
1.消息队列的使用场景。
消息队列主要是为了解决应用耦合,异步消息,流量削峰等问题,
实现高性能,高可用,可伸缩和最终一致性架构。
消息队列:ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ。
1.异步处理
2.应用解耦
3.流量削峰
4.日志处理
2.消息的重发,补充策略。
在MQ中,当消费者消费消息产生异常时,消费者会把消息放入一个特殊队列中,进行下次处理,这就是消息的重发。
3.如何保证消息的有序性。
消息队列的底层数据实现便是队列,先进先出,便保证了消息的有序性。
4.用过哪些MQ,和其他mq比较有什么优缺点,MQ的连接是线程安全的吗,你们公司的MQ服务架构怎样的。
ActiveMQ,RabbitMQ,Kafka,RocketMQ,ZeroMQ
RabbitMQ:采用Erlang语言实现的AMQP协议的消息中间件。优点,可靠性,可用性,扩展性,功能丰富。
Kafka:一个分布式,多分区,多副本基于zookeeper协调的分布式消息系统、高吞吐量的分布式发布订阅消息系统。
5.MQ系统的数据如何保证不丢失。
1.消息持久化
1)Exchange 设置持久化
2)Queue设置持久化
3)Message持久化发送,发送消息设置发送模式deliveryMode=2,代表持久化消息
2.ACK确认机制
消费端消费完成时需要通知服务端,服务端才把消息从内存中删除
3.设置集群镜像模式
6.rabbitmq如何实现集群高可用。
RabbitMQ分为3种模式
1.单一模式(非集群模式)
2.普通模式(默认的集群模式)
3.镜像模式
7.kafka吞吐量高的原因。
1.顺序读写
2.零拷贝
3.分区
4.批量发送
5.数据压缩
8.kafka 和其他消息队列的区别,kafka 主从同步怎么实现。
高性能跨语言分布式发布/订阅消息队列系统
快速持久化,可以在O(1)的系统开销下进行消息持久化;
高吞吐,在一台普通的服务器上既可以达到10W/s的吞吐速率;
完全的分布式系统,Broker、Producer、Consumer都原生自动支持分布式,自动实现负载均衡;
支持Hadoop数据并行加载,对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka通过Hadoop的并行加载机制统一了在线和离线的消息处理。
一个非常轻量级的消息系统,除了性能非常好之外,还是一个工作良好的分布式系统。
9.利用mq怎么实现最终一致性。
利用事件表,事件表为中间表,修改其状态保证事务一致性。
10.MQ有可能发生重复消费,如何避免,如何做到幂等。
比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update 一下好吧。
比如你是写 Redis,那没问题了,反正每次都是 set,天然幂等性。
比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个全局唯一的 id,类似订单 id 之类的东西,然后你这里消费到了之后,先根据这个 id 去比如 Redis 里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个 id 写 Redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
比如基于数据库的唯一键来保证重复数据不会重复插入多条。因为有唯一键约束了,重复数据插入只会报错,不会导致数据库中出现脏数据。
十一、缓存
1.常见的缓存策略有哪些,如何做到缓存(比如redis)与DB里的数据一致性,你们项目中用到了什么缓存系统,如何设计的。
如果以Redis为主,DB只是作为数据的一种备份或持久化方案,可以不用太过在意数据一致性问题,这时所有的应用服务器对数据的操作都在Redis中,数据Redis层数据是一致的,数据操作不会穿透到DB层。
2.如何防止缓存击穿和雪崩。
线程互斥:只让一个线程构建缓存,其他线程等待构建缓存的线程执行完,重新从缓存获取数据才可以,每个时刻只有一个线程在执行请求,减轻了db的压力,但缺点也很明显,降低了系统的qps。
交错失效时间:这种方法时间比较简单粗暴,既然在同一时间失效会造成请求过多雪崩,那我们错开不同的失效时间即可从一定长度上避免这种问题,在缓存进行失效时间设置的时候,从某个适当的值域中随机一个时间作为失效时间即可。双重校验(Dubbo Check)类似线程安全的懒汉单例模式实现,保证只会有一个线程去访问数据库
3.缓存数据过期后的更新如何设计。
