JuiceFS 目录配额功能设计详解
JuiceFS 在最近 v1.1 版本中加入了社区中呼声已久的目录配额功能。已发布的命令支持为目录设置配额、获取目录配额信息、列出所有目录配额等。完整的详细信息,请查阅文档。
在设计此功能时,对于它的统计准确性,实效性以及对性能的影响,团队内部经历过多次讨论和权衡。在本文中,我们会详述一些在设计关键功能时的不同抉择及其优缺点,并分享最终的实现方案,为想深入了解目录配额或有相似开发需求的用户提供参考。
01 需求分析
配额的设计首先需考虑以下三个要素:
-
统计的维度:常见的是基于目录来统计用量和实现限制,其他还有基于用户和用户组的统计
-
统计的资源:一般包括文件总容量和文件总数量
-
限制的方式:最简单的就是当使用量达到预定值时,就不让应用继续写入。这种预定值一般称为硬阈值(Hard Limit)。还有一种常见的限制叫做软阈值(Soft Limit),在使用量达到这个值时,仅触发告警通知但不立即限制写入,而是在达到硬阈值或者经过一定的宽限时间(Grace Period)后再实施限制。
其次,也应考虑对配额统计实效性和准确性的要求。在分布式系统中,往往会有多个客户端同时访问,若要保证他们在同一时间点对配额的视图始终一致,势必会对性能有比较大的影响。最后,还应考虑是否支持复杂的配置,如配额嵌套、为非空目录设置配额等。
开发原则
我们的主要考量是尽量简单和便于管理。在实现时避免大规模代码重构,减少对关键读写路径的侵入,以期在实现新特性的同时,不会对现有系统的稳定性和性能造成较大影响。基于此,我们整理出了如下表所示的待开发功能:
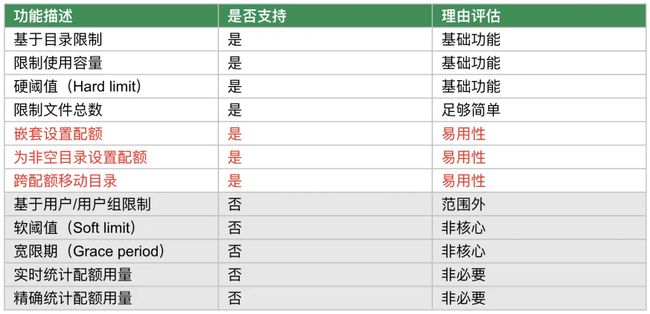
值得一提的是表中标红的三项。一开始我们并不打算支持这些,因为它们的复杂性对配额功能的整体实现构成了挑战,而且也不在我们定义的核心功能之列。但在与多方用户沟通后,我们意识到缺少这些功能会导致配额功能的实用性大打折扣,许多用户确实需要这些功能来满足他们的实际需求。因此,最终我们还是决定在 v1.1 版本中就带入这些功能。
02 基础功能
1 用户接口
在设计配额功能时,首先要考虑的是用户如何设置和管理配额。这一般有两种方式:
1.使用特定的命令行工具,如 GlusterFS 使用以下命令为指定目录设置硬阈值:
$ gluster volume quota <VOLNAME> limit-usage <DIR> <HARD_LIMIT>
2.借助已有的 Linux 工具,但使用特定的字段;如 CephFS 将配额作为一项特殊的扩展属性来管理:
$ setfattr -n ceph.quota.max_bytes -v 100000000 /some/dir # 100 MB
JuiceFS 采用了第一种方式,命令形式为:
$ juicefs quota set <METAURL> --path <PATH> --capacity <LIMIT> --inodes <LIMIT>
做出这个选择主要有以下三点理由:
-
JuiceFS 已有现成的 CLI 工具,要添加配额管理功能只需新加一个子命令即可,非常方便。
-
配额通常应由管理员来进行配置,普通用户不能随意更改;自定义的命令中可要求提供 METAURL 来保证权限。
-
第二种方式需要提前将文件系统挂载到本地。配额设置常需对接管控平台,将目录路径作为参数直接包含在命令中可以避免此步骤,使用起来更加方便。
2 元数据结构
JuiceFS 支持三大类元数据引擎,包括 Redis,SQL 类(MySQL、PostgreSQL、SQLite 等)和 TKV 类(TiKV、FoundationDB、BadgerDB 等)。每类引擎根据其支持的数据结构有不同的具体实现,但管理的信息大体上是一致的。在上一小节我们已决定使用独立的 juicefs quota 命令来管理配额,那么元数据引擎中也同样使用独立的字段来存储相关信息。以较简单的 SQL 类为例:
