模拟手写mybatis源码,深刻体会思想
一起学习模拟mybatis源码
- 1- 前言
-
- 1.1 为什么要分析源码?
- 1.2 mybatis简介
- 1.3 参考渠道
- 2- 手写mybatis代码具体流程
-
- 2.1 创建项目
- 2.2 开始写代码
-
- 2.2.1 从哪里开始?
- 2.2.2 SqlSessionFactoryBuilder是干啥的?
- 2.2.3 SqlSessionFactory是干啥的?
- 2.2.4 逐行分析(上)
-
- 2.2.3.1 关于build方法
- 2.2.3.2 关于SqlSessionFactory需要设置哪些属性?
- 2.2.3.3 DataSource只定义对象就行了吗?
- 2.2.3.4 TranSaction只定义对象就行了吗?
- 2.2.3.5 TranSaction对象中有哪些属性呢?
- 2.2.3.6 sql语句存放在什么样的数据结构中呢?
- 2.2.4 逐行分析(下)
- 2.2.5 sqlsession闪亮登场
- 2.2.6 书写完毕,测试
1- 前言
1.1 为什么要分析源码?
对于java初学者来说,源码看起来是比较困难的。开始时,我也不理解为什么要看源码?有什么用?而且面试还喜欢问。随着工作年限的增加,逐渐理解了.因为对于开发来说,框架的源码是最好的学习素材,因为里面的思想值得我们借鉴,如果能略知一二,对我们平时开发中遇到问题快速的想到解决方案非常有帮助。
1.2 mybatis简介
框架的诞生当然为了解决某种共性问题,而mybatis框架的诞生帮我们比较轻松地解决了持久层问题,帮我们从繁琐重复的代码中解放出来,使我们可以将更多的时间关注实现业务。
概念:
一个优秀的持久层框架
优点:
1- 将sql语句与代码分离,sql语句放在xml中,这样的话sql语句就很好维护了,一报错,控制台有打印,我们根据提示就很容易定位到哪个文件的哪个sql有问题。
 2- 封装了创建连接,开启会话,关闭连接这些重复操作。底层帮我们做啦,我们就不用每次执行sql时,重复写这些代码了。
2- 封装了创建连接,开启会话,关闭连接这些重复操作。底层帮我们做啦,我们就不用每次执行sql时,重复写这些代码了。
1.3 参考渠道
这篇文章参考的是动力节点老杜的比站视频,个人觉得老杜是目前觉得Java讲的最好的一个。大多数讲师都只告诉你怎么用,而老杜从0到1教我们,更多的是教我们为什么这样用,原理是什么,只有懂原理,工作中才能灵活运用。
下面开始模拟mybatis源码,手写一个能用的框架,有些地方没有具体处理,旨在理解框架的思想。有兴趣可以看源码。废话不多说,开始吧,go~~
2- 手写mybatis代码具体流程
2.1 创建项目
创建一个普通maven项目,因为我们这次是框架的开发者,所以不需要依赖其他框架。
项目的pom依赖
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>jaxen</groupId>
<artifactId>jaxen</artifactId>
<version>1.2.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
</dependencies>
dom4j:框架要解析xml文件,当然要这个依赖
mysql-connector-java:要连接数据库,当然需要数据库驱动依赖
junit:最后写完需要测试一下
tips:写完后可以install到maven仓库里面,那么你就可以在自己创建的demo项目中去导入框架去使用啦,当然只能自己玩玩,因为很多地方没实现。。
2.2 开始写代码
2.2.1 从哪里开始?
从哪里开始呢?当然得根据我们平时使用的mybatis代码去逆推mybatis的作者是怎么开发出来的。下面是我们使用mybatis后的一个简单插入的示例代码,我们看首先需要书写一个 SqlSessionFactoryBuilder的类。
@Test
public void test () {
SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder();
SqlSessionFactory sqlSessionFactory = sqlSessionFactoryBuilder.build(Resources.getResourceAsStream("mybatis-config.xml"));
SqlSession sqlSession = sqlSessionFactory.openSession();
User user = new User();
user.setId("1");
user.setName("老默");
user.setPhone("110");
int count = sqlSession.insert("1.insert", user);
