POI导出Excel (满满的干货啊)
已经实现的POI导出Excel
步骤一:导入依赖
org.apache.poi
poi
4.1.2
org.apache.poi
poi-ooxml
4.1.2
这块是导出,并不需要实体类中的类型上的注解的添加
easyExcel并不能实现实体类中有实体类的属性或者是LIST类型的属性
因此使用EASYPOI
步骤二:重写poi的导出方法
/**
* 导出Ecel
*
* @return org.apache.poi.ss.usermodel.Workbook
* @author zhuyongsheng
* @date 2019/11/6
*/
private static Workbook exportExcel(List<Map<String, Object>> list, ExcelType type) {
Workbook workbook = new HSSFWorkbook();
for (Map<String, Object> map : list) {
MyExcelExportService service = new MyExcelExportService();
service.createSheetWithList(workbook, (ExportParams) map.get("title"), ExportParams.class, (List<ExcelExportEntity>) map.get("entityList"), (Collection<?>) map.get("data"));
}
return workbook;
}
步骤三:重写校验将Data中的值给Sheet的服务
MyExcelExportService
import cn.afterturn.easypoi.excel.annotation.ExcelTarget;
import cn.afterturn.easypoi.excel.entity.ExportParams;
import cn.afterturn.easypoi.excel.entity.enmus.ExcelType;
import cn.afterturn.easypoi.excel.entity.params.ExcelExportEntity;
import cn.afterturn.easypoi.excel.export.ExcelExportService;
import cn.afterturn.easypoi.exception.excel.ExcelExportException;
import cn.afterturn.easypoi.exception.excel.enums.ExcelExportEnum;
import cn.afterturn.easypoi.util.PoiPublicUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.poi.ss.usermodel.Workbook;
import java.lang.reflect.Field;
import java.util.Collection;
import java.util.List;
/**
* @program: pc
* @description
* @author: yangtao
* @create: 2021-06-29 13:17
**/
@Slf4j
public class MyExcelExportService extends ExcelExportService {
public void createSheetWithList(Workbook workbook, ExportParams entity, Class<?> pojoClass, List<ExcelExportEntity> entityList, Collection<?> dataSet) {
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("Excel export start ,class is {}", pojoClass);
LOGGER.debug("Excel version is {}",
entity.getType().equals(ExcelType.HSSF) ? "03" : "07");
}
if (workbook == null || entity == null || pojoClass == null || dataSet == null) {
throw new ExcelExportException(ExcelExportEnum.PARAMETER_ERROR);
}
try {
List<ExcelExportEntity> excelParams = entityList;
// 得到所有字段
Field[] fileds = PoiPublicUtil.getClassFields(pojoClass);
ExcelTarget etarget = pojoClass.getAnnotation(ExcelTarget.class);
String targetId = etarget == null ? null : etarget.value();
getAllExcelField(entity.getExclusions(), targetId, fileds, excelParams, pojoClass,
null, null);
//获取所有参数后,后面的逻辑判断就一致了
createSheetForMap(workbook, entity, excelParams, dataSet);
} catch (Exception e) {
LOGGER.error(e.getMessage(), e);
throw new ExcelExportException(ExcelExportEnum.EXPORT_ERROR, e.getCause());
}
}
}
步骤四:定义列头(包括动态列头)
/**
* 定义表格样式
*
* @return java.util.List
* @since 2.8.2
*/
private List<ExcelExportEntity> setExportExcelStyle(EvaluationRecordVo evaluationRecordVo) {
System.out.println("开始创建模板-----");
//定义表格列名,该集合存放的就是表格的列明,每个对象就是表格中的一列
List<ExcelExportEntity> modelList = new ArrayList<ExcelExportEntity>();
//该对象就是定义列属性的对象
ExcelExportEntity excelentity = null;
excelentity = new ExcelExportEntity("学生姓名", "peopleName");
excelentity.setWidth(20);
excelentity.setHeight(10);
modelList.add(excelentity);
excelentity = new ExcelExportEntity("年龄", "age");
excelentity.setWidth(20);
excelentity.setHeight(10);
modelList.add(excelentity);
excelentity = new ExcelExportEntity("性别", "sexName");
excelentity.setWidth(20);
excelentity.setHeight(10);
modelList.add(excelentity);
excelentity = new ExcelExportEntity("院系", "studentDepartmentName");
excelentity.setWidth(20);
excelentity.setHeight(10);
modelList.add(excelentity);
excelentity = new ExcelExportEntity("专业", "studentMajorName");
excelentity.setWidth(20);
excelentity.setHeight(10);
modelList.add(excelentity);
excelentity = new ExcelExportEntity("班级", "studentClassName");
excelentity.setWidth(20);
excelentity.setHeight(10);
modelList.add(excelentity);
excelentity = new ExcelExportEntity("测评总分", "score");
excelentity.setWidth(20);
excelentity.setHeight(10);
modelList.add(excelentity);
excelentity = new ExcelExportEntity("测评结果", "evaluationResultsPageDisplay");
excelentity.setWidth(20);
excelentity.setHeight(10);
modelList.add(excelentity);
excelentity = new ExcelExportEntity("题号/题目名称", "srco");
excelentity.setWidth(20);
excelentity.setHeight(10);
modelList.add(excelentity);
// ---------------------定义自定义动态列头
//量表的所有的题目以及内容
List<TitleAndContentVo> titleAndContentVos = papersExaminationResultAnswerInfoMapper.titleAndContent(evaluationRecordVo.getPaperId());
for (TitleAndContentVo titleAndContentVo : titleAndContentVos) {
ExcelExportEntity excelExportEntity = new ExcelExportEntity();
excelExportEntity.setName(titleAndContentVo.getPaperNumber() + "." + titleAndContentVo.getQuestionsContent());
excelExportEntity.setKey(titleAndContentVo.getQuestionsId() + "APO");
excelExportEntity.setHeight(15);
modelList.add(excelExportEntity);
}
System.out.println("创建模板结束-----");
return modelList;
}
步骤五:定义数据源
/**
* 定义数据
*
* @return
*/
private List<Map<String, Object>> getData(EvaluationRecordVo evaluationRecordVo) {
System.out.println("开始获取数据源结束-----");
//获取数据源
List<Map<String, Object>> dataList = new ArrayList<>();
//存储表格中的每一行数据
Map<String, Object> mapParent = null;
//获取该测评下的学生的基本信息以及测评结果和分数
List<AssessmentResultsAndScoresVo> assessmentResultsAndScoresVos =
papersExaminationResultAnswerInfoMapper.getDataOneToMany(evaluationRecordVo.getExaminationId(),
evaluationRecordVo.getPaperId(), evaluationRecordVo.getOrganizationId());
System.out.println("总计人数:" + assessmentResultsAndScoresVos.size());
for (AssessmentResultsAndScoresVo assessmentResultsAndScoresVo : assessmentResultsAndScoresVos) {//10849
mapParent = new HashMap();
mapParent.put("peopleName", assessmentResultsAndScoresVo.getPeopleName());
mapParent.put("age", assessmentResultsAndScoresVo.getAge());
mapParent.put("sexName", assessmentResultsAndScoresVo.getSexName());
mapParent.put("studentDepartmentName", assessmentResultsAndScoresVo.getStudentDepartmentName());
mapParent.put("studentMajorName", assessmentResultsAndScoresVo.getStudentMajorName());
mapParent.put("studentClassName", assessmentResultsAndScoresVo.getStudentClassName());
mapParent.put("score", assessmentResultsAndScoresVo.getScore());
mapParent.put("evaluationResultsPageDisplay", assessmentResultsAndScoresVo.getEvaluationResultsPageDisplay());
mapParent.put("srco", assessmentResultsAndScoresVo.getSrco());
for (TheStudentScoreVo theStudentScoreVo : assessmentResultsAndScoresVo.getTheStudentScoreVoList()) {
String[] strs = theStudentScoreVo.getRepose().split("-");
mapParent.put(strs[0] + "APO", strs[1]);
}
dataList.add(mapParent);
System.out.println("获取数据源结束-----");
}
int size = assessmentResultsAndScoresVos.size();
return dataList;
}
**这块的内容自己获取 保证返回的格式就OK了 **
步骤六:导出
这块主要是将列头和数据源给到Excel对象进行创建Excel文件和格式然后导出
/**
* 报表导出
*
* @param response response
* @return javax.servlet.http.HttpServletResponse
* @author huan
* @date 2019/6/21
* @since 2.8.2
*/
@Override
public HttpServletResponse export(HttpServletResponse response, EvaluationRecordVo evaluationRecordVo) {
System.out.println("数据导出中----");
//定义表格样式 之前的列头的定义的东西
List<ExcelExportEntity> modelList = setExportExcelStyle(evaluationRecordVo);
//定义表格名称 之前的获取的数据
try {
String fileName = URLEncoder.encode("StudentAnswerOptions", "utf-8");
List<Map<String, Object>> data = getData(evaluationRecordVo);
int size = data.size();
// 将sheet1、sheet2使用得map进行包装
List<Map<String, Object>> sheetsList = new ArrayList<>();
//如果需要是多个的话就创建多个的ExportParams对象放到sheetsList集合中就ok了
// Sheet样式
ExportParams sheetExportParams = new ExportParams();
// 设置sheet得名称
sheetExportParams.setSheetName("学生选项详情");
sheetExportParams.setTitleHeight((short) 20);
// 创建sheet使用得map
Map<String, Object> sheet1ExportMap = new HashMap<>();
// title的参数为ExportParams类型,目前仅仅在ExportParams中设置了sheetName
sheet1ExportMap.put("title", sheetExportParams);
//sheet1样式
sheet1ExportMap.put("entityList", modelList);
//sheet1中要填充得数据,true表示查询入库数据,false表示查询易签待入库数据
sheet1ExportMap.put("data", data);
sheetsList.add(sheet1ExportMap);
// 执行方法
Workbook workBook = exportExcel(sheetsList, ExcelType.XSSF);
//设置response
response.setHeader("content-disposition", "attachment;filename=" + fileName + ".xls");
//设置编码格式
response.setCharacterEncoding("GBK");
//将表格内容写到输出流中并刷新缓存
@Cleanup ServletOutputStream out = null;
out = response.getOutputStream();
workBook.write(out);
out.flush();
workBook.close();
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
前端对接进行Excel下载
let blob = new Blob([res], { type: "application/vnd.ms-excel" }); // 这里表示xmlx类型application/soap+xml; charset=utf-8
let downloadElement = document.createElement("a");
let href = window.URL.createObjectURL(blob); // 创建下载的链接
downloadElement.href = href;
// downloadElement.download = name; // 下载后文件名
document.body.appendChild(downloadElement);
downloadElement.click(); // 点击下载
document.body.removeChild(downloadElement); // 下载完成移除元素
window.URL.revokeObjectURL(href); // 释放掉blob对象
注意指定返回的类型是bolb类型
注意指定返回的类型是bolb类型
注意指定返回的类型是bolb类型
EasyPoi官方文档内容
Excel自适应xls和xlsx两种格式,word只支持docx模式
- 1.easypoi 父包–作用大家都懂得
- 2.easypoi-annotation 基础注解包,作用与实体对象上,拆分后方便maven多工程的依赖管理
- 3.easypoi-base 导入导出的工具包,可以完成Excel导出,导入,Word的导出,Excel的导出功能
- 4.easypoi-web 耦合了spring-mvc 基于AbstractView,极大的简化spring-mvc下的导出功能
- 5.sax 导入使用xercesImpl这个包(这个包可能造成奇怪的问题哈),word导出使用poi-scratchpad,都作为可选包了
如果不使用spring mvc的便捷福利,直接引入easypoi-base 就可以了,easypoi-annotation
如果使用maven,请使用如下坐标
<dependency>
<groupId>cn.afterturngroupId>
<artifactId>easypoi-baseartifactId>
<version>3.2.0version>
dependency>
<dependency>
<groupId>cn.afterturngroupId>
<artifactId>easypoi-webartifactId>
<version>3.2.0version>
dependency>
<dependency>
<groupId>cn.afterturngroupId>
<artifactId>easypoi-annotationartifactId>
<version>3.2.0version>
dependency>
Excel 注解版
2.1 Excel导入导出
Excel的导入导出是Easypoi的核心功能,前期基本也是围绕这个打造的,主要分为三种方式的处理,其中模板和Html目前只支持导出,因为支持Map.class其实导入应该是怎样都支持的
- 注解方式,注解变种方式
- 模板方式
- Html方式
下面分别就这三种方式进行讲解
2.2 注解
注解介绍
easypoi起因就是Excel的导入导出,最初的模板是实体和Excel的对应,model–row,filed–col 这样利用注解我们可以和容易做到excel到导入导出 经过一段时间发展,现在注解有5个类分别是
- @Excel 作用到filed上面,是对Excel一列的一个描述
- @ExcelCollection 表示一个集合,主要针对一对多的导出,比如一个老师对应多个科目,科目就可以用集合表示
- @ExcelEntity 表示一个继续深入导出的实体,但他没有太多的实际意义,只是告诉系统这个对象里面同样有导出的字段
- @ExcelIgnore 和名字一样表示这个字段被忽略跳过这个导导出
- @ExcelTarget 这个是作用于最外层的对象,描述这个对象的id,以便支持一个对象可以针对不同导出做出不同处理
注解中的ID的用法 这个ID算是一个比较独特的例子,比如
@ExcelTarget("teacherEntity")public class TeacherEntity implements java.io.Serializable { /** name */ @Excel(name = "主讲老师_teacherEntity,代课老师_absent", orderNum = "1", mergeVertical = true,needMerge=true,isImportField = "true_major,true_absent") private String name;
这里的@ExcelTarget 表示使用teacherEntity这个对象是可以针对不同字段做不同处理 同样的ExcelEntity 和ExcelCollection 都支持这种方式 当导出这对象时,name这一列对应的是主讲老师,而不是代课老师还有很多字段都支持这种做法
@Excel
这个是必须使用的注解,如果需求简单只使用这一个注解也是可以的,涵盖了常用的Excel需求,需要大家熟悉这个功能,主要分为基础,图片处理,时间处理,合并处理几块,name_id是上面讲的id用法,这里就不累言了
| 属性 | 类型 | 默认值 | 功能 |
|---|---|---|---|
| name | String | null | 列名,支持name_id |
| needMerge | boolean | fasle | 是否需要纵向合并单元格(用于含有list中,单个的单元格,合并list创建的多个row) |
| orderNum | String | “0” | 列的排序,支持name_id |
| replace | String[] | {} | 值得替换 导出是{a_id,b_id} 导入反过来 |
| savePath | String | “upload” | 导入文件保存路径,如果是图片可以填写,默认是upload/className/ IconEntity这个类对应的就是upload/Icon/ |
| type | int | 1 | 导出类型 1 是文本 2 是图片,3 是函数,10 是数字 默认是文本 |
| width | double | 10 | 列宽 |
| height | double | 10 | 列高,后期打算统一使用@ExcelTarget的height,这个会被废弃,注意 |
| isStatistics | boolean | fasle | 自动统计数据,在追加一行统计,把所有数据都和输出 这个处理会吞没异常,请注意这一点 |
| isHyperlink | boolean | false | 超链接,如果是需要实现接口返回对象 |
| isImportField | boolean | true | 校验字段,看看这个字段是不是导入的Excel中有,如果没有说明是错误的Excel,读取失败,支持name_id |
| exportFormat | String | “” | 导出的时间格式,以这个是否为空来判断是否需要格式化日期 |
| importFormat | String | “” | 导入的时间格式,以这个是否为空来判断是否需要格式化日期 |
| format | String | “” | 时间格式,相当于同时设置了exportFormat 和 importFormat |
| databaseFormat | String | “yyyyMMddHHmmss” | 导出时间设置,如果字段是Date类型则不需要设置 数据库如果是string 类型,这个需要设置这个数据库格式,用以转换时间格式输出 |
| numFormat | String | “” | 数字格式化,参数是Pattern,使用的对象是DecimalFormat |
| imageType | int | 1 | 导出类型 1 从file读取 2 是从数据库中读取 默认是文件 同样导入也是一样的 |
| suffix | String | “” | 文字后缀,如% 90 变成90% |
| isWrap | boolean | true | 是否换行 即支持\n |
| mergeRely | int[] | {} | 合并单元格依赖关系,比如第二列合并是基于第一列 则{0}就可以了 |
| mergeVertical | boolean | fasle | 纵向合并内容相同的单元格 |
| fixedIndex | int | -1 | 对应excel的列,忽略名字 |
| isColumnHidden | boolean | false | 导出隐藏列 |
@ExcelTarget
限定一个到处实体的注解,以及一些通用设置,作用于最外面的实体
| 属性 | 类型 | 默认值 | 功能 |
|---|---|---|---|
| value | String | null | 定义ID |
| height | double | 10 | 设置行高 |
| fontSize | short | 11 | 设置文字大小 |
@ExcelEntity
标记是不是导出excel 标记为实体类,一遍是一个内部属性类,标记是否继续穿透,可以自定义内部id
| 属性 | 类型 | 默认值 | 功能 |
|---|---|---|---|
| id | String | null | 定义ID |
@ExcelCollection
一对多的集合注解,用以标记集合是否被数据以及集合的整体排序
| 属性 | 类型 | 默认值 | 功能 |
|---|---|---|---|
| id | String | null | 定义ID |
| name | String | null | 定义集合列名,支持nanm_id |
| orderNum | int | 0 | 排序,支持name_id |
| type | Class | ArrayList.class | 导入时创建对象使用 |
@ExcelIgnore
忽略这个属性,多使用需循环引用中,无需多解释吧^^
2.3 注解导出,导入
2.3.1 对象定义
注解介绍了这么多,大家基本上也了解我们的注解是如何定义Excel的了吧,下面我们来跟着路飞实战吧 这天老师吧路飞叫到了办公室,让给给老师实现一个报表的需求,就是从教育平台把某个班级的人员导出来 需求是,导出我们班的所有学生的姓名,性别,出生日期,进校日期 正巧路飞刚看到Easypo,就打算用Easypoi来实现,实现方法如下:
首先定义一个我们导出的对象,*为了节省篇幅,统一忽略getter,setter*
public class StudentEntity implements java.io.Serializable { /** * id */ private String id; /** * 学生姓名 */ @Excel(name = "学生姓名", height = 20, width = 30, isImportField = "true_st") private String name; /** * 学生性别 */ @Excel(name = "学生性别", replace = { "男_1", "女_2" }, suffix = "生", isImportField = "true_st") private int sex; @Excel(name = "出生日期", databaseFormat = "yyyyMMddHHmmss", format = "yyyy-MM-dd", isImportField = "true_st", width = 20) private Date birthday; @Excel(name = "进校日期", databaseFormat = "yyyyMMddHHmmss", format = "yyyy-MM-dd") private Date registrationDate; }
这里设置我们的4列分别是学生姓名,学生性别,出生日期,进校日期 其中学生姓名定义了我们的列的行高,学生性别因为我们基本上都是存在数据库都是数字所以我们转换下,两个日期我们都是进行了格式化输出了,这样我们就完成了业务对我们Excel的样式需求,后面只有把这个学生列表输出就可以了 生成Excel代码如下
Workbook workbook = ExcelExportUtil.exportExcel(new ExportParams("计算机一班学生","学生"), StudentEntity .class, list);
这样我们就得到的一个java中的Excel,然后把这个输出就得到我们的Excel了https://static.oschina.net/uploads/space/2017/0622/212811_uh7e_1157922.png
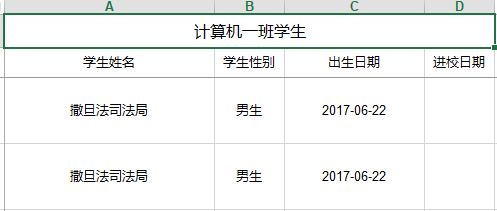
2.3.2 集合定义
路飞很快的完成了老师的任务,花了也就是喝杯茶的时间,就交差了,但过了一会就又被老师叫去了,让他给出一个某个班级选择选择某些课的学生以及对应的老师 路飞又很快的想到了Easypoi,其中有一对多的导出,这不正是一对多的体现吗,然后他继续定义实体: 一个课程对应一个老师 一个课程对应N个学生 课程的实体
@ExcelTarget("courseEntity") public class CourseEntity implements java.io.Serializable { /** 主键 */ private String id; /** 课程名称 */ @Excel(name = "课程名称", orderNum = "1", width = 25) private String name; /** 老师主键 */ @ExcelEntity(id = "absent") private TeacherEntity mathTeacher; @ExcelCollection(name = "学生", orderNum = "4") private List<StudentEntity> students; }
教师的实体
@ExcelTarget("teacherEntity")public class TeacherEntity implements java.io.Serializable { private String id; /** name */ @Excel(name = "主讲老师_major,代课老师_absent", orderNum = "1", isImportField = "true_major,true_absent") private String name;
这里在课程这个实体里面就完成了一堆多的导出,达到了我们基础需求,同时使用了orderNum对我们的列进行了排序,满足老师的需求,导出代码如下
Workbook workbook = ExcelExportUtil.exportExcel(new ExportParams("2412312", "测试", "测试"), CourseEntity.class, list);
这样我们就完成了老师的需求,效果如图2.3.2-1 但是课程名和代课老师没有合并,不太美观
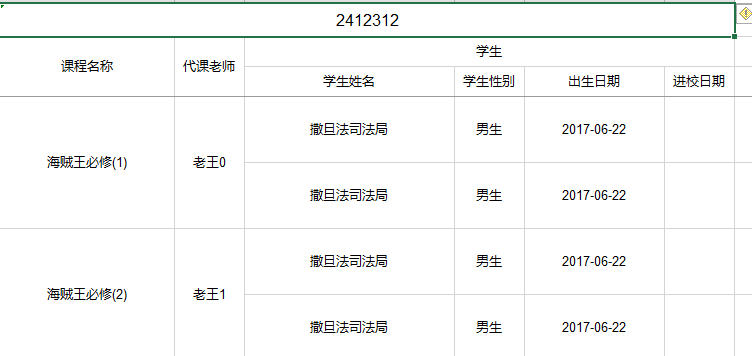
路飞又果断给课程名称和代课老师加了needMerge = true的属性,就可以完成单元格的合并
/** 课程名称 */ @Excel(name = "课程名称", orderNum = "1", width = 25,needMerge = true) private String name; //-------------------------------- /** name */ @Excel(name = "主讲老师_major,代课老师_absent", orderNum = "1",needMerge = true, isImportField = "true_major,true_absent")
效果如图2.3.2-2 到这里,路飞就完美的完成了老师的任务,快乐的去交差了
图2.3.2-1
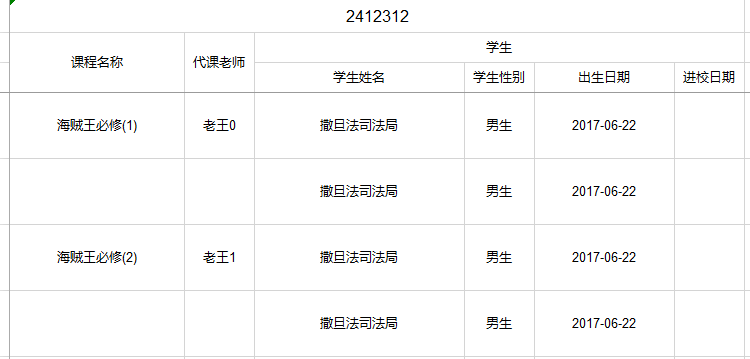
图2.3.2-2
2.3.3 图片的导出
在日常运作中不可避免的会遇到图片的导入导出,这里提供了两种类型的图片导出方式
@Excel(name = "公司LOGO", type = 2 ,width = 40 , height = 20,imageType = 1) private String companyLogo;
-
表示type =2 该字段类型为图片,imageType=1 (默认可以不填),表示从file读取,字段类型是个字符串类型 可以用相对路径也可以用绝对路径,绝对路径优先依次获取
@Excel(name = "公司LOGO", type = 2 ,width = 40 , height = 20,imageType = 1) private byte[] companyLogo;2.表示type =2 该字段类型为图片,imageType=2 ,表示从数据库或者已经读取完毕,字段类型是个字节数组 直接使用 同时,image 类型的cell最好设置好宽和高,
会百分百缩放到cell那么大,不是原尺寸,这里注意下
效果如下
List<CompanyHasImgModel> list; @Before public void initData() { list = new ArrayList<CompanyHasImgModel>(); list.add(new CompanyHasImgModel("百度", "imgs/company/baidu.png", "北京市海淀区西北旺东路10号院百度科技园1号楼")); list.add(new CompanyHasImgModel("阿里巴巴", "imgs/company/ali.png", "北京市海淀区西北旺东路10号院百度科技园1号楼")); list.add(new CompanyHasImgModel("Lemur", "imgs/company/lemur.png", "亚马逊热带雨林")); list.add(new CompanyHasImgModel("一众", "imgs/company/one.png", "山东济宁俺家")); } @Test public void exportCompanyImg() throws Exception { File savefile = new File("D:/excel/"); if (!savefile.exists()) { savefile.mkdirs(); } Workbook workbook = ExcelExportUtil.exportExcel(new ExportParams(), CompanyHasImgModel.class, list); FileOutputStream fos = new FileOutputStream("D:/excel/ExcelExportHasImgTest.exportCompanyImg.xls"); workbook.write(fos); fos.close(); }
运行效果
2.3.3 -1

