剑指offer刷题记录--树
1. JZ55 二叉树的深度
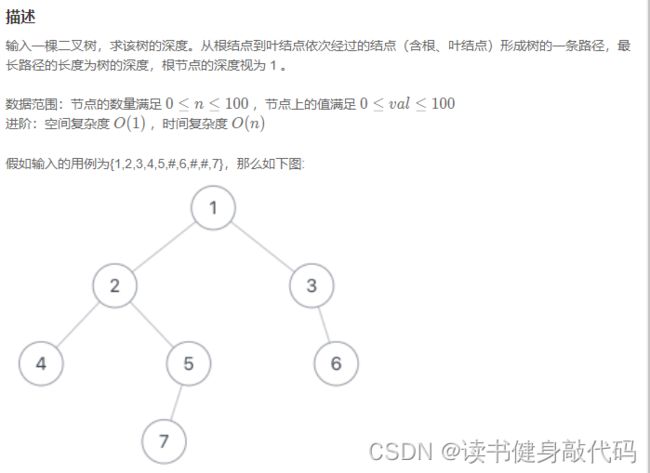
1. 递归(后序遍历,,无法用栈)
使用递归方法对每个结点进行递归,直到找到叶子节点,层层返回,每一层+1,最终即得树的深度。
(这个遍历方式是后序遍历)
动图
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
//使用链表来存储二叉树
class Solution {
public:
int TreeDepth(TreeNode* pRoot) {
if(pRoot==nullptr)
return 0;
return max( TreeDepth(pRoot->left), TreeDepth(pRoot->right) )+1;
}
};
2. 层序遍历(队列)
求树的层数就想到了层序遍历的方法,由于队列中的元素个数是可知的,所以循环把本层的元素处理完即可,统计二叉树层数需要在每一层内进行循环,但是如果是按照层序遍历的顺序打印元素就不需要分层循环了。
//使用层序遍历来统计层数,由于每层的节点个数n可以统计出来,那就循环n次,把队列中n个节点都出队,同时将其子节点入队。
class Solution {
public:
int TreeDepth(TreeNode* pRoot) {
TreeNode* FrontNode(nullptr);
queue<TreeNode*> que;
int Res=0;
if(pRoot==nullptr)
return 0;
que.push(pRoot);
while(!que.empty())
{
++Res;
size_t n = que.size(); //统计本层的节点个数
for(size_t i=0; i<n; ++i)
{
FrontNode = que.front();
que.pop();
if(FrontNode->left)
que.push(FrontNode->left);
if(FrontNode->right)
que.push(FrontNode->right);
}
}
return Res;
}
};
3. 本题小结
- 统计树的深度可以使用递归的方法,后序遍历。
- 也可以使用队列层序遍历,在对一层的队列元素进行处理之前可以先统计本层的元素个数,然后在循环中处理本层所有节点,然后深度++,最后进入下一层的处理。
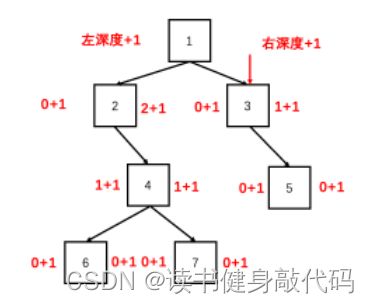
2. JZ27 二叉树的镜像
1. 递归
在前向递归的时候就交换左右结点,依次迭代直到叶子节点,就完成了镜像。
//递归法
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pRoot TreeNode类
* @return TreeNode类
*/
TreeNode* Mirror(TreeNode* pRoot) {
// write code here
if(pRoot==nullptr)
return pRoot;
TreeNode* TmpNode = pRoot->left;
pRoot->left = pRoot->right;
pRoot->right = TmpNode;
pRoot->left = Mirror(pRoot->left);
pRoot->right = Mirror(pRoot->right);
return pRoot;
}
};
2. 栈
在树中,凡是能用递归的都能用栈。
由于先对左右结点入栈,然后再交换左右结点,所以相当于是在原来的树上的右侧开始处理,堆栈保证了在出栈时一个右结点,一个左节点地处理。
/**
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* };
*/
//栈法
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pRoot TreeNode类
* @return TreeNode类
*/
TreeNode* Mirror(TreeNode* pRoot) {
// write code here
if(pRoot==nullptr)
return pRoot;
stack<TreeNode*> sta1;
sta1.push(pRoot);
while(!sta1.empty())
{
TreeNode* TopNode = sta1.top();
sta1.pop();
if(TopNode->left)
sta1.push(TopNode->left);
if(TopNode->right)
sta1.push(TopNode->right);
TreeNode* TmpNode = TopNode->left;
TopNode->left = TopNode->right;
TopNode->right = TmpNode;
}
return pRoot;
}
};
3. 本题小结
- 二叉树的镜像用递归比较简单;
- 二叉树中能用递归的大多数也能用栈,求深度不行,因为求深度如果不递归的话就得处理一层中所有的结点,但是对于已经在栈中的元素,出了栈之后就得立即处理,但是由于栈式LIFO,新入栈的就不是这一层的了,所以不能用栈。
3. JZ28 对称的二叉树(有些难)

这题本身之前想用双向队列deque进行层序遍历,每次将deque中的front()和back()出队比较其值,其实想想这样也可以做。后面尝试一下
1. 层序遍历
不用严格控制每层,即不用设置一层的for循环,原理是如果对称的话,遍历每一层的数据会形成回文,所以管理两个相对的队列,一个从左,一个从右,空指针也要算,否则可能会因为空指针位置不同而导致不同的结构,就不对称了。
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};
*/
//使用层序遍历判断,使用deque
class Solution {
public:
bool isSymmetrical(TreeNode* pRoot) {
if(pRoot==nullptr)
return true;
queue<TreeNode*> quel; //左便利
queue<TreeNode*> quer; //右遍历
quel.push(pRoot->left);
quer.push(pRoot->right);
while(!quel.empty() && !quer.empty())
{
TreeNode * LeftFront = quel.front();
TreeNode * RightFront = quer.front();
quel.pop();
quer.pop();
//同时为空就不插入了,就能检测到退出了
if(LeftFront==nullptr && RightFront==nullptr)
continue;
if((LeftFront==nullptr || RightFront==nullptr) || (LeftFront->val!=RightFront->val))
return false;
//从左往右
quel.push(LeftFront->left);
quel.push(LeftFront->right);
//从右往左
quer.push(RightFront->right);
quer.push(RightFront->left);
}
return true;
}
};
2. 递归(推荐)
思路:前序遍历的时候我们采用的是“根左右”的遍历次序,如果这棵二叉树是对称的,即相应的左右节点交换位置完全没有问题,那我们是不是可以尝试“根右左”遍历,按照轴对称图像的性质,这两种次序的遍历结果应该是一样的。
递归主要把握住:条递逻。
终止条件:当二者都为nullptr证明到了叶子节点,返回true;当二者不是同时为nullptr或者二者的val不相等,则必定不对称,返回false。
递归调用:因为是“根左右”和“根右左”的递归,所以递归的 “左对右”&“右对左” 。
逻辑处理:此题没有什么逻辑处理(链表反转那题在正向时要反转指针,属于逻辑处理,此题没有)。
//使用层序遍历判断,使用deque
class Solution {
public:
//先序遍历和逆先序遍历
bool recursion(TreeNode* root1, TreeNode* root2)
{
//可以两个都为空
if(root1==nullptr && root2==nullptr)
return true;
//只有一个为空或者节点值不同,必定不对称
if(root1==nullptr || root2==nullptr || root1->val!=root2->val)
return false;
//每层对应的节点进入递归,“根左右”走左边的时候“根右左”走右边,“根左右”走右边的时候“根右左”走左边
return recursion(root1->left, root2->right) && recursion(root1->right, root2->left);
}
bool isSymmetrical(TreeNode* pRoot) {
return recursion(pRoot, pRoot);
}
};
4. JZ79 判断是不是平衡二叉树

1. 自顶向下递归(推荐)
空间复杂度O(n),递归的栈;时间复杂度 O ( n 2 ) O(n^2) O(n2),最坏情况每个结点都要递归IsBalanced_Solution()函数,每个IsBalanced_Solution(0里面是O(n),所以是 O ( n 2 ) O(n^2) O(n2).
这个我做的时候忘了对每个子树都要递归调用IsBalanced_Solution(),可能出现两遍都是两个链表一样的子树,显然不是平衡的。
//自顶向下法,先获得深度再根据深度判断是否平衡
class Solution {
public:
int recursion(TreeNode* root)
{
if(root==nullptr)
return 0;
return max(recursion(root->left), recursion(root->right))+1;
}
bool IsBalanced_Solution(TreeNode* pRoot) {
if(pRoot==nullptr)
return true;
int HLeft = recursion(pRoot->left);
int HRight = recursion(pRoot->right);
if(abs(HLeft - HRight)>1)
return false;
return IsBalanced_Solution(pRoot->left) & IsBalanced_Solution(pRoot->right); //每一个子树都要判断其是否平衡
}
};
2. 自底向上法
在第一步递归的基础上添加一些判断的代码即可得这个版本,但是有些难理解。

