基于多核处理器的RTOS多核扩展分析与研究
本文是我写得一篇关于RTOS SMP扩展的硕士论文,希望对有志于了解RTOS-SMP工作机制的兄弟们提供些许帮助,O(∩_∩)O~。
一直以来人们通过提高主频来提升微处理器的性能,但是高功耗制约着主频的进一步提升,这种矛盾在仅依靠电池供电的嵌入式设备上表现的尤为突出。多核处理器将多个较低主频的处理核心集成到一个芯片内部,通过提高IPC(Instruction Per Clock)来提升处理器性能。多核处理器构架在提升性能的同时又降低了功耗,显然是嵌入式设备上处理器的理想选择。在这样的背景下,支持多核处理器的RTOS(Real Time Operating System)成为当前研究的热点,尤其是支持SMP(Symmetric Multi-Processing)的RTOS因具有较高的性能和功耗比、容易实现负载均衡等优点,更能发挥多核并行处理的优势。因此本文以单核RTOS的SMP扩展为研究重点,为单核RTOS扩展成为支持SMP模式提出一套可行性的解决方案。
本文选择uC/OS-II为实验对象,在深入研究uC/OS-II任务调度、中断处理、任务间同步与通信机制的基础上,将其扩展成支持SMP的原型系统。在系统初始化方面,采用主CPU负责初始化系统、启动次CPU,次CPU享受主CPU的初始化成果;对于CPU间的互斥和通信,提出了基于FCFS(First Come First Serve)的Ticket内核锁机制,有效解决了CPU饥饿和Cache频繁刷新问题;同时设计并实现了核间中断接口用于CPU间的通信;在多核同步方面,本文设计了原子操作、内存屏障、自旋锁,提出了对uC/OS-II全局资源进行SMP扩展的原则,以便对互斥信号量、邮箱、消息队列等任务间同步与通信模块进行SMP扩展;在中断处理方面本文采用基于Ticket内核锁的中断动态分配算法;在任务调度方面,本文在uC/OS-II位图算法的基础上提出了基于全局队列的任务调度算法,有效实现了负载均衡,保证了系统的实时性和可预测性。
文章最后在MPC8641D双核处理器平台对原型系统进行了测试,并对测试结果进行了定性和定量分析,验证了SMP扩展方案的可行性。
第一章 序言
1.1 术语解释
CPU和处理器(Processor)在一般的计算机技术文档中是同义词,但是在SMP硬件平台上对两者进行区分有助于准确描述问题,同时我们还定义了其它几个术语。
CPU:特指一个硅处理单元,该单元可以执行程序指令和处理数据,和多核(Multi-Core)中的核(Core)是同义词,本文对Core和CPU不加区分;
处理器(Processor):指一个物理硅片,里面可能会包含一个或者多个CPU;
多处理器(Multiprocessor):指的是一个硬件系统,其中可以包含有多个处理器(Processor);
单核处理器(Uniprocessor):指的是一个物理硅片,该硅片中仅仅含有一个CPU;
SMP硬件平台:指的是包含SMP处理器的硬件系统,SMP处理器可以是一个对称多核处理器,也可以是多个对等的单核处理器构成。CPU之间、或者单核处理器之间的地位平等,即它们平等的访问内存和外设资源,硬件系统的内存结构必须是UMA(一致内存访问)体系结构。在嵌入式业内多核处理器更多的是指对称多核处理器。
举个例子,本文使用的SBC8641D开发板是一个SMP硬件平台,该平台使用的双核处理器MPC8641D是一个多核处理器(Multicore Processor),在该处理器中集成了两个CPU(即Core)。
1.2 论文研究背景