2.3.4 Excel导入介绍
有导出就有导入,基于注解的导入导出,配置配置上是一样的,只是方式反过来而已,比如类型的替换 导出的时候是1替换成男,2替换成女,导入的时候则反过来,男变成1 ,女变成2,时间也是类似 导出的时候date被格式化成 2017-8-25 ,导入的时候2017-8-25被格式成date类型 下面说下导入的基本代码,注解啥的都是上面讲过了,这里就不累赘了
@Test public void test2() { ImportParams params = new ImportParams(); params.setTitleRows(1); params.setHeadRows(1); long start = new Date().getTime(); List<MsgClient> list = ExcelImportUtil.importExcel( new File(PoiPublicUtil.getWebRootPath("import/ExcelExportMsgClient.xlsx")), MsgClient.class, params); System.out.println(new Date().getTime() - start); System.out.println(list.size()); System.out.println(ReflectionToStringBuilder.toString(list.get(0))); }
基本是写法也很简单,ImportParams 参数介绍下
| 属性 | 类型 | 默认值 | 功能 |
|---|---|---|---|
| titleRows | int | 0 | 表格标题行数,默认0 |
| headRows | int | 1 | 表头行数,默认1 |
| startRows | int | 0 | 字段真正值和列标题之间的距离 默认0 |
| *keyIndex* | int | 0 | *主键设置,如何这个cell没有值,就跳过 或者认为这个是list的下面的值* 这一列必须有值,不然认为这列为无效数据 |
| startSheetIndex | int | 0 | 开始读取的sheet位置,默认为0 |
| sheetNum | int | 1 | 上传表格需要读取的sheet 数量,默认为1 |
| needSave | boolean | false | 是否需要保存上传的Excel |
| needVerfiy | boolean | false | 是否需要校验上传的Excel |
| saveUrl | String | “upload/excelUpload” | 保存上传的Excel目录,默认是 如 TestEntity这个类保存路径就是 upload/excelUpload/Test/yyyyMMddHHmss****** 保存名称上传时间*五位随机数 |
| verifyHanlder | IExcelVerifyHandler | null | 校验处理接口,自定义校验 |
| lastOfInvalidRow | int | 0 | 最后的无效行数,不读的行数 |
| readRows | int | 0 | 手动控制读取的行数 |
| importFields | String[] | null | 导入时校验数据模板,是不是正确的Excel |
| keyMark | String | “:” | Key-Value 读取标记,以这个为Key,后面一个Cell 为Value,多个改为ArrayList |
| readSingleCell | boolean | false | 按照Key-Value 规则读取全局扫描Excel,但是跳过List读取范围提升性能 仅仅支持titleRows + headRows + startRows 以及 lastOfInvalidRow |
| dataHanlder | IExcelDataHandler | null | 数据处理接口,以此为主,replace,format都在这后面 |
2.3.5 Excel导入小功能
- 读取指定的sheet 比如要读取上传得第二个sheet 那么需要把startSheetIndex = 1 就可以了
- 读取几个sheet 比如读取前2个sheet,那么 sheetNum=2 就可以了
- 读取第二个到第五个sheet 设置 startSheetIndex = 1 然后sheetNum = 4
- 读取全部的sheet sheetNum 设置大点就可以了
- 保存Excel 设置 needVerfiy = true,默认保存的路径为upload/excelUpload/Test/yyyyMMddHHmss****** 保存名称上传时间*五位随机数 如果自定义路径 修改下saveUrl 就可以了,同时saveUrl也是图片上传时候的保存的路径
- 判断一个Excel是不是合法的Excel importFields 设置下值,就是表示表头必须至少包含的字段,如果缺一个就是不合法的excel,不导入
2.3.6 图片的导入
有图片的导出就有图片的导入,导入的配置和导出是一样的,但是需要设置保存路径 1.设置保存路径saveUrl 默认为"upload/excelUpload" 可以手动修改 ImportParams 修改下就可以了
@Test public void test() { try { ImportParams params = new ImportParams(); params.setNeedSave(true); List<CompanyHasImgModel> result = ExcelImportUtil.importExcel( new File(PoiPublicUtil.getWebRootPath("import/imgexcel.xls")), CompanyHasImgModel.class, params); for (int i = 0; i < result.size(); i++) { System.out.println(ReflectionToStringBuilder.toString(result.get(i))); } Assert.assertTrue(result.size() == 4); } catch (Exception e) { e.printStackTrace(); } }}
导入日志
16:35:43.081 [main] DEBUG c.a.e.e.imports.ExcelImportServer - Excel import start ,class is class cn.afterturn.easypoi.test.entity.img.CompanyHasImgModel16:35:43.323 [main] DEBUG c.a.e.e.imports.ExcelImportServer - start to read excel by is ,startTime is 150365014332316:35:43.344 [main] DEBUG c.a.e.e.imports.ExcelImportServer - end to read excel by is ,endTime is 150365014334416:35:43.429 [main] DEBUG c.a.e.e.imports.ExcelImportServer - end to read excel list by pos ,endTime is 1503650143429cn.afterturn.easypoi.test.entity.img.CompanyHasImgModel@1b083826[companyName=百度,companyLogo=upload/CompanyHasImgModel/pic88273295062.PNG,companyAddr=北京市海淀区西北旺东路10号院百度科技园1号楼]cn.afterturn.easypoi.test.entity.img.CompanyHasImgModel@105fece7[companyName=阿里巴巴,companyLogo=upload/CompanyHasImgModel/pic22507938183.PNG,companyAddr=北京市海淀区西北旺东路10号院百度科技园1号楼]cn.afterturn.easypoi.test.entity.img.CompanyHasImgModel@3ec300f1[companyName=Lemur,companyLogo=upload/CompanyHasImgModel/pic86390457892.PNG,companyAddr=亚马逊热带雨林]cn.afterturn.easypoi.test.entity.img.CompanyHasImgModel@482cd91f[companyName=一众,companyLogo=upload/CompanyHasImgModel/pic69566571093.PNG,companyAddr=山东济宁俺家]
2.3.5-1

