kafka集群搭建及问题
一、zookeeper集群搭建
1、创建文件夹
cd /home
mkdir zookeeper
2、下载
cd zookeeper
wget https://downloads.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
解压到当前文件夹
tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz
文件夹重命名
mv apache-zookeeper-3.8.0-bin zookeeper
3、修改配置文件
3.1 进入到conf目录,将zoo_sample.cfg修改为zoo.cf
mv zoo_sample.cfg zoo.cfg
3.2 退回上级目录,添加一个文件zkdata
mkdir zkdata
3.3 打开zoo.cfg文件,修改datadir=zkdata的路劲,并再最后添加
/home/zookeeper/zookeeper/zkdata
server.1=192.168.1.171:2888:3888
server.2=192.168.1.211:2888:3888
server.3=192.168.1.240:2888:3888
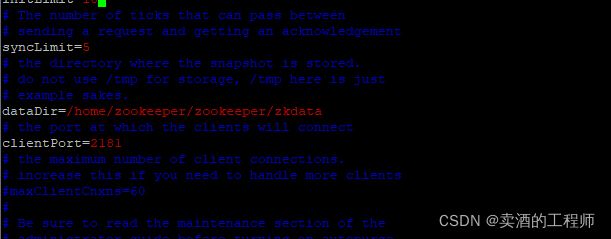

3.4 详解每个配置代表的含义
1.tickTime:CS通信心跳时间Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。tickTime=2000
2.initLimit:LF初始通信时限集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。initLimit=5
3.syncLimit:LF同步通信时限集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。syncLimit=2
4.dataDir:数据文件目录Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。dataDir=/home/zookeeper/zookeeper/zkdata
5.clientPort:客户端连接端口客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。clientPort=2181
6.服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口)这个配置项的书写格式比较特殊,规则如下:server.N=YYY:A:B
server.1=IP或者主机名:2888:3888server.2=IP或者主机名:2888:3888server.3=IP或者主机名:2888:3888
3.5 在刚创建好的zkdata下面创建一个文件 myid,,里面内容是server.N中的N(另外的服务器也同样)
vim myid
1
3.6 将配置好的zookeeper拷贝到其他服务器
tar -zcf zookeeper.tar.gz zookeeper
scp zookeeper.tar.gz root@lmb2:/home/zookeeper
scp zookeeper.tar.gz root@lmb3:/home/zookeeper
3.7 在其余服务器解压,并修改myid文件
tar -zxvf zookeeper.tar.gz
二、kafka集群搭建
0、前置环境
前置环境搭建需要jdk8和zk集群,zk集群参考:zookeeper集群部署
1、下载kafka安装包
kafka官网:http://kafka.apache.org/downloads; 根据需要下载需要的包;
2、解压
tar -zxvf kafka-3.1.0-src.tgz
mv kafka-3.1.0-src kafka
3、server.properties配置
进去kafka文件夹的config目录下,并编辑server.properties
修改broker.id=num,集群kafka的num都需要是独一无二的,相当于id不可重复(例如,broker.id=0,broker=1等等,你有几个kafka就这样累积下去不要出现重复就行)

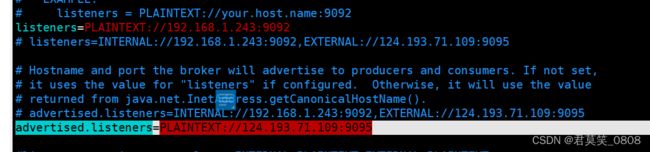
修改listeners = PLAINTEXT://your.host.name:9092 中的ip为当前kafka所在的服务器的ip(此处是内网ip)
修改advertised.listeners=PLAINTEXT://your.host.name:9095 中的ip为当前kafka所在的服务器的ip(此处是外网ip)
两个ip配置主要是用来做内外网映射
 修改一下日志文件的存储位置(位置放在你已存在的目录下,不一定要跟我这个一致)
修改一下日志文件的存储位置(位置放在你已存在的目录下,不一定要跟我这个一致)
修改zookeeper集群的连接地址为你自己的zookeeper集群地址

4、启动kafka
修改完成之后,保存退出,进入到kafka的bin目录下,执行以下命令来启动kafka
sh kafka-server-start.sh ../config/server.properties
nohup ./kafka-server-start.sh ../config/server.properties > kafka.log 2>&1 &
5、拷贝
拷贝到另外两台服务器
cd /home/kafka
tar -zcf kafka.tar.gz kafka
scp kafka.tar.gz root@lmb2:/home/kafka
scp kafka.tar.gz root@lmb3:/home/kafka
按照步骤来执行,一般不会出错,如果出现错误,可能是zk集群地址不对,或者是broker.id的值没有修改导致出现3台重复的broker,
这里只给出kafka集群中一个kafka的配置步骤,其他的kafka搭建过程和这个是一样的,重复的步骤就不多写了,没什么区别,只需要修改listeners = PLAINTEXT://your.host.name:9092和broker.id即可,其他一样,不管集群有几个kafka,都是一样的配置,
6、操作指南
6.1 创建topic
cd /home/kafka/kafka
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test

