MySql多表查询——复杂查询
一.select语句基本查询结构;

1.执行顺序;
(1).首先执行where语句过滤原始数据
(2).执行group by进行分组
(3).执行having对分组数据进行操作
(4).执行select筛选出数据
(5). 执行order by排序
2.Sql优化问题(先简单了解,后续再详解);
当你数据库有100万条数据的时候怎么优化SQL语句
①. 不要有超过5个以上的表连接(连接的表越多,其编译的时间和连接的开销也越大,性能越不好控制,最好是把连接拆开成较小的几个部分逐个顺序执行)
②. 考虑使用临时表或表变量存放中间结果
③. 修改like程序,去掉前置百分号,like语句因为前置百分号而无法使用索引,会导致全表扫描
④. 限制结果集,要尽量减少返回的结果行,包括行数和字段列数
⑤. 使用存储过程封装复杂的SQL语句或商业逻辑,因为存储过程的执行计划可以被缓存在内存中较长时间,减少了重新编译的时间,还有存储过程可以减少客户端和服务器的频繁交互。
⑥. 尽量避免在where子句中使用!=或<>操作符,否则会进行全表扫描,应避免全表扫描,考虑在where及order by设计的列上建立索引
⑦. 尽量避免在where子句中对字段进行null值判断,否则会进行全表扫描,例如select id from person where num is null,可以在num上设置默认值0,确保表中num列没有null列,然后使用查询:select id from person where num=0
⑧. 尽量避免在where子句中使用or来连接条件,否则会进行全表扫描,例如select id from person where num=05 or num=22,优化后:select id from person where num=05 union all select id from person where num=22
二.连接查询
2.1数据的完整性约束;
主键:主键是关系表中记录的唯一标识。主键的选取非常重要,主键不要带有业务含义, 而应该使用BIGINT自增或者GUID类型。主键也不应该允许NULL。可以使用多个列 作为联合主键,但联合主键并不常用。
外键:外键主要是维护表之间的关系的,主要是为了保证参照完整性,如果表中的某个字 段为外键字段,那么该字段的值必须来源于参照的表的主键。
2.2.实体间的关系
2.2.1 一对一关系(1:1):一张表里面的数据与另外一张表的数据是一对一的;
如下表:基本满足咱们的要求,其中姓名、性别和年龄属于常用数据,但是身高、体重、籍贯和居住地为不常用数据。如果每次查询都要查询所有数据的话,那么不常用数据就会影响效率,而且又不常用。

因此,咱们可以将常用的数据和不常用的数据分离存储,即分为两张表,例如:

表1:常用数据
 表2:不常用数据
表2:不常用数据
现在表1和表2所示,通过字段ID,表1中的一条记录只能匹配表2中的一条记录,反之亦然,这就是一对一的关系。
2.2.2 一对多关系(1:n):一张表的数据与另一张表是一对多,就是一张表里的1条数据可以对象领一张表的多天数据。如下面两张表:
咱们设计「国家城市表」,其包含两个实体,即国家和城市。

如上面表3和表4所示,通过字段国家,表3中的一条记录可以匹配表4中的多条记录,但反过来,表4中的一条记录只能匹配表3中的一条记录,这就是典型的一对多的关系。
2.2.3 多对多关系(n:n):即一张表中的记录可以对应另外一张表中的多条记录,反过来,另外一张表中的一条记录也可以对应第一张表中的多条记录。
例如,咱们设计「教师学生表」,其包含两个实体,即教师和学生
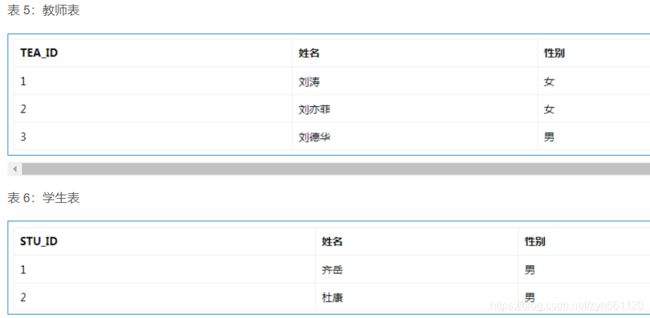
观察上面的表5和表6,咱们会发现:表5和表6的设计满足了实体的属性,但没有维护实体之间的关系,即一个老师教过多个学生,一个学生也被多个老师教过。但是无论咱们在表5中还是在表6中增加字段,都会出现一个问题,那就是:该字段要保存多个数据,并且还是与其他表有关系的字段,不符合设计规范。因此,咱们可以再设计一张「中间表」,专门用来维护表5和表6的关系。

观察上面的表5、表6和表7,咱们会发现增加表7之后,咱们维护表5和表6的关系更加方便了!无论是想从表5通过表7查到表6,还是想从表6通过表7查到表5,都非常容易啦!这就是典型的多对多的关系。
3.关系型数据库内表的连接的方式
3.1 内连接:是指所有查询出的结果都是能够在连接的表中有对应记录的。组合两个表中 的记录,返回关联字段相符的记录,也就是返回两个表的交集(阴影)部分。

关键字:inner join on
语句:select * from a_table a inner join b_table b on a.a_id = b.b_id;
3.2 外连接:left join 是left outer join的简写,它的全称是左外连接,是外连接中的一 种。 左(外)连接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显 示符合搜索条件的记录。右表记录不足的地方均为NULL。(右连接也是一样)
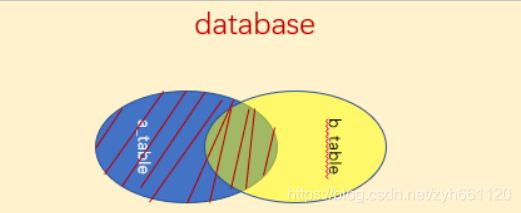
关键字:
LEFT(OUTER)JOIN //左连接查询、
RIGHT(OUTER)JOIN//右连接查询
4.三表查询