2.3.7 Excel多Sheet导出
目前单Sheet和单Class的方式比较多,对于多Sheet的方式还是一片空白,这里做一下说明:
导出基本采用ExportParams 这个对象,进行参数配置; 我们需要进行多Sheet导出,那么就需要定义一个基础配置对象
public class ExportView { public ExportView(){ } private ExportParams exportParams; private List<?> dataList; private Class<?> cls; public ExportParams getExportParams() { return exportParams; } public void setExportParams(ExportParams exportParams) { this.exportParams = exportParams; } public Class<?> getCls() { return cls; } public void setCls(Class<?> cls) { this.cls = cls; } public List<?> getDataList() { return dataList; } public void setDataList(List<?> dataList) { this.dataList = dataList; } public ExportView(Builder builder) { this.exportParams = builder.exportParams; this.dataList = builder.dataList; this.cls = builder.cls; } public static class Builder { private ExportParams exportParams=null; private List<?> dataList=null; private Class<?> cls=null; public Builder() { } public Builder exportParams(ExportParams exportParams) { this.exportParams = exportParams; return this; } public Builder dataList(List<?> dataList) { this.dataList = dataList; return this; } public Builder cls(Class<?> cls) { this.cls = cls; return this; } public ExportView create() { return new ExportView(this); } }}
对象主要有三个属性: // 该注解配置的导出属性
- ExportParams exportParams // 对应注解 class 实例对象的数据集合
- List dataList // 对应注解的 class
- Class cls
这里没有用泛型,因为多Sheet导出时,会引用到不同的注解对象;
定义基础配置的集合
public class ExportMoreView { private List<ExportView> moreViewList=Lists.newArrayList(); public List<ExportView> getMoreViewList() { return moreViewList; } public void setMoreViewList(List<ExportView> moreViewList) { this.moreViewList = moreViewList; }}
最后在实现调用的方法中,对整个集合进行配置和解析
List<Map<String, Object>> exportParamList=Lists.newArrayList(); //该行主要用于获取业务数据,请根据具体的情况进行修改和调整 ExportMoreView moreView=this.getBaseTransferService().mergeExportView(templateTypeCode); //迭代导出对象,将对应的配置信息写入到实际的配置中 for(ExportView view:moreView.getMoreViewList()){ Map valueMap=Maps.newHashMap(); valueMap.put(NormalExcelConstants.PARAMS,view.getExportParams()); valueMap.put(NormalExcelConstants.DATA_LIST,view.getDataList()); valueMap.put(NormalExcelConstants.CLASS,view.getCls()); exportParamList.add(valueMap); } //实现导出配置 modelMap.put(NormalExcelConstants.FILE_NAME,new DateTime().toString("yyyyMMddHHmmss")); //将转换完成的配置接入到导出中 modelMap.put(NormalExcelConstants.MAP_LIST,exportParamList); return NormalExcelConstants.JEECG_EXCEL_VIEW;
如果不是采用的MVC的方式,请将转换的配置采用以下的方式实现:
参见ExcelExportUtil