//自底向上法,从底部的子树开始判断,如果子树不平衡,直接返回false,不用再判断
class Solution {
public:
bool recursion(TreeNode* root, int& depth) //条递逻
{
if(root==nullptr)
{
depth=0;
return true;
}
int LDepth = 0;
int RDepth = 0;
if(recursion(root->left, LDepth)==false || recursion(root->right, RDepth) == false)
return false;
// 判断深度查是否大于1
if(abs(LDepth-RDepth)>1)
return false;
depth = max(LDepth, RDepth)+1;
return true;
}
bool IsBalanced_Solution(TreeNode* pRoot)
{
if(pRoot==nullptr)
return true;
int depth = 0;
return recursion(pRoot, depth); //每一个子树都要判断其是否平衡
}
};
3. 本题小结
自顶向下递归虽然时间复杂度高,但是容易理解,因为计算深度和判断平衡是分开进行的(注意对每个子树都要递归判断是否平衡,避免左右链表得情况);而自底向上法将这两项工作融合在一起,理解起来有些难。
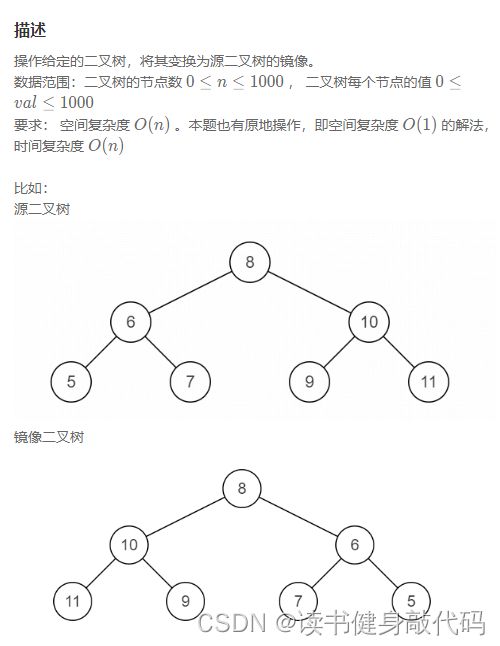
5. JZ77 按之字形顺序打印二叉树

1. 使用双端队列deque(推荐)
时间空间复杂度均为O(N)
很好理解,只需要额外维护一个布尔类型的flag,为true时从对头输出,从左到右入队尾;为false时从队尾输出,从右到左入队头。注意结果是一个二维vector
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};
*/
//考虑层序遍历,双向队列,单层(True)从左到右,双层(false)从右到左。
class Solution {
public:
vector<vector<int> > Print(TreeNode* pRoot) {
bool LayerFlag(true);
deque<TreeNode*> deq;
vector<vector<int> > ResVec;
if(pRoot==nullptr)
return ResVec;
deq.push_back(pRoot);
while(!deq.empty())
{
vector<int> ResTmp;
int n = deq.size();
//单层从左到右
if(LayerFlag)
{
LayerFlag = false;
for(int i=0; i<n; ++i)
{
TreeNode* TmpNode = deq.front();
ResTmp.push_back(TmpNode->val);
deq.pop_front();
if(TmpNode->left) deq.push_back(TmpNode->left);
if(TmpNode->right) deq.push_back(TmpNode->right);
}
ResVec.push_back(ResTmp);
}
//双层从右到左
else
{
LayerFlag = true;
for(int i=0; i<n; ++i)
{
TreeNode* TmpNode = deq.back();
ResTmp.push_back(TmpNode->val);
deq.pop_back();
if(TmpNode->right) deq.push_front(TmpNode->right);
if(TmpNode->left) deq.push_front(TmpNode->left);
}
ResVec.push_back(ResTmp);
}
}
return ResVec;
}
};
2. 官方解析1—普通队列
时间空间复杂度均为O(N)
使用普通队列,维护一个层数变量level,出队正常从front出,但是插入到二维Result vector中根据层数判断是push_back还是insert(begin),如此实现之字输出。
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};
*/
class Solution {
public:
vector<vector<int> > Print(TreeNode* pRoot) {
vector<vector<int> > res;
if (!pRoot)
return res;
queue<TreeNode*> q; // 定义队列
q.push(pRoot); // 根结点入队列
int level = 0;
while (!q.empty()) {
vector<int> arr; // 定义数组存储每一行结果
int size = q.size(); // 当前队列长度
for (int i = 0; i < size; i++) {
TreeNode* tmp = q.front(); // 队头元素
q.pop();
if (!tmp) // 空元素跳过
continue;
q.push(tmp->left); // 左孩子入队列
q.push(tmp->right); // 右孩子入队列
if (level % 2 == 0) {
// 从左至右打印
arr.push_back(tmp->val);
} else { // 从右至左打印
arr.insert(arr.begin(), tmp->val);
}
}
level++; // 下一层,改变打印方向
if (!arr.empty())
res.push_back(arr); // 放入最终结果
}
return res;
}
};
3. 官方解析2—双堆栈
时间空间复杂度均为O(N),维护两个堆栈,根据不同层决定从左往右入栈还是从右往左入栈,对于结果都是push_back()
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};
*/
class Solution {
public:
vector<vector<int> > Print(TreeNode* pRoot) {
vector<vector<int> > res;
if (!pRoot)
return res;
stack<TreeNode*> stk1, stk2; // 定义两个栈
stk1.push(pRoot); // 根结点入栈
while (!stk1.empty() || !stk2.empty()) { // 两个栈全空时循环结束
vector <int> arr;
while (!stk1.empty()) {
TreeNode* p = stk1.top();
stk1.pop();
arr.push_back(p->val); // 访问栈顶
if (p->left) stk2.push(p->left); // 左孩子入栈
if (p->right) stk2.push(p->right); // 右孩子入栈
}
if (arr.size())
res.push_back(arr); // 保存结果
arr.clear(); // 清空
while (!stk2.empty()) {
TreeNode* p = stk2.top();
stk2.pop();
arr.push_back(p->val); // 访问栈顶
if (p->right) stk1.push(p->right); // 右孩子入栈
if (p->left) stk1.push(p->left); // 左孩子入栈
}
if (arr.size())
res.push_back(arr); // 保存结果
}
return res;
}
};
4. 本题小结
使用双向队列deque直观,代码也好写,只需注意出队和入队的方向。
6. JZ32 从上往下打印二叉树(简单)
1. 层序遍历(推荐)
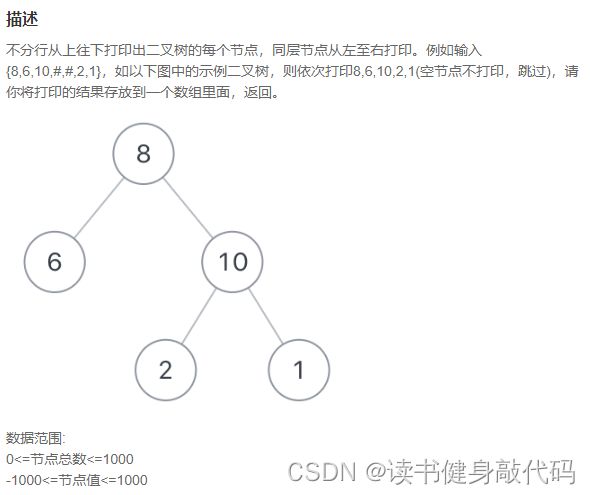
// 层次遍历二叉树
class Solution {
public:
vector<int> PrintFromTopToBottom(TreeNode* root) {
vector<int> ResVec;
queue<TreeNode*> que;
if(root==nullptr)
return ResVec;
que.push(root);
while(!que.empty())
{
TreeNode* TmpNode = que.front();
que.pop();
ResVec.push_back(TmpNode->val);
if(TmpNode->left) que.push(TmpNode->left);
if(TmpNode->right) que.push(TmpNode->right);
}
return ResVec;
}
};
2. 官方基于递归的层序遍历
实际上是先将所有数据按照层次为第一下标存在一个二维vector中,然后遍历二维vector存到1维vector中,有些麻烦,看看思路即可。
class Solution {
public:
void traverse(TreeNode* root, vector<vector<int>>& res, int depth) {
if(root){
//新的一层
if(res.size() < depth)
res.push_back(vector<int>{});
//vector从0开始计数因此减1,在节点当前层的vector中插入节点
res[depth - 1].push_back(root->val);
}
else
return;
//递归左右时进入下一层
traverse(root->left, res, depth + 1);
traverse(root->right, res, depth + 1);
}
vector<int> PrintFromTopToBottom(TreeNode* root) {
vector<int> res;
vector<vector<int> > temp;
if(root == NULL)
//如果是空,则直接返回空vector
return res;
traverse(root, temp, 1);
//送入一维数组
for(int i = 0; i < temp.size(); i++)
for(int j = 0; j < temp[i].size(); j++)
res.push_back(temp[i][j]);
return res;
}
};
7. JZ54 二叉搜索树的第k个节点