随着应用需求的扩展和软件技术的进步,人们对处理器性能的要求越来越高,仅仅依靠提高CPU主频来提升处理器性能的方式受到随之而来的高功耗的制约,“摩尔定律”难以继续维持。因此,多核处理器构架开始成为一条全新的解决方案。多核处理器构架[1]是指将两个以上(包括两个)的较低主频的CPU封装在一个芯片的内部,通过提高IPC(Instruction Per Clock)来达到在比较低的功耗下获得更高处理性能的目的,因此受到人们越来越多的关注。学术界对多核处理器构架进行深入研究始于20世纪90年代中后期,在此期间提出了大量的设想,其中最著名的是斯坦福大学提出的单片多处理器构架CMP(Chip Multi-Processor)[2]。随着微处理器技术的迅猛发展,多核处理器构架逐步成为通用处理器的主流,从IBM于2001年发布第一款通用双核处理器Power4以来,通用处理器开始进入多核时代,并陆续在桌面计算、服务器计算和高性能计算等领域得到全面应用和普及。
虽然多核处理器目前已经成为桌面PC电脑处理器的主流,但在嵌入式领域却刚刚起步。随着移动互联网的发展,多核处理器芯片逐步渗入到嵌入式领域,从2011年开始在移动终端领域得到了迅猛发展,但是和通用桌面多核处理器一样,如果没有操作系统的配合,多核处理器芯片并不能发挥相对于单核处理器多核并行处理的优势。正因为如此,如何对传统单核RTOS进行多核扩展、甚至重新设计出支持多核处理器的RTOS,使其能够发挥多核并行处理的优势成为当前多核RTOS研究的热点。
目前在嵌入式领域支持多核处理器芯片的操作系统体系结构有两种:
一是AMP(Asymmetric Multi-processing)模式:AMP模式的RTOS在各个CPU上均运行一个操作系统实例(这些操作实例不一定完全相同),各个操作系统拥有自己专用的内存,相互之间通过访问受限的共享内存进行通信。AMP模式的操作系统结构需要用户参与系统资源的分配。这种类型的RTOS应用比较少,商用操作系统中仅有Wind River公司的VxWorks 提供AMP模式的配置。
二是SMP(Symmetric Multi-processing)模式:SMP模式的操作系统构架是多核处理器技术的一种变体,由一个操作系统实例控制所有处理器,所有处理器共享内存。与AMP模式中每个CPU上运行一个操作系统实例不同,SMP模式系统中所有CPU的地位相同,共同运行一个操作系统实例,所有CPU共享系统内存和外设资源。相对于AMP模式,SMP模式的操作系统具有可共享内存、较高的性能和功耗比、以及易实现负载均衡等优点,更能发挥发挥多核处理器的硬件优势[3]。
本文着重研究将单核RTOS扩展为SMP模式的操作系统所面临的技术难题,提出相应的解决方案,在尽可能不改变原有系统结构、以及不降低原有系统性能的前提下完成SMP扩展。之所以选择对单核RTOS进行SMP扩展,一方面是因为重新设计支持SMP的RTOS工作量太大,而直接在单核版本上进行SMP扩展,可以利用单核RTOS现有的技术成果;另一方面,不管是对单核RTOS进行SMP扩展,还是重新设计一款支持SMP的RTOS,都必须解决系统引导、任务间同步与互斥、任务调度、中断处理等方面的SMP扩展问题,解决了这些问题也就解决了设计SMP模式的RTOS面临的核心难题。
1.3 国内外研究现状
多核处理器只有在软件能够充分利用多核并行处理的特性时,其相对于传统单核处理器的优势才会体现出来。在桌面系统业界,主流的操作系统厂商相继推出了支持SMP模式的操作系统,例如微软的Windows、Redhat公司的Redhat Enterprise Linux发行版、Sun微系统公司的Solaris等等。但是在嵌入式RTOS业内,支持SMP模式的操作系统发展相对缓慢,目前主要有WindRiver公司(该公司已经被Intel收购)的VxWorks-6.6及后续版本,QNX软件有限公司的Neutrino、以及由Linux-2.4内核演化而来的MontaVista Linux等少数的操作系统。