2.4 注解变种-更自由的导出
这天老师又把路飞喊道的办公室,要求路飞导出班级学生的整体信息
@Excel(name = "学生姓名", height = 20, width = 30, isImportField = "true_st") private String name; @Excel(name = "学生性别", replace = { "男_1", "女_2" }, suffix = "生", isImportField = "true_st") private int sex; @Excel(name = "出生日期", databaseFormat = "yyyyMMddHHmmss", format = "yyyy-MM-dd", isImportField = "true_st", width = 20) private Date birthday; @Excel(name = "进校日期", databaseFormat = "yyyyMMddHHmmss", format = "yyyy-MM-dd") private Date registrationDate;
路飞飞快的用到上面的学到的知识搞定了,这这时有一个老师把路飞叫去,说想要导出一个不要出生日期的Excel,感觉用户需求很无奈,路飞又造两个一个bean,把这个注解去掉了,来导出
@Excel(name = "学生姓名", height = 20, width = 30, isImportField = "true_st") private String name; @Excel(name = "学生性别", replace = { "男_1", "女_2" }, suffix = "生", isImportField = "true_st") private int sex; @Excel(name = "进校日期", databaseFormat = "yyyyMMddHHmmss", format = "yyyy-MM-dd") private Date registrationDate;
虽然解决了老师的需求,但这个并不是一个完美的解决方案,下面介绍一个更自由的解决方案
注解的导出,规定我们必须把model写好,并且注解写好,每次导出的Excel都是固定的,无法动态控制导出的列,虽然可以通过id来处理一个案例,但是自由度远远不够,这里介绍个变种支持,基本支持注解所有的功能
基于List 的导出,ExcelExportEntity是注解经过处理翻译成的实体类,两者几乎是一对的,所以如果我们要动态自定义导出列,我们只要动态拼装ExcelExportEntity就可以了 下面我们看下这个类
/** * 如果是MAP导出,这个是map的key */ private Object key; private double width = 10; private double height = 10; /** * 图片的类型,1是文件,2是数据库 */ private int exportImageType = 0; /** * 排序顺序 */ private int orderNum = 0; /** * 是否支持换行 */ private boolean isWrap; /** * 是否需要合并 */ private boolean needMerge; /** * 单元格纵向合并 */ private boolean mergeVertical; /** * 合并依赖 */ private int[] mergeRely; /** * 后缀 */ private String suffix; /** * 统计 */ private boolean isStatistics; private String numFormat; private List<ExcelExportEntity> list;
基本上是和注解对应的, List list 这个是对应的一对多的导出,相当于集合,其他基本上都是和注解保持一致 下面给出正常的demo
public void test() { try { List<ExcelExportEntity> entity = new ArrayList<ExcelExportEntity>();//构造对象等同于@Excel ExcelExportEntity excelentity = new ExcelExportEntity("姓名", "name"); excelentity.setNeedMerge(true); entity.add(excelentity); entity.add(new ExcelExportEntity("性别", "sex")); excelentity = new ExcelExportEntity(null, "students"); List temp = new ArrayList(); temp.add(new ExcelExportEntity("姓名", "name")); temp.add(new ExcelExportEntity("性别", "sex"));//构造List等同于@ExcelCollection excelentity.setList(temp); entity.add(excelentity); List> list = new ArrayList>();//把我们构造好的bean对象放到params就可以了 Workbook workbook = ExcelExportUtil.exportExcel(new ExportParams("测试", "测试"), entity, list); FileOutputStream fos = new FileOutputStream("D:/excel/ExcelExportForMap.tt.xls"); workbook.write(fos); fos.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }
路飞想到了这个方案,并且用上面做了测试可以完美解决所以他把之前的代码改为了(代码有删减,基本上都是和注解对应的)
List<ExcelExportEntity> beanList = new ArrayList<ExcelExportEntity>();beanList .add(new ExcelExportEntity(new ExcelExportEntity("学生姓名", "name"));beanList .add(new ExcelExportEntity("学生性别", "sex"));beanList .add(new ExcelExportEntity("进校日期", "registrationDate"));if(needBirthday()){ beanList .add(new ExcelExportEntity("出生日期", "birthday"));} Workbook workbook = ExcelExportUtil.exportExcel(new ExportParams("测试", "测试"), beanList , list);
用同一套代买完美了支持了老师的需求,心满意足的回宿舍了^^
2.5 Map导入,自由发挥
这天,老师把路飞叫到办公室,总是被叫,能者的悲哀啊,让他临时导入一批数据,到数据库,但是中间需要处理一些字段逻辑没办法直接导入到数据库, 这时路飞首先想到构造一个bean然后标记注解,导入处理对象,但是想想一次的对象太过于浪费,不如用map试试,获取map处理map也是一样的 导入的逻辑就变成了
ImportParams params = new ImportParams(); params.setDataHanlder(new MapImportHanlder()); long start = new Date().getTime(); List<Map<String, Object>> list = ExcelImportUtil.importExcel( new File(PoiPublicUtil.getWebRootPath("import/check.xls")), Map.class, params);
导入后,处理每个map,然后入库完美的解决了老师的需求,简单更快捷,和bean导入基础没有区别,省去了bean的构造时间
PS:这个作者也只是在临时方案中或者一次性活当中使用,一般还是推荐注解这种方式,拥有更高的代码阅读性 !!!测试了时间的,最好导入使用文本格式,可以获取时间格式可能无法获取
2.6 Excel的样式自定义
“路飞,来办公室一趟”,就这样路飞又被叫到了办公室,这次老师的需求是,想要一个漂亮点的Excel,希望路飞可以点缀下Excel,思来想去还是需要用poi的style来解决,但是如果每个都写style是不是太麻烦,而且Excel的styler数量是有限制的,这里就需要尽量复用已经创造的style,看看之前的Excel表格,大体上可以分为[标题,表头,表体],那可以说的就是创建一个接口每次调用这三个接口就可以了不说干就干
public interface IExcelExportStyler { /** * 列表头样式 * @param headerColor * @return */ public CellStyle getHeaderStyle(short headerColor); /** * 标题样式 * @param color * @return */ public CellStyle getTitleStyle(short color); /** * 获取样式方法 * @param Parity * @param entity * @return */ public CellStyle getStyles(boolean Parity, ExcelExportEntity entity);}
实现类尽量复用已经创建的Styler,切记 这样路飞先造了一个带边框的styler ,ExcelExportStylerBorderImpl 效果如下  然后路飞又手痒写了个带换行颜色的 ExcelExportStylerColorImpl 效果如下
然后路飞又手痒写了个带换行颜色的 ExcelExportStylerColorImpl 效果如下 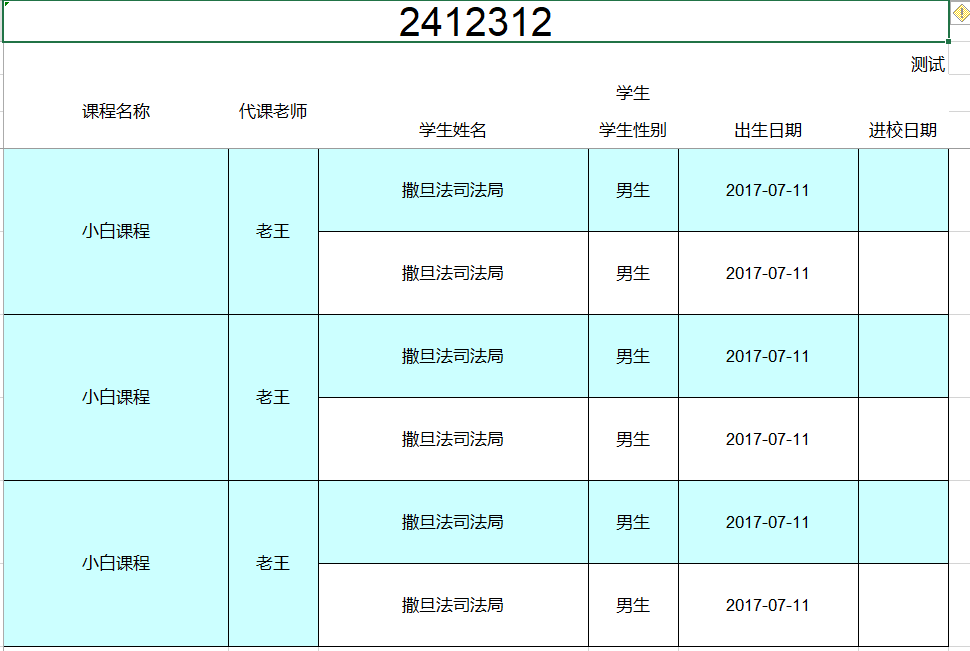
客官看到这里应该就大体理解了我们的实现方法了吧, 最后路飞实现了一个复杂的按照老师要求的样式交差了
styler接口用法 上面两个表头和标题样式不用解释 后面这个是传入当前列的以及奇偶行,用户可以根据需求实现业务,包括去掉Excel的小箭头(也就是设置数字为数字格式的Cell),完成居中,字体等等各式各样的需求 但是这里无法实现特别没的Excel,如果有这种需求可以使用模板来实现,在Excel点点就可以完美实现
2.7 如何自定义数据处理
导入导出总有一些自定义格式转换,EasyPoi虽然定义了很多服务,但是也无法满足所有客户的需求,这个时候就需要咱们自己定义数据处理 EasyPoi提供了
/** * Excel 导入导出 数据处理接口 * * @author JueYue * 2014年6月19日 下午11:59:45 */public interface IExcelDataHandler<T> { /** * 导出处理方法 * * @param obj * 当前对象 * @param name * 当前字段名称 * @param value * 当前值 * @return */ public Object exportHandler(T obj, String name, Object value); /** * 获取需要处理的字段,导入和导出统一处理了, 减少书写的字段 * * @return */ public String[] getNeedHandlerFields(); /** * 导入处理方法 当前对象,当前字段名称,当前值 * * @param obj * 当前对象 * @param name * 当前字段名称 * @param value * 当前值 * @return */ public Object importHandler(T obj, String name, Object value); /** * 设置需要处理的属性列表 * @param fields */ public void setNeedHandlerFields(String[] fields); /** * 设置Map导入,自定义 put * @param map * @param originKey * @param value */ public void setMapValue(Map<String, Object> map, String originKey, Object value); /** * 获取这个字段的 Hyperlink ,07版本需要,03版本不需要 * @param creationHelper * @param obj * @param name * @param value * @return */ public Hyperlink getHyperlink(CreationHelper creationHelper, T obj, String name, Object value);}
简单的使用方法如下
CourseHandler hanlder = new CourseHandler(); hanlder.setNeedHandlerFields(new String[] { "课程名称" }); exportParams.setDataHandler(hanlder);
我们自己实现以下这个类,也可以继承ExcelDataHandlerDefaultImpl ,避免实现多余的接口 setNeedHandlerFields 这个是需要我们自己处理的字段,需要手动设置
让我们看一个demo
public class MapImportHandler extends ExcelDataHandlerDefaultImpl<Map<String, Object>> { @Override public void setMapValue(Map<String, Object> map, String originKey, Object value) { if (value instanceof Double) { map.put(getRealKey(originKey), PoiPublicUtil.doubleToString((Double) value)); } else { map.put(getRealKey(originKey), value != null ? value.toString() : null); } } private String getRealKey(String originKey) { if (originKey.equals("交易账户")) { return "accountNo"; } if (originKey.equals("姓名")) { return "name"; } if (originKey.equals("客户类型")) { return "type"; } return originKey; }}
这里我们在map导入的时候把map的key给转了,从中文转为习惯的英文
2.8 Excel导入校验
校验,是一个不可或缺的功能,现在java校验主要是JSR 303 规范,实现方式主流的有两种
- Hibernate Validator
- Apache Commons Validator
这个EasyPoi没有限制,只要你防止一个实现丢到maven中就可以了,但是Hibernate Validator用的貌似多一些 之前的版本EasyPoi有定义自己的实现,但是后来抛弃了,没有必要造这种轮子,这个了功能已经够丰富了
*对象*
EasyPoi的校验使用也很简单,对象上加上通用的校验规则或者这定义的这个看你用的哪个实现 然后params.setNeedVerfiy(true);配置下需要校验就可以了 看下具体的代码
/** * Email校验 */ @Excel(name = "Email", width = 25) private String email; /** * 最大 */ @Excel(name = "Max") @Max(value = 15,message = "max 最大值不能超过15" ,groups = {ViliGroupOne.class}) private int max; /** * 最小 */ @Excel(name = "Min") @Min(value = 3, groups = {ViliGroupTwo.class}) private int min; /** * 非空校验 */ @Excel(name = "NotNull") @NotNull private String notNull; /** * 正则校验 */ @Excel(name = "Regex") @Pattern(regexp = "[\u4E00-\u9FA5]*", message = "不是中文") private String regex;
这里的校验规则都是JSR 303 的,使用方式也是的,这里就不做解释了 然后使用方式是
@Test public void basetest() { try { ImportParams params = new ImportParams(); params.setNeedVerfiy(true); params.setVerfiyGroup(new Class[]{ViliGroupOne.class}); ExcelImportResult<ExcelVerifyEntity> result = ExcelImportUtil.importExcelMore( new File(PoiPublicUtil.getWebRootPath("import/verfiy.xlsx")), ExcelVerifyEntity.class, params); FileOutputStream fos = new FileOutputStream("D:/excel/ExcelVerifyTest.basetest.xlsx"); result.getWorkbook().write(fos); fos.close(); for (int i = 0; i < result.getList().size(); i++) { System.out.println(ReflectionToStringBuilder.toString(result.getList().get(i))); } Assert.assertTrue(result.getList().size() == 1); Assert.assertTrue(result.isVerfiyFail()); } catch (Exception e) { LOGGER.error(e.getMessage(),e); } }
*ExcelImportResult*
我们会返回一个ExcelImportResult 对象,比我们平时返回的list多了一些元素
/** * 结果集 */ private List<T> list; /** * 是否存在校验失败 */ private boolean verfiyFail; /** * 数据源 */ private Workbook workbook;
一个是集合,是一个是是否有校验失败的数据,一个原本的文档,但是在文档后面追加了错误信息
*注意,这里的list,有两种返回*
- 一种是只返回正确的数据
- 一种是返回全部的数据,但是要求这个对象必须实现IExcelModel接口,如下
*IExcelModel*
public class ExcelVerifyEntityOfMode extends ExcelVerifyEntity implements IExcelModel { private String errorMsg; @Override public String getErrorMsg() { return errorMsg; } @Override public void setErrorMsg(String errorMsg) { this.errorMsg = errorMsg; }}
*IExcelDataModel 获取错误数据的行号
public interface IExcelDataModel { /** * 获取行号 * @return */ public int getRowNum(); /** * 设置行号 * @param rowNum */ public void setRowNum(int rowNum);}
需要对象实现这个接口
每行的错误数据也会填到这个错误信息中,方便用户后面自定义处理 看下代码
@Test public void baseModetest() { try { ImportParams params = new ImportParams(); params.setNeedVerfiy(true); ExcelImportResult<ExcelVerifyEntityOfMode> result = ExcelImportUtil.importExcelMore( new FileInputStream(new File(PoiPublicUtil.getWebRootPath("import/verfiy.xlsx"))), ExcelVerifyEntityOfMode.class, params); FileOutputStream fos = new FileOutputStream("D:/excel/baseModetest.xlsx"); result.getWorkbook().write(fos); fos.close(); for (int i = 0; i < result.getList().size(); i++) { System.out.println(ReflectionToStringBuilder.toString(result.getList().get(i))); } Assert.assertTrue(result.getList().size() == 4); } catch (Exception e) { LOGGER.error(e.getMessage(),e); } }
*IExcelVerifyHandler*
加入上面的不满足你,你可以用接口实现自己的校验规则,比如唯一性校验,等等,需要返回错误信息和成功与否
public interface IExcelVerifyHandler<T> { /** * 导入校验方法 * * @param obj * 当前对象 * @return */ public ExcelVerifyHanlderResult verifyHandler(T obj);}
调用顺序是先通用的,再接口,到这里校验的就完整了,下面给大家看下错误的excel返回 
2.9 Excel 大批量读取
2.10 Excel大数据导出
大数据导出是当我们的导出数量在几万,到上百万的数据时,一次从数据库查询这么多数据加载到内存然后写入会对我们的内存和CPU都产生压力,这个时候需要我们像分页一样处理导出分段写入Excel缓解Excel的压力 EasyPoi提供的是两个方法 *强制使用 xssf版本的Excel*
/** * @param entity * 表格标题属性 * @param pojoClass * Excel对象Class * @param dataSet * Excel对象数据List */ public static Workbook exportBigExcel(ExportParams entity, Class<?> pojoClass, Collection<?> dataSet) { ExcelBatchExportServer batachServer = ExcelBatchExportServer .getExcelBatchExportServer(entity, pojoClass); return batachServer.appendData(dataSet); } public static void closeExportBigExcel() { ExcelBatchExportServer batachServer = ExcelBatchExportServer.getExcelBatchExportServer(null, null); batachServer.closeExportBigExcel(); }
添加数据和关闭服务,关闭服务不是必须的,可以调也可以不掉 我们只需要for循环写入Excel就可以了
@Test public void bigDataExport() throws Exception { List<MsgClient> list = new ArrayList<MsgClient>(); Workbook workbook = null; Date start = new Date(); ExportParams params = new ExportParams("大数据测试", "测试"); for (int i = 0; i < 1000000; i++) { //一百万数据量 MsgClient client = new MsgClient(); client.setBirthday(new Date()); client.setClientName("小明" + i); client.setClientPhone("18797" + i); client.setCreateBy("JueYue"); client.setId("1" + i); client.setRemark("测试" + i); MsgClientGroup group = new MsgClientGroup(); group.setGroupName("测试" + i); client.setGroup(group); list.add(client); if(list.size() == 10000){ workbook = ExcelExportUtil.exportBigExcel(params, MsgClient.class, list); list.clear(); } } ExcelExportUtil.closeExportBigExcel(); System.out.println(new Date().getTime() - start.getTime()); File savefile = new File("D:/excel/"); if (!savefile.exists()) { savefile.mkdirs(); } FileOutputStream fos = new FileOutputStream("D:/excel/ExcelExportBigData.bigDataExport.xlsx"); workbook.write(fos); fos.close(); }
生成的Excel数据 
Cpu和内存 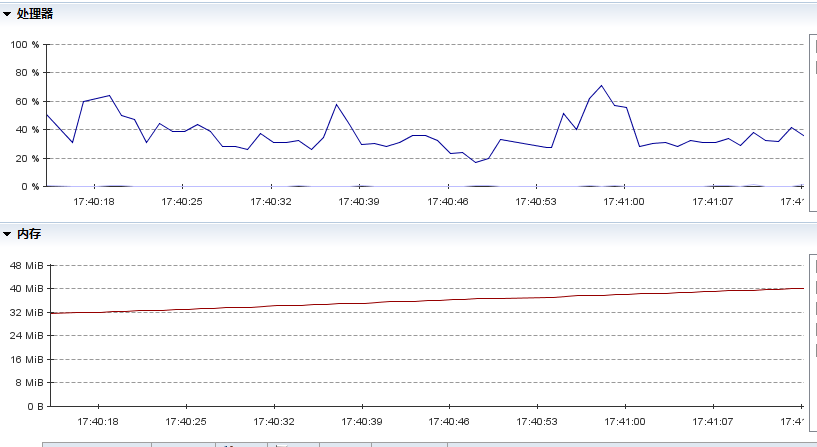
多次测试用时统计,速度还是可以接受的,^^
| 数据量 | 用时 | 文件大小 | 列数 |
|---|---|---|---|
| 100W | 16.4s | 24.3MB | 5 |
| 100W | 15.9s | 24.3MB | 5 |
| 200W | 29.5s | 48.5MB | 5 |
| 100W | 30.8s | 37.8MB | 10 |
| 200W | 58.7s | 76.1MB | 10 |
2.11 导入获取Key-Value
from 3.0.1 工作中是否会遇到导入读取一些特定的字段比如 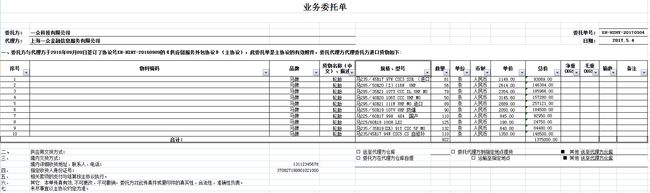 Excel 中的委托方,代理方,日期,单号,或者尾部的身份证号,电话等等,需要我们统一入库,这些字段没有具体位置,只能特定计算 这里给出了一个全新的解决办法 key-value 导入方法 key 是要导入的字段名称比如 委托方: 就认为是一个要导入的字段,后面的一个cell就是起对应的值 比如委托方: 一众科技有限公司 这样导入进去就是 key委托方,value 一众科技有限公司 示例代码
Excel 中的委托方,代理方,日期,单号,或者尾部的身份证号,电话等等,需要我们统一入库,这些字段没有具体位置,只能特定计算 这里给出了一个全新的解决办法 key-value 导入方法 key 是要导入的字段名称比如 委托方: 就认为是一个要导入的字段,后面的一个cell就是起对应的值 比如委托方: 一众科技有限公司 这样导入进去就是 key委托方,value 一众科技有限公司 示例代码
@Test public void test() { try { ImportParams params = new ImportParams(); params.setKeyMark(":"); params.setReadSingleCell(true); params.setTitleRows(7); params.setLastOfInvalidRow(9); ExcelImportResult<Map> result = ExcelImportUtil.importExcelMore( new File(PoiPublicUtil.getWebRootPath("import/业务委托单.xlsx")), Map.class, params); for (int i = 0; i < result.getList().size(); i++) { System.out.println(result.getList().get(i)); } Assert.assertTrue(result.getList().size() == 10); System.out.println(result.getMap()); } catch (Exception e) { LOGGER.error(e.getMessage(),e); } }
需要设置两个或者一个值 params.setKeyMark(“:”); 判断一个cell是key的规则,可以自定义,默认就是 “:” params.setReadSingleCell(true); 是否需要读取这种单独的sql 读取完毕后,通过result.getMap() 就可以拿到自己想要的值了比如上面的Excel读取到的map就是
{境内详细收货地址、联系人、电话:=1.3112345678E10, 委托方:=一众科技有限公司, 代理方:=上海一众金融信息服务有限公司, 委托单号:=XH-HZHY-20170504, 日期:=2017.5.4, 供应商交货方式:=, 合计:=, 境内交货方式:=, 指定收货人身份证号:=3.7082719880102099E17}
这样就比较方便的处理较为复杂的Excel导入了
2.12 groupname和ExcelEntity的name属性
之前一直没想好,双号表头如何处理数据,直到前几天突然想到了groupname这个属性,下面先介绍下这两个属性解决的问题,也是之前很多朋友问到的问题  这种双行的表头,之前只有在集合的模式情况下才会支持,但是很多情况都不是集合模式,也只是一列数据,
这种双行的表头,之前只有在集合的模式情况下才会支持,但是很多情况都不是集合模式,也只是一列数据,
- 简单的groupname
比如这里的时间算是两个时间的聚合,单也是对象当中的元素而已,我们要导出这样的数据现在只要设置下groupname就可以了
@Excel(name = "电话号码", groupName = "联系方式", orderNum = "1") private String clientPhone = null; // 客户姓名 @Excel(name = "姓名") private String clientName = null; // 备注 @Excel(name = "备注") private String remark = null; // 生日 @Excel(name = "出生日期", format = "yyyy-MM-dd", width = 20, groupName = "时间", orderNum = "2") private Date birthday = null; // 创建人 @Excel(name = "创建时间", groupName = "时间", orderNum = "3") private String createBy = null;
这样就会把两个groupname合并到一起展示,使用也比较简单
- ExcelEntity 一个对象在一起
假如我们需要一个对象属性统一在一起,name我们需要设置下这个对象的name属性,并且show=true 这两个是 且的关系 比如
@Excel(name = "电话号码", groupName = "联系方式", orderNum = "1") private String clientPhone = null; @Excel(name = "姓名") private String clientName = null; @ExcelEntity(name = "学生", show = true) private GnStudentEntity studentEntity;
学生对象的内部就是普通的注解
@Excel(name = "学生姓名", height = 20, width = 30, orderNum = "2") private String name; @Excel(name = "学生性别", replace = {"男_1", "女_0"}, suffix = "生", orderNum = "3") private int sex; @Excel(name = "出生日期", format = "yyyy-MM-dd", width = 20, orderNum = "4") private Date birthday; @Excel(name = "进校日期", format = "yyyy-MM-dd", orderNum = "5") private Date registrationDate;
出来的效果如下 
使用起来还是很简单的,导入的话同样设置就可以获取到了
- 排序问题
导出时,表头双行显示,聚合,排序以最小的值参与总体排序再内部排序 导出排序跟定义了annotation的字段的顺序有关 可以使用a_id,b_id来确实是否使用 优先弱与 @ExcelEntity 的name和show属性
简单说就是先排外部顺序,再排内部顺序
Excel 模板版
3.1 模板 指令介绍
模板是处理复杂Excel的简单方法,复杂的Excel样式,可以用Excel直接编辑,完美的避开了代码编写样式的雷区,同时指令的支持,也提了模板的有效性 下面列举下EasyPoi支持的指令以及作用,最主要的就是各种fe的用法
- 空格分割
- 三目运算 {{test ? obj:obj2}}
- n: 表示 这个cell是数值类型 {{n:}}
- le: 代表长度{{le:()}} 在if/else 运用{{le:() > 8 ? obj1 : obj2}}
- fd: 格式化时间 {{fd:(obj;yyyy-MM-dd)}}
- fn: 格式化数字 {{fn:(obj;###.00)}}
- fe: 遍历数据,创建row
- !fe: 遍历数据不创建row
- $fe: 下移插入,把当前行,下面的行全部下移.size()行,然后插入
- #fe: 横向遍历
- v_fe: 横向遍历值
- !if: 删除当前列 {{!if:(test)}}
- 单引号表示常量值 ‘’ 比如’1’ 那么输出的就是 1
- &NULL& 空格
- ]] 换行符 多行遍历导出
- sum: 统计数据
整体风格和el表达式类似,大家应该也比较熟悉 采用的写法是{{}}代表表达式,然后根据表达式里面的数据取值
关于样式问题 easypoi不会改变excel原有的样式,如果是遍历,easypoi会根据模板的那一行样式进行复制
测试项目
在cn.afterturn.easypoi.test.excel.template 这个目录下面 https://gitee.com/lemur/easypoi-test/tree/master/src/test/java/cn/afterturn/easypoi/test/excel/template
3.2 基本导出
看一个常见的到处模板–专项支出用款申请书  这里面有正常的标签以及 f e 遍历, fe遍历, fe遍历,fe遍历应该是使用最广的遍历,用来解决遍历后下面还有数据的处理方式 我们要生成的是这个需要一些list集合和一些单纯的数据
这里面有正常的标签以及 f e 遍历, fe遍历, fe遍历,fe遍历应该是使用最广的遍历,用来解决遍历后下面还有数据的处理方式 我们要生成的是这个需要一些list集合和一些单纯的数据
fe的写法 fe标志 冒号 list数据 单个元素数据(默认t,可以不写) 第一个元素 {{$fe: maplist t t.id }}
看下数据代码,主要是构造数据TemplateExportParams是主要的参数数据
@Test public void fe_map() throws Exception { TemplateExportParams params = new TemplateExportParams( "WEB-INF/doc/专项支出用款申请书_map.xls"); Map<String, Object> map = new HashMap<String, Object>(); map.put("date", "2014-12-25"); map.put("money", 2000000.00); map.put("upperMoney", "贰佰万"); map.put("company", "执笔潜行科技有限公司"); map.put("bureau", "财政局"); map.put("person", "JueYue"); map.put("phone", "1879740****"); List<Map<String, String>> listMap = new ArrayList<Map<String, String>>(); for (int i = 0; i < 4; i++) { Map<String, String> lm = new HashMap<String, String>(); lm.put("id", i + 1 + ""); lm.put("zijin", i * 10000 + ""); lm.put("bianma", "A001"); lm.put("mingcheng", "设计"); lm.put("xiangmumingcheng", "EasyPoi " + i + "期"); lm.put("quancheng", "开源项目"); lm.put("sqje", i * 10000 + ""); lm.put("hdje", i * 10000 + ""); listMap.add(lm); } map.put("maplist", listMap); Workbook workbook = ExcelExportUtil.exportExcel(params, map); File savefile = new File("D:/excel/"); if (!savefile.exists()) { savefile.mkdirs(); } FileOutputStream fos = new FileOutputStream("D:/excel/专项支出用款申请书_map.xls"); workbook.write(fos); fos.close(); }
看下输出的效果 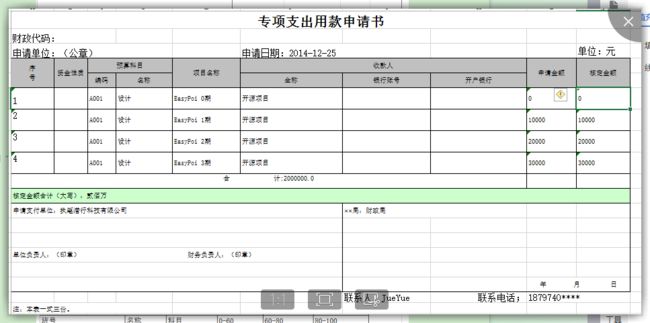
3.3 模板当中使用注解
3.4 图片导出
模板图片导出,没有注解导出图片那么容易,但也不算复杂,构建一个ImageEntity 设置下高宽,地址或者byte[]及可以了
ImageEntity image = new ImageEntity();image.setHeight(200);image.setWidth(500);image.setUrl("imgs/company/baidu.png");
具体的导出代码
@Test public void one() throws Exception { TemplateExportParams params = new TemplateExportParams( "doc/exportTemp_image.xls", true); Map<String, Object> map = new HashMap<String, Object>(); // sheet 2 map.put("month", 10); Map temp; for (int i = 1; i < 8; i++) { temp = new HashMap(); temp.put("per", i * 10); temp.put("mon", i * 1000); temp.put("summon", i * 10000); ImageEntity image = new ImageEntity(); image.setHeight(200); image.setWidth(500); image.setUrl("imgs/company/baidu.png"); temp.put("image", image); map.put("i" + i, temp); } Workbook book = ExcelExportUtil.exportExcel(params, map); File savefile = new File("D:/excel/"); if (!savefile.exists()) { savefile.mkdirs(); } FileOutputStream fos = new FileOutputStream("D:/excel/exportTemp_image.xls"); book.write(fos); fos.close(); }
Excel<->Html
4.1 Excel 的Html预览
Excel预览,这里支持了比较简单的预览,样式也都可以转换过去,支持03 和 更高版本 使用也是简单的很ExcelXorHtmlUtil.excelToHtml(params),也支持图片的预览,demo如下
/** * 07 版本EXCEL预览 */ @RequestMapping("07") public void toHtmlOf07Base(HttpServletResponse response) throws IOException, InvalidFormatException { ExcelToHtmlParams params = new ExcelToHtmlParams(WorkbookFactory.create(POICacheManager.getFile("exceltohtml/testExportTitleExcel.xlsx"))); response.getOutputStream().write(ExcelXorHtmlUtil.excelToHtml(params).getBytes()); } /** * 03 版本EXCEL预览 */ @RequestMapping("03img") public void toHtmlOf03Img(HttpServletResponse response) throws IOException, InvalidFormatException { ExcelToHtmlParams params = new ExcelToHtmlParams(WorkbookFactory.create(POICacheManager.getFile("exceltohtml/exporttemp_img.xls")),true,"yes"); response.getOutputStream().write(ExcelXorHtmlUtil.excelToHtml(params).getBytes()); }
返回一个string的html界面,输出到前台就可以了
4.2 html转Excel更神奇的导出
这个是一个MM提出的需求,需求原因是,她要导出一个比较复杂的Excel,无论用模板还是注解都比较难实现,所以她想到了这个方案,然后就实现了如下的方法,我的使用方法如下 自己搞个html,然后用模板引擎,beetl,freemark等生成html,然后调用easypoi提供的方法转换成Excel,因为html的标签以及规则大家比Excel要熟悉的多,更容易编写复杂的table,然后easypoi转换成Excel再导出,麻烦了点,但是可以处理一些特定的情况,也同样生成两个版本的Excel都支持 使用demo
@Test public void htmlToExcelByStr() throws Exception { StringBuilder html = new StringBuilder(); Scanner s = new Scanner(getClass().getResourceAsStream("/html/sample.html"), "utf-8"); while (s.hasNext()) { html.append(s.nextLine()); } s.close(); Workbook workbook = ExcelXorHtmlUtil.htmlToExcel(html.toString(), ExcelType.XSSF); File savefile = new File("D:\\home\\lemur"); if (!savefile.exists()) { savefile.mkdirs(); } FileOutputStream fos = new FileOutputStream("D:\\home\\lemur\\htmlToExcelByStr.xlsx"); workbook.write(fos); fos.close(); workbook = ExcelXorHtmlUtil.htmlToExcel(html.toString(), ExcelType.HSSF); fos = new FileOutputStream("D:\\home\\lemur\\htmlToExcelByStr.xls"); workbook.write(fos); fos.close(); } @Test public void htmlToExcelByIs() throws Exception { Workbook workbook = ExcelXorHtmlUtil.htmlToExcel(getClass().getResourceAsStream("/html/sample.html"), ExcelType.XSSF); File savefile = new File("D:\\home\\lemur"); if (!savefile.exists()) { savefile.mkdirs(); } FileOutputStream fos = new FileOutputStream("D:\\home\\lemur\\htmlToExcelByIs.xlsx"); workbook.write(fos); fos.close(); workbook = ExcelXorHtmlUtil.htmlToExcel(getClass().getResourceAsStream("/html/sample.html"), ExcelType.HSSF); fos = new FileOutputStream("D:\\home\\lemur\\htmlToExcelByIs.xls"); workbook.write(fos); fos.close(); }
提供了流或者字符串的入参,内部都多了缓存,多次生成不会重复解析
Word
5.1 word模板导出
word模板和Excel模板用法基本一致,支持的标签也是一致的,仅仅支持07版本的word也是只能生成后缀是docx的文档,poi对doc支持不好,所以这里也就懒得支持了,支持表格和图片,具体demo如下
/** * 简单导出包含图片 */ @Test public void imageWordExport() { Map<String, Object> map = new HashMap<String, Object>(); map.put("department", "Easypoi"); map.put("person", "JueYue"); map.put("time", format.format(new Date())); WordImageEntity image = new WordImageEntity(); image.setHeight(200); image.setWidth(500); image.setUrl("cn/afterturn/easypoi/test/word/img/testCode.png"); image.setType(WordImageEntity.URL); map.put("testCode", image); try { XWPFDocument doc = WordExportUtil.exportWord07( "cn/afterturn/easypoi/test/word/doc/Image.docx", map); FileOutputStream fos = new FileOutputStream("D:/excel/image.docx"); doc.write(fos); fos.close(); } catch (Exception e) { e.printStackTrace(); } } /** * 简单导出没有图片和Excel */ @Test public void SimpleWordExport() { Map<String, Object> map = new HashMap<String, Object>(); map.put("department", "Easypoi"); map.put("person", "JueYue"); map.put("time", format.format(new Date())); map.put("me","JueYue"); map.put("date", "2015-01-03"); try { XWPFDocument doc = WordExportUtil.exportWord07( "cn/afterturn/easypoi/test/word/doc/Simple.docx", map); FileOutputStream fos = new FileOutputStream("D:/excel/simple.docx"); doc.write(fos); fos.close(); } catch (Exception e) { e.printStackTrace(); } }
Spring MVC
7.1 View 介绍
easypoi view 项目是为了更简单的方便搭建在导出时候的操作,利用spring mvc 的view 封装,更加符合spring mvc的风格 view下面包括多个 view的实现
- EasypoiBigExcelExportView 大数据量导出
- EasypoiMapExcelView map 列表导出
- EasypoiPDFTemplateView pdf导出
- EasypoiSingleExcelView 注解导出
- EasypoiTemplateExcelView 模板导出
- EasypoiTemplateWordView word模板导出
- MapGraphExcelView 图表导出
view的是使用方法大同小异,都有一个对应的bean,里面保护指定的参数常量 同意用modelmap.put(‘常量参数名’,‘值’)就可以,最后返回这个view名字
注解目录扫描的时候加上 cn.afterturn.easypoi.view 就可以使用了
7.2 大数据导出View的用法
EasypoiBigExcelExportView 是针对大数据量导出特定的View,在跳转到这个View的时候不需要查询数据,而且这个View自己去查询数据,用户只要实现IExcelExportServer接口就可以了 对应的常量类BigExcelConstants
public interface IExcelExportServer { /** * 查询数据接口 * @param obj 查询条件 * @param page 当前页数 * @return */ public List<Object> selectListForExcelExport(Object obj, int page);}
EasypoiBigExcelExportView 判断是否还有下一页的条件是,如果selectListForExcelExport 返回null就认为是最后一页了,如果返回有数据这page+1继续查询 在我们自己的controller中
@RequestMapping("load") public void downloadByPoiBaseView(ModelMap map, HttpServletRequest request, HttpServletResponse response) { ExportParams params = new ExportParams("2412312", "测试", ExcelType.XSSF); params.setFreezeCol(2); map.put(BigExcelConstants.CLASS, MsgClient.class); map.put(BigExcelConstants.PARAMS, params); //就是我们的查询参数,会带到接口中,供接口查询使用 map.put(BigExcelConstants.DATA_PARAMS, new HashMap()); map.put(BigExcelConstants.DATA_INTER,excelExportServer); PoiBaseView.render(map, request, response, BigExcelConstants.EASYPOI_BIG_EXCEL_VIEW); }
我们需要把参数条件封装成map或者其他类型,上面的obj可以把参数自己转回来 参数名字 BigExcelConstants.DATA_PARAM 然后把实现查询的接口注入进来就可以了 *map.put(BigExcelConstants.DATA_INTER,excelExportServer);* 后面就和其他View一样了
7.3 注解导出View用法
注解导出的View是这个EasypoiSingleExcelView,其实View大家可以忽略不看,主要用到的还是他对应的bean对象 NormalExcelConstants 注解到处还比较简单,大家只要把datalist,class和params 这几个参数put下就可以了。 具体的案例
@RequestMapping() public String download(ModelMap map) { List<MsgClient> list = new ArrayList<MsgClient>(); for (int i = 0; i < 100; i++) { MsgClient client = new MsgClient(); client.setBirthday(new Date()); client.setClientName("小明" + i); client.setClientPhone("18797" + i); client.setCreateBy("JueYue"); client.setId("1" + i); client.setRemark("测试" + i); MsgClientGroup group = new MsgClientGroup(); group.setGroupName("测试" + i); client.setGroup(group); list.add(client); } ExportParams params = new ExportParams("2412312", "测试", ExcelType.XSSF); params.setFreezeCol(2); map.put(NormalExcelConstants.DATA_LIST, list); // 数据集合 map.put(NormalExcelConstants.CLASS, MsgClient.class);//导出实体 map.put(NormalExcelConstants.PARAMS, params);//参数 map.put(NormalExcelConstants.FILE_NAME, params);//文件名称 return NormalExcelConstants.EASYPOI_EXCEL_VIEW;//View名称 }
和非View导出基本一致,只是把调用方法封装了而已,其他参数还都是一样的,具体可以看下测试项目的 EasypoiSingleExcelViewTest
7.4 注解变种Map类型的导出View
作为动态注解存在的 List ,也提供的单独的View方便大家使用,EasypoiMapExcelView 使用方法都是一样,直接看下例子吧
@RequestMapping() public String download(ModelMap modelMap) { List<ExcelExportEntity> entity = new ArrayList<ExcelExportEntity>(); ExcelExportEntity excelentity = new ExcelExportEntity("姓名", "name"); excelentity.setNeedMerge(true); entity.add(excelentity); entity.add(new ExcelExportEntity("性别", "sex")); excelentity = new ExcelExportEntity(null, "students"); List<ExcelExportEntity> temp = new ArrayList<ExcelExportEntity>(); temp.add(new ExcelExportEntity("姓名", "name")); temp.add(new ExcelExportEntity("性别", "sex")); excelentity.setList(temp); entity.add(excelentity); List<Map<String, Object>> list = new ArrayList<Map<String, Object>>(); Map<String, Object> map; for (int i = 0; i < 10; i++) { map = new HashMap<String, Object>(); map.put("name", "1" + i); map.put("sex", "2" + i); List<Map<String, Object>> tempList = new ArrayList<Map<String, Object>>(); tempList.add(map); tempList.add(map); map.put("students", tempList); list.add(map); } ExportParams params = new ExportParams("2412312", "测试", ExcelType.XSSF); params.setFreezeCol(2); modelMap.put(MapExcelConstants.MAP_LIST, list); //数据集合 modelMap.put(MapExcelConstants.ENTITY_LIST, entity); //注解集合 modelMap.put(MapExcelConstants.PARAMS, params);//参数 modelMap.put(MapExcelConstants.FILE_NAME, "EasypoiMapExcelViewTest");//文件名称 return MapExcelConstants.EASYPOI_MAP_EXCEL_VIEW;//View名称 }
具体案例参考EasypoiMapExcelViewTest
7.5Excel模板导出View
模板导出提供的EasypoiTemplateExcelView以及对应的bean *TemplateExcelConstants* 案例
@RequestMapping() public String download(ModelMap modelMap) { Map<String, Object> map = new HashMap<String, Object>(); TemplateExportParams params = new TemplateExportParams( "doc/foreach.xlsx"); List<TemplateExcelExportEntity> list = new ArrayList<TemplateExcelExportEntity>(); for (int i = 0; i < 4; i++) { TemplateExcelExportEntity entity = new TemplateExcelExportEntity(); entity.setIndex(i + 1 + ""); entity.setAccountType("开源项目"); entity.setProjectName("EasyPoi " + i + "期"); entity.setAmountApplied(i * 10000 + ""); entity.setApprovedAmount((i + 1) * 10000 - 100 + ""); list.add(entity); } map.put("entitylist", list); map.put("manmark", "1"); map.put("letest", "12345678"); map.put("fntest", "12345678.2341234"); map.put("fdtest", null); List<Map<String, Object>> mapList = new ArrayList<Map<String, Object>>(); for (int i = 0; i < 1; i++) { Map<String, Object> testMap = new HashMap<String, Object>(); testMap.put("id", "xman"); testMap.put("name", "小明" + i); testMap.put("sex", "1"); mapList.add(testMap); } map.put("maplist", mapList); mapList = new ArrayList<Map<String, Object>>(); for (int i = 0; i < 6; i++) { Map<String, Object> testMap = new HashMap<String, Object>(); testMap.put("si", "xman"); mapList.add(testMap); } map.put("sitest", mapList); modelMap.put(TemplateExcelConstants.FILE_NAME, "用户信息"); //文件名 modelMap.put(TemplateExcelConstants.PARAMS, params);//参数 modelMap.put(TemplateExcelConstants.MAP_DATA, map);//数据 return TemplateExcelConstants.EASYPOI_TEMPLATE_EXCEL_VIEW;//view名称 }
具体案例EasypoiTemplateExcelViewTest
7.6 PoiBaseView.render view的补救
假如因为不可抗拒或者其他神奇的原因,view导出无法使用,作者遇到过好几次了,各种神奇原因都有,提供一个统一的封装,算是一个补救措施吧 上面的modelMap写法和设置参数还是一样,最后直接输出就可以了 PoiBaseView.render(modelMap, request, response,View名称);
看个简单demo
@RequestMapping("load") public void downloadByPoiBaseView(ModelMap map, HttpServletRequest request, HttpServletResponse response) { List<MsgClient> list = new ArrayList<MsgClient>(); for (int i = 0; i < 100; i++) { MsgClient client = new MsgClient(); client.setBirthday(new Date()); client.setClientName("小明" + i); client.setClientPhone("18797" + i); client.setCreateBy("JueYue"); client.setId("1" + i); client.setRemark("测试" + i); MsgClientGroup group = new MsgClientGroup(); group.setGroupName("测试" + i); client.setGroup(group); list.add(client); } ExportParams params = new ExportParams("2412312", "测试", ExcelType.XSSF); params.setFreezeCol(2); map.put(NormalExcelConstants.DATA_LIST, list); map.put(NormalExcelConstants.CLASS, MsgClient.class); map.put(NormalExcelConstants.PARAMS, params); PoiBaseView.render(map, request, response, NormalExcelConstants.EASYPOI_EXCEL_VIEW); }
Apache POI
1.POI结构与常用类
(1)POI介绍
Apache POI是Apache软件基金会的开源项目,POI提供API给Java程序对Microsoft Office格式档案读和写的功能。 .NET的开发人员则可以利用NPOI (POI for .NET) 来存取 Microsoft Office文档的功能。
(2)POI结构说明
包名称说明
HSSF提供读写Microsoft Excel XLS格式档案的功能。XSSF提供读写Microsoft Excel OOXML XLSX格式档案的功能。HWPF提供读写Microsoft Word DOC格式档案的功能。HSLF提供读写Microsoft PowerPoint格式档案的功能。HDGF提供读Microsoft Visio格式档案的功能。HPBF提供读Microsoft Publisher格式档案的功能。HSMF提供读Microsoft Outlook格式档案的功能。
(3)POI常用类说明
类名 说明
HSSFWorkbook Excel的文档对象
HSSFSheet Excel的表单HSSFRow Excel的行HSSFCell
Excel的格子单元
HSSFFont Excel字体
HSSFDataFormat 格子单元的日期格式HSSFHeader Excel文档Sheet的页眉HSSFFooter Excel文档Sheet的页脚HSSFCellStyle 格子单元样式HSSFDateUtil 日期HSSFPrintSetup 打印
HSSFErrorConstants 错误信息表
2.Excel的基本操作
(1)创建Workbook和Sheet
public class Test00 { public static void main(String[] args) throws IOException { String filePath = "d:\\users\\lizw\\桌面\\POI\\sample.xls";//文件路径 HSSFWorkbook workbook = new HSSFWorkbook();//创建Excel文件(Workbook) HSSFSheet sheet = workbook.createSheet();//创建工作表(Sheet) sheet = workbook.createSheet("Test");//创建工作表(Sheet) FileOutputStream out = new FileOutputStream(filePath); workbook.write(out);//保存Excel文件 out.close();//关闭文件流 System.out.println("OK!"); } }
(2)创建单元格
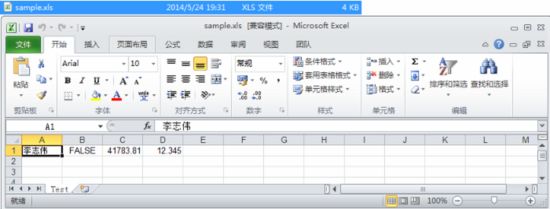
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFRow row = sheet.createRow(0);// 创建行,从0开始HSSFCell cell = row.createCell(0);// 创建行的单元格,也是从0开始cell.setCellValue("李志伟");// 设置单元格内容row.createCell(1).setCellValue(false);// 设置单元格内容,重载row.createCell(2).setCellValue(new Date());// 设置单元格内容,重载row.createCell(3).setCellValue(12.345);// 设置单元格内容,重载
(3)创建文档摘要信息
workbook.createInformationProperties();//创建文档信息DocumentSummaryInformation dsi=workbook.getDocumentSummaryInformation();//摘要信息dsi.setCategory("类别:Excel文件");//类别dsi.setManager("管理者:李志伟");//管理者dsi.setCompany("公司:--");//公司SummaryInformation si = workbook.getSummaryInformation();//摘要信息si.setSubject("主题:--");//主题si.setTitle("标题:测试文档");//标题si.setAuthor("作者:李志伟");//作者si.setComments("备注:POI测试文档");//备注