1. 使用vector
使用中序遍历,依次将节点push_back()到vector中,检查元素个数,到k就停止插入,然后输出。
//随时检查vec是否符合对应的节点个数
void MidRecursion(TreeNode* root, int k, vector<int>& vec)
{
if(root==nullptr || vec.size()==k) return;
MidRecursion(root->left, k, vec);
//只插入到等于k时
if(vec.size()<k) vec.push_back(root->val);
MidRecursion(root->right, k, vec);
}
//返回的是节点值
int KthNode(TreeNode* proot, int k) {
// write code here
vector<int> vec;
if(k==0) return -1;
MidRecursion(proot, k, vec);
if(vec.size()==k) return vec[k-1];
else return -1;
}
2. 官方给的直接使用count(推荐)
不用push_back(),直接管理一个计数器count,到达k就停止遍历,然后输出,注意如果不定义成员变TreeNode* Res(nullptr)的话,需要传入指针的引用TreeNode*& Res,否则默认初始化的指针是空指针,一直报错。
void MidRecursion(TreeNode* root, int& count, int k, TreeNode*& res)
{
if(root==nullptr || count==k)
return;
MidRecursion(root->left, count, k, res);
++count;
if (count==k)
res = root;
MidRecursion(root->right, count, k, res);
}
//返回的是节点值
int KthNode(TreeNode* proot, int k) {
// write code here
vector<int> vec;
int count=0;
TreeNode* Res = nullptr;
MidRecursion(proot, count, k, Res);
if(Res) return Res->val;
else return -1;
}
3. 官方使用栈进行中序遍历
这个不太好写,还是递归比较方便。这个思想是先从左子树开始到底,到底之后转到右子树,再左子树到底,再转到右子树,直到找到够k个为止。
class Solution {
public:
int KthNode(TreeNode* proot, int k) {
if(proot == NULL)
return -1;
//记录遍历了多少个数
int count = 0;
TreeNode* p = NULL;
//用栈辅助建立中序
stack<TreeNode*> s;
while(!s.empty() || proot != NULL){
while (proot != NULL) {
s.push(proot);
//中序遍历每棵子树从最左开始
proot = proot->left;
}
p = s.top();
s.pop();
count++;
//第k个直接返回
if(count == k)
return p->val;
proot = p->right;
}
//没有找到
return -1;
}
};
4. 本题小结
- 先序,中序,后序遍历都是在根节点处进行操作,比如这里的
++count。
8. JZ68 二叉搜索树的最近公共祖先
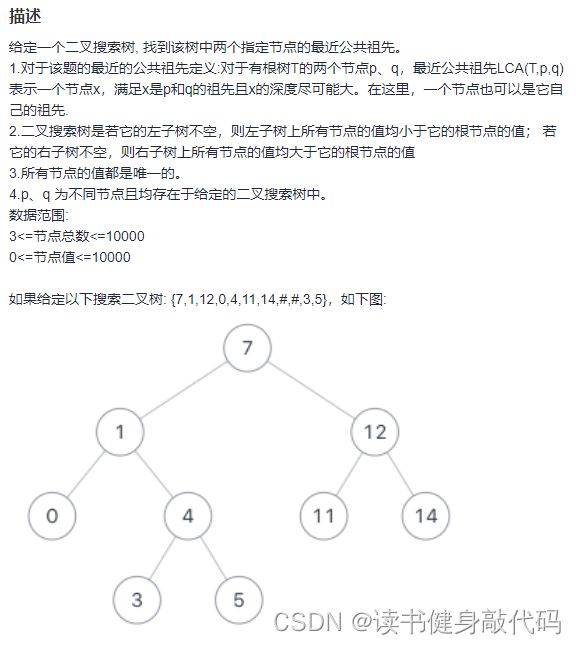
1. 自己的层序遍历搜索法
空间复杂度 O ( N ) O(N) O(N),时间复杂度 O ( N ) O(N) O(N)。
思路:
- 先使用层序遍历将所有的结点值存入一个vector
- 再求得p和q的深度,根据深度是否相同来搜索,
- 相同时从其所在的层的上一层开始搜索,找其父节点,直到找到相同父节点为止;
- 若深度不同则从较深的一层开始找,直到找到相同的层,如果找到的父节点是相同的,则返回,如果不同则根据3的思路来查找。
在过程3中最坏的情况是最底层的两个结点,其唯一公共父节点是最上层的根节点,需要遍历所有结点才能找到,时间复杂度O(N);引入了额外的vector
/**
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* };
*/
//空间复杂度O(N),时间复杂度O(N^2)
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @param p int整型
* @param q int整型
* @return int整型
*/
void LayerTraverse(TreeNode* root, int& layer, vector<map<int, TreeNode*>>& Vec)
{
queue<TreeNode*> que;
if(root==nullptr) return;
que.push(root);
while(!que.empty())
{
//层数递增
++layer;
//本层数据个数
int n = que.size();
map<int, TreeNode*> TmpMap;
for(int i=0; i<n; ++i)
{
TreeNode* TmpNode=que.front();
que.pop();
TmpMap[TmpNode->val] = TmpNode;
if(TmpNode->left) que.push(TmpNode->left);
if(TmpNode->right) que.push(TmpNode->right);
}
//本层数据入vector
Vec.push_back(TmpMap);
}
}
//在相同层的遍历上查找共同祖先,
//@param layer 待查的数据所在的层数
int FindInSameLayer(vector<map<int, TreeNode*>>& Vec, int& layer, int p, int q)
{
//到了同一层,仍然不是本身,那就继续往上在每一层中找
for(int i=layer-1; i>=0; --i)
{
for(auto each:Vec[i])
{
int TmpVal = -1;
if(each.second->left)
{
TmpVal = each.second->left->val;
if(TmpVal==p) p = each.first;
if(TmpVal==q) q = each.first;
}
if(each.second->right)
{
TmpVal = each.second->right->val;
if(TmpVal==p) p = each.first;
if(TmpVal==q) q = each.first;
}
if(p==q) return p;
}
}
return -1;
}
//使用层序遍历将数据全部存入vector > >中便于查找
int lowestCommonAncestor(TreeNode* root, int p, int q) {
// write code here
if(p==q) return p;
int layer = -1;
int Res = -1;
vector<map<int, TreeNode*>> Vec;
LayerTraverse(root, layer, Vec);
//求p,q深度
int DP=0;
int DQ=0;
for(int i=0; i<Vec.size(); ++i)
{
//根据first的值来找
if(Vec[i].find(p)!=Vec[i].end()) DP = i;
if(Vec[i].find(q)!=Vec[i].end()) DQ = i;
}
//若p,q深度相同,分别找到上一层的祖先,如果相同则结束查找,如果不同继续往上查找
if(DP==DQ)
{
Res = FindInSameLayer(Vec, layer, p, q);
if(Res!=-1) return Res;
}
// 深度不相同时先从更深的往上找,直到找到同一深度。
int TMP_Anc = -1;
int max_layear = (DP>DQ)? DP:DQ;
int min_layear = (DP<DQ)? DP:DQ;
int ToFindVal = (DP>DQ)? p:q;
int ToComparedVal = (DP<DQ)? p:q;
for(int i=max_layear-1; i>=min_layear; --i)
for(auto each:Vec[i])
{
int TmpVal = -1;
if(each.second->left)
{
TmpVal = each.second->left->val;
if(TmpVal==ToFindVal) ToFindVal = each.first;
}
if(each.second->right)
{
TmpVal = each.second->right->val;
if(TmpVal==ToFindVal) ToFindVal = each.first;
}
if(ToFindVal==ToComparedVal) return ToFindVal; //往上找找到了本身就是最近祖先节点
}
//到了同一层,仍然不是本身,那就继续往上在每一层中找
Res = FindInSameLayer(Vec, min_layear, ToFindVal, ToComparedVal);
if(Res!=-1) return Res;
return -1;
}
};
2. 官方1–路径搜索比较(推荐)
空间复杂度 O ( N ) O(N) O(N),时间复杂度 O ( N ) O(N) O(N)
思路:分别找到从根节点到p和q的路径,比较路径,最后一个相同的路径点就是最近祖先节点。
最坏情况是一个链表式的二叉比较树,存放路径,空间复杂度 O ( N ) O(N) O(N),只有最初的根节点式共同祖先,时间复杂度 O ( N ) O(N) O(N)
//空间复杂度O(N),时间复杂度O(N)
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @param p int整型
* @param q int整型
* @return int整型
*/
//获得路径
void GetPath(TreeNode* root, int target, vector<int>& ResVec)
{
TreeNode* TmpNode(root);
while(TmpNode->val!=target)
{
ResVec.push_back(TmpNode->val);
if(TmpNode->val > target)
TmpNode = TmpNode->left;
else
TmpNode = TmpNode->right;
}
ResVec.push_back(target);
}
//使用层序遍历将数据全部存入vector > >中便于查找
int lowestCommonAncestor(TreeNode* root, int p, int q) {
// write code here
int Res=-1;
vector<int> PathP;
vector<int> PathQ;
GetPath(root, p, PathP);
GetPath(root, q, PathQ);
int Short = (PathP.size()<PathQ.size())? PathP.size() : PathQ.size();
for(size_t i=0; i<PathP.size() && i<PathQ.size(); ++i)
{
if(PathP[i]==PathQ[i])
{
Res = PathP[i];
}
else break;
}
return Res;
}
};
3. 官方–2一次遍历法(更推荐)
分析是王道:二叉查找树的特征是左<根<右,所以如果 此根节点值大于一个小于另一个,则此根节点必定是最近的公共父节点,如果此节点均大于两值,则要找的点必定在左子树上,往左递归即可,如果均小于,则必在右子树上,往右递归即可。
这就是二分查找的原型,时间复杂度 O ( l o g ( N ) ) O(log(N)) O(log(N)),空间复杂度 O ( N ) O(N) O(N)(这个不太确定)。
//空间复杂度O(N),时间复杂度O(log(N))
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @param p int整型
* @param q int整型
* @return int整型
*/
//递归调用
int lowestCommonAncestor(TreeNode* root, int p, int q) {
// write code here
if( ((root->val >= p) && (root->val <= q)) || (root->val <= p) && (root->val >= q) )
return root->val;
else if(root->val>=p && root->val>=q)
return lowestCommonAncestor(root->left, p, q);
else
return lowestCommonAncestor(root->right, p, q);
}
};
4. 小结
- (最推荐)最推荐的方法是一边遍历递归,跟据分析,结果只能在一个大于,一个小于的节点处。
- (次推荐)根据左<根<右的特征可以找到 p p p和 q q q的路径,两个路径最后一个相同的值就是结果。
9. JZ26 树的子结构
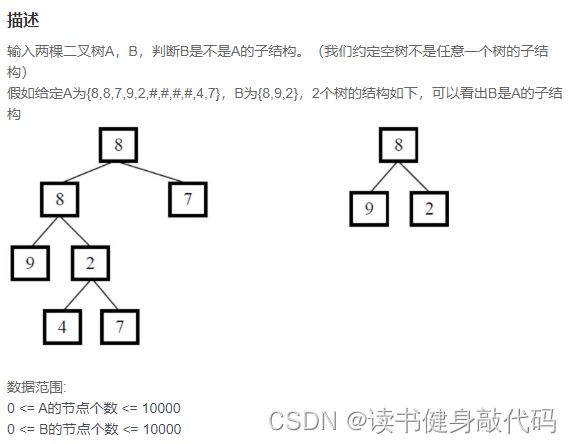
1. 递归先序遍历(推荐)
思路:先找到A中与B的根节点值相同的结点;根据已找到的头结点为地址,同时先序遍历A和B,比较数值是否相同,如果最后都相同,那么B为A的子树,有一个不相同则不是子树。
复杂度分析:时间复杂度: O ( m n ) O(mn) O(mn), m m m和 n n n分别是AB树的节点个数,最坏情况下,B为aab形式,A中结点只有一个b剩下全是a,所以要在A按照B的顺序遍历m次,最后才找到匹配的aab,所以是 O ( m n ) O(mn) O(mn),实际上求相同根节点可以和后面的前序遍历查找融合在一起,但是这样显得代码混乱,不易读懂。
官方方法和我的思路相同,这里就不贴官方的代码了。
//递归解决,在每个递归中只判断根,利用先序遍历来递归
class Solution {
public:
bool PreTraverse(TreeNode* root1, TreeNode* root2)
{
bool Res(false);
if(root2==nullptr)
return true;
else if(root2!=nullptr && root1==nullptr)
return false;
else if(root1->val!=root2->val)
return false;
Res = PreTraverse(root1->left, root2->left);
if(Res==false) return false;
Res = PreTraverse(root1->right, root2->right);
return Res;
}
void FindRoot(TreeNode* root, int TargetVal, vector<TreeNode*>& RootVec)
{
if(root)
{
if(root->val==TargetVal)
RootVec.push_back(root);
FindRoot(root->left, TargetVal, RootVec);
FindRoot(root->right, TargetVal, RootVec);
}
}
bool HasSubtree(TreeNode* pRoot1, TreeNode* pRoot2) {
if(pRoot1==nullptr || pRoot2==nullptr)
return false;
vector<TreeNode*> RootVec;
FindRoot(pRoot1, pRoot2->val, RootVec); //在A中找到与B根节点相同的根节点
bool Res(false);
for(auto EachRoot:RootVec)
{
Res = PreTraverse(EachRoot, pRoot2);
if(Res==true)
return true; //有一个就算有
}
return false;
}
};
2. 两次层次遍历
思想是借助队列方法1中的先序遍历替换为层次遍历,其余一样。将A先进行层次遍历,找到B的头结点,找到之后就以这个结点为头节点来层次遍历这棵树,与B比较。
class Solution {
public:
//层次遍历判断两个树是否相同
bool helper(TreeNode* root1, TreeNode* root2){
queue<TreeNode*> q1, q2;
q1.push(root1);
q2.push(root2);
//以树2为基础,树1跟随就可以了
while(!q2.empty()){
TreeNode* node1 = q1.front();
TreeNode* node2 = q2.front();
q1.pop();
q2.pop();
//树1为空或者二者不相等
if(node1 == NULL || node1->val != node2->val)
return false;
//树2还有左子树
if(node2->left){
//子树入队
q1.push(node1->left);
q2.push(node2->left);
}
//树2还有右子树
if(node2->right){
//子树入队
q1.push(node1->right);
q2.push(node2->right);
}
}
return true;
}
bool HasSubtree(TreeNode* pRoot1, TreeNode* pRoot2) {
//空树不为子结构
if(pRoot1 == NULL || pRoot2 == NULL)
return false;
queue<TreeNode*> q;
q.push(pRoot1);
//层次遍历树1
while(!q.empty()){
TreeNode* node = q.front();
q.pop();
//遇到与树2根相同的节点,以这个节点为根判断后续子树是否相同
if(node->val == pRoot2->val){
if(helper(node, pRoot2))
return true;
}
//左子树入队
if(node->left)
q.push(node->left);
//右子树入队
if(node->right)
q.push(node->right);
}
return false;
}
};
3. 本题小结
- 查找B树是否为A的子树,需要两步:1. 先序遍历在A中找到与B的头节点值相同的所有结点 2.对于每个找到的节点,先序遍历对比AB子树是否相同,只要有一个相同就算是找到了。
10. JZ8 二叉树的下一个结点