随着SMP硬件平台的发展,如何让RTOS更好得支持SMP来充分发挥多核处理器的硬件特性成为当前的研究热点。在Cache利用率方面文献[4]提出支持SMP模式的操作系统如果能充分考虑Cache热度,通过计算任务的共享程度,将共享程度高的任务放在同一个CPU上运行,共享程度低的任务放在不同的CPU上运行,对提高系统的性能、降低系统功耗起着非常显著的作用;文献[5]提出二级Cache不命中比一级Cache不命中对操作系统性能的影响更大,同时指出操作系统可以通过改进调度算法来减少对二级Cache的访问;文献[6]指出为了减少线程对二级Cache的访问,可以将可能引起二级Cache访问的任务放在一个线程组中,使用合理的调度策略使得这个组中的任务不会并行执行;为了增加Cache访问的可预测性,文献[7]提出通过锁和分区机制来对共享Cache进行保护。
为了更好的支持SMP硬件平台,WindRiver公司从VxWorks6.6版本开始引入对SMP的支持,但是它的支持是粗粒度的,即用一个大内核锁来保护VxWorks的内核态,每次只有一个CPU能够进入内核态。如果单从调度模块设计来看,VxWorks6.6及其后继版本对SMP的支持水平仅相当与Linux-2.2内核SMP的支持水平,特别需要指出的是Linux内核在通用计算机平台对SMP模式的支持技术目前是比较成熟的。
2006年美国嵌入式操作系统开发联盟的James.Aderson提出了基于锁中断的中断分配算法,有效解决了多核实时操作系统在多个CPU间分配中断的问题,对多核RTOS自旋锁的研究与设计起到极大的推动作用[8]。
2010年,多核应用协会提出了多核编程接口标准MCAPI V1.0(Multicore Resource API Specification),为多核操作系统设计、应用程序的开发及移植也起到极大的推动作用[9]。
和国外的研究相比,国内在支持SMP模式的操作系统研究方面起步较晚,一直处于跟踪研究状态,但随着近年来国内专家对多核技术的重视,仍取得了不少成果。文献[10]针对SMP硬件平台上的静态任务调度问题提出了新的调度模型和调度算法,在提高调度器性能的同时又降低了算法时间复杂度。文献[11]对支持多核处理器的启发式任务调度算法进行了深入研究,提出了一种包含两轮操作的任务调度算法,优化了任务分派到CPU的策略,在一定程度上降低了算法的复杂度。然而上述文献研究的更多是通用操作系统对多核处理器的支持,并不是针对嵌入式多核RTOS,因而支持多核硬件平台RTOS的实时性和可预测性并不能得到保证。文献[12]提出了对实时操作系统RTEMS进行SMP扩展的完整解决方案,文献[13]深入研究了SMP硬件平台的多核调度算法,可以说是目前对单核RTOS进行SMP扩展研究的最新成果。
1.4 本文主要工作
对任何一款单核RTOS进行SMP扩展,都必须要解决三个主要问题:系统完整性(System Integrity)、性能(Performance)和外部编程模型(External Programming Model)[14]。系统的完整性意味着如何正确协调CPU间的并行活动,来避免破坏内核数据结构;在保证系统完整性的前提下尽可能地提高系统性能也是SMP扩展必须要考虑的情况;外部编程模型决定了对应用程序的影响,如果系统调用接口与原系统不一致,那么许多为原系统编写的应用程序就必须修改,有时候修改的代价是巨大的。所以对RTOS的SMP扩展一般都会选择保持原有API(Application Interface)接口不变。另外RTOS的实时性和可预测性在进行SMP扩展时必须得到保证。