(4)创建批注
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFPatriarch patr = sheet.createDrawingPatriarch();HSSFClientAnchor anchor = patr.createAnchor(0, 0, 0, 0, 5, 1, 8,3);//创建批注位置HSSFComment comment = patr.createCellComment(anchor);//创建批注comment.setString(new HSSFRichTextString("这是一个批注段落!"));//设置批注内容comment.setAuthor("李志伟");//设置批注作者comment.setVisible(true);//设置批注默认显示HSSFCell cell = sheet.createRow(2).createCell(1);cell.setCellValue("测试");cell.setCellComment(comment);//把批注赋值给单元格
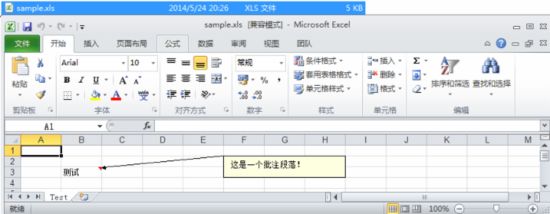
创建批注位置HSSFPatriarch.createAnchor(dx1, dy1, dx2, dy2, col1, row1, col2, row2)方法参数说明:
dx1 第1个单元格中x轴的偏移量dy1 第1个单元格中y轴的偏移量dx2 第2个单元格中x轴的偏移量dy2 第2个单元格中y轴的偏移量col1 第1个单元格的列号row1 第1个单元格的行号col2 第2个单元格的列号row2 第2个单元格的行号
(5)创建页眉和页脚
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFHeader header =sheet.getHeader();//得到页眉header.setLeft("页眉左边");header.setRight("页眉右边");header.setCenter("页眉中间");HSSFFooter footer =sheet.getFooter();//得到页脚footer.setLeft("页脚左边");footer.setRight("页脚右边");footer.setCenter("页脚中间");
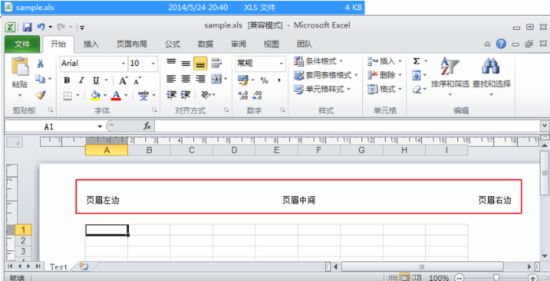
也可以使用Office自带的标签定义,你可以通过HSSFHeader或HSSFFooter访问到它们,都是静态属性,列表如下:
HSSFHeader.tab &A 表名HSSFHeader.file &F 文件名HSSFHeader.startBold &B 粗体开始HSSFHeader.endBold &B 粗体结束HSSFHeader.startUnderline &U 下划线开始HSSFHeader.endUnderline &U 下划线结束HSSFHeader.startDoubleUnderline &E 双下划线开始HSSFHeader.endDoubleUnderline &E 双下划线结束HSSFHeader.time &T 时间HSSFHeader.date &D 日期HSSFHeader.numPages &N 总页面数HSSFHeader.page &P 当前页号
3.Excel的单元格操作
(1)设置格式
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFRow row=sheet.createRow(0);//设置日期格式--使用Excel内嵌的格式HSSFCell cell=row.createCell(0);cell.setCellValue(new Date());HSSFCellStyle style=workbook.createCellStyle();style.setDataFormat(HSSFDataFormat.getBuiltinFormat("m/d/yy h:mm"));cell.setCellStyle(style);//设置保留2位小数--使用Excel内嵌的格式cell=row.createCell(1);cell.setCellValue(12.3456789);style=workbook.createCellStyle();style.setDataFormat(HSSFDataFormat.getBuiltinFormat("0.00"));cell.setCellStyle(style);//设置货币格式--使用自定义的格式cell=row.createCell(2);cell.setCellValue(12345.6789);style=workbook.createCellStyle();style.setDataFormat(workbook.createDataFormat().getFormat("¥#,##0"));cell.setCellStyle(style);//设置百分比格式--使用自定义的格式cell=row.createCell(3);cell.setCellValue(0.123456789);style=workbook.createCellStyle();style.setDataFormat(workbook.createDataFormat().getFormat("0.00%"));cell.setCellStyle(style);//设置中文大写格式--使用自定义的格式cell=row.createCell(4);cell.setCellValue(12345);style=workbook.createCellStyle();style.setDataFormat(workbook.createDataFormat().getFormat("[DbNum2][$-804]0"));cell.setCellStyle(style);//设置科学计数法格式--使用自定义的格式cell=row.createCell(5);cell.setCellValue(12345);style=workbook.createCellStyle();style.setDataFormat(workbook.createDataFormat().getFormat("0.00E+00"));cell.setCellStyle(style);
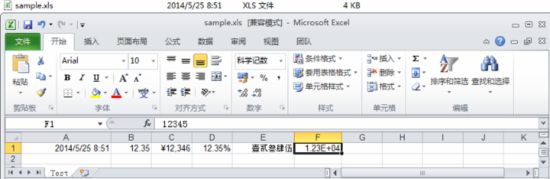
HSSFDataFormat.getFormat和HSSFDataFormat.getBuiltinFormat的区别: 当使用Excel内嵌的(或者说预定义)的格式时,直接用HSSFDataFormat.getBuiltinFormat静态方法即可。当使用自己定义的格式时,必须先调用HSSFWorkbook.createDataFormat(),因为这时在底层会先找有没有匹配的内嵌FormatRecord,如果没有就会新建一个FormatRecord,所以必须先调用这个方法,然后你就可以用获得的HSSFDataFormat实例的getFormat方法了,当然相对而言这种方式比较麻烦,所以内嵌格式还是用HSSFDataFormat.getBuiltinFormat静态方法更加直接一些。
(2)合并单元格
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFRow row=sheet.createRow(0);//合并列HSSFCell cell=row.createCell(0);cell.setCellValue("合并列");CellRangeAddress region=new CellRangeAddress(0, 0, 0, 5);sheet.addMergedRegion(region);//合并行cell=row.createCell(6);cell.setCellValue("合并行");region=new CellRangeAddress(0, 5, 6, 6);sheet.addMergedRegion(region);
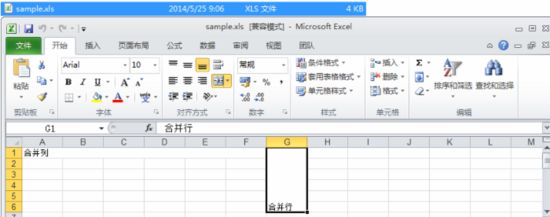
CellRangeAddress对象其实就是表示一个区域,其构造方法如下:CellRangeAddress(firstRow, lastRow, firstCol, lastCol),参数的说明:
-
firstRow 区域中第一个单元格的行号 -
lastRow 区域中最后一个单元格的行号 -
firstCol 区域中第一个单元格的列号 -
lastCol 区域中最后一个单元格的列号提示: 即使你没有用CreateRow和CreateCell创建过行或单元格,也完全可以直接创建区域然后把这一区域合并,Excel的区域合并信息是单独存储的,和RowRecord、ColumnInfoRecord不存在直接关系。
(3)单元格对齐
HSSFCell cell=row.createCell(0);cell.setCellValue("单元格对齐");HSSFCellStyle style=workbook.createCellStyle();style.setAlignment(HSSFCellStyle.ALIGN_CENTER);//水平居中style.setVerticalAlignment(HSSFCellStyle.VERTICAL_CENTER);//垂直居中style.setWrapText(true);//自动换行style.setIndention((short)5);//缩进style.setRotation((short)60);//文本旋转,这里的取值是从-90到90,而不是0-180度。cell.setCellStyle(style);