1. 中序遍历分情况讨论
因为中序遍历是根左右。
思路:三种情况
- 若有右子树,对右子树中序遍历,取最左下角的值;
- 若无右子树,则依次往上爬,找目标节点的左父结点,找到则返回;
- 找不到则返回nullptr
/*
struct TreeLinkNode {
int val;
struct TreeLinkNode *left;
struct TreeLinkNode *right;
struct TreeLinkNode *next;
TreeLinkNode(int x) :val(x), left(NULL), right(NULL), next(NULL) {
}
};
*/
class Solution {
public:
//左中右
void MidTraverse(TreeLinkNode* root, TreeLinkNode*& ResNode)
{
if(root)
{
if(ResNode==nullptr) MidTraverse(root->left,ResNode);
if(ResNode==nullptr) ResNode = root;
if(ResNode==nullptr) MidTraverse(root->right,ResNode);
}
}
TreeLinkNode* GetNext(TreeLinkNode* pNode) {
if(pNode==nullptr) return nullptr;
TreeLinkNode* ResNode(nullptr);
// 1. 找右子树中序遍历第一个值(其实也可以不用找最左小角的值)
MidTraverse(pNode->right, ResNode);
if(ResNode) return ResNode;
// 2. 右子树若没有,找左父节点,如果没有则返回nullptr
TreeLinkNode* TmpNode = pNode;
while(TmpNode->next && TmpNode->next->right==TmpNode)
TmpNode = TmpNode->next;
return TmpNode->next;
}
};
2. 官方(推荐)
思路:找到根节点,从根节点对整棵树进行中序遍历,保存结果;输出结果中目标节点的下一个结点
class Solution {
public:
//左中右
void MidTraverse(TreeLinkNode* root, vector<TreeLinkNode*>& ResNode)
{
if(root)
{
MidTraverse(root->left,ResNode);
ResNode.push_back(root);
MidTraverse(root->right,ResNode);
}
}
TreeLinkNode* GetNext(TreeLinkNode* pNode) {
if(pNode==nullptr) return nullptr;
TreeLinkNode* root(pNode);
TreeLinkNode* ResNode(nullptr);
vector<TreeLinkNode*> MidRes;
while(root->next!=nullptr)
root = root->next; //寻找根节点
MidTraverse(root, MidRes);
for(size_t i=0; i<MidRes.size(); ++i)
if(MidRes[i]==pNode && i+1<MidRes.size())
ResNode = MidRes[i+1];
return ResNode;
}
};
3. 本题小结
- 这种分情况讨论的话,可能不会想的那么全,所以可以的话使用最简单的思路实现最好。直接找出根节点,中序遍历,取出下一个结点即可。
11. JZ7 重建二叉树

二叉树的重建必须要有中序遍历,外加一个先序或者后序遍历即可重建。
1. 自己结合先序和中序
本题思路:先序遍历的第一个节点是根节点,在中序中找到根节点对应的位置,将中序再分为左中序和右中序,按照数量将先序划分为左先序和右先序,以此递归,即可求解。
自己的代码,思路相同,但实现有些复杂:
/**
* Definition for binary tree
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
// 先序遍历第一个是根节点R,在中序中找到R,将中序拆分成左中序和右中序;根据长度取出先序序列中的左先序和右先序,
// 递归上述的操作,不断地把先序中的根节点加到结果中
class Solution {
public:
void recursion(TreeNode*& root, vector<int>& pre, vector<int>& vin)
{
TreeNode* TmpNode(root);
//叶子节点,左右都为空
if(pre.size()==1) {
root=new TreeNode(pre[0]);
return;
}
//对序列进行拆分
//在中序中查找
vector<int> TmpPre;
vector<int> TmpIn;
int RootIdxIn = (int)(std::find(vin.begin(), vin.end(), pre[0])-vin.begin());
root = new TreeNode(pre[0]);
//在头,证明无左子树,处理右子树
if(RootIdxIn==0) {
TmpPre.assign(pre.begin()+RootIdxIn+1, pre.end()); //左闭右开
TmpIn.assign(vin.begin()+RootIdxIn+1, vin.end());
recursion(root->right, TmpPre, TmpIn);
}
//在末尾,证明无右子树
else if(RootIdxIn==vin.size()-1)
{
TmpPre.assign(pre.begin()+1, pre.begin()+RootIdxIn+1);
TmpIn.assign(vin.begin(), vin.begin()+RootIdxIn);
recursion(root->left, TmpPre, TmpIn);
}
//在中间,两边都处理
else
{
TmpPre.assign(pre.begin()+1, pre.begin()+RootIdxIn+1);
TmpIn.assign(vin.begin(), vin.begin()+RootIdxIn);
recursion(root->left, TmpPre, TmpIn);
//右前序和右中序
TmpPre.assign(pre.begin()+RootIdxIn+1, pre.end());
TmpIn.assign(vin.begin()+RootIdxIn+1, vin.end());
recursion(root->right, TmpPre, TmpIn);
}
}
TreeNode* reConstructBinaryTree(vector<int> pre,vector<int> vin) {
TreeNode* ResNode(nullptr);
if(pre.empty()) return nullptr; //是否可行
// ResNode = new TreeNode(pre[0]);
recursion(ResNode, pre, vin);
return ResNode;
}
};
2. 官方的递归版本代码(推荐)
同样的思路,官方的递归版本代码,较为简洁:
class Solution {
public:
TreeNode* reConstructBinaryTree(vector<int> pre,vector<int> vin) {
int n=pre.size();
int m = vin.size();
if(n==0 || m==0) return nullptr;
TreeNode* root = new TreeNode(pre[0]);
for(int i=0; i<vin.size(); ++i)
{
if(pre[0]==vin[i])
{
vector<int> leftpre(pre.begin()+1, pre.begin()+i+1);
vector<int> leftvin(vin.begin(), vin.begin()+i);
root->left = reConstructBinaryTree(leftpre, leftvin);
vector<int> rightpre(pre.begin()+i+1, pre.end());
vector<int> rightvin(vin.begin()+i+1, vin.end());
root->right = reConstructBinaryTree(rightpre, rightvin);
break;
}
}
return root;
}
};
2. 官方思路扩展–栈

class Solution {
public:
TreeNode* reConstructBinaryTree(vector<int> pre,vector<int> vin) {
int n = pre.size();
int m = vin.size();
//每个遍历都不能为0
if(n == 0 || m == 0)
return NULL;
stack<TreeNode*> s;
//首先建立前序第一个即根节点
TreeNode *root = new TreeNode(pre[0]);
TreeNode *cur = root;
for(int i = 1, j = 0; i < n; i++){
//要么旁边这个是它的左节点
if(cur->val != vin[j]){
cur->left = new TreeNode(pre[i]);
s.push(cur);
//要么旁边这个是它的右节点,或者祖先的右节点
cur = cur->left;
}else{
j++;
//弹出到符合的祖先
while(!s.empty() && s.top()->val == vin[j]){
cur = s.top();
s.pop();
j++;
}
//添加右节点
cur->right = new TreeNode(pre[i]);
cur = cur->right;
}
}
return root;
}
};
3. 本题小结
- 需要注意STL中的区间都是左闭右开,迭代器的
.end()是尾后迭代器,所以vec1(vec.begin(), vec.end())能取整个vec,因为是左闭右开,所以vec1(vec.begin(), vec.begin())是空的。 - vector的查找可以使用
std::find(vec.begin(), vec.end(), element), - 取vector的区间可以在初始化时传入范围迭代器
vector,也可以使用vec1(vec.begin(), vec.end()) vec1.assign(vec.begin(), vec.end()),只不过assign()是void函数,无返回值。 - 使用栈
12. JZ82 二叉树中和为某一值的路径(一)

