分布式事务——seata简单使用
1. 本地事务
1.1 事务的基本性质
数据库事务的几个特性:原子性、一致性、隔离性或独立性、持久性简称ACID
1)原子性;一系列的操作整体不可拆分,要么同时成功,要么同时失败
2)一致性:数据在事务前后,业务整体一致
3)隔离性:事务之间互相隔离
4)持久性:一旦事务成功,数据一定会落盘在数据库
在以往的单体应用中,我们多个业务操作使用同一事务连接操作不同的数据表,一旦有异常,我们可以很容易的整体回滚
1.2 事务隔离级别
1) READ UNCOMMITTED(读未提交):该隔离级别的事务会读到其它未提交事务的数据,此现象也称之为脏读
2)READ COMMITTED(读已提交):一个事务可以读取另一个已提交的事务,多次读取会造成不一样的结果,此现象称之为不可重复读问题,Oracle和SQL Server的默认隔离级别
3)REPEATABLE READ(可重复读):该隔离级别是MySQL默认的隔离级别,在同一个事务里,select的结果是事务开始时时间点的状态,因此,同样的select操作读到的结果会是一致的,但是,会有幻读现象。MySQL的InnoDB引擎可以通过next-key locks机制来避免幻读
4)SERIALIZABLE(序列化):在该隔离级别下事务都是串行顺序执行的,mysql数据库的InnoDB引擎会给操作隐式的加一把读共享锁,从而避免了脏读、不可重读复读和幻读问题。
1.3 事务的传播行为
1)PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置
2)PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行
3)PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常
4)PROPAGATION_REQUIRES_NEW:创建新事务,无论当前存不存在事务,都创建新事务
5)PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起
6)PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常
7)PROPAGATION_NESTED:如果当前存在事务,则嵌套事务内执行。如果当前没有事务,则执行PROPAGATION_REQUIRED类似的操作
1.4 SpringBoot中的本地事务问题
1.4.1 事务的自动配置
TransactionAutoConfiguration
1.4.2 事务的一个巨坑
同一个对象内事务方法互调默认失效,原因是同一个对内的方法互调就相当于是将B方法copy到A方法,而boot中事务是使用代理对象来控制的,因此本地方法的互调就绕过了代理对象,从而导致在B上设置的事务行为不起作用了;但是如果同一个对象内调用的是其他类的方法,那么不会出现这个问题。
解决方案:使用代理对象来调用事务方法
1)引入AOP场景启动器
2)在启动类上使用注解@EnableAspectJAutoProxy开启AspectJ动态代理功能(即使没有接口也可以创建动态代理),因为默认使用的是JDK的动态代理。
3)并设置属性exposeProxy=true。即@EnableAspectJAutoProxy(