nohup sh kafka-server-start.sh ../config/server.properties >>/data/kafka2-logs/kafka.log 2>&1 & 后台启动
./kafka-topics.sh --create --bootstrap-server 192.168.197.2:9092,192.168.197.3:9092,192.168.197.4:9092,192.168.197.5:9092,192.168.197.6:9092 --topic test --partitions 3 --replication-factor 3
6.2 创建主题
./kafka-console-producer.sh --broker-list 192.168.197.2:9092 --topic test 生产消息
./kafka-console-consumer.sh --bootstrap-server 192.168.197.2:9092 --topic test --from-beginning 消费消息
./kafka-topics.sh --describe --topic test --bootstrap-server 192.168.197.3:9092 查看主题
7、 监控
监控使用 kafka-console-ui
三、客户端参数调试
3.1 kafka客户端发送数据过程
request.required.acks
-
0 生产者从不等待ack
-
1 生产者等Leader写成功后返回
-
-1 /all 生产者Leader和所有ISR中的Follower写成功后返回
buffer.memory
生产者缓冲区大小,生产者会把数据写到缓冲区,封装成batch,然后发送到服务端,如果写入过快,生产者将阻塞 max.block.ms 之后,抛出异常。
batch.size
多条消息组装成一个batch,达到batch.size后,才发送到服务端。
retries
设置一个比零大的值,客户端如果发送失败则会重新发送。注意,这个重试功能和客户端在接到错误之后重新发送没什么不同。如果max.in.flight.requests.per.connection 没有设置为 1,有可能改变消息发送的顺序,因为如果 2 个批次发送到一个分区中,并第一个失败了并重试,但是第二个成功了,那么第二个批次将超过第一个。
retries.backoff.ms
结合retries使用,失败后多少时间后重试。
linger.ms
指逗留时间,这个逗留指的是消息不立即发送,而是逗留这个时间后一块发送。这个设置是比较有用的,有时候消息产生的要比能够发送的要快,这个参数完美的实现了一个人工的延迟,使得大批量可以聚合到一个 Batch 里一块发送, 当 Batch 慢了的话,会忽略这个参数立即发送。默认值 : 0。
四、消费者参数调试
五、遇到的问题及解决
1、RecordTooLargeException
1.1.Kafka者配置文件 server.properties中添加
message.max.bytes=100000000(100M)
replica.fetch.max.bytes=100000000(100M)每个分区试图获取的消息字节数。
要大于等于message.max.bytes1.2 生产者配置文件producer.properties中添加
max.request.size = 100000000(100M)请求的最大大小为字节。要小于 message.max.bytes1.3 消费者配置文件consumer.properties中添加
fetch.message.max.bytes=100000000(100M)每个提取请求中为每个
主题分区提取的消息字节数。要大于等于message.max.bytes2、网络和io操作线程配置优化
2.1 broker处理消息的最大线程数(默认为3)
num.network.threads=cpu核数+1
2.2 broker处理磁盘IO的线程数
num.io.threads=cpu核数*2
3、log数据文件刷盘策略
3.1 每当producer写入10000条消息时,刷数据到磁盘
log.flush.interval.messages=10000
3.2 每间隔1秒钟时间,刷数据到磁盘
log.flush.interval.ms=1000
3.3 保留三天,也可以对个别主题单独设置 (log.cleaner.delete.retention.ms)
log.retention.hours=72
3.4、Replica相关配置
offsets.topic.replication.factor:3
# 这个参数指新创建一个topic时,默认的Replica数量,Replica过少会影响数据的可用性,太多则会白白浪费存储资源,一般建议在2~3为宜。
消费者与分区数的关系
分配关系有1、range(取余) 2、轮询分配
参考链接:https://www.cnblogs.com/cjsblog/p/9664536.html
3.5、offsets.topic.replication.factor
__consumer_offsets:作用是保存 Kafka 消费者的位移信息
offsets.topic.replication.factor
解释:该值默认为1。表示kafka的内部topic consumer_offsets副本数。当该副本所在的broker宕机,consumer_offsets只有一份副本,该分区宕机。使用该分区存储消费分组offset位置的消费者均会收到影响,offset无法提交,从而导致生产者可以发送消息但消费者不可用。所以需要设置该字段的值大于1。
3.6 自动创建topic
是否允许自动创建topic。如果设为true,那么produce,consume或者fetch metadata一个不存在的topic时,就会自动创建一个默认replication factor和partition number的topic。
auto.create.topics.enable = false (default => true)
3.7 消费者启动后很久之后才消费
metadata.max.age.ms 强制刷新元数据时间,毫秒,默认300000,5分钟
3.8 kafka集群扩容
kafka数据迁移实践 - 腾讯云开发者社区-腾讯云
参考链接;kafka系列(15):集群配置参数server.properties_快快乐乐#的博客-CSDN博客