数据分析实用工具——EXCEL下的power query自动取数
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、power query
- 二、实用功能
-
- 1.选择数据源
- 2.数据格式处理
- 3.进阶数据处理
- 4.自动取数的路径问题
- 总结
前言
说到数据分析工具,大家第一时间可能会想到excel、python、sql、powerbi 、tableau等等,但第一印象里并没有power query。这是因为power query 并不是一个独立的数据处理软件。但他确实是一个好用的,能提高数据处理效率的工具。
一、power query
Power query是微软从Excel 到 PowerBI 的中间产物,它既是PowerBi取数部分的内核,又能够在Excel中使用。 在excel中使用Power query处理数据的能力要高出用excel本身处理数据的性能数倍。power query的操作方法不仅有图形化界面,也有它自己独立的语言:M。power query是excel2016及之后的版本所拥有的功能
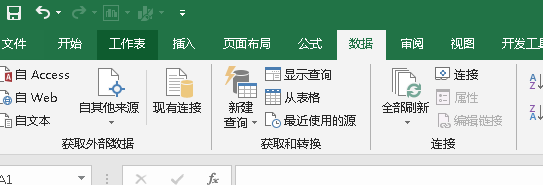
它的位置就在excel中数据一栏下的“获取和转换一栏”
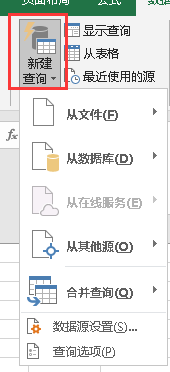

它可获取数据的渠道非常多,不仅可以从普通的表格、文本、XML或是文件夹中获取数据,
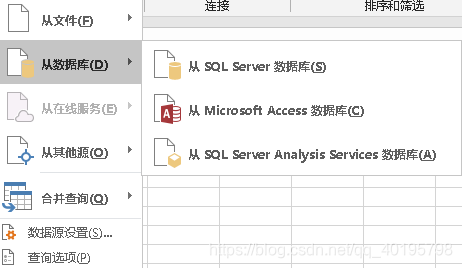
也可以从ACESS、SQLserver数据库中获取
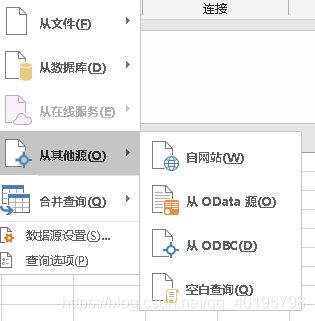
甚至可以通过OData链接开放数据接口,或是通过ODBC连接其他开放数据库如Mysql、Orcle。
启动powerquery编辑器,我们就可以看到power query的图形化界面。
在PowerBI中的功能更加强大,可获取的数据来源更多

如图左边是Power BI,右边是excel,我们可以看出两个并无明显差异,因为其本质相同,使用方法也大同小异。
二、实用功能
为什么说power query是一个实用工具呢,从上面的数据获取来源,我们可以知道,power query是可以从文件夹中获取数据的。而文件夹是用来存放多个文件的。这就代表着我们可以通过power query来快速将一个文件夹中的多张表的数据进行整合。不仅如此,它还可以批量的处理表格格式。例如我们的有多张表,那必然每张表都有自己的表头,如果仅是把表合在一起,那么每一定行的数据中都会掺杂一个表头。而通过power query,我们可以仅通过对一张表进行格式编辑,它就会批量处理剩下的表格。
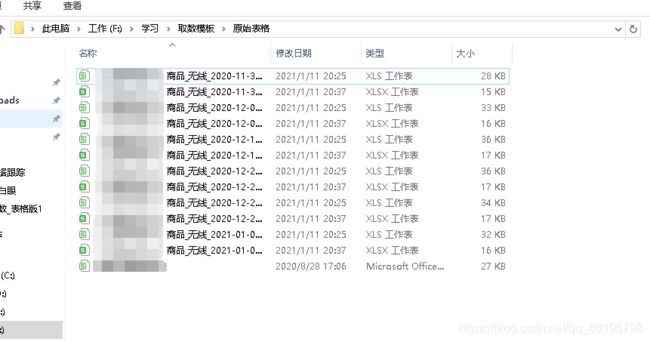
可以看到,在这个文件夹下有着多个表格数据。如何将这些数据快速、自动的进行汇总处理呢?
1.选择数据源
首先新建一个数据表正常的Xlsx格式。