本文深入研究单核RTOS进行SMP扩展面临的技术难题,并给出相应的解决方案,在对RTOS进行SMP扩展的过程中本文做了以下方面的工作。
在系统初始化方面,我们将CPU分为主CPU和次CPU,由主CPU负责系统的初始化并启动次CPU,次CPU享受主CPU的初始化成果;
在CPU同步方面,我们提出了原子操作、自旋锁、内存屏障来实现数据的可重入,同时设计了具有FCFS(First Come First Serve)功能的内核锁,有效解决了因自旋锁频繁涮洗Cache造成的系统性能损失、以及CPU饥饿问题;
在系统调度模块设计方面,我们采用基于优先级的全局队列调度算法,实现了CPU间的负载均衡、以及算法时间复杂度与系统负载无关;
在系统出错调试方面,我们设计了异常处理模块来输出系统产生异常时的栈帧和CPU寄存器值,方便内核开发者解决设计缺陷;
在系统中断处理方面,我们提出了基于内核锁的中断动态分配算法;
对于通用模块,比如任务间同步和通信模块,我们提出了完整的的SMP扩展原则。
1.5 本文结构布局
本文分为六章,各章组织如下:
第1章为绪论部分,主要介绍了本文的研究背景、多核处理器构架的发展历程、以及国内外研究现状;
第2章为对称多处理器技术综述,介绍了与本文研究相关的技术背景,包括SMP构架的基本特征和关键技术,讨论了支持SMP和AMP两种模式的操作系统异同,着重分析Linux内核支持SMP的机制,为单核RTOS的SMP扩展提供借鉴。
第3章为uC/OS-II内核分析,深入研究了uC/OS-II核心机制,为对其进行SMP扩展做准备;
第4章为RTOS的SMP扩展设计与实现,深入分析uC/OS-II内核在SMP扩展时所面临的技术难题,分别给出相应的解决方案;
第5章为实验验证,在MPC8641D硬件平台上对SMP原型系统做功能性测试,并与uC/OS-II单核系统做性能对比测试、验证SMP扩展方案的可行性;
第6章为结束语,对论文进行总结,对进一步的研究工作做论述和展望。
2.1 对称多处理器构架
摩尔定律指出芯片集成度每隔18至24个月翻一翻。从Intel第一块真正意义上的微处理器4004直到2000年左右,处理器生产厂商一直通过提高时钟频率来提升处理器性能,摩尔定律在过去的近30年中展现出惊人的准确性。然而主频的提高导致处理器功耗和发热量急剧增加,反过来制约了处理器性能的进一步提升。于是人们开始把研究重点转向将多个处理核心集成到单个芯片内部,通过将任务放在不同处理器核心上并行执行来达到提高处理器性能的目的,这就是多核硬件平台。
SMP硬件平台指的是包含SMP处理器的硬件系统,SMP处理器可以是一个对称多核处理器,也可以是多个对等的单核处理器构成。CPU之间、或者单核处理器之间的地位相同,即它们平等的访问内存和外设资源,并且系统内存结构是一致内存访问(UMA)体系结构。双核SMP的典型硬件结构如图2-1。
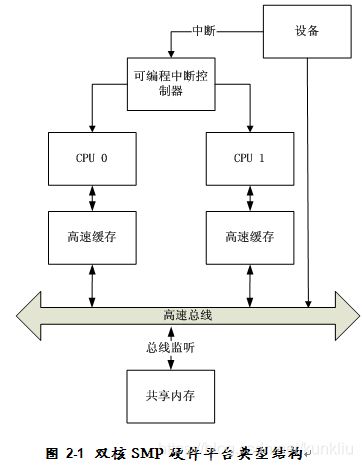
SMP模式的操作系统同时使用多个CPU,但从应用程序的角度来看,它们在逻辑上表现为一个单处理器。操作系统负责将任务分配到各个CPU上运行,从而极大地提高了整个系统的数据处理能力,并且所有CPU都可以平等地访问内存和外设资源,由操作系统负责将任务均匀地分配到所有可用CPU上运行。本文的实验平台所用的处理器MPC8641D[15]就是一种集成了两个E600[16]内核的典型SMP硬件结构,如图2-2所示。

2.2 SMP与AMP体系