水平对齐相关参数
-
如果是左侧对齐就是 HSSFCellStyle.ALIGN_FILL; -
如果是居中对齐就是 HSSFCellStyle.ALIGN_CENTER; -
如果是右侧对齐就是 HSSFCellStyle.ALIGN_RIGHT; -
如果是跨列举中就是 HSSFCellStyle.ALIGN_CENTER_SELECTION; -
如果是两端对齐就是 HSSFCellStyle.ALIGN_JUSTIFY; -
如果是填充就是 HSSFCellStyle.ALIGN_FILL;垂直对齐相关参数
-
如果是靠上就是 HSSFCellStyle.VERTICAL_TOP; -
如果是居中就是 HSSFCellStyle.VERTICAL_CENTER; -
如果是靠下就是 HSSFCellStyle.VERTICAL_BOTTOM; -
如果是两端对齐就是 HSSFCellStyle.VERTICAL_JUSTIFY;
(4)使用边框
边框和其他单元格设置一样也是调用CellStyle接口,CellStyle有2种和边框相关的属性,分别是:
| 边框相关属性 | 说明 | 范例 |
|---|---|---|
| Border+ 方向 | 边框类型 | BorderLeft, BorderRight 等 |
| 方向 +BorderColor | 边框颜色 | TopBorderColor,BottomBorderColor 等 |
HSSFCell cell=row.createCell(1);cell.setCellValue("设置边框");HSSFCellStyle style=workbook.createCellStyle();style.setBorderTop(HSSFCellStyle.BORDER_DOTTED);//上边框style.setBorderBottom(HSSFCellStyle.BORDER_THICK);//下边框style.setBorderLeft(HSSFCellStyle.BORDER_DOUBLE);//左边框style.setBorderRight(HSSFCellStyle.BORDER_SLANTED_DASH_DOT);//右边框style.setTopBorderColor(HSSFColor.RED.index);//上边框颜色style.setBottomBorderColor(HSSFColor.BLUE.index);//下边框颜色style.setLeftBorderColor(HSSFColor.GREEN.index);//左边框颜色style.setRightBorderColor(HSSFColor.PINK.index);//右边框颜色cell.setCellStyle(style);

其中边框类型分为以下几种:
| 边框范例图 | 对应的静态值 |
|---|---|
| HSSFCellStyle. BORDER_DOTTED | |
| HSSFCellStyle. BORDER_HAIR | |
| HSSFCellStyle. BORDER_DASH_DOT_DOT | |
| HSSFCellStyle. BORDER_DASH_DOT | |
| HSSFCellStyle. BORDER_DASHED | |
| HSSFCellStyle. BORDER_THIN | |
| HSSFCellStyle. BORDER_MEDIUM_DASH_DOT_DOT | |
| HSSFCellStyle. BORDER_SLANTED_DASH_DOT | |
 |
HSSFCellStyle. BORDER_MEDIUM_DASH_DOT |
| HSSFCellStyle. BORDER_MEDIUM_DASHED | |
| HSSFCellStyle. BORDER_MEDIUM | |
| HSSFCellStyle. BORDER_THICK | |
| HSSFCellStyle. BORDER_DOUBLE |
(5)设置字体
HSSFCell cell = row.createCell(1);cell.setCellValue("设置字体");HSSFCellStyle style = workbook.createCellStyle();HSSFFont font = workbook.createFont();font.setFontName("华文行楷");//设置字体名称font.setFontHeightInPoints((short)28);//设置字号font.setColor(HSSFColor.RED.index);//设置字体颜色font.setUnderline(FontFormatting.U_SINGLE);//设置下划线font.setTypeOffset(FontFormatting.SS_SUPER);//设置上标下标font.setStrikeout(true);//设置删除线style.setFont(font);cell.setCellStyle(style);
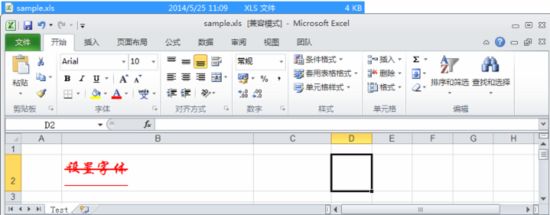
下划线选项值:
单下划线 FontFormatting.U_SINGLE
双下划线 FontFormatting.U_DOUBLE
会计用单下划线 FontFormatting.U_SINGLE_ACCOUNTING
会计用双下划线 FontFormatting.U_DOUBLE_ACCOUNTING
无下划线 FontFormatting.U_NONE
上标下标选项值:
上标 FontFormatting.SS_SUPER
下标 FontFormatting.SS_SUB
普通,默认值 FontFormatting.SS_NONE
(6)背景和纹理
HSSFCellStyle style = workbook.createCellStyle();style.setFillForegroundColor(HSSFColor.GREEN.index);//设置图案颜色style.setFillBackgroundColor(HSSFColor.RED.index);//设置图案背景色style.setFillPattern(HSSFCellStyle.SQUARES);//设置图案样式cell.setCellStyle(style);
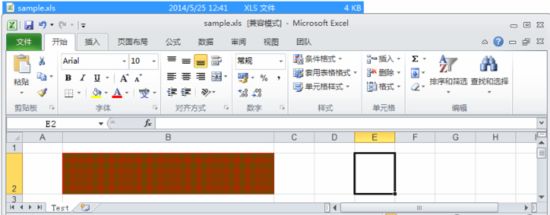
图案样式及其对应的值:
| 图案样式 | 常量 |
|---|---|
| HSSFCellStyle. NO_FILL | |
| HSSFCellStyle. ALT_BARS | |
| HSSFCellStyle. FINE_DOTS | |
| HSSFCellStyle. SPARSE_DOTS | |
| HSSFCellStyle. LESS_DOTS | |
| HSSFCellStyle. LEAST_DOTS | |
| HSSFCellStyle. BRICKS | |
| HSSFCellStyle. BIG_SPOTS | |
 |
HSSFCellStyle. THICK_FORWARD_DIAG |
| HSSFCellStyle. THICK_BACKWARD_DIAG | |
| HSSFCellStyle. THICK_VERT_BANDS | |
| HSSFCellStyle. THICK_HORZ_BANDS | |
| HSSFCellStyle. THIN_HORZ_BANDS | |
| HSSFCellStyle. THIN_VERT_BANDS | |
| HSSFCellStyle. THIN_BACKWARD_DIAG | |
| HSSFCellStyle. THIN_FORWARD_DIAG | |
| HSSFCellStyle. SQUARES | |
| HSSFCellStyle. DIAMONDS |
(7)设置宽度和高度
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFRow row = sheet.createRow(1);HSSFCell cell = row.createCell(1);cell.setCellValue("123456789012345678901234567890");sheet.setColumnWidth(1, 31 * 256);//设置第一列的宽度是31个字符宽度row.setHeightInPoints(50);//设置行的高度是50个点