在新建查询中选择从文件夹获取数据。
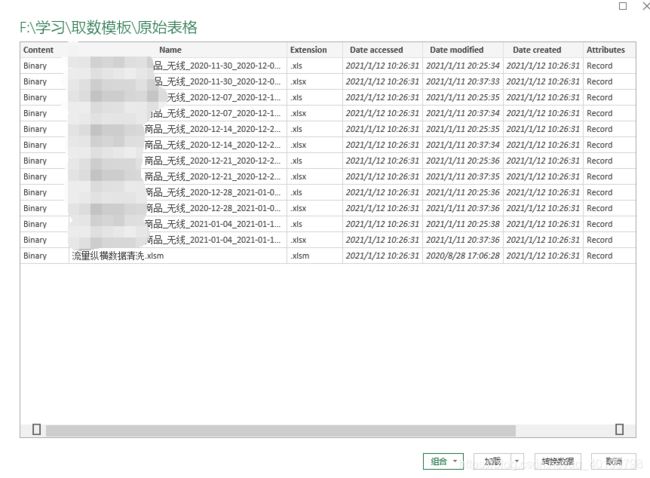
这里可以看到我们所选的路径文件夹下所有的文件,选择好路径并转化数据后就会进入到Powerquery编辑器。我们可以看到已获取了该文件夹下的13张表。
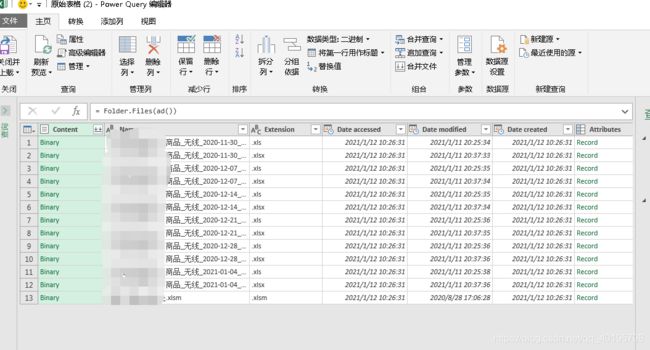
由于文件编码问题,power query只能识别csv或是xlsx文件,这里的表格是我已经将本来的6个xls文件转换为xlsx,xlsm是用来一键转换的工具表,所以才有13张表。接下来我们需要进行一个筛选,只留下xlsx文件。

之后我们只需选择第一列,删除其他列,再点击第一列表头旁的扩展按钮,即可得到我们表格内的数据。和一组查询。
2.数据格式处理
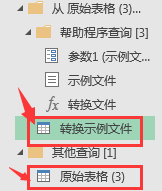
其中示例文件是我们的表格中的一张表,原始表格是最后的结果表。在我们对转换示例文件进行格式修改后,其他所有表格都会按照转换示例文件的格式处理,最后合并反馈在原始表格中。

我们可看到表格内的数据是这样的,每张表的前面都有一段无效内容,如果直接合并在一起对于后续的数据处理分析会很麻烦,难以使用,因此就需要在这里删除前5行数据。

之后将第一行设置为表头,再根据需要,将各个字段的值修改为对应的日期/数字/文本类型,将我们想要的得到的结果都通过示例处理完。

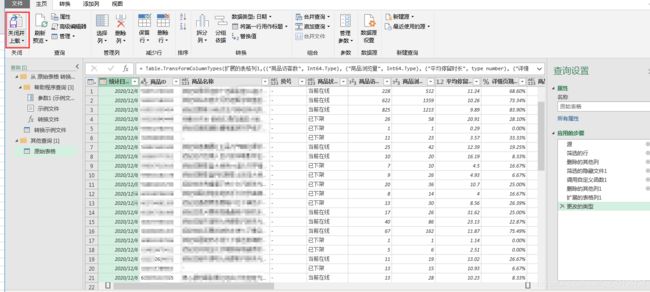
到这里,我们的数据就初步处理完了,只需关闭并上载,处理好的数据就会全部出线在我们的excel表格中。可以直接对其进行可视化或是计算处理。
3.进阶数据处理
power query能够实现excel对数据处理的全部功能。