目前支持多核处理器平台的实时操作系统体系结构有对称多处理SMP(Symmetric Multi-Processing)构架和非对称多处理AMP(Asymmetric Multi-Processing)构架两种。这两种操作系统的结构、代码和数据区的分配方面差别很大。SMP构架的系统中所有CPU共享系统内存和外设资源,由操作系统负责处理器间协作,并保持数据结构的一致性,而在AMP构架的系统中,用户需要对各个操作系统使用的硬件资源进行划分,CPU间的合作仅限于使用共享存储器的情况。由于CPU间的合作程度不同,AMP则称为松散耦合多CPU系统(图2-4所示),SMP系统称为紧耦合多CPU系统(图2-3所示)。

图2-3所示的SMP模式操作系统负责协调两个处理器核之间的工作,两个处理器核共享主存中同一个操作系统实例。虽然在每个核中应用程序的地址相同,但是通过MMU把它们映射到主存中不同的位置,从而实现了两个应用程序间代码和数据空间的隔离。

图2-4所示的是典型的AMP系统结构,每个CPU上运行一个操作系统实例,各个操作系统都有自己独占的资源(最基本的是独占各自专用的CPU),其它资源或者由两个系统共享、或者分配给各个系统专用。资源的分配由用户来决定,因而对用户是可见的。在商用实时操作系统当中只有WindRiver公司的VxWorks提供了AMP模式的支持,目前该模式的应用较少。
2.3 Linux-SMP实现机制
从Linux-2.0内核版本开始引入对SMP的支持开始,在全球Linux内核开发者的共同协作下,Linux对SMP的支持逐渐完善。特别是从Linux-2.4版本开始,对SMP的支持在内核态实现,真正实现了多CPU并行执行。目前Linux内核版本已经更新到linux-3.xx系列,但Linux-2.4和Linux-2.6系列版本对SMP的支持是革命性的,这两个版本的SMP系统发展历程,对实时操作系统的SMP研究具有极大的借鉴意义。因此我们着重从Linux-2.4内核以及linux-2.6内核对SMP支持的角度出发,对Linux支持SMP的关键技术进行分析。
2.3.1 Linux-SMP初始化
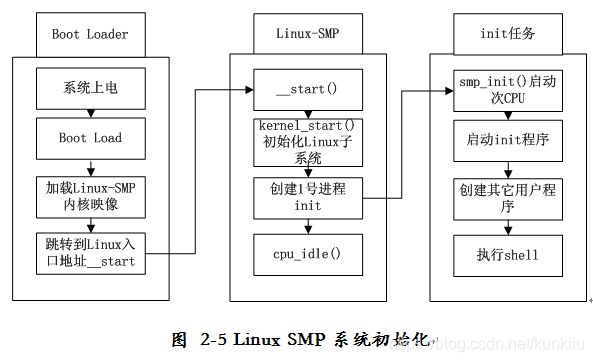
操作系统的初始化是操作系统获得CPU控制权的第一步,也是Linux支持SMP的关键部分。虽然在SMP系统中所有CPU的地位平等,但是由于在系统初始化的过程中只有一个“可执行上下文”,所以只能有一个CPU负责系统初始化。我们把该CPU称为引导CPU(Bootstrap CPU),也称之为主CPU,其它的CPU称为应用CPU,也称之为次CPU。支持SMP的Linux内核的初始化过程分三个步骤:
- (1) Boot Loader首先对目标板系统做基本的初始化,搜集这个目标板的基本信息,比如内存大小、处理器主频、外设的使用情况等等。接着把这些信息传递给linux内核。最后Boot loader把linux内核复制到从0x0000 0000 开始的物理内存处(虚拟地址一般为0xc000 0000处)开始执行。
- (2) Boot Loader将CPU的PC指针指向Linux-SMP内核映像的__start()入口处,由Linux-SMP内核映像来对目标板再次初始化(引导程序已经对系统做了一次初始化),这一部分分成两小步:
第一小步:对CPU内部寄存器初始化,严格的说也分成两步:
- 1)当MMU地址映射没有开启时,需要通过显式地进行链接地址到物理地址的转换来初始化处理器的Cache、TLB以及通用寄存器;
- 2)开启临时的MMU地址映射,构造0号init_task任务的执行上下文,启动init_task任务继续完成初始化部分,init_task是Linux内核中唯一一个没有用kernel_thread() 函数创建的任务,在init_task任务执行后期,它会调用kernel_thread()函数创建第一个核心任务kernel_init(即我们常说的1号进程),而init_task任务则最终退化成主CPU上的idle任务。