更新缓存的设计模式有四种:Cache aside, Read through, Write through, Write behind caching
Cache aside
读取:
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
命中:应用程序从cache中取数据,取到后返回。
更新:先把数据存到数据库中,成功后,再让缓存失效。
4.redis的list结构相关的操作。
lpush
rpush
linsert
lset
lrem
ltrim
lpop
rpoplpush
lindex
llen
5.Redis的数据结构都有哪些。
String
List
set
hash
sorted set:有序集合
6.Redis的使用要注意什么,讲讲持久化方式,内存设置,集群的应用和优劣势,淘汰策略等。
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。在配置文件有一行:
#maxmemory-policy volatile-lru
对应的策略
noeviction:当内存使用达到阈值的时候,所有引起申请内存的命令会报错。
allkeys-lru:在主键空间中,优先移除最近未使用的key。(推荐)
volatile-lru:在设置了过期时间的键空间中,优先移除最近未使用的key。
allkeys-random:在主键空间中,随机移除某个key
volatile-random:在设置了过期时间的键空间中,随机移除某个key。
volatile-ttl:在设置了过期时间的键空间中,具有更早过期时间的key优先移除。
7.redis2和redis3的区别,redis3内部通讯机制。
前者是一个完全无中心的设计,节点之间通过gossip方式传递集群信息,数据保证最终一致性
后者是一个中心化的方案设计,通过类似一个分布式锁服务来保证强一致性,数据写入先写内存和redo log,然后定期compat归并到磁盘上,将随机写优化为顺序写,提高写入性能。
8.Redis的并发竞争问题如何解决,了解Redis事务的CAS操作吗。
某个时刻,多个系统实例都去更新某个 key。可以基于 zookeeper 实现分布式锁。每个系统通过 zookeeper 获取分布式锁,确保同一时间,只能有一个系统实例在操作某个 key,别人都不允许读和写。
12.Redis的选举算法和流程是怎样的。
哨兵节点监控数据节点
1.所有从数据节点监控挂了,然后,中止复制主数据节点
2.所有哨兵节点监控挂了,然后,判断是否超过下线时长
3.如果超过下线时长,那么leader哨兵节点将会进行故障转移
13.redis的持久化的机制,aof和rdb的区别。
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
14.redis的集群怎么同步的数据的.
1、redis没有像mysql那样复制位置的概念,所以Slave和Master断开连接再重新连接时,会全量取Master的快照,Slave的所有数据都会清除,重新建立整个内存表,这样导致Salve恢复数据特别慢,同时也给Master带来的压力。
2、通过主动复制解决redis本身复制的缺陷,即通过业务端或代理中间件对redis中的数据进行多份存储。Twitter开发的用于复制和分区的中间件gizzard(https://github.com/twitter/gizzard)。
主动复制虽然解决了被动复制的延迟问题,但却带来了数据一致性问题。
3、缓存数据失效策略?
15.知道哪些redis的优化操作。
尽量使用短的key
避免使用keys *
在存到Redis之前先把你的数据压缩下
设置 key 有效期
选择回收策略(maxmemory-policy)
使用bit位级别操作和byte字节级别操作来减少不必要的内存使用。
尽可能地使用hashes哈希存储。
当业务场景不需要数据持久化时,关闭所有的持久化方式可以获得最佳的性能。
想要一次添加多条数据的时候可以使用管道。
限制redis的内存大小(64位系统不限制内存,32位系统默认最多使用3GB内存)
16.Reids的主从复制机制原理。
1、一个master可以有多个slave
2、一个slave只能有一个master
3、数据流向是单向的,master到slave
17.Redis的线程模型是什么。
Redis 基于 Reactor 模式开发了自己的网络事件处理器: 这个处理器被称为文件事件处理器(file event handler):
十二、搜索