}
2.2.2 SqlSessionFactoryBuilder是干啥的?
从代码里面可以初步得到结论,它是帮我们来解析配置文件的,帮我们把配置文件 mybatis-config.xml 转换成一个流,然后,将里面的内容全部转换成一个个对象,java就是面向对象嘛,对吧。
我们开始创建对象,然后里面有一个build方法。每次书写方法,要清楚入参和出参是什么,入参通过代码看是一个输入流,出参是SqlsessionFactory对象,我们继续创建一个SqlsessionFactory对象,至于里面的属性和方法,往下分析才能知道。

具体代码如下
/**
* 解析输入流,返回一个会话工厂对象,想要对文件中的内容进行相关操作,当然得转换成流啦
* @param inputStream
*/
public SqlSessionFactory build(InputStream inputStream) {
SqlSessionFactory sqlSessionFactory = new SqlSessionFactory();
try {
// 采用dom4j解析配置文件
SAXReader reader = new SAXReader();
// 根据流得到对应的文档对象
Document document = reader.read(inputStream);
// 获取xml里面的environments元素对象
Element environments = (Element)document.selectSingleNode("/configuration/environments");
// 获取到其中的default属性的值
String defaultValue = environments.attributeValue("default");
// 根据default才能知道用的是哪个环境
Element environment = (Element)document.selectSingleNode("/configuration/environments/environment[@id='"+defaultValue+"']");
// 获取transactionManager元素对象
Element transactionElt = environment.element("transactionManager");
// 获取dataSource元素对象
Element dataSourceElt = environment.element("dataSource");
// 获取mapper标签里面的resource,可以知道所有的mapper.xml文件的路径了,目的是为后面获取所有的sql语句做准备
List<String> sqlMapperXmlList = new ArrayList<>(); // sql文件的名称集合
List<Node> nodes = document.selectNodes("//mapper");// 两个斜杠表示获取所有的mapper标签对象
nodes.forEach(node -> {
Element element = (Element) node;
String resource = element.attributeValue("resource");
sqlMapperXmlList.add(resource);
});
// 获取数据源对象
DataSource dataSource = getDataSource(dataSourceElt);
// 创建事务管理器
Transaction transaction = getTransaction(transactionElt,dataSource);
// 创建map集合
Map<String,MappedStatement> mappedStatements = getMappedStatements(sqlMapperXmlList);
// 给会话工厂赋值
sqlSessionFactory = new SqlSessionFactory(transaction,mappedStatements);
} catch (DocumentException e) {
e.printStackTrace();
}
return sqlSessionFactory;
}
2.2.3 SqlSessionFactory是干啥的?
SqlSessionFactoryBuild主要作用:解析配置文件,创建SqlSessionFactory对象。
咱就是解析文件的作用,解析完成后将其中的信息都赋值给你(SqlSessionFactory)
SqlSessionFactory作用:作为对象来承接SqlSessionFactoryBuild解析后的所有信息。
xml里面的信息解析完毕都在我这里,可以通过我去进行后续操作啦
2.2.4 逐行分析(上)
2.2.3.1 关于build方法
至于bulid方法,是重载方法,可以支持多种方式去获取配置文件,这里也可以理解到方法重载的意义。
2.2.3.2 关于SqlSessionFactory需要设置哪些属性?
创建一个空的SqlSessionFactory对象,准备返回。
走到这里可能又卡主了,不知道SqlSessionFactory对象里面有哪些属啊我怎么往下写呢?其实看源代码大概知道,这个build方法整体就在干一件事:
解析配置文件,将里面的内容封装成一个个对象,再将这些对象作为属性赋值给核心对象SqlSessionFactory,得到核心对象后,我们就能通过它来对一个数据库中的表进行增删改查了。
具体有哪些对象,我们来看看配置文件

想对一个数据库进行增删改查需要哪些东西?
- 数据库的相关信息(得知道操作哪个库) ------> 对应上图的datasource
- 如何控制事务? 你得在这个对象里面有相对应的属性吧?这就是上图的transaction
- 执行的sql语句是什么? 这就是上图的mapper属性里面的东西
因此,SqlSessionFactory里面大概有以上三个属性。下面开始分析SqlSessionFactory,不然我们的SqlSessionFactoryBuilder代码无法进行下去。
2.2.3.3 DataSource只定义对象就行了吗?
问题再次出现!!!!!!