第二小步:1号进程kernel_init任务会接着完成应用程序的初始化,并启动系统中所有应用CPU。
- (3) 1号kernel_init进程完成linux的各项配置(包括启动次CPU)后,会在/sbin,/etc,/bin目录中寻找init程序来运行。该init程序会替换kernel_init任务,此时内核态的1号kernel_init任务将会转换为用户空间内的1号init任务。最终init任务执行/bin/sh产生shell界面提供给用户与系统交互。
整个初始化过程如图2-5所示。
2.3.2 Linux-SMP任务调度
Linux-2.4内核调度模块最主要的特征是内核不可抢占,即任务在内核态运行时,除非其主动放弃CPU,否则不能被任意挂起或者抢占。如果在内核态运行的任务出现死循环并且不主动让出CPU,那么系统就会失去响应。尽管这时候Linux内核仍在响应各种中断,其中包括时钟中断,却不会发生任务调度,其它任务没有机会得到运行。
Linux内核中schedule()负责任务调度,它按照不同的调度策略对实时任务和非实时任务进行不同的调度,从中选择权值最大的任务投入运行。如果全局就绪队列中的所有任务时间片耗尽,schedule()会给所有任务重新分配时间片。
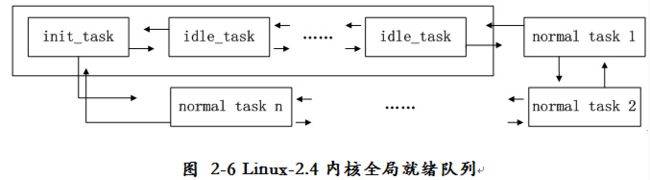
Linux内核用task_struct结构体代表各个任务,将所有任务链接到以初始任务init_task为表头的全局双向链表中。Linux内核为每个CPU绑定一个idle任务,代表idle任务的task_struct类型指针放在init_tasks[NR_CPUS]数组中,schedule()通过idle_task(cpu)宏来访问这些idle任务。由于所有CPU共享一个全局就绪队列(如图2-6所示),因此需要一把全局锁机制来保证CPU互斥访问,这导致SMP系统中当某个CPU操作就绪队列时会阻止其它CPU同时操作这个队列,只有等到该CPU释放就绪队列锁后,其它CPU才能访问。这种全局调度队列机制显然会造成系统效率的下降,这也是采用全局队列不可避免的副作用,但是全局队列具有负载均衡的优势,所以我们在后面SMP扩展中所采用的就是全局就绪队列,后面会进一步的讨论。
在单核处理器的操作系统中每个时刻只能有一个任务在运行,其它就绪任务都在等待CPU,操作系统通过中断机制(主要是时钟中断)进行频繁的任务切换,使得在一段时间间隔内所有任务都有机会运行,从而使得给用户宏观上的感觉好像每个任务都有一个CPU,所有任务在“并行运行”一样。但是这只是一种“并行运行”的幻象,微观上每个时刻只有一个任务在运行(毕竟只有一个CPU)。而在SMP系统中多个任务可以分配到不同的CPU上并行执行。只要各个CPU上运行的任务得到有效配合,SMP系统性能的提升是显而易见的。
为了支持SMP,在Linux内核的task_struct结构体中增加了两个字段,has_cpu和processor,当has_cpu为1时表示任务正在编号为processor的CPU上运行。一个任务只有has_cpu为0才能被调度运行,宏can_schedule()来判断当前CPU是否可以接受调度,其代码如下:
#define can_schedule(p,cpu) ((!(p)->has_cpu) && \
((p)->cpus_allowed & (1 << cpu)))