这里你会发现一个有趣的现象,setColumnWidth的第二个参数要乘以256,这是怎么回事呢?其实,这个参数的单位是1/256个字符宽度,也就是说,这里是把B列的宽度设置为了31个字符。
设置行高使用HSSFRow对象的setHeight和setHeightInPoints方法,这两个方法的区别在于setHeightInPoints的单位是点,而setHeight的单位是1/20个点,所以setHeight的值永远是setHeightInPoints的20倍。
你也可以使用HSSFSheet.setDefaultColumnWidth、HSSFSheet.setDefaultRowHeight和HSSFSheet.setDefaultRowHeightInPoints方法设置默认的列宽或行高。
(8)判断单元格是否为日期
判断单元格是否为日期类型,使用DateUtil.isCellDateFormatted(cell)方法,例如:
HSSFCell cell = row.createCell(1);cell.setCellValue(new Date());//设置日期数据System.out.println(DateUtil.isCellDateFormatted(cell));//输出:falseHSSFCellStyle style =workbook.createCellStyle();style.setDataFormat(HSSFDataFormat.getBuiltinFormat("m/d/yy h:mm"));cell.setCellStyle(style);//设置日期样式System.out.println(DateUtil.isCellDateFormatted(cell));//输出:true
4.使用Excel公式
(1)基本计算
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFRow row = sheet.createRow(0);HSSFCell cell = row.createCell(0);cell.setCellFormula("2+3*4");//设置公式cell = row.createCell(1);cell.setCellValue(10);cell = row.createCell(2);cell.setCellFormula("A1*B1");//设置公式

(2)SUM函数
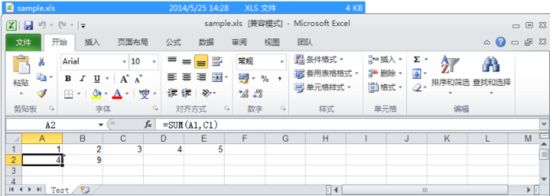
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFRow row = sheet.createRow(0);row.createCell(0).setCellValue(1);row.createCell(1).setCellValue(2);row.createCell(2).setCellValue(3);row.createCell(3).setCellValue(4);row.createCell(4).setCellValue(5);row = sheet.createRow(1);row.createCell(0).setCellFormula("sum(A1,C1)");//等价于"A1+C1"row.createCell(1).setCellFormula("sum(B1:D1)");//等价于"B1+C1+D1"
(3)日期函数
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFCellStyle style=workbook.createCellStyle();style.setDataFormat(workbook.createDataFormat().getFormat("yyyy-mm-dd"));HSSFRow row = sheet.createRow(0);Calendar date=Calendar.getInstance();//日历对象HSSFCell cell=row.createCell(0);date.set(2011,2, 7);cell.setCellValue(date.getTime());cell.setCellStyle(style);//第一个单元格开始时间设置完成cell=row.createCell(1);date.set(2014,4, 25);cell.setCellValue(date.getTime());cell.setCellStyle(style);//第一个单元格结束时间设置完成cell=row.createCell(3);cell.setCellFormula("CONCATENATE(DATEDIF(A1,B1,\"y\"),\"年\")");cell=row.createCell(4);cell.setCellFormula("CONCATENATE(DATEDIF(A1,B1,\"m\"),\"月\")");cell=row.createCell(5);cell.setCellFormula("CONCATENATE(DATEDIF(A1,B1,\"d\"),\"日\")");
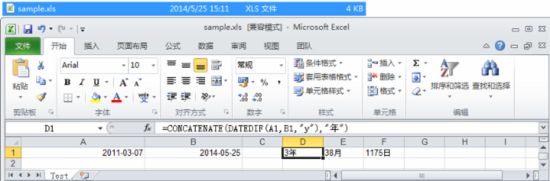
以上代码中的公式说明:
DATEDIF(A1,B1,“y”) :取得 A1 单元格的日期与 B1 单元格的日期的时间间隔。 ( “ y ” : 表示以年为单位 , ” m ”表示以月为单位 ; ” d ”表示以天为单位 ) 。
CONCATENATE( str1,str2, … ) :连接字符串。
更多 Excel 的日期函数可参考:http://tonyqus.sinaapp.com/archives/286
(4)字符串相关函数
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFRow row = sheet.createRow(0);row.createCell(0).setCellValue("abcdefg");row.createCell(1).setCellValue("aa bb cc dd ee fF GG");row.createCell(3).setCellFormula("UPPER(A1)");row.createCell(4).setCellFormula("PROPER(B1)");
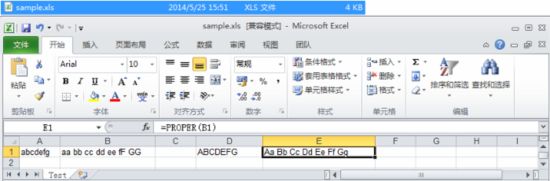
以上代码中的公式说明:
UPPER( String ) :将文本转换成大写形式。
PROPER( String ) :将文字串的首字母及任何非字母字符之后的首字母转换成大写。将其余的字母转换成小写。
更多 Excel 的字符串函数可参考:http://tonyqus.sinaapp.com/archives/289
(5)IF函数
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFRow row = sheet.createRow(0);row.createCell(0).setCellValue(12);row.createCell(1).setCellValue(23);row.createCell(3).setCellFormula("IF(A1>B1,\"A1大于B1\",\"A1小于等于B1\")");
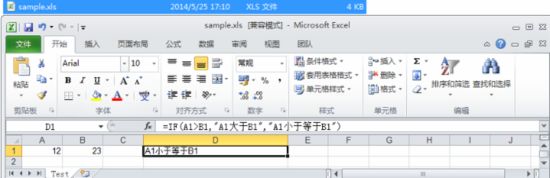
以上代码中的公式说明:
IF(logical_test,value_if_true,value_if_false)用来用作逻辑判断。其中Logical_test表示计算结果为 TRUE 或 FALSE 的任意值或表达式 ; value_if_true表示当表达式Logical_test的值为TRUE时的返回值;value_if_false表示当表达式Logical_test的值为FALSE时的返回值。
(6)CountIf和SumIf函数
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFRow row = sheet.createRow(0);row.createCell(0).setCellValue(57);row.createCell(1).setCellValue(89);row.createCell(2).setCellValue(56);row.createCell(3).setCellValue(67);row.createCell(4).setCellValue(60);row.createCell(5).setCellValue(73);row.createCell(7).setCellFormula("COUNTIF(A1:F1,\">=60\")");row.createCell(8).setCellFormula("SUMIF(A1:F1,\">=60\",A1:F1)");

以上代码中的公式说明:
COUNTIF(range,criteria):满足某条件的计数的函数。参数range:需要进行读数的计数;参数criteria:条件表达式,只有当满足此条件时才进行计数。
SumIF(criteria_range, criteria,sum_range):用于统计某区域内满足某条件的值的求和。参数criteria_range:条件测试区域,第二个参数Criteria中的条件将与此区域中的值进行比较;参数criteria:条件测试值,满足条件的对应的sum_range项将进行求和计算;参数sum_range:汇总数据所在区域,求和时会排除掉不满足Criteria条件的对应的项。
(7)Lookup函数
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFRow row = sheet.createRow(0);row.createCell(0).setCellValue(0);row.createCell(1).setCellValue(59);row.createCell(2).setCellValue("不及格");row = sheet.createRow(1);row.createCell(0).setCellValue(60);row.createCell(1).setCellValue(69);row.createCell(2).setCellValue("及格");row = sheet.createRow(2);row.createCell(0).setCellValue(70);row.createCell(1).setCellValue(79);row.createCell(2).setCellValue("良好");row = sheet.createRow(3);row.createCell(0).setCellValue(80);row.createCell(1).setCellValue(100);row.createCell(2).setCellValue("优秀");row = sheet.createRow(4);row.createCell(0).setCellValue(75);row.createCell(1).setCellFormula("LOOKUP(A5,$A$1:$A$4,$C$1:$C$4)");row.createCell(2).setCellFormula("VLOOKUP(A5,$A$1:$C$4,3,true)");
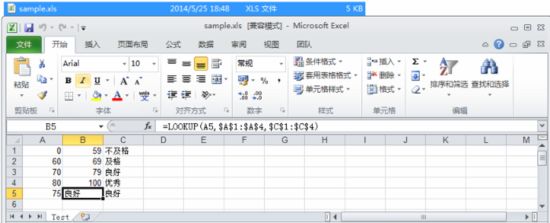
以上代码中的公式说明:
LOOKUP(lookup_value,lookup_vector,result_vector) ,第一个参数:需要查找的内容,本例中指向 A5 单元格,也就是 75 ;第二个参数:比较对象区域,本例中的成绩需要与 $A 1 : 1: 1:A 4 中的各单元格中的值进行比较;第三个参数:查找结果区域,如果匹配到会将此区域中对应的数据返回。如本例中返回 4 中的各单元格中的值进行比较;第三个参数:查找结果区域,如果匹配到会将此区域中对应的数据返回。如本例中返回 4中的各单元格中的值进行比较;第三个参数:查找结果区域,如果匹配到会将此区域中对应的数据返回。如本例中返回C 1 : 1: 1:C$4 中对应的值。
可能有人会问,字典中没有 75 对应的成绩啊,那么 Excel 中怎么匹配的呢?答案是模糊匹配,并且 LOOKUP 函数只支持模糊匹配。 Excel 会在 $A 1 : 1: 1:A$4 中找小于 75 的最大值,也就是 A3 对应的 70 ,然后将对应的 $C 1 : 1: 1:C$4 区域中的 C3 中的值返回,这就是最终结果“良好”的由来。
VLOOKUP(lookup_value,lookup_area,result_col,is_fuzzy ) ,第一个参数:需要查找的内容,这里是 A5 单元格;第二个参数:需要比较的表,这里是 $A 1 : 1: 1:C$4 ,注意 VLOOKUP 匹配时只与表中的第一列进行匹配。第三个参数:匹配结果对应的列序号。这里要对应的是成绩列,所以为 3 。第四个参数:指明是否模糊匹配。例子中的 TRUE 表示模糊匹配,与上例中一样。匹配到的是第三行。如果将此参数改为 FALSE ,因为在表中的第 1 列中找不到 75 ,所以会报“#N/A ”的计算错误。
另外,还有与 VLOKUP 类似的 HLOOKUP 。不同的是 VLOOKUP 用于在表格或数值数组的首列查找指定的数值,并由此返回表格或数组当前行中指定列处的数值。而HLOOKUP 用于在表格或数值数组的首行查找指定的数值,并由此返回表格或数组当前列中指定行处的数值。读者可以自已去尝试。
(8)随机数函数
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFRow row = sheet.createRow(0);row.createCell(0).setCellFormula("RAND()");//取0-1之间的随机数row.createCell(1).setCellFormula("int(RAND()*100)");//取0-100之间的随机整数row.createCell(2).setCellFormula("rand()*10+10");//取10-20之间的随机实数row.createCell(3).setCellFormula("CHAR(INT(RAND()*26)+97)");//随机小写字母row.createCell(4).setCellFormula("CHAR(INT(RAND()*26)+65)");//随机大写字母//随机大小写字母row.createCell(5).setCellFormula("CHAR(INT(RAND()*26)+if(INT(RAND()*2)=0,97,65))");

以上代码中的公式说明:
上面几例中除了用到RAND函数以外,还用到了CHAR函数用来将ASCII码换为字母,INT函数用来取整。值得注意的是INT函数不会四舍五入,无论小数点后是多少都会被舍去。
(9)获得公式的返回值
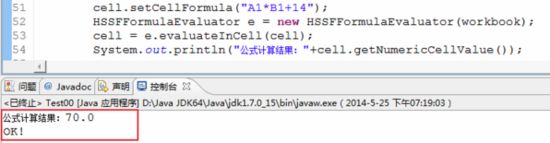
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFRow row = sheet.createRow(0);row.createCell(0).setCellValue(7);//A1row.createCell(1).setCellValue(8);//B1HSSFCell cell=row.createCell(2);cell.setCellFormula("A1*B1+14");HSSFFormulaEvaluator e = newHSSFFormulaEvaluator(workbook);cell = e.evaluateInCell(cell);//若Excel文件不是POI创建的,则不必调用此方法System.out.println("公式计算结果:"+cell.getNumericCellValue());
5.使用图形
(1)画线
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFPatriarch patriarch=sheet.createDrawingPatriarch();HSSFClientAnchor anchor = new HSSFClientAnchor(0, 0, 0, 0,(short)1, 0,(short)4, 4);HSSFSimpleShape line = patriarch.createSimpleShape(anchor);line.setShapeType(HSSFSimpleShape.OBJECT_TYPE_LINE);//设置图形类型line.setLineStyle(HSSFShape.LINESTYLE_SOLID);//设置图形样式line.setLineWidth(6350);//在POI中线的宽度12700表示1pt,所以这里是0.5pt粗的线条。
通常,利用POI画图主要有以下几个步骤:
\1. 创建一个Patriarch(注意,一个sheet中通常只创建一个Patriarch对象);
\2. 创建一个Anchor,以确定图形的位置;
\3. 调用Patriarch创建图形;
\4. 设置图形类型(直线,矩形,圆形等)及样式(颜色,粗细等)。
关于HSSFClientAnchor(dx1,dy1,dx2,dy2,col1,row1,col2,row2)的参数,有必要在这里说明一下:
dx1:起始单元格的x偏移量,如例子中的0表示直线起始位置距B1单元格左侧的距离;
dy1:起始单元格的y偏移量,如例子中的0表示直线起始位置距B1单元格上侧的距离;
dx2:终止单元格的x偏移量,如例子中的0表示直线起始位置距E5单元格左侧的距离;
dy2:终止单元格的y偏移量,如例子中的0表示直线起始位置距E5单元格上侧的距离;
col1:起始单元格列序号,从0开始计算;
row1:起始单元格行序号,从0开始计算,如例子中col1=1,row1=0就表示起始单元格为B1;
col2:终止单元格列序号,从0开始计算;
row2:终止单元格行序号,从0开始计算,如例子中col2=4,row2=4就表示起始单元格为E5;
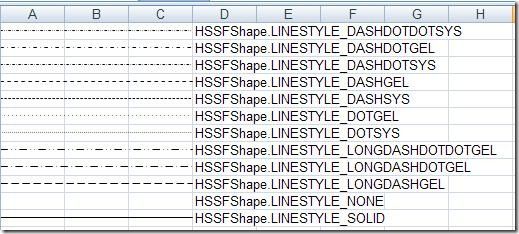
最后,关于LineStyle属性,有如下一些可选值,对应的效果分别如图所示:
(2)画矩形
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFPatriarch patriarch=sheet.createDrawingPatriarch();HSSFClientAnchor anchor = new HSSFClientAnchor(255,122,255, 122, (short)1, 0,(short)4, 3);HSSFSimpleShape rec = patriarch.createSimpleShape(anchor);rec.setShapeType(HSSFSimpleShape.OBJECT_TYPE_RECTANGLE);rec.setLineStyle(HSSFShape.LINESTYLE_DASHGEL);//设置边框样式rec.setFillColor(255, 0, 0);//设置填充色rec.setLineWidth(25400);//设置边框宽度rec.setLineStyleColor(0, 0, 255);//设置边框颜色