数据源对象是用来和数据库连接的,但是与数据库连接的方法有很多,我们还可以通过数据库连接池来连接数据库,因此,这里需要采用面向接口编程,定义一个DataSource接口,定义多个实现类,至于采用哪个实现类,就交给用户去选择,表现在配置文件当中就是DataSource的type值,如果用户填写unpooled
我们就采用普通方法来连接数据库,如果填pooled那么用户是选择用连接池来完成数据库的连接。
这也就是接口存在的意义,代码在真正执行过程中,有时候具体要创建什么对象是无法预料的,我们就要采用接口编程,将选择的权利交给用户决定,根据用户的配置,来创建对应的对象,达到预期的效果。
很庆幸这个接口已经有写好的了
具体代码:
package cn.lt.godbatis.core;
import java.io.PrintWriter;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.SQLFeatureNotSupportedException;
import java.util.logging.Logger;
/**
* 1- 创建普通连接对象实现DataSource接口
*/
public class UnPooledDataSource implements javax.sql.DataSource{
private String url;
private String username;
private String password;
public UnPooledDataSource() {
}
/**
* 2- 主要实现这个方法,它在帮我们加载驱动,并对属性进行赋值
* @param driver
* @param url
* @param username
* @param password
*/
public UnPooledDataSource(String driver, String url, String username, String password) {
try {
Class.forName(driver); // 是否可以体会反射的意义??
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
this.url = url;
this.username = username;
this.password = password;
}
/**
* 3- 主要实现这个方法,连接数据库啦
*/
public Connection getConnection() throws SQLException {
Connection connection = DriverManager.getConnection(url, username, password);
return connection;
}
public Connection getConnection(String username, String password) throws SQLException {
return null;
}
public <T> T unwrap(Class<T> iface) throws SQLException {
return null;
}
public boolean isWrapperFor(Class<?> iface) throws SQLException {
return false;
}
public PrintWriter getLogWriter() throws SQLException {
return null;
}
public void setLogWriter(PrintWriter out) throws SQLException {
}
public void setLoginTimeout(int seconds) throws SQLException {
}
public int getLoginTimeout() throws SQLException {
return 0;
}
public Logger getParentLogger() throws SQLFeatureNotSupportedException {
return null;
}
}
ok,UnPooledDataSource方法就是完成两件事,帮我们承载配置文件中的datasource,并帮我们连接数据库,对于PooledDatasource我们不去实现,能力有限,理解核心思想为重点。
2.2.3.4 TranSaction只定义对象就行了吗?
通过上面我们同样可以推出,配置文件中事务管理的type属性也有两个值,同样我们需要定义一个事务管理的接口,事务可以家采用JDBC的,也可以交给其他容器管理,比如spring,spring可以使用注解形式来控制事务,本质还是对JDBC事务的封装,我们在做springboot项目时可以采用spring定义的注解,用起来方便一些。
图片:
 具体代码:
具体代码:
import java.sql.Connection;
/**
* 事务管理接口
* 提供控制事务的抽象 方法
*/
public interface Transaction {
/**
* 提交事务
*/
void commit ();
/**
* 回滚事务
*/
void rollback ();
/**
* 关闭 事务
*/
void close ();
/**
* 开启连接
*/
void openConnection();
/**
* 获取连接
*/
Connection getConnection();
}
2.2.3.5 TranSaction对象中有哪些属性呢?
我们只对jdbc事务进行实现,因此创建对象实现我们刚才的事务接口。问题又来了,事务对象里面有哪些属性嘞?分析一下事务对象帮我们做啥事的,控制事务的,它还是调用的connection对象帮我们回滚,提交,关闭事务的,因此定义一个connection属性是不是比较方便一些。connection对象我们好像在哪里获取过?没错,在我们datasource对象里面获取过,于是我们的datasource对象是不是作为属性定义在事务对象里面比较好?
原因1:TranSaction对象需要用connection,而你connection对象就是datasource帮你创的。
原因2:我们核心对象SqlSessionFacory就是代表一个数据库,从它里面可以获取到我们连接数据库的所有信息就ok了嘛,因此,把原来定义在核心对象里面的datasource属性删掉,挪到TranSaction对象里面来,我们仍然可以通过对象套对象获取datasource对吧?