相比与Linux-2.4内核,Linux-2.6内核做了以下改进,能够更好地发挥多核处理器的性能。
- Linux-2.6内核中各个CPU拥有私有就绪队列,也称为Per-CPU队列,使得同一时刻多个CPU可以同时访问各自私有的队列进行任务调度,由Linux内核负责监控CPU的负载情况进行负载平衡[17]。但由于负载平衡执行时间的不确定,在一定程度上影响了Linux内核的实时性和可预测性。这也是目前所有支持SMP模式的RTOS没有采用私有队列进行任务调度的根本原因。
- Linux-2.6内核采用了时间复杂度为0(1)的调度算法,提高了内核的实时性,同时新的调度算法在高负载的情况下性能也非常优秀[18],由于采用了调度类的设计思想,调度模块很容易扩展[19]。
- Linux-2.6内核采用位图机制来辅助查找运行队列中优先级最高的任务(这也是所有RTOS调度模块采用的通用技术),Linux-2.6内核在5个32位存储字拼成的优先级位图队列中查找优先级最高的那一位,查找时间仅依赖于优先级的数量(目前仅使用前140位,来代表140个优先级),各个CPU上的调度队列如图2-7所示。

2.3.3 Linux-SMP锁机制
2.3.3.1 自旋锁
Linux-SMP使用自旋锁来实现CPU间的同步与互斥,自旋锁(spinlock)采用忙等的锁机制,它不同于信号量等其它锁机制,CPU在获取自旋锁的过程中,会一直测试锁的状态直到其可用为止,自旋锁在锁不可用时是不会主动放弃CPU的,因此自旋锁只用于多核平台。Linux-2.4内核中其实现的代码如下:
void arch_spin_lock(arch_spinlock_t *lock)
{
mb();//内存屏障
while (1) {
if (__arch_spin_trylock(lock) == 0)
break;
do {
mb();//内存屏障
} while(lock->slock != 0);
}
}
void arch_spin_unlock(arch_spinlock_t *lock)
{
mb();//内存屏障
lock->slock = 0;
}
#define spin_lock_irqsave(lock, flags) do{local_irq_save(flags); \ arch_spin_lock(lock); }while(0)
#define spin_unlock_irqrestore(lock, flags) do{arch_spin_unlock(lock);local_irq_restore(flags);}while(0)
其中__arch_spin_trylock(lock)函数是一个原子操作,它测试lock是否被上锁,如果未上锁则返回原值0,然后把lock置为1;如果已上锁,则返回1。
arch_spin_lock()/arch_spin_unlock自旋锁并没有关中断功能,只有中断处理程序从不访问该自旋锁保护的临界区时才会起作用。为了增加通用性,Linux-2.4内核在自旋锁的基础上使用中断锁(通过local_irq_save(flags)/ local_irq_restore(flags)实现),使得改进之后的自旋锁不但可以实现CPU间的互斥,还可以实现当前CPU上任务与中断ISR之间的互斥,需要注意的是关中断操作要放在申请自旋锁之前,开中断操作要放在释放自旋锁之后,否则会出现死锁。
2.3.3.2 读/写锁
Linux内核中引入读/写锁是为了增加内核的并行执行能力。如果没有内核控制路径(即Linux内核处理系统调用、异常或者中断所执行的指令序列)对数据结构进行修改,读/写锁会允许多个内核控制路径同时读取同一个数据结构。如果一个内核控制路径需要对该结构数据结构进行修改,那么它必须获得读/写锁中的写锁,写锁使得该控制路径独占这个资源。读写锁在Linux内核中应用广泛,但这种锁使用原子操作指令实现,因此需要原子地访问内存,获得锁的开销与访问内存的速度相关。