// SQL table
type dirQuota struct {
Inode Ino `xorm:”pk”`
MaxSpace int64 `xorm:”notnull”`
MaxInodes int64 `xorm:”notnull”`
UsedSpace int64 `xorm:”notnull”`
UsedInodes int64 `xorm:”notnull”`
}
可见,JuiceFS 为目录配额新建了一张表,以目录索引号(Inode)为主键,保存了配额中容量和文件数的阈值以及已使用值。
3 配额更新/检查
接下来考虑配额信息的维护,主要是两个任务:更新和检查。
更新配额通常牵涉到新建和删除文件或目录,这些操作都会对文件个数产生影响。此外,文件的写入操作会对配额的使用容量产生影响。实现上最直接的方式是在每个请求完成更新后,同时将更改提交到数据库。这可以确保统计信息的实时性和准确性,但很容易造成严重的元数据事务冲突。
究其原因,是因为在 JuiceFS 的架构中,没有独立的元数据服务进程,而是由多个客户端以乐观事务的形式并发将修改提交到元数据引擎。一旦它们在短时间内尝试更改同一个字段(比如配额的使用量),就会引发严重的冲突。
因此,JuiceFS 的做法是在每个客户端内存中同步维护配额相关的缓存,并将本地更新每隔 3 秒异步地提交到数据库。这样做牺牲了一定的实时性,但可以有效减少请求个数和事务冲突。此外,客户端在每个心跳周期(默认 12 秒)从元数据引擎加载最新信息,包括配额阈值和使用量,以了解文件系统全局的情况。
配额检查与更新类似,但更为简单。在执行操作之前,如有必要客户端可直接在内存中进行同步检查,并在检查通过后才继续后面的流程。
03 复杂功能设计
本章讨论目录配额中相对复杂的两个功能(即第一章需求表中标红项)的设计思路。
功能1:配额嵌套
在与用户进行沟通时,我们经常面临这样的需求:某个部门设置了一个大型的配额,但在该部门内部可能还有小组或个人,而这些个体也需要各自的配额。
这里就需要对配额增加嵌套结构。如果不考虑嵌套,每个目录只有两种状态:没有配额或者只受一个配额限制,整体维护比较简单。一旦引入嵌套结构,情况就会变得相对复杂。例如,在更新文件时,我们需要找到所有受影响的配额并对其进行检查或更改。那么在给定目录后,如何快速找到其所有受影响的配额呢?
方案一:缓存 Quota 树以及目录到最近 Quota 的映射

这个方案比较简单直接,即维护配额间相互的嵌套结构,以及每个目录到最近配额的映射信息。针对上图的数据结构如下:
// quotaTree map[quotaID]quotaID
{q1: 0, q2:0, q3: q1}
// dirQuotas map[Inode]quotaID
{d1: q1, d3: q1, d4: q1, d6: q3, d2: q2, d5: q2}
有了这些信息,在配额更新或查找时,我们可以根据操作的目录 Inode 快速找到最近的配额 ID,再根据 quotaTree 逐级找到所有受影响的配额。这个方案能实现高效的查找,从静态角度来看,是有优势的。然而,某些动态变化会难以处理。考虑如下图所示场景:
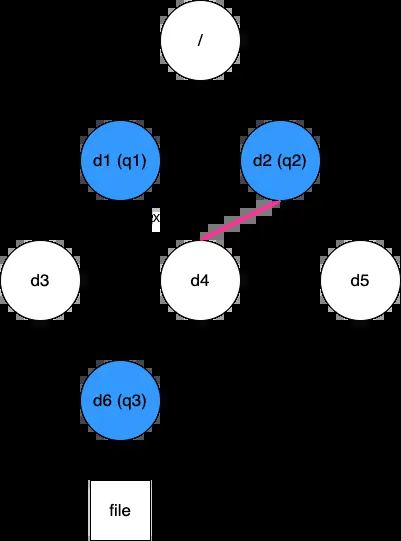
现在需要将目录 d4 从原来的 d1 移动到 d2 下。这个操作中 q3 的父配额从 q1 变成了 q2,但由于 q3 被配置在 d6 上,这个变化很难被感知到(我们可以在移动 d4 的同时遍历其下所有目录看它们是否有配额,但显然这会是个大工程)。鉴于此,这个方案并不可取。
方案二:缓存目录到父目录的映射关系

第二个方案是缓存所有目录到其父目录的映射关系,针对上图的初始数据结构如下:
// dirParent map[Inode]Inode