1. 自己的把所有叶子结点的和求出来再查找
先把所有叶子节点的和求出来存入vector中,最后在其中查找有没有,如果
class Solution {
public:
/**
*
* @param root TreeNode类
* @param sum int整型
* @return bool布尔型
*/
//朴素的想法:求出所有叶子结点的路径长度,找有没有即可。
//先序 根左右
void PreTraverse(TreeNode* root, int TmpSum, vector<int>& ResVec)
{
if(root)
{
TmpSum += root->val;
if(root->left==nullptr && root->right==nullptr) //叶子节点
ResVec.push_back(TmpSum);
PreTraverse(root->left, TmpSum, ResVec);
PreTraverse(root->right, TmpSum, ResVec);
}
}
bool hasPathSum(TreeNode* root, int sum) {
// write code here
if(root==nullptr)
return false;
vector<int> ResVec;
int TmpSum=0;
PreTraverse(root, TmpSum, ResVec);
if(std::find(ResVec.begin(), ResVec.end(), sum)!=ResVec.end())
return true;
else return false;
}
};
2. 官方递归(推荐)
不进行递增,而是进行相减,如果减到叶子节点时刚好差为0则证明存在这种路径,先序递归调用。
class Solution {
public:
/**
*
* @param root TreeNode类
* @param sum int整型
* @return bool布尔型
*/
//先序 根左右
bool hasPathSum(TreeNode* root, int sum) {
// write code here
if(root==nullptr) return false;
if(root->left==nullptr && root->right==nullptr && sum-root->val==0) return true; //叶子节点
return hasPathSum(root->left, sum-root->val) || hasPathSum(root->right, sum-root->val);
}
};
3. 官方非递归(实际上是DFS,不是严格先序,因为一个方向没到底)(同样推荐)
这个基于栈的DFS(深度优先搜索)对于左右节点入栈的先后顺序没有要求,因为栈是LIFO所以处理的方式就是针对某一个节点处理到其叶子节点之后才会处理其他的节点,所以形成了DFS,总体来说这个处理的了逻辑较为简单。

class Solution {
public:
/**
*
* @param root TreeNode类
* @param sum int整型
* @return bool布尔型
*/
bool hasPathSum(TreeNode* root, int sum) {
if(root==nullptr) return false;
stack<pair<TreeNode*,int>> sta;
sta.push(make_pair(root, sum-root->val));
while(!sta.empty() ){
auto TmpPair = sta.top();
sta.pop();
if(TmpPair.first->left==nullptr && TmpPair.first->right==nullptr && TmpPair.second==0)
return true;
if(TmpPair.first->left) sta.push(make_pair(TmpPair.first->left, TmpPair.second-TmpPair.first->left->val));
if(TmpPair.first->right) sta.push(make_pair(TmpPair.first->right, TmpPair.second-TmpPair.first->right->val));
}
return false;
}
};
4. 拓展–二叉树的非递归先中后序遍历(重点)

把握准则,遍历只对根节点进行输出,按照上面的路线进行遍历,先序遍历第一次遇到时输出(根左右);中序第二次(左根右);后序第三次(左右根)。
递归的思路就是:



if中的三行分别代表第一次第二次和第三次遇到,所以对应的遍方式历也就在第一次第二次和第三次处理。
非递归方法借助栈来完成,左节点往下一直到底的入栈过程是第一次,到底之后转向右侧是第二次,后序遍历需要引入一个flag来判断右子节点是否访问过,如果没有,则在第二次出栈的时候将flag置为1,再入栈,下次再遇到时flag==1,就可以正常出栈输出了。
先序DFS:取弹右
/**
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* };
*/
//非递归先序遍历
void PreNoRecursionTravel(TreeNode* proot)
{
cout<<endl<<"非递归先序"<<endl;
if(proot==nullptr) return;
stack<TreeNode*> sta;
TreeNode* root = proot;
while(!sta.empty() || root)
{
//左节点一直往下到底,第一次
while(root)
{
std::cout<<root->val<<" ";
sta.push(root);
root=root->left;
}
//倒地之后转向右节点,第二次
TreeNode* TmpNode = sta.top();
sta.pop();
root = TmpNode->right;
}
}
//非递归中序遍历
void MidNoRecursionTravel(TreeNode* proot)
{
cout<<endl<<"非递归中序"<<endl;
if(proot==nullptr) return;
stack<TreeNode*> sta;
TreeNode* root = proot;
while(!sta.empty() || root)
{
//第一次
while(root)
{
sta.push(root);
root=root->left;
}
//第二次
TreeNode* TmpNode = sta.top();
sta.pop();
std::cout<<TmpNode->val<<" ";
root = TmpNode->right;
}
}
//非递归后序遍历,借助flag
void PostNoRecursionTravel(TreeNode* proot)
{
cout<<endl<<"非递归后序"<<endl;
if(proot==nullptr) return;
stack<pair<TreeNode*,int>> sta;
TreeNode* root = proot;
while(!sta.empty() || root)
{
//第一次
while(root)
{
sta.push(make_pair(root, 0));
root=root->left;
}
//第二次
auto TmpPair = sta.top();
sta.pop();
if(TmpPair.second!=1)
{
TmpPair.second=1;
sta.push(TmpPair);
root = TmpPair.first->right;
}
//第三次
else std::cout<<TmpPair.first->val<<" ";
}
}
//递归后序遍历(由于这里需要借助),第三次输出,左右根
void PostRecursionTravel(TreeNode* proot)
{
if(proot==nullptr) return;
TreeNode* root = proot;
if(root)
{
PostRecursionTravel(root->left); //左
PostRecursionTravel(root->right); //右
cout<<root->val<<" "; //根
}
}
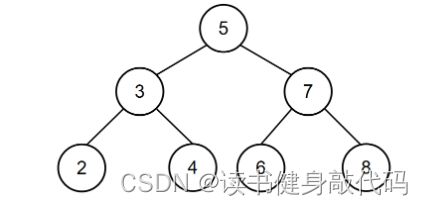

5. 本题小结
- 使用先序遍历做加法或者减法,加法看到叶子节点和是否等于sum,减法看在叶子节点的差是否为0,满足条件即视为找到。
- 使用基于栈的DFS,配合pair实现DFS的深度优先查找,比较开开阔思路。
13. JZ34 二叉树中和为某一值的路径(二)

