Spark Sql对列的操作
SQL写得好,工作随便找
本篇博客讲的是关于Spark SQL中对于列的操作。在SQL中对列的操作有起别名,转化类型等在Spark SQL中同样也支持,下面来看一看把
Spark withColumn()语法和用法
withColumn用于操作DataFrame上所有行或选定行的列值
withCplumn执行之后,会产生一个新的DataFrame
tips:
如果用withColumn同时更新多个列的情况下,可能会有性能问题甚至StackOverflowException为避免这种情况,可以把该dataFrame注册为临时表,注册完之后进行SQL上面的更新。这样不会有性能问题
创建元数据
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{StringType, StructType}
//创建元数据,里面有嵌套数据
//("Janmes","","Smith")是嵌套字段
val data = Seq(Row(Row("James;","","Smith"),"36636","M","3000"), Row(Row("Michael","Rose",""),"40288","M","4000"), Row(Row("Robert","","Williams"),"42114","M","4000"), Row(Row("Maria","Anne","Jones"),"39192","F","4000"), Row(Row("Jen","Mary","Brown"),"","F","-1") )
//创建StructType对象,并且添加字段名
val schema = new StructType()
.add("name",new StructType()
.add("firstname",StringType)
.add("middlename",StringType)
.add("lastname",StringType))
.add("dob",StringType)
.add("gender",StringType)
.add("salary",StringType)
//创建DataFrame
val df = spark.createDataFrame(spark.sparkContext.parallelize(data),schema)向DataFrame添加一个新列
要创建新列,请将所需的列名传递给withColumn()函数的第一个参数,第一个参数中的新的列名不能出现在原本的字段名当中,如果出现,会更新该列的值,使用lit()函数可以将常量值加到DataFrame。
df.withColumns("Country",lit("USA")).show()
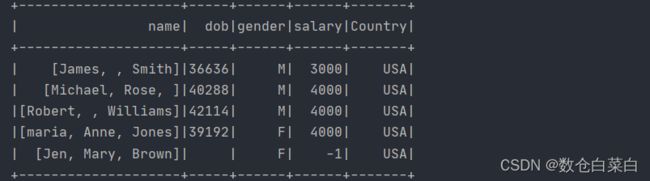
这个操作如果用SQL的话,就是
select name,dob,gender,salary,"USA" as Country from table_name
更改现有列的值
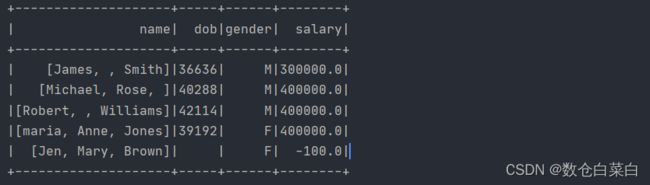
将现有的列名作为第一个参数,并将要分配的值作为第二个参数传递
df.withColumn("salary",df("salary") * 100).show()
此代码将“salary”字段的值扩大一百倍。
换作SQL语句就是
select salary * 100 as salary from table_name
从现有列派生新列
要创建新列,第一个参数就是新的列名,第二个参数就是通过现有的列进行操作分配
df.withColumn("CopiedColumn",df("salary) * -1).show()
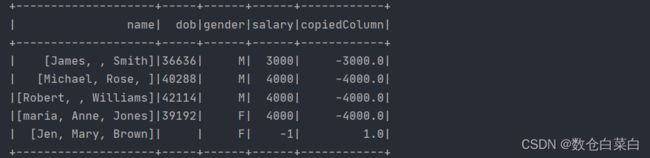
换做SQL语句就是
select salary,salary*-1 as "copieldColumn" from table_name
更改列数据类型
通过cast进行转化类型
df.withColumn("salary",df("salary").cast("Integer")).show

'换做SQL语句
select name,cast(salary as Int) as salary from table_name
添加,替换或更新多个列
使用withColumn增加多个列的时候,不建议使用该函数,因为可能会造成性能下降,不过可以创建成视图,通过SQL语句进行操作
df.createOrReplaceTempView("Person")