除了可视化界面上这些基本操作外,还有power query的700多个函数可以使用。详情见
https://docs.microsoft.com/zh-cn/powerquery-m/power-query-m-function-reference
4.自动取数的路径问题
对于做excel自动化报表来说,自然不能只做一次性报表,如果每个人/每次都要因为数据的不同而重做同一个报表,那浪费的人力成本是很大的。因此,在power query自动获取文件夹的数据的基础上,还应该使该表格不管放在哪个文件夹下,都可以读取该文件夹路径,从而自动获得文件夹数据,而不是每换一个人适合、换一个文件夹使用,就要重新手动修改一次路径。这就涉及到power query的另一个功能——自定义函数。
首先需要在当前表格中建一个如下表格,用cell函数返回当前工作簿所在路径。

![]()
在power query左侧表格名上单击右键,找到创建函数

在如图位置输入下列函数,并吧Name位置的“表3”修改为之前创建的用来获取路径的表,将“原始表格”修改为数据源所在的文件夹名。
= ()=>
let
源 = Excel.CurrentWorkbook(){[Name="表3"]}[Content],
更改的类型 = Table.TransformColumnTypes(源,{{"fd", type text}}),
按分隔符拆分列 = Table.SplitColumn(更改的类型, "fd", Splitter.SplitTextByDelimiter("[", QuoteStyle.Csv), {"fd.1", "fd.2"}),
更改的类型1 = Table.TransformColumnTypes(按分隔符拆分列,{{"fd.1", type text}, {"fd.2", type text}}),
添加的后缀 = Table.TransformColumns(更改的类型1, {{"fd.1", each _ & "原始表格", type text}}),
#"fd 1" = 添加的后缀{0}[fd.1]
in
#"fd 1"
之后还需要切换到表格查询中选择”源“这一步骤,将数据源的获取改为我们刚建好的路径函数,使之通过调用函数来自动获取工作簿路径下数据源所在文件夹中的数据。
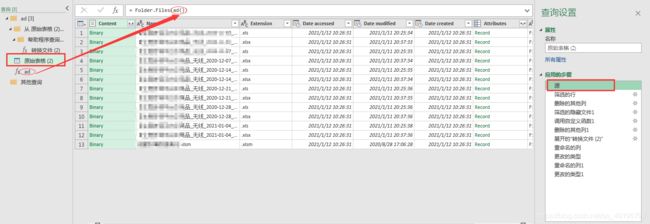
完成后检查是否出现错误步骤,如没有错误点击窗口左上角“关闭并上载” 自动取数模板就完成了,
如有错误,将源之后从出现错误的步骤开始修改。

最后确认上图中几个文件(这里“数据库”是做数据留存,将取数取出的所有数据导入数据库,“透视”是根据数据库中数据建立透视表做可视化的。二者都不影响“取数”表的工作,这里不做额外解释。)在同一文件夹下,我这里是在“取数模板”文件夹下。之后不管将“取数模板“这一文件夹放在哪个目录下,只要不修改数据源所在文件夹的名字,”取数“均可正常工作了。
注:也可先构建路径函数,通过路径函数直接获取数据源。
总结
这一工具是在工作中,发现诸多数据的下载,如日数据的跟踪、历史数据的复盘等工作时,均需要下载很多表格的数据。而通过第三方平台/插件下载的数据又大多带有平台标签之类无用格式。因此如果手工将数据汇总需要花费大量时间,而通过自动取数,则只需将下载好的数据表放在同一个文件夹下,然后在取数表中刷新。大大节省了时间成本。对于一些中小公司,无数据沉淀、无成熟数据库、数仓使用的情况下,是一个很便利的工具。
补充:手动设置power query相对路径详细 链接: https://blog.csdn.net/qq_40195798/article/details/117784947
如跳转失败,请复制链接到浏览器