1. 自己DFS
自己的传递临时路径和管理一个二维数组的引用,由于需要传递大量的临时路径,所以效率不高,但是容易理解,而且管理一个类成员变量笔管理一个形参效率更高。
class Solution {
public:
void recursion(TreeNode* root, int sum, vector<int> TmpRes, vector<vector<int>>& ResVec)
{
if(root==nullptr) return;
TmpRes.push_back(root->val);
sum -= root->val;
if(root->left==nullptr && root->right==nullptr && sum==0)
{
ResVec.push_back(TmpRes);
return;
}
recursion(root->left, sum, TmpRes, ResVec);
recursion(root->right, sum, TmpRes, ResVec);
}
vector<vector<int>> FindPath(TreeNode* root,int expectNumber) {
vector<vector<int>> ResVec;
vector<int> TmpRes;
if(root==nullptr) return ResVec;
recursion(root, expectNumber, TmpRes, ResVec);
return ResVec;
}
};
2. 官方DFS(推荐)
官方的DFS,这里之所以不用栈是因为这里需要路径,而栈如果取路径就得把所有的元素都出栈,出完之后就不能再使用了,而vector可以继续使用。
class Solution {
public:
vector<vector<int>> ResVec;
vector<int> path;
void dfs(TreeNode* root, int sum)
{
if(root==nullptr) return;
path.push_back(root->val);
sum -= root->val;
if(root->left==nullptr && root->right==nullptr && sum==0)
ResVec.push_back(path);
dfs(root->left, sum);
dfs(root->right, sum);
path.pop_back(); //这里需要原路返回,DFS好好理解
}
vector<vector<int>> FindPath(TreeNode* root,int expectNumber) {
dfs(root, expectNumber);
return ResVec;
}
};
3. 官方BFS(作为拓展)
//使用BFS广度优先搜索,用队列对二叉树进行层序遍历,对叶子节点的和进行比较,若匹配则记录路径
#include4. 本题小结
- 使用成员变量比传递形参效率更高。
- 对于DFS,栈适用于判断是否存在,而如果要求路径的话就得需要使用vector;且需注意求路径时路径需要依次原路返回,即官方DFS代码中的
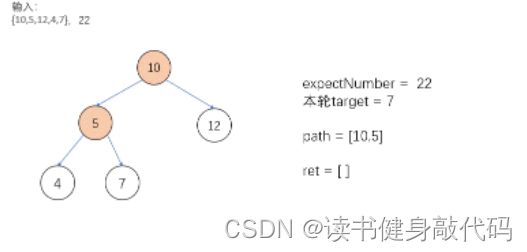
path.pop_back(),处理的是找完一个方向的到底之后,不管有没有找到,都需要退回到原来的路上进行兄弟结点的DFS,如下图,找完5的DFS之后,需要将5从path中pop掉,然后对10的right进行DFS。
14. JZ33 二叉搜索树的后序遍历序列(中)
1. 官方&自己
受T11重建二叉树的影响,递归调用,先找根节点,然后根据 左<根<右 规律的切分序列为left和right,再递归,主要是切分下标的计算。
class Solution {
public:
bool recursion(vector<int> sequence)
{
if(sequence.size()==0) return true;
int HeadVal = sequence[sequence.size()-1];
int lidx = sequence.size()-2;
//找第一个比根节点小的结点
for( ; lidx>=0; --lidx)
if(sequence[lidx] < HeadVal) break;
vector<int> left(sequence.begin(), sequence.begin()+lidx+1);
vector<int> right(sequence.begin()+lidx+1, sequence.end()-1);
for(auto each:left)
if(each>=HeadVal) return false;
return recursion(left) && recursion(right);
}
bool VerifySquenceOfBST(vector<int> sequence) {
if(sequence.size()==0) return false;
return recursion(sequence);
}
};
2. 官方使用单调栈
太难理解,不使用。
class Solution {
public:
bool VerifySquenceOfBST(vector<int> sequence) {
// 处理序列为空情况
if(sequence.size() == 0) return false;
stack<int> s;
int root = INT_MAX;
// 以根,右子树,左子树顺序遍历
for(int i = sequence.size() - 1; i >= 0; i--) {
// 确定根后一定是在右子树节点都遍历完了,因此当前sequence未遍历的节点中只含左子树,左子树的节点如果>root则说明违背二叉搜索的性质
if(sequence[i] > root) return false;
// 进入左子树的契机就是sequence[i]的值小于前一项的时候,这时可以确定root
while(!s.empty() && s.top() > sequence[i]) {
root = s.top();
s.pop();
}
// 每个数字都要进一次栈
s.push(sequence[i]);
}
return true;
}
};
3. 本题小结
- 给一序列,看他是否是搜索二叉树,可以根据根节点来切分,切分之后看剩下的是否符合搜索树的特征,可以给先序或者后序,因为可以方便地定位根节点,中序不行。
15. JZ78 把二叉树打印成多行(中)

1. 基于队列的层次遍历(BFS) (推荐)
写过很多遍了,不再赘述。这也是广度优先搜索BFS。
class Solution {
public:
//层次遍历,队列
vector<vector<int> > Print(TreeNode* pRoot) {
vector<vector<int>> Res;
if(pRoot==nullptr) return Res;
queue<TreeNode*> que;
que.push(pRoot);
while(!que.empty())
{
int n = que.size();
vector<int> TmpVec;
for(int i=0; i<n; ++i)
{
TreeNode* TmpNode = que.front();
que.pop();
TmpVec.push_back(TmpNode->val);
if(TmpNode->left) que.push(TmpNode->left);
if(TmpNode->right) que.push(TmpNode->right);
}
Res.push_back(TmpVec);
}
return Res;
}
};
2. 递归层次遍历
根据先序遍历的遍历顺序:根左右,实际上符合从上到下,从左到右的顺序,所以只需要在先序遍历的基础上管理一个行号,根据行号来进行插入即可,如果结果的维度不够,则新push_back一层。
class Solution {
public:
//先序遍历,多管理一个层号
void recursion(TreeNode* root, int layer, vector<vector<int>>& vec)
{
if(root)
{
if(vec.size()<layer) vec.push_back(vector<int>{});
vec[layer-1].push_back(root->val);
recursion(root->left, layer+1, vec);
recursion(root->right, layer+1, vec);
}
}
// 使用递归进行打印
vector<vector<int> > Print(TreeNode* pRoot) {
vector<vector<int>> Res;
recursion(pRoot, 1, Res);
return Res;
}
};
3. 本题小结
- 思考:按照题目要求,虽然后序遍历也是左右,但是是从下往上,所以不能用后序,如果他要求从上往下,从右往左,那可以将先序的遍历顺序变为“根右左”即可。
- 层次遍历的打印可以基于队列或者先序遍历来实现。
16. JZ86 在二叉树中找到两个节点的最近公共祖先

1. 路径搜索法,DFS
和T8一样,可以使用vector来记录路径,使用DFS来搜索,满足条件的话就找到一条路径,两条都找到之后,比较最后一个相同的元素即为最近的公共父节点。
class Solution {
public:
/**
*
* @param root TreeNode类
* @param o1 int整型
* @param o2 int整型
* @return int整型
*/
//根据之前一题的启发,找到两个节点的路径,找到最后一个相同的即为结果,普通二叉树没有左<根<右的结论,所以目前这样做。
vector<int> TmpPath1{};
vector<int> TmpPath2{};
vector<int> path1{};
vector<int> path2{};
//dfs搜索出目标值的路径
void getpath(TreeNode* root, int val, vector<int>& TmpPath, vector<int>& path)
{
if(root==nullptr) return;
TmpPath.push_back(root->val);
if(root->val==val){
path = TmpPath;
return;
}
if(path.size()==0)
{
getpath(root->left, val, TmpPath, path);
getpath(root->right, val, TmpPath, path);
TmpPath.pop_back();
}
else return;
}
int lowestCommonAncestor(TreeNode* root, int o1, int o2) {
// write code here
getpath(root, o1, TmpPath1, path1);
getpath(root, o2, TmpPath2, path2);
int res;
for(size_t i=0; i<path1.size(); ++i)
{
if(path1[i]!=path2[i]) return path1[i-1];
if(i==path1.size()-1) return path1[path1.size()-1];
}
return -1;
}
};
2. 官方分析法,递归
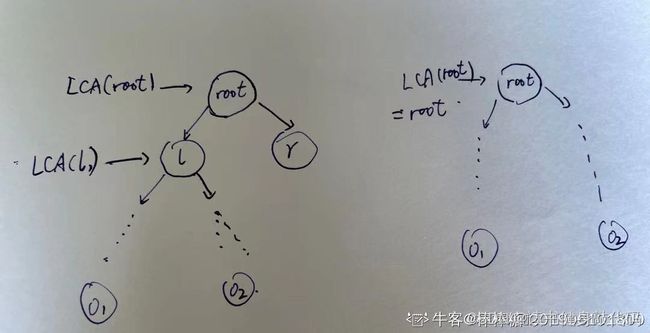
分析:
- 如果o1和o2都在root的左子树中,那么LCA(root, o1, o2) = LCA(root->left, o1, o2).
- 如果o1和o2都在root的右子树中,那么LCA(root, o1, o2) = LCA(root->right, o1, o2).
- 如果一个在左子树,一个在右子树,显然root就是答案!
如果左右子树有一个为空,那么必定在对方的结果中,如果是一左一右的结果,那么这个节点本身就是结果。
class Solution {
public:
/**
*
* @param root TreeNode类
* @param o1 int整型
* @param o2 int整型
* @return int整型
*/
TreeNode* LCA(TreeNode* r, int o1, int o2) {
if (!r) return NULL;
if (r->val == o1 || r->val == o2) return r;
TreeNode* ln = LCA(r->left, o1, o2); //在左子树中找o1或者o2,如果找到其中一个就不返回nullptr;如果找不到就返回nullptr,说明o1和o2都在右边
TreeNode* rn = LCA(r->right, o1, o2);
if (ln=nullptr) return rn; //如果左边两个都没找到,就返回右子树的结果,结果是o1或者o2其中一个,而且是先被找到的那个,那么一定就是公共节点
if (rn=nullptr) return ln;
return r;
}
int lowestCommonAncestor(TreeNode* root, int o1, int o2) {
TreeNode* lca = LCA(root, o1, o2);
return lca->val;
}
};
3. 本题小结
- 对于寻找最近公共父节点思路有两个,
- 求出对应结点的路径然后比较找出最后一个相同的即为结果;
- 使用递归,递归左右子树,对于普通二叉树(本题),左没找到肯定在右,如果一左一右,该节点即为结果。对于二叉搜索树(T8),由于知道大小,满足下列条件即为结果.
if( ((root->val >= p) && (root->val <= q)) || (root->val <= p) && (root->val >= q) )
return root->val;
17. JZ84 二叉树中和为某一值的路径(三)

1. 自己的分治法
自己的分治法没有成功,原因是对于负数结点无法处理。
思路:先从根节点开始进行DFS,把所有的从根节点到叶子结点的路径全部求出来,然后分别对每条路径使用分治法来搜索,思想是将路径等分为二份,在左右两边分别找和与sum的差的绝对值最小的路径,如果找到差为0的路径就证明找到了一条,此时++res,分别对左右递归调用分治法,最后返回最终的res,但是这种思路无法处理负数结点,如下图的蓝色路径无法通过分治法找到,目标和为6,第一遍左侧找到2,右侧找到5,合起来最终找到5,所以判断找不到,但是实际上[2, 5, -1]是满足的。