(3)画圆形
更改上例的代码如下:
rec.setShapeType(HSSFSimpleShape.OBJECT_TYPE_OVAL);//设置图片类型

(4)画Grid
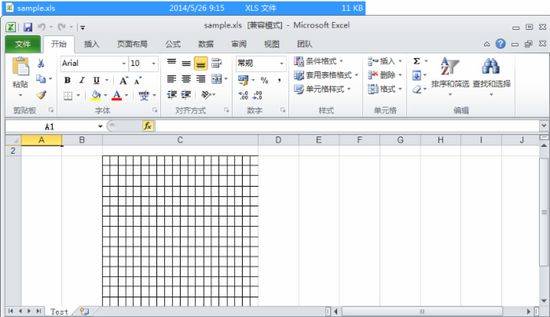
在POI中,本身没有画Grid(网格)的方法。但我们知道Grid其实就是由横线和竖线构成的,所在我们可以通过画线的方式来模拟画Grid。代码如下:
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)HSSFRow row = sheet.createRow(2);row.createCell(1);row.setHeightInPoints(240);sheet.setColumnWidth(2, 9000);int linesCount = 20;HSSFPatriarch patriarch = sheet.createDrawingPatriarch();//因为HSSFClientAnchor中dx只能在0-1023之间,dy只能在0-255之间,这里采用比例的方式double xRatio = 1023.0 / (linesCount * 10);double yRatio = 255.0 / (linesCount * 10);// 画竖线int x1 = 0;int y1 = 0;int x2 = 0;int y2 = 200;for (int i = 0; i < linesCount; i++){HSSFClientAnchor a2 = new HSSFClientAnchor();a2.setAnchor((short) 2, 2, (int) (x1 * xRatio),(int) (y1 * yRatio), (short) 2, 2, (int) (x2 * xRatio),(int) (y2 * yRatio));HSSFSimpleShape shape2 = patriarch.createSimpleShape(a2);shape2.setShapeType(HSSFSimpleShape.OBJECT_TYPE_LINE);x1 += 10;x2 += 10;}// 画横线x1 = 0;y1 = 0;x2 = 200;y2 = 0;for (int i = 0; i < linesCount; i++){HSSFClientAnchor a2 = new HSSFClientAnchor();a2.setAnchor((short) 2, 2, (int) (x1 * xRatio),(int) (y1 * yRatio), (short) 2, 2, (int) (x2 * xRatio),(int) (y2 * yRatio));HSSFSimpleShape shape2 = patriarch.createSimpleShape(a2);shape2.setShapeType(HSSFSimpleShape.OBJECT_TYPE_LINE);y1 += 10;y2 += 10;}
(5)插入图片
HSSFSheet sheet = workbook.createSheet("Test");// 创建工作表(Sheet)FileInputStream stream=newFileInputStream("d:\\POI\\Apache.gif");byte[] bytes=new byte[(int)stream.getChannel().size()];stream.read(bytes);//读取图片到二进制数组int pictureIdx = workbook.addPicture(bytes,HSSFWorkbook.PICTURE_TYPE_JPEG);HSSFPatriarch patriarch = sheet.createDrawingPatriarch();HSSFClientAnchor anchor = new HSSFClientAnchor(0, 0, 0, 0,(short)0, 0, (short)5, 5);HSSFPicture pict = patriarch.createPicture(anchor,pictureIdx);//pict.resize();//自动调节图片大小,图片位置信息可能丢失
(6)从Excel文件提取图片
InputStream inp = new FileInputStream(filePath);HSSFWorkbook workbook = new HSSFWorkbook(inp);//读取现有的Excel文件Listpictures = workbook.getAllPictures(); for(int i=0;i{HSSFPictureData pic=pictures.get(i);String ext = pic.suggestFileExtension();if (ext.equals("png"))//判断文件格式{FileOutputStream png=newFileOutputStream("d:\\POI\\Apache.png");png.write(pic.getData());png.close();//保存图片}}
6.Excel表操作
(1)设置默认工作表
HSSFWorkbook workbook = new HSSFWorkbook();// 创建Excel文件(Workbook)workbook.createSheet("Test0");// 创建工作表(Sheet)workbook.createSheet("Test1");// 创建工作表(Sheet)workbook.createSheet("Test2");// 创建工作表(Sheet)workbook.createSheet("Test3");// 创建工作表(Sheet)workbook.setActiveSheet(2);//设置默认工作表
(2)重命名工作表
HSSFWorkbook workbook = new HSSFWorkbook();// 创建Excel文件(Workbook)workbook.createSheet("Test0");// 创建工作表(Sheet)workbook.createSheet("Test1");// 创建工作表(Sheet)workbook.createSheet("Test2");// 创建工作表(Sheet)workbook.createSheet("Test3");// 创建工作表(Sheet)workbook.setSheetName(2, "1234");//重命名工作表
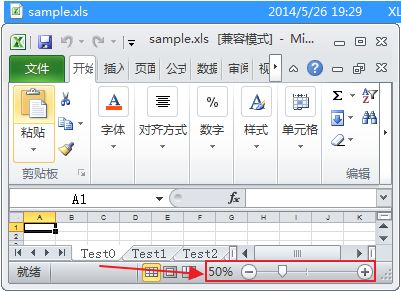
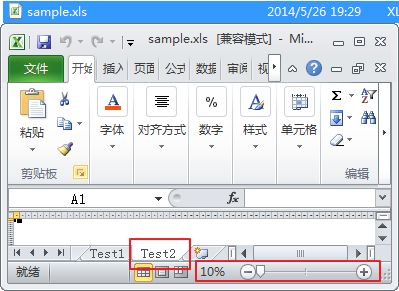
(3)调整表单显示比例
HSSFWorkbook workbook = new HSSFWorkbook();// 创建Excel文件(Workbook)HSSFSheet sheet1= workbook.createSheet("Test0");// 创建工作表(Sheet)HSSFSheet sheet2=workbook.createSheet("Test1");// 创建工作表(Sheet)HSSFSheet sheet3=workbook.createSheet("Test2");// 创建工作表(Sheet)sheet1.setZoom(1,2);//50%显示比例sheet2.setZoom(2,1);//200%显示比例sheet3.setZoom(1,10);//10%显示比例

(4)显示/隐藏网格线
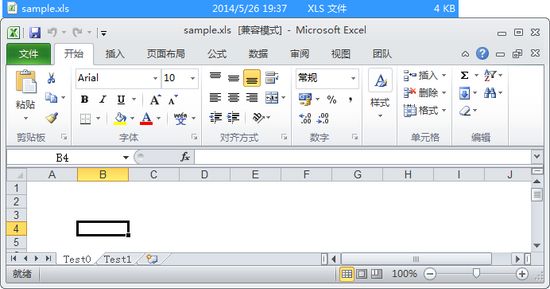
HSSFWorkbook workbook = new HSSFWorkbook();// 创建Excel文件(Workbook)HSSFSheet sheet1= workbook.createSheet("Test0");// 创建工作表(Sheet)HSSFSheet sheet2=workbook.createSheet("Test1");// 创建工作表(Sheet)sheet1.setDisplayGridlines(false);//隐藏Excel网格线,默认值为truesheet2.setGridsPrinted(true);//打印时显示网格线,默认值为false
(5)遍历Sheet
String filePath = "d:\\users\\lizw\\桌面\\POI\\sample.xls";FileInputStream stream = new FileInputStream(filePath);HSSFWorkbook workbook = new HSSFWorkbook(stream);//读取现有的ExcelHSSFSheet sheet= workbook.getSheet("Test0");//得到指定名称的Sheetfor (Row row : sheet){for (Cell cell : row){System.out.print(cell + "\t");}System.out.println();}


7.Excel行列操作
(1)组合行、列
HSSFSheet sheet= workbook.createSheet("Test0");// 创建工作表(Sheet)sheet.groupRow(1, 3);//组合行sheet.groupRow(2, 4);//组合行sheet.groupColumn(2, 7);//组合列

这里简单的介绍一下什么叫做组合:组合分为行组合和列组合,所谓行组合,就是让n行组合成一个集合,能够进行展开和合拢操作。
使用POI也可以取消组合,例如:sheet.ungroupColumn(1, 3);//取消列组合
(2)锁定列
在Excel中,有时可能会出现列数太多或是行数太多的情况,这时可以通过锁定列来冻结部分列,不随滚动条滑动,方便查看。
HSSFSheet sheet= workbook.createSheet("Test0");// 创建工作表(Sheet)sheet.createFreezePane(2, 3, 15, 25);//冻结行列

下面对CreateFreezePane的参数作一下说明:
第一个参数表示要冻结的列数;
第二个参数表示要冻结的行数,这里只冻结列所以为0;
第三个参数表示右边区域可见的首列序号,从1开始计算;
第四个参数表示下边区域可见的首行序号,也是从1开始计算,这里是冻结列,所以为0;
(3)上下移动行
FileInputStream stream = new FileInputStream(filePath);HSSFWorkbook workbook = new HSSFWorkbook(stream);HSSFSheet sheet = workbook.getSheet("Test0");sheet.shiftRows(2, 4, 2);//把第3行到第4行向下移动两行
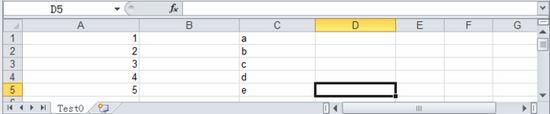
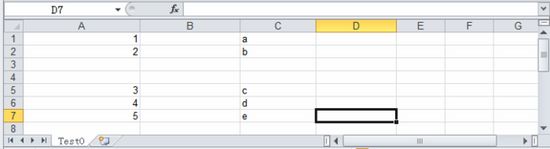
HSSFSheet.shiftRows(startRow, endRow, n)参数说明
startRow:需要移动的起始行;
endRow:需要移动的结束行;
n:移动的位置,正数表示向下移动,负数表示向上移动;
8.Excel的其他功能
(1)设置密码
HSSFSheet sheet= workbook.createSheet("Test0");// 创建工作表(Sheet)HSSFRow row=sheet.createRow(1);HSSFCell cell=row.createCell(1);cell.setCellValue("已锁定");HSSFCellStyle locked = workbook.createCellStyle();locked.setLocked(true);//设置锁定cell.setCellStyle(locked);cell=row.createCell(2);cell.setCellValue("未锁定");HSSFCellStyle unlocked = workbook.createCellStyle();unlocked.setLocked(false);//设置不锁定cell.setCellStyle(unlocked);sheet.protectSheet("password");//设置保护密码

(2)数据有效性
HSSFSheet sheet= workbook.createSheet("Test0");// 创建工作表(Sheet)HSSFRow row=sheet.createRow(0);HSSFCell cell=row.createCell(0);cell.setCellValue("日期列");CellRangeAddressList regions = new CellRangeAddressList(1, 65535,0, 0);//选定一个区域DVConstraint constraint = DVConstraint.createDateConstraint(DVConstraint . OperatorType . BETWEEN , “1993-01-01” ,“2014-12-31” , “yyyy-MM-dd” );HSSFDataValidation dataValidate = new HSSFDataValidation(regions,constraint);dataValidate.createErrorBox("错误", "你必须输入一个时间!");sheet.addValidationData(dataValidate);
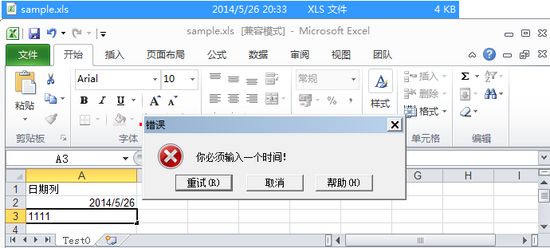
CellRangeAddressList类表示一个区域,构造函数中的四个参数分别表示起始行序号,终止行序号,起始列序号,终止列序号。65535是一个Sheet的最大行数。另外,CreateDateConstraint的第一个参数除了设置成DVConstraint.OperatorType.BETWEEN外,还可以设置成如下一些值,大家可以自己一个个去试看看效果:
验证的数据类型也有几种选择,如下:

(3)生成下拉式菜单
CellRangeAddressList regions = new CellRangeAddressList(0, 65535,0, 0);DVConstraint constraint =DVConstraint.createExplicitListConstraint(new String[] { "C++","Java", "C#" });HSSFDataValidation dataValidate = new HSSFDataValidation(regions,constraint);sheet.addValidationData(dataValidate);
(4)打印基本设置
HSSFSheet sheet= workbook.createSheet("Test0");// 创建工作表(Sheet)HSSFPrintSetup print = sheet.getPrintSetup();//得到打印对象print.setLandscape(false);//true,则表示页面方向为横向;否则为纵向print.setScale((short)80);//缩放比例80%(设置为0-100之间的值)print.setFitWidth((short)2);//设置页宽print.setFitHeight((short)4);//设置页高print.setPaperSize(HSSFPrintSetup.A4_PAPERSIZE);//纸张设置print.setUsePage(true);//设置打印起始页码不使用"自动"print.setPageStart((short)6);//设置打印起始页码sheet.setPrintGridlines(true);//设置打印网格线print.setNoColor(true);//值为true时,表示单色打印print.setDraft(true);//值为true时,表示用草稿品质打印print.setLeftToRight(true);//true表示“先行后列”;false表示“先列后行”print.setNotes(true);//设置打印批注sheet.setAutobreaks(false);//Sheet页自适应页面大小
更详细的打印设置请参考: http://tonyqus.sinaapp.com/archives/271
(5)超链接
HSSFSheet sheet = workbook.createSheet("Test0");CreationHelper createHelper = workbook.getCreationHelper();// 关联到网站Hyperlink link =createHelper.createHyperlink(Hyperlink.LINK_URL);link.setAddress("http://poi.apache.org/");sheet.createRow(0).createCell(0).setHyperlink(link);// 关联到当前目录的文件link = createHelper.createHyperlink(Hyperlink.LINK_FILE);link.setAddress("sample.xls");sheet.createRow(0).createCell(1).setHyperlink(link);// e-mail 关联link = createHelper.createHyperlink(Hyperlink.LINK_EMAIL);link.setAddress("mailto:[email protected]?subject=Hyperlinks");sheet.createRow(0).createCell(2).setHyperlink(link);//关联到工作簿中的位置link = createHelper.createHyperlink(Hyperlink.LINK_DOCUMENT);link.setAddress("'Test0'!C3");//Sheet名为Test0的C3位置sheet.createRow(0).createCell(3).setHyperlink(link);

9.POI对Word的基本操作
(1)POI操作Word简介
POI读写Excel功能强大、操作简单。但是POI操作时,一般只用它读取word文档,POI只能能够创建简单的word文档,相对而言POI操作时的功能太少。
(2)POI创建Word文档的简单示例
XWPFDocument doc = new XWPFDocument();// 创建Word文件 XWPFParagraph p = doc.createParagraph();// 新建一个段落 p.setAlignment(ParagraphAlignment.CENTER);// 设置段落的对齐方式 p.setBorderBottom(Borders.DOUBLE);//设置下边框 p.setBorderTop(Borders.DOUBLE);//设置上边框 p.setBorderRight(Borders.DOUBLE);//设置右边框 p.setBorderLeft(Borders.DOUBLE);//设置左边框 XWPFRun r = p.createRun();//创建段落文本 r.setText("POI创建的Word段落文本"); r.setBold(true);//设置为粗体 r.setColor("FF0000");//设置颜色 p = doc.createParagraph();// 新建一个段落 r = p.createRun(); r.setText("POI读写Excel功能强大、操作简单。"); XWPFTable table= doc.createTable(3, 3);//创建一个表格 table.getRow(0).getCell(0).setText("表格1"); table.getRow(1).getCell(1).setText("表格2"); table.getRow(2).getCell(2).setText("表格3"); FileOutputStream out = newFileOutputStream("d:\\POI\\sample.doc"); doc.write(out); out.close();

(3)POI读取Word文档里的文字
FileInputStream stream = newFileInputStream("d:\\POI\\sample.doc");XWPFDocument doc = new XWPFDocument(stream);// 创建Word文件 for(XWPFParagraph p :doc.getParagraphs()) { System.out.print(p.getParagraphText());} for(XWPFTable table :doc.getTables()) { for (XWPFTableRow row : table.getRows()) { for (XWPFTableCell cell : row.getTableCells()) { System.out.print(cell.getText()); } }}