sparkSession.sql("SELECT salary*100 as salary, salary*-1 as CopiedColumn,
'USA' as country FROM PERSON").show()将列拆分成多列
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark SQL")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
import sparkSession.implicits._
//字段名
val seq = Seq("name", "address")
//数据集合
val data = Seq(("Robert,Smith", "1 Main st,Newark,NJ,92537")
, ("maria,Garcia", "3456 Walnut st,newWark,NJ,94732"))
//创建dataFrame
val dataFrame = sparkSession.createDataFrame(data).toDF(seq: _*)
dataFrame.printSchema()关于将列拆分成多列,这个案例是这样的。
首先是两个字段 name address
数据中name字段为"Robert,Smith" address字段为("1 Main st,Newark,NJ,92537")
现在的需求就是将元数据拆开,分裂成多个数据,同理元数据分裂了,字段如果还是原来的两个字段名,就不行了。因此也需要增加新的字段。
将name字段按照逗号进行切分,address字段根据逗号进行切分。
切分完之后就是
Robert Smith 1 Main st Newark NJ 92537
将拆分完后的数据转换为dataFrame,并且创建字段名
val value1 = dataFrame.map(f => {
//对name字段进行切分
val value = f.getAs[String](0).split(",")
//对address字段进行拆分
val strings = f.getAs[String](1).split(",")
(value(0), value(1), strings(0), strings(1), strings(2), strings(3)) })
//转换为dataframe并且填充字段名
val dataFrame1 = value1.toDF("First Name", "Last Name",
"Address Linel", "City", "State", "ZipCode")
dataFrame1.printSchema() dataFrame1.show()看一下转化完成后的数据。

使用withColumnRenamed -重命名DataFrame列名
df.withColumnRenamed("dob","DateOfBirth")
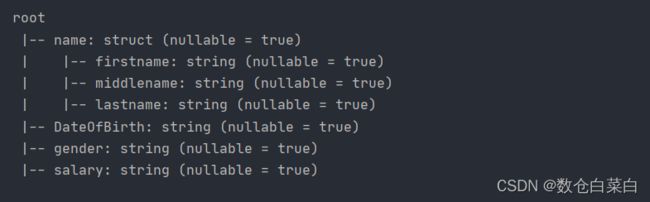
可以看到schema已经发生了变化,其实经过这种转化函数之后,就会变成新的dataframe,原来的datafrmae并没有发生改变。
使用withColumnRenamed--重命名多个列
val df2 = df.withColumnRenamed("dob","DateOfBirth") .withColumnRenamed("salary","salary_amount") df2.printSchema()重命名嵌套列
首先创建一个新的StructType,里面是新的嵌套列
val schema2 = new StructType()
.add("fname",StringType)
.add("middlename",StringType)
.add("lname",StringType)对嵌套字段进行更改列名
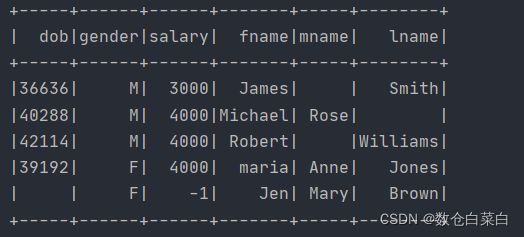
df.select(col("name").cast(schema2), col("dob"), col("gender"), col("salary")) .printSchema()
这个cast是转化类型的,将嵌套字段name转换成schema这个StructType类型。
看一下结果把
总结:
为什么会写这部分内容呢?
因为就在前天,本来是在做项目的,结果项目中关于StructType并不清楚怎么做,当时导包也总出现错误,现在学习了这一片段的知识。明天就可以开始更新电影分析的项目了。
明天的电影分析项目更加精彩