//改进的方法:仍然使用DFS求出每条路径,但是使用分治法来求符合长度的路径,O(n*log(n))的时间复杂度
//分治法
//返回差值的绝对值、左下标、右下标
vector<int> devide_conquer(vector<int> path, int& sum, int& res)
{
//先分再治,处理大于1,等于1的情况
//等于1个结点
if(path.size()==1)
{
if(path[0]==sum)
++res;
return vector<int>{path[0], 0, 0};
}
//多于一个节点的情况
else
{
//分:划分左右段,递归求左右段的与sum差的绝对值最小的段的下标
size_t sub1_size = path.size()/2;
size_t sub2_size = path.size()-sub1_size;
vector<int> sub1(path.begin(), path.begin()+sub1_size);
vector<int> sub2(path.begin()+sub1_size, path.end());
int LDiff = INT_MAX;
int RDiff = INT_MAX;
vector<int> left_margin{};
vector<int> right_margin{};
int TmpLMargin = -1;
int TmpRMargin = -1;
vector<int> ret_vec{};
int TmpLSum = 0 ; //临时累加的变量
int TmpRSum = 0 ;
int LSum = 0; //记录左侧无符合时的最小差的边界
int RSum = 0;
vector<int> sub1_vec; //左右子列的递归结果
vector<int> sub2_vec;
//治
if(sub1.size()>0) sub1_vec = devide_conquer(sub1, sum, res); //递归
if(sub2.size()>0) sub2_vec = devide_conquer(sub2, sum, res);
//求出跨分界线的连续的最接近sum的段
//往左搜索
for(int i=sub1_size-1; i>=0; --i)
{
TmpLSum += path[i];
int ThisDiff = abs(TmpLSum-sum);
if(ThisDiff == 0)
{
++res;
LSum = TmpLSum;
left_margin.push_back(i);
}
else if(ThisDiff < LDiff)
{
LDiff = ThisDiff; //更新左侧最小差绝对值
LSum = TmpLSum; //更新最小差绝对值对应的和
TmpLMargin = i;
}
}
//往右搜索
for(int i=sub1_size; i!=path.size(); ++i)
{
TmpRSum += path[i];
int ThisDiff = abs(TmpRSum-sum);
if(ThisDiff == 0)
{
++res;
RSum = TmpRSum;
right_margin.push_back(i);
}
else if(ThisDiff < RDiff)
{
RDiff = ThisDiff; //更新左侧最小差绝对值
RSum = TmpRSum; //更新最小差绝对值对应的和
TmpRMargin = i;
}
}
//两边都没找到匹配的路径
if(left_margin.size()==0 && right_margin.size()==0) //都没找到
{
int Cross_sum = LSum + RSum;
ret_vec.push_back(Cross_sum);
ret_vec.push_back(TmpLMargin);
ret_vec.push_back(TmpRMargin);
}
else if(left_margin.size()==0 && right_margin.size()!=0) //右边找到
{
ret_vec.push_back(0);
ret_vec.push_back(sub1_size);
ret_vec.push_back(TmpRMargin);
}
else if(left_margin.size()!=0 && right_margin.size()==0) //左边找到
{
ret_vec.push_back(0);
ret_vec.push_back(TmpLMargin);
ret_vec.push_back(sub1_size-1);
}
else if(left_margin.size()!=0 && right_margin.size()!=0) //都找到
{
ret_vec.push_back(0);
for(int i=0; i<left_margin.size(); ++i)
for(int j=0; i<right_margin.size(); ++j)
{
ret_vec.push_back(left_margin[i]);
ret_vec.push_back(right_margin[j]);
}
}
//和递归的结果比较
int sub1_diff = abs(sub1_vec[0]-sum);
int sub2_diff = abs(sub2_vec[0]-sum);
int cross_diff = abs(ret_vec[0]-sum);
if(sub1_diff==0)
for(auto it=sub1_vec.begin()+1; it!=sub1_vec.end(); ++it)
ret_vec.push_back(*it);
if(sub2_diff==0)
for(auto it=sub2_vec.begin()+1; it!=sub2_vec.end(); ++it)
ret_vec.push_back(*it);
if(sub1_diff<cross_diff)
{
ret_vec.clear();
ret_vec = sub1_vec;
cross_diff = abs(ret_vec[0]-sum);
}
if(sub2_diff<cross_diff)
{
ret_vec.clear();
ret_vec = sub2_vec;
}
return ret_vec;
}
}
void dfs(TreeNode* root, vector<int>& path, vector<vector<int>>& vec)
{
if(root==nullptr) return;
path.push_back(root->val);
if(root->left==nullptr && root->right==nullptr)
vec.push_back(path);
dfs(root->left, path, vec);
dfs(root->right, path, vec);
path.pop_back();
}
int FindPath(TreeNode* root, int sum) {
// write code here
vector<int> path;
vector<vector<int>> AllPath;
int res=0;
dfs(root, path, AllPath);
for(auto each:AllPath)
devide_conquer(each, sum, res);
std::cout<<res<<std::endl;
return res;
}
};
2. 官方递归(单、双递归,推荐)
思路:先序遍历树以保证每个节点都被访问到,遍历时对每个根节点进行DFS,过程中每遇到一个节点就-sum值,判断是否为0,如果为0则找到一条。

时间复杂度 O ( N 2 ) O(N^2) O(N2),对每个结点都及逆行DFS,每个DFS又时 O ( N ) O(N) O(N),空间复杂度 O ( N ) O(N) O(N), N N N为节点个数。
双递归:
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @param sum int整型
* @return int整型
*/
int res=0;
void dfs(TreeNode* root, int sum, int& res)
{
if(root==nullptr) return;
if(sum-root->val==0)
++res;
dfs(root->left, sum-root->val, res);
dfs(root->right, sum-root->val, res);
}
//先序遍历这棵树
int FindPath(TreeNode* root, int sum) {
if(root==nullptr) return 0;
dfs(root, sum, res);
FindPath(root->left, sum);
FindPath(root->right, sum);
return res;
}
};
单递归:
// 先序遍历树,遍历时对每个根节点进行DFS,过程中每遇到一个节点就-sum值,判断是否为0,如果为0则找到一条。
void dfs(TreeNode* root, int sum, int& res)
{
if(root==nullptr) return;
sum -= root->val;
if(sum==0) ++res;
dfs(root->left, sum, res);
dfs(root->right, sum, res);
}
//先序遍历这棵树
int FindPath(TreeNode* root, int sum) {
// write code here
if(root==nullptr) return 0;
int res=0;
stack<TreeNode*> sta;
while(!sta.empty() || root)
{
while(root) //先序遍历一定要左到底再往右
{
sta.push(root);
dfs(root, sum, res);
root = root->left;
}
TreeNode* TmpNode = sta.top();
sta.pop();
root = TmpNode->right;
}
return res;
}
};
如果需要记录路径则在每个dfs内记录即可,不要忘了pop_back
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @param sum int整型
* @return int整型
*/
int res=0;
vector<int> path;
vector<vector<int>> Res;
void dfs(TreeNode* root, int sum, int& res)
{
if(root==nullptr) return;
path.push_back(root->val);
if(sum-root->val==0){
++res;
Res.push_back(path);
}
dfs(root->left, sum-root->val, res);
dfs(root->right, sum-root->val, res);
path.pop_back();
}
//先序遍历这棵树
int FindPath(TreeNode* root, int sum) {
if(root==nullptr) return 0;
stack<TreeNode*> sta;
sta.push(root);
while(!sta.empty())
{
TreeNode* TmpNode = sta.top();
sta.pop();
dfs(TmpNode, sum, res);
if(TmpNode->left) sta.push(TmpNode->left);
if(TmpNode->right) sta.push(TmpNode->right);
}
return res;
}
};
3. 官方分析法(虽然巧妙,但是不易理解)

这里不好理解,用个图来说明

target sum=4,到4的分支时和为7,7-4=3,前面有两条,由左图可以看出,何为7的有一个,从根节点到和为3的由map得有两个,那么自然和为4的也就有两个了。
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @param sum int整型
* @return int整型
*/
map<int, int> mp;
void PreTravel(TreeNode* root, int tmpsum, const int& sum, int& res)
{
if(root)
{
//根
tmpsum += root->val;
//如果与sum的差之前出现过,说明路径找到
if(mp.count(tmpsum-sum)!=0)
res += mp[tmpsum-sum];
++mp[tmpsum]; //必须要在处理完res之后才能++
//左
PreTravel(root->left, tmpsum, sum, res);
//右
PreTravel(root->right, tmpsum, sum, res);
//回退该路径和,因为别的树枝不需要这边存的路径和
--mp[tmpsum];
}
}
//先序遍历这棵树
int FindPath(TreeNode* root, int sum) {
if(root==nullptr) return 0;
int res=0;
mp[0] = 1; //勿漏
PreTravel(root, 0, sum, res);
return res;
}
};
4. 和为某值的路径小结
-
类似的题:T12,T13,T17
如果求到叶子结点的路径是否存在,可以先序递归相减,到叶子节点和为0即存在。如果要求路径就维护一个vector,使用dfs,回溯时pop_back(),如果像本题的求任意起点开始路径和为某值的,两种思路:1. 先序遍历套每个节点的dfs 2. 使用本题3的哈希法。 -
另外,map可以直接++map[key]来递增不存在的键值