{d1: 1, d3: d1, d4: d1, d6: d4, d2: 1, d5: d2}
同样的修改操作,这时仅需将 d4 的值由 d1 改成 d2 即可。此方案中,在查找某个目录所有受影响的配额时,我们需要根据 dirParent 逐级往上直到根目录,在过程中检查每个路过的目录是否设置了配额。显然,这个方案的查找效率相比之前的方案略低。但好在这些信息都缓存在客户端内存中,整体效率依然在可接受范围内,因此我们最终采用了这个方案。
值得一提的是,这个目录到父目录的映射关系是常驻客户端内存的,没有设置特定的过期策略,这主要有两个角度的考虑:
-
通常情况下,文件系统的目录数量不会非常大,仅用少量内存即可将其全部缓存起来。
-
其他客户端对目录的更改,在本客户端中并不需要立即感知;当本客户端再次访问相关目录时,会通过内核下发的查找(Lookup)或读取目录(Readdir)请求更新缓存。
功能2:递归统计
在需求分析阶段,除了嵌套配额外,还出现了两个相关的问题:一是为非空目录设置配额,二是目录移动之后产生配额变化。这两个问题其实本质上是同一个,那就是 “如何快速地获取某个目录树的统计信息”。

方案一:默认为每个目录添加递归统计信息
这个方案有点像前面的配额嵌套功能,只是现在需要为每个目录都加上递归统计信息,数量上会比配额多不少。它的好处是使用时比较方便,仅需一次查询就能立即知道指定目录下整棵树的大小。这个方案的代价是维护成本较高,在修改任一文件时,都需要逐级往上修改每个目录的递归统计信息。这样越靠近根节点的目录被修改的越频繁。JuiceFS 的元数据实现均采用乐观锁机制,即在发现冲突时通过重试来解决,在高压力情况下,部分目录的修改事务会冲突得非常严重。而且随着集群规模的扩大,频繁重试还会导致元数据引擎压力急剧上升,容易导致崩溃。
方案二:平时不干预,只有在需要时,才对指定目录树进行临时扫描
这是一个很简单而直接的方案。其问题在于当目录下的文件数量庞大时,临时扫描可能会耗时非常久。同时,这也会对元数据引擎产生很高的爆发压力。因此,这个方案也不适合拿来直接使用。
方案三:平时只维护每个目录下一级子项的使用量,需要时扫描指定树下所有目录

这个方案结合了前两个方案的优点,并尽力避免了它们的缺点。在进一步说明前首先介绍两个文件系统中的现象:
-
在处理大部分元数据请求时,其本身就带有直接父目录的信息,因此不需要额外的操作去获取,也不会引入额外的事务冲突
-
通常情况下,文件系统中目录数量会比普通文件少 2 ~ 3 个数量级
基于上述两点观察,JuiceFS 实现了称之为目录统计的功能,即在平时就维护好每一个目录下一级子项的统计量。当配额功能需要使用递归统计信息时,无需遍历所有文件,而只需统计所有子目录的使用量即可。这也是 JuiceFS 最终采用的方案。
另外,在加入了目录统计功能后,我们还发现了一些额外的好处。比如原本就有的 juicefs info -r 命令,被用来代替 du 统计指定目录下的使用总量;现在这个命令的执行速度又有了数量级上的提升。还有一个是新加的 juicefs summary 命令,它可用来快速分析指定目录下的具体使用情况,如执行特定排序来找到已用容量最高的子目录等。
04 其他功能 :配额修复
在上述的介绍中,我们已经知道 JuiceFS 在实现目录配额时,为了追求稳定性和减少对性能的影响,在一定程度上牺牲了准确性。当客户端进程异常退出,或目录被频繁移动时,配额信息会有少量的丢失。随着时间的推移,这可能导致存储的配额统计值与实际情况出现较大的偏差。
因此,JuiceFS 还提供了 juicefs check 这个修复功能。它被用来重新扫描统计整棵目录树,并将结果与配额中保存的值做比对。如果发现数据不匹配,系统会向您报告存在的问题,并提供可选的修复选项。
希望这篇内容能够对你有一些帮助,如果有其他疑问欢迎加入 JuiceFS 社区与大家共同交流。