2.3.3.3 互斥锁
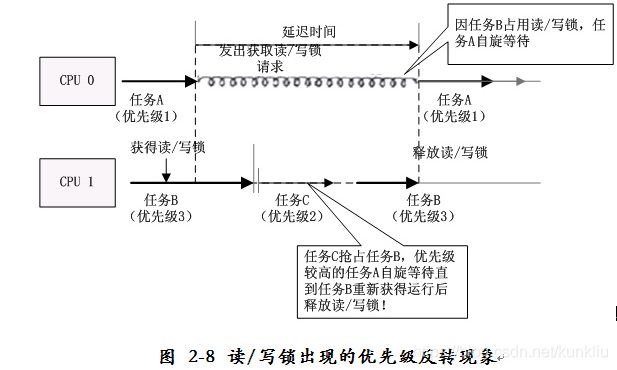
Linux-2.4内核采用读/写锁来实现对临界资源的保护,但由于读/写锁没有优先级继承功能,会发生优先级反转现象。比如有三个优先级依次降低的任务A、C、B,CPU 1上的B获取读/写锁来访问临界区,接着CPU 0上的A也发出了访问该临界区的请求,但是该临近区的读/写锁已经被B占用,A只能在CPU 0上自旋等待B释放读/写锁。这时优先级比B高的C就绪,C抢占B的CPU 1获得运行,此时CPU 1上执行比A优先级低的任务C,任务A只能在CPU 0上自旋等待更长的时间,直到B重新获得运行释放读/写锁为止。上述现象导致了C的优先级比A低却先完成,而优先级更高的A却得不到响应,降低了任务A的响应时间,如图2-8所示。
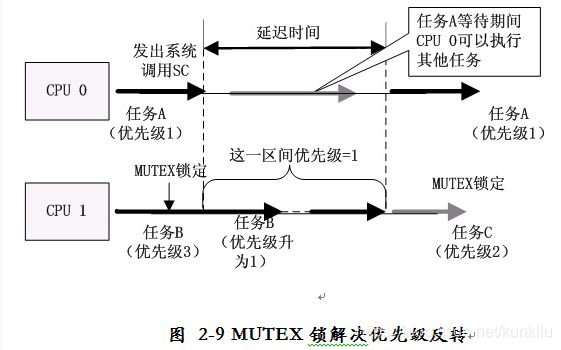
为了解决使用读/写锁带来的优先级翻转的问题,MontaVista Linux提出了具有优先级继承功能的MUTEX锁,从根本上解决了优先级翻转问题。还是上面的例子,任务B获得MUTEX锁后正访问临界区,优先级较高的任务A想要访问该临界区时, MUTEX就会把任务B提升至与任务A相同的优先级,避免了因任务C抢占B而降低A的响应时间,并且在A被挂起的这段时间,CPU 0可以运行其它任务,提高了内核的运行效率,如图2-9所示。
2.3.4 中断机制
传统i386处理器通过使用8259A中断控制器来提供外部中断源与CPU之间连接。为了充分发挥SMP系统中多核并行处理特性,Intel从Pentium III开始引入APIC(Advanced Programmable Interrupt Controller)[20]高级可编程中断控制器,来替换8259A中断控制器。新近的主板为了支持老的操作系统都包含8259A和APIC两种芯片,Intel当前所有的处理器都含有一个本地LAPIC(Local APIC),LAPIC包含多个32位的寄存器、一个内部时钟、一个本地定时设备、以及为本地APIC中断保留的两条额外的IRQ线LINE0和LINE1。所有本地APIC都连接到一个外部I/O APIC上形成了一个中断分发网络[21],如图2-10所示。

本地LAPIC位于CPU内部,而I/O APIC位于所有CPU外部,确切的说是位于南桥上,这样由一个I/O APIC和多个本地LAPIC组成了一个中断分发网络。I/O APIC根据其内部的PRT(Programmable Redirection Table)表格式化出一条中断消息,然后将其发送给某个CPU上的LAPIC,由LAPIC 通知CPU 进行处理。目前典型的I/O APIC具有24个中断管脚,每个管脚对应一个RTE(Redirection Table Entry)表项,连接在各个管脚上的设备是平等的。但这并不意味着APIC系统没有硬件优先级,APIC将优先级控制功能放到了LAPIC中。当I/O APIC某个管脚接收到中断信号后,会根据该管脚对应的RTE格式化出一条中断消息,将其发送给某个(或多个)CPU 上的LAPIC,收到来自I/O APIC的中断消息后,LAPIC 会将该中断交由CPU 处理[21]。
2.4 本章小结
本章介绍了嵌入式SMP硬件平台的背景和关键技术,以及支持SMP模式的RTOS研究现状,为单核RTOS的SMP扩展提供借鉴。
待续。。。。。。