-
MAX_INT或者INT_MAX表示最大整数。
4. DFS小结
- 实际上DFS和先序遍历很相似,但是先序遍历是严格根左右,是要左到底再转右,而dfs可以不严格按照这个顺序,只要按照递归或者栈的方式把所有的到叶子节点的路径走完一遍即可。
- 简记为先序后推,DFS先推(入栈)
非递归先序遍历:
//非递归先序遍历
void PreNoRecursionTravel(TreeNode* proot)
{
cout<<endl<<"非递归先序"<<endl;
if(proot==nullptr) return;
stack<TreeNode*> sta;
TreeNode* root = proot;
while(!sta.empty() || root)
{
//左节点一直往下到底,第一次
while(root)
{
std::cout<<root->val<<" ";
sta.push(root); //先序后推入栈
root=root->left;
}
//倒地之后转向右节点,第二次
TreeNode* TmpNode = sta.top();
sta.pop();
root = TmpNode->right;
}
}
非递归DFS,和层序遍历的队列很像,出一个,处理,进左右
int FindPath(TreeNode* root, int sum) {
if(root==nullptr) return 0;
stack<TreeNode*> sta;
sta.push(root); //dfs先推入栈
while(!sta.empty())
{
//根节点处理
TreeNode* TmpNode = sta.top();
sta.pop();
dfs(TmpNode, sum, res); //这也是属于根节点的处理,只不过这里的处理是再进行一次dfs
if(TmpNode->left) sta.push(TmpNode->left);
if(TmpNode->right) sta.push(TmpNode->right);
}
return res;
}
18. JZ36 二叉搜索树与双向链表
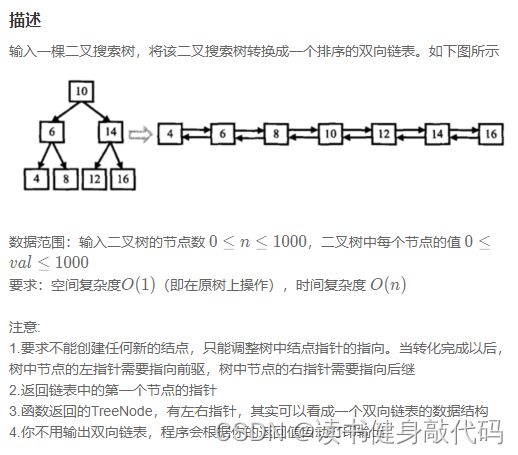
题目里说要在原树上进行操作可以理解,但是空间复杂度为 O ( 1 ) O(1) O(1)有些办不到,无论是递归还是非递归,都是要借助额外的空间的。
1. 递归中序遍历
思路:二叉搜索树左<根<右,所以其中序遍历出来就是升序排列的,递归中序遍历,管理一个结果指针和前一个结点的指针,依次翻转指向即可。
class Solution {
public:
void MidTravel(TreeNode* root, TreeNode*& res, TreeNode*& pre)
{
if(root)
{
//到最左侧
MidTravel(root->left, res, pre);
if(res==nullptr)
{
res = root;
pre = root;
}
else{
//根节点处理
pre->right = root;
root->left = pre;
pre = root;
}
//右
MidTravel(root->right, res, pre);
}
}
TreeNode* Convert(TreeNode* pRootOfTree) {
TreeNode* res(nullptr);
TreeNode* pre(nullptr);
MidTravel(pRootOfTree, res, pre);
return res;
}
};
2. 非递归中序遍历
逻辑一样,非递归使用栈,中序遍历左边走到底,根节点处进行操作。
class Solution {
public:
TreeNode* Convert(TreeNode* pRootOfTree) {
if(pRootOfTree==nullptr) return nullptr;
TreeNode* res(nullptr);
TreeNode* pre(nullptr);
TreeNode* root = pRootOfTree;
stack<TreeNode*> sta;
while(!sta.empty() || root){
//第一次
while(root){
sta.push(root);
root = root->left;
}
//第二次
TreeNode* TmpNode = sta.top();
if(pre==nullptr){
res = TmpNode;
pre = TmpNode;
}
else{
pre->right = TmpNode;
TmpNode->left = pre;
pre = TmpNode;
}
sta.pop();
root = TmpNode->right;
}
return res;
}
};
3. 本题小结
- 中序遍历二叉搜索树出来就是升序序列,管理上一个遍历的结点指针来交换前一个和后一个的指针指向即可。
19. JZ37 序列化二叉树(难)
1. 自己的层序遍历
还未实现,因为不知道如何处理用char存储多位数,实际上要借助string类。
class Solution {
public:
#define MAX_SIZE 100
int TreeDepth(TreeNode* root){
if(root==nullptr) return 0;
return max(TreeDepth(root->left), TreeDepth(root->right))+1;
}
//层序遍历保存所有结点为str
char* Serialize(TreeNode *root) {
if(root==nullptr) return nullptr;
char* res=nullptr;
queue<TreeNode*> que;
que.push(root);
vector<int> vec;
int Layer= TreeDepth(root); //获取二叉树深度
int NextLayer = 1;
char Ser[MAX_SIZE] = {}; //必须是常量表达式
while(!que.empty()){
if(NextLayer<=Layer){
for(int i=0; i<pow(2, NextLayer-1); ++i){
TreeNode* TmpNode = que.front();
que.pop();
vec.push_back(TmpNode->val);
//空结点也推入
que.push(TmpNode->left);
que.push(TmpNode->right);
}
}
++NextLayer;
}
for(int i=0; i<vec.size(); ++i)
Ser[i] = (char)vec[i];
res = Ser;
for(auto each:Ser)
cout<<each<<" ";
return res;
}
//满二叉树来重建二叉树 char*不能使用下标来进行操作,因为是单纯的字符指针,而不是数组指针
TreeNode* Deserialize(char *str) {
if(str==nullptr) return nullptr;
return nullptr;
// for(int i=0; i*2
// {
// int child_idx = i*2;
// }
}
};
2. 官方先序遍历(推荐)

这里反序列化的函数传入的是char类型的二重指针,第一次传入的时候这个地址是按照str的一系列字符串连续排列的,但是当递归之后,传的是指针值相同单指针地址不同的临时指针。
当你想改编一个指针的值时,把指针看做一个变量,改变这个变量的值就只能传递这个变量的地址或者这个变量的引用。传值就传递这个指针的地址,就成了二重指针。传递一重指针改变的是指针指向的内存的值,没有改变指针的指向。
递归之后,如果传的是一重指针,那么实际上传的是指针值,指针的值不变,但在递归中会构造的临时指针,指针值不变,但是指针的地址会改变,如果想避免二重指针的操作,可以传指针的引用,每次传的都是同一个地址的指针的值,不会再临时构建一个指针值相同但指针地址不同的临时指针了。
class Solution {
public:
//处理序列化的功能函数(递归)
void SerializeFunction(TreeNode* root, string& str){
//如果指针为空,表示左子节点或右子节点为空,用#表示
if(root == NULL){
str += '#';
return;
}
//根节点
string temp = to_string(root->val);
str += temp + '!';// 加!,区分节点
//左子树
SerializeFunction(root->left, str);
//右子树
SerializeFunction(root->right, str);
}
char* Serialize(TreeNode *root) {
//处理空树
if(root == NULL)
return "#";
string res;
SerializeFunction(root, res);
//把str转换成char
char* charRes = new char[res.length() + 1];
strcpy(charRes, res.c_str());
charRes[res.length()] = '\0';
return charRes;
}
//处理反序列化的功能函数(递归)
TreeNode* DeserializeFunction(char** str){
//到达叶节点时,构建完毕,返回继续构建父节点
//双**表示取值
if(**str == '#'){
(*str)++;
return NULL;
}
//数字转换
int val = 0;
while(**str != '!' && **str != '\0'){
val = val * 10 + ((**str) - '0');
(*str)++;
}
TreeNode* root = new TreeNode(val);
//序列到底了,构建完成
if(**str == '\0')
return root;
else
(*str)++;
//反序列化与序列化一致,都是前序
root->left = DeserializeFunction(str);
root->right = DeserializeFunction(str);
return root;
}
TreeNode* Deserialize(char *str) {
//空序列对应空树
if(str == "#"){
return NULL;
}
TreeNode* res = DeserializeFunction(&str);
return res;
}
};
下面是传指针的引用来避免二重指针的反序列化函数:
class Solution {
public:
//处理序列化的功能函数(先序递归)
void SerializeFunction(TreeNode* root, string& str){
if(root==nullptr){
str +='#';
return;
}
string temp = to_string(root->val); //转换成string存储,用!来分割
str+=temp + '!'; //!来在string中区分结点值
//左子树
SerializeFunction(root->left, str);
//右子树
SerializeFunction(root->right, str);
}
char* Serialize(TreeNode *root) {
//处理空树
if(root==nullptr) return "#";
string res;
//先序递归树,因为不用层序遍历,所以不用要求是满二叉树
SerializeFunction(root, res);
//把str转换成char
char* charRes = new char[res.length()+1];
strcpy(charRes, res.c_str()); //必须使用strcpy来操作c_str()返回的指针,否则res对象被析构之后,charRes的指向就不可控了
charRes[res.length()] = '\0';
return charRes;
}
//处理反序列化的功能函数(递归)
TreeNode* DeserializeFunction(char*& str) //指针的引用,避免二重指针
{
//到达叶节点时,构建完毕,返回继续构建父节点
//双**表示取值
if(*str=='#'){
(str)++;
return nullptr;
}
//处理根节点
//数字转换
int val = 0;
while(*str!='!' && *str!='\0'){
val = val * 10 + ((*str)-'0'); //处理个、十、百位
(str)++;
}
TreeNode* root = new TreeNode(val); //实例化一个树结点
//序列到底了,构建完成
if(*str=='\0')
return root;
else(str)++;
//递归左子树
//这里如果不使用二重指针的话,可以使用指针的引用,如果不传引用也不传二重指针,而是只传一重指针,实际上传的是指针的值,但是指针的地址会改变,
//如果改变的话,指针的地址就不是字符串那样连续的了。
root->left = DeserializeFunction(str);
root->right = DeserializeFunction(str);
return root;
}
TreeNode* Deserialize(char *str) {
//空序列对应空树
if(str == "#"){
return NULL;
}
TreeNode* res = DeserializeFunction(str); //传递指针的引用
return res;
}
};
3. 本题小结(字符串,二重指针==一重指针的引用)
- 由于C中没有string类,只有char*,所以将C++中的string变为C风格的char需要借助c_str()函数,参考博客:C++中c_str()函数的用法
一定要使用strcpy()等函数来操作c_str()返回的指针。
如果一个函数要求char参数,可以使用c_str()方法。
char *cstr,*p;
string str ("Please split this phrase into tokens");
cstr = new char [str.size()+1];
strcpy (cstr, str.c_str());
- 传递二重指针==一重指针的引用。
当你想改编一个指针的值时,把指针看做一个变量,改变这个变量的值就只能传递这个变量的地址或者这个变量的引用。传值就传递这个指针的地址,就成了二重指针。传递一重指针改变的是指针指向的内存的值,没有改变指针的指向。
递归之后,如果传的是一重指针,那么实际上传的是指针值,指针的值不变,但在递归中会构造的临时指针,指针值不变,但是指针的地址会改变,如果想避免二重指针的操作,可以传指针的引用,每次传的都是同一个地址的指针的值,不会再临时构建一个指针值相同但指针地址不同的临时指针了。