5.多表查询练习
给出两张表,一张部门表department,另一张员工表employee
department表
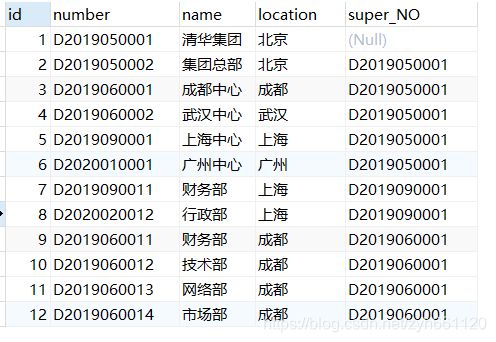
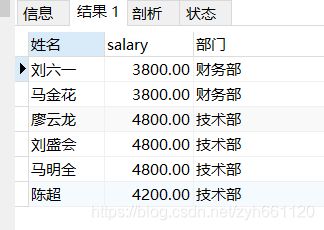
employee表
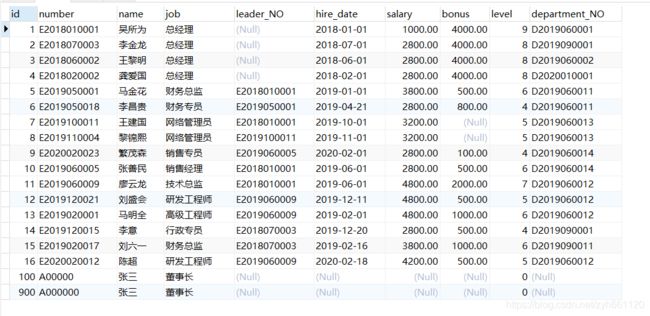
题目:
- 列出所有员工的姓名及其直接上级的姓名。
- 列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。
- 列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门。
- 列出在财务部工作的员工的姓名,假定不知道财务部的部门编号。
- 列出薪金高于公司平均薪金的所有员工信息,所在部门名称,上级领导。
- 列出与陈超从事相同工作的所有员工及部门名称。
- 查出至少有一个员工的部门。显示部门编号、部门名称、部门位置、部门人数。
- 列出薪金高于在财务部工作员工平均薪金的员工姓名和薪金、部门名称。
答案:
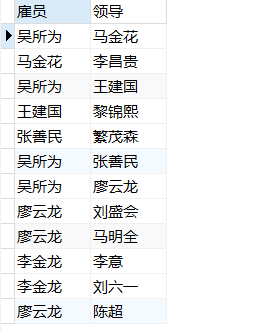
- 列出所有员工的姓名及其直接上级的姓名。
select e.name 雇员,e1.name 领导 from employee e INNER JOIN employee e1 on e.number=e1.leader_NO; //内连接
select e.name 雇员,e1.name 领导 from employee e RIGHT JOIN employee e1 on e.number=e1.leader_NO; //左连接
select e.name 雇员,e1.name 领导 from employee e , employee e1 where e.number=e1.leader_NO; //右连接
2.列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。
SELECT e.number 部门编号, e.name 名字, d.name 部门 AND e.department_NO= d.number; 3.列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门。 select e.* ,d.`name` 部门 from employee e 4.列出在财务部工作的员工的姓名,假定不知道财务部的部门编号。 (1).子查询:找出财务部的编号 select number from department d where d.`name`='财务部'; (2).根据条件来 select d1.number 部门编号,e1.`name` 名字,d1.`name` 部门 from employee e1 LEFT JOIN department d1 on e1.department_NO=d1.number 5.列出薪金高于公司平均薪金的所有员工信息,所在部门名称,上级领导。 (1).找出平均工资 select avg(e.salary) from employee e; (2).根据条件来 select e1.*,d.`name` 部门,e2.`name` 领导 from employee e1 LEFT JOIN department d on 6.列出与陈超从事相同工作的所有员工及部门名称。 (1)找出陈超从事的工作 select e.job from employee e where e.name='陈超'; (2)根据条件来 select e.`name` 员工,d.`name` 部门 from employee e LEFT JOIN 7.查出至少有一个员工的部门。显示部门编号、部门名称、部门位置、部门人数。 (1)找出部门,和部门数,即员工数。 SELECT department_NO, COUNT(*) as 人数 FROM employee GROUP BY department_NO; (2)根据条件来 SELECT d.number, d.name, d.location,z1.人数 FROM department d, 8.列出薪金高于在财务部工作员工平均薪金的员工姓名和薪金、部门名称。 SELECT ee.name 姓名, ee.salary, dd.name 部门 结束!加油吧!!!!!
FROM employee e, employee m, department d
WHERE e.leader_NO=m.number AND e.hire_date
right outer JOIN department d on e.department_NO=d.number; 

where e1.department_NO in
(select number from department d where d.`name`='财务部');

e1.department_NO=d.number LEFT JOIN employee e2 on e2.number=e1.leader_NO
where e1.salary>(select avg(e.salary) from employee e);
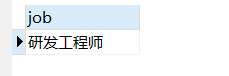
department d on e.department_NO=d.number where e.job=
(select e.job from employee e where e.name='陈超');

(SELECT department_NO, COUNT(*) 人数 FROM employee GROUP BY department_NO) z1
WHERE d.number = z1.department_NO;
from employee ee left join department dd on ee.department_NO = dd.number
where ee.salary > (SELECT avg(e.salary)
from employee e, department d
WHERE e.department_NO=d.number and d.name='财务部');