SqlSessionFactory代码:
package cn.lt.godbatis.core;
import javax.sql.DataSource;
import java.util.Map;
/**
* 会话工厂,可以创建会话连接
*/
public class SqlSessionFactory {
/**
* 事务管理器属性
* 应该是一个接口,可以灵活切换
*/
private Transaction transaction;
/**
* 数据源属性
*/
//删除掉 private DataSource dataSource;
/**
* map集合,存放所有的sql语句,key是namespace和id组成的唯一标识,value是sql语句标签对象
*/
private Map<String,MappedStatement> mappedStatements;
public SqlSessionFactory(Transaction transaction, Map<String, MappedStatement> mappedStatements) {
this.transaction = transaction;
this.mappedStatements = mappedStatements;
}
public SqlSessionFactory() {
}
/**
* 获取sqlsession对象
*/
public SqlSession openSession() {
// 获取会话的前提是获取连接
transaction.getConnection();
SqlSession sqlSession = new SqlSession(this);
return sqlSession;
}
public Transaction getTransaction() {
return transaction;
}
public void setTransaction(Transaction transaction) {
this.transaction = transaction;
}
public Map<String, MappedStatement> getMappedStatements() {
return mappedStatements;
}
public void setMappedStatements(Map<String, MappedStatement> mappedStatements) {
this.mappedStatements = mappedStatements;
}
}
JdbcTransaction代码:
package cn.lt.godbatis.core;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
public class JdbcTransaction implements Transaction {
/**
* 数据源属性
*/
private DataSource dataSource; // 面向接口
private boolean autoCommit; // 自动提交的开关,目前没深入研究
/**
* 连接属性
*/
private Connection connection;
// 有参构造对属性赋值
public JdbcTransaction(DataSource dataSource, boolean autoCommit) {
this.dataSource = dataSource;
this.autoCommit = autoCommit;
}
// 提交事务
public void commit() {
try {
connection.commit();
} catch (SQLException e) {
e.printStackTrace();
}
}
// 回滚事务
public void rollback() {
try {
connection.rollback();
} catch (SQLException e) {
e.printStackTrace();
}
}
// 关闭事务
public void close() {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 开启连接
*/
public void openConnection() {
if (connection == null) { // 这样可以保证连接是同一个连接,如果不是同一个,事务控制就没有意义
try {
connection = dataSource.getConnection();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 对外提供获取连接的方法,datasource连接数据库后创建了这个,获取这个对象后,就相当于和数据库连接啦,你可以通过它对数据库进行操作,我们在transaction对象中提供方法让外界可以获取到就ok
* @return
*/
public Connection getConnection() {
this.openConnection();
return connection;
}
}
DataSource与TranSaction接口分析到这,貌似还有个mapper标签的内容没有对象去进行承载,继续往下看。
2.2.3.6 sql语句存放在什么样的数据结构中呢?
我们所有的mapper.xml文件里面的sql语句,如果可以存放在一个数据结构当中,我们想获取时,可以轻松根据一个唯一标识获取到执行的sql就好了。那不就是map集合吗,顺便我们也可以理解了mapper文件的namespace必须要唯一的原因,这样就可以将namespace和id拼接为map的key,这样我们不就可以轻松获取到我们要操作哪张表?执行哪条sql了吗 ?
value是什么呢?定义为string不就好了?不行,因为标签里面还有其他属性呀,所以用个对象承接比较好。
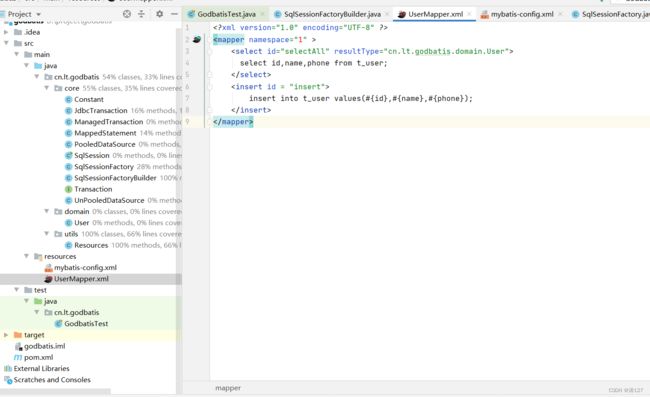 map集合的value(是一个sql语句对象)代码:
map集合的value(是一个sql语句对象)代码:
package cn.lt.godbatis.core;
/**
* sql语句标签对象,因为一个标签内有很多属性,需要封装为对象
*/
public class MappedStatement {
private String sql;
private String resultType;
public MappedStatement() {
}
@Override
public String toString() {
return "MappedStatement{" +
"sql='" + sql + '\'' +
", resultType='" + resultType + '\'' +
'}';
}
public String getSql() {
return sql;
}
public void setSql(String sql) {
this.sql = sql;
}
public String getResultType() {
return resultType;
}
public void setResultType(String resultType) {
this.resultType = resultType;
}
public MappedStatement(String sql, String resultType) {
this.sql = sql;
this.resultType = resultType;
}
}
2.2.4 逐行分析(下)
绕了一圈,继续来分析我们的build方法,注释如下:
package cn.lt.godbatis.core;
import cn.lt.godbatis.utils.Resources;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import javax.sql.DataSource;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 会话工厂构建器,用来解析核心配置文件的输入流,创建会话工厂
*/
public class SqlSessionFactoryBuilder {
public SqlSessionFactoryBuilder() {};
/**
* 解析输入流,返回一个会话工厂对象
* @param inputStream
*/
public SqlSessionFactory build(InputStream inputStream) {
SqlSessionFactory sqlSessionFactory = new SqlSessionFactory();
// 一切以给sqlSessionFactory赋值为导向
try {
// 1- 解析配置文件
SAXReader reader = new SAXReader();
Document document = reader.read(inputStream);
Element environments = (Element)document.selectSingleNode("/configuration/environments");
String defaultValue = environments.attributeValue("default");
Element environment = (Element)document.selectSingleNode("/configuration/environments/environment[@id='"+defaultValue+"']");
Element transactionElt = environment.element("transactionManager");
Element dataSourceElt = environment.element("dataSource");
List<String> sqlMapperXmlList = new ArrayList<>(); // sql文件的名称集合
List<Node> nodes = document.selectNodes("//mapper");// 两个斜杠表示获取所有的mapper标签对象
// 2- 获取所有的mapper.xml文件
nodes.forEach(node -> {
Element element = (Element) node;
String resource = element.attributeValue("resource");
sqlMapperXmlList.add(resource);
});
// 3- 获取数据源对象,最好封装成方法,避免代码臃肿,SqlSessionFactory作为核心对象,核心方法里面应当是简介且见名知意的
DataSource dataSource = getDataSource(dataSourceElt);
// 4- 创建事务管理器,最好封装成方法,避免代码臃肿
Transaction transaction = getTransaction(transactionElt,dataSource);
// 5- 创建sql集合(这样所有的sql语句全在里面了),最好封装成方法,避免代码臃肿
Map<String,MappedStatement> mappedStatements = getMappedStatements(sqlMapperXmlList);
// 给会话工厂赋值
sqlSessionFactory = new SqlSessionFactory(transaction,mappedStatements);
} catch (DocumentException e) {
e.printStackTrace();
}
return sqlSessionFactory;
}
/**
* 封装获取sql语句集合的方法,提高代码复用,避免代码臃肿
*/
private Map<String, MappedStatement> getMappedStatements(List<String> sqlMapperXmlList) {
// 一切以封装map集合为导向
Map<String, MappedStatement> map = new HashMap<>();
// 遍历获取每个mapper.xml文件名
sqlMapperXmlList.forEach(sqlMapperXml -> {
try {
// 同样采用dom4j解析
SAXReader reader = new SAXReader(); // 解析mapper.xml文件
Document document = reader.read(Resources.getResourceAsStream(sqlMapperXml));
Element mapperElt = (Element)document.selectSingleNode("mapper");// 获取根节点
String namespace = mapperElt.attributeValue("namespace");
// 获取到当前mapper.xml文件里面所有的sql标签集合
List<Element> sqlElts = mapperElt.elements();
sqlElts.forEach(sqlElt -> {
// 遍历集合,将每个对象处理后封装到map集合中返回
// 获取sql标签的id
String id = sqlElt.attributeValue("id");
// 拼接namespace和id得到map的key,这样就封装好了key
String sqlId = namespace + "." + id;
// 获取sql标签中resultType值
String resultType = sqlElt.attributeValue("resultType");
String sql = sqlElt.getTextTrim();
// 封装对象
MappedStatement mappedStatement = new MappedStatement(sql, resultType);
// 存入map
map.put(sqlId,mappedStatement);
});
} catch (DocumentException e) {
e.printStackTrace();
}
});
return map;
}
/**
* 封装获取事务管理对象的方法,提高代码复用,避免代码臃肿
*/
private Transaction getTransaction(Element transactionElt, DataSource dataSource) {
// 创建空对象
Transaction transaction = null;
// 获取用户输入的type属性
String type = transactionElt.attributeValue("type").trim().toUpperCase();
// 如果为jdbc,就创建jdbc的事务对象
if (Constant.JDBC_TRANSACTION.equals(type)) {
transaction = new JdbcTransaction(dataSource,false);
}
// 实力有限哈哈,没有实现
if (Constant.MANAGED_TRANSACTION.equals(type)) {
transaction = new ManagedTransaction();
}
return transaction;
// tips这里可以深刻体会面向接口,和配置文件结合的意义,将选择权交给用户,动态的帮用户创建相应的对象
}
/**
* 封装获取数据源对象的方法,提高代码复用,避免代码臃肿
*/
private DataSource getDataSource(Element dataSourceElt) {
// 创建数据源空对象
DataSource dataSource = null;
Map<String,String> map = new HashMap<>();
// 获取type,看用户想用哪种方式连接数据库
String type = dataSourceElt.attributeValue("type").trim().toUpperCase();
// 获取配置文件中的datasource的每个标签里面的property对象
List<Element> properties = dataSourceElt.elements("property"); // 获取下面的property标签对象的集合
// 遍历,用map集合来承载
properties.forEach(propertie -> { // java8新特性的优雅之处
String name = propertie.attributeValue("name");
String value = propertie.attributeValue("value");
map.put(name,value);
});
// 同上
if (Constant.UN_POOLED_DATASOURCE.equals(type)) {
dataSource = new UnPooledDataSource(map.get("driver"),map.get("url"),map.get("username"),map.get("password"));
}
// 不做实现
if (Constant.POOLED_DATASOURCE.equals(type)) {
dataSource = new PooledDataSource();
}
return dataSource;
}
}
2.2.5 sqlsession闪亮登场
接下来怎么写呢?看图1倒推,需要书写一个sqlsession对象。SqlsessionFactory封装好了配置文件的所有信息,任务已经完成。我们按照图片提示在SqlsessionFactory定义一个openSession方法,将自己传递给sqlsession,因为,所有的信息都在SqlsessionFactory里面啊,对吧?sqlsession是执行sql的打工仔,打工之前你得把工作安排告诉我呀。我们简单完成一个insert语句即可,重要学习思想。
图1:
 SqlsessionFacory完整代码:
SqlsessionFacory完整代码:
重点看openSession方法
package cn.lt.godbatis.core;
import javax.sql.DataSource;
import java.util.Map;
/**
* 会话工厂,可以创建会话连接
*/
public class SqlSessionFactory {
/**
* 事务管理器属性
* 应该是一个接口,可以灵活切换
*/
private Transaction transaction;
/**
* 数据源属性
*/
private DataSource dataSource;
/**
* map集合,存放所有的sql语句,key是namespace和id组成的唯一标识,value是sql语句标签对象
*/
private Map<String,MappedStatement> mappedStatements;
public SqlSessionFactory(Transaction transaction, Map<String, MappedStatement> mappedStatements) {
this.transaction = transaction;
this.mappedStatements = mappedStatements;
}
public SqlSessionFactory() {
}
/**
* 获取sqlsession对象
*/
public SqlSession openSession() {
// 获取会话的前提是获取连接
transaction.getConnection();
SqlSession sqlSession = new SqlSession(this);
return sqlSession;
}
public Transaction getTransaction() {
return transaction;
}
public void setTransaction(Transaction transaction) {
this.transaction = transaction;
}
public Map<String, MappedStatement> getMappedStatements() {
return mappedStatements;
}
public void setMappedStatements(Map<String, MappedStatement> mappedStatements) {
this.mappedStatements = mappedStatements;
}
}
SqlSession 代码与分析如下:
package cn.lt.godbatis.core;
import java.lang.reflect.Method;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class SqlSession {
private SqlSessionFactory sqlSessionFactory;
public SqlSession() {
}
public SqlSession(SqlSessionFactory sqlSessionFactory) {
this.sqlSessionFactory = sqlSessionFactory;
}
/**
*
* @param sqlId 你要执行哪条sql?key告诉我
* @param pojo 你要存的对象给我
* @return 影响的行数
*/
public int insert(String sqlId,Object pojo) {
// 定义变量记录插入影响的行数,可由此判断插入是否成功,可以根据成功与否返回给前端不同的东西
int count = 0;
// 一切以获取到预执行对象为导向
try {
// 1- 获取连接对象,把sqlSessionFactory存放的连接对象拿出来,开始要用了
Connection connection = sqlSessionFactory.getTransaction().getConnection();
// 2- 执行的sql语句也取出来
String sqlFromXml = sqlSessionFactory.getMappedStatements().get(sqlId).getSql();
// 配置文件中的sql语句样子insert into user values(#{id},#{name},#{age});
// 难点1: 需要对sql进行处理,将sql中的所有#{*}替换为?
String prepareSql = sqlFromXml.replaceAll("#\\{[a-zA-Z0-9_$]*}", "?");
// 3- 获取预执行对象
PreparedStatement preparedStatement = connection.prepareStatement(prepareSql);
// 难点2: 给?传值,将?替换成pojo中的属性值,并且要一一对应
sqlAssignment(preparedStatement,sqlFromXml,pojo);
// 执行sql
count = preparedStatement.executeUpdate();
} catch (Exception e) {
e.printStackTrace();
}
return count;
}
/**
* 给prepareStatement里面的?占位符赋值
* @param preparedStatement
* @param sqlFromXml
*/
private void sqlAssignment(PreparedStatement preparedStatement, String sqlFromXml ,Object pojo) {
// 一切以赋值为导向
// 1- 需要知道sql语句中的?属性名以及它的顺序
// insert into user values(#{id},#{name},#{age});
int fromIndex = 0; // 起始索引
int index = 1; // ?初始顺序
while(true) {
// 获取#第一次出现的索引位置
int jinHaoIndex = sqlFromXml.indexOf("#",fromIndex);
// 没获取到终止循环
if (jinHaoIndex < 0) {
break;
}
// 获取到 } 的索引位置
int youHuaKuoHaoIndex = sqlFromXml.indexOf("}",fromIndex);
// 再将 } 的索引+1赋值为起始索引
fromIndex = youHuaKuoHaoIndex + 1;
// 截取获取属性名
String propertyName = sqlFromXml.substring(jinHaoIndex + 2, youHuaKuoHaoIndex);
// 将属性名拼接get方法获取属性值
String getMethodName = "get" + propertyName.toUpperCase().substring(0,1) + propertyName.substring(1) ;
try {
// 调用get方法
Method getMethod = pojo.getClass().getDeclaredMethod(getMethodName);
// 因为类型有很多,能力有限,我们在这里假设输入的都是string,那么数据库也只能定义string,这是目前这个模拟版的局限性,重在学思想
String propertyValue = (String)getMethod.invoke(pojo);
// 赋值啦
preparedStatement.setString(index,propertyValue);
} catch (Exception e) {
e.printStackTrace();
}
// 每次赋完值,就要+1去给sql语句中的下一个?赋值
index++;
}
}
public static void main(String[] args) {
// 测试用例
String pro = "name";
String getMethod = "get" + pro.toUpperCase().substring(0,1) + pro.substring(1) ;
System.out.println(getMethod);
}
public void commit() {
sqlSessionFactory.getTransaction().commit();
}
public void rollback() {
sqlSessionFactory.getTransaction().rollback();
}
public void close() {
sqlSessionFactory.getTransaction().close();
}
}
2.2.6 书写完毕,测试
 看看数据库:
看看数据库:

成功啦,我们通过自己手写的源代码实现了mybatis的简单功能。当然可以将自己的这个工程install后会出现在maven的坐标里,那么以后就可以用自己的框架啦哈哈,当然有很多地方要改进,搬运至此,我是想不出这么深奥的东西的,仅仅搬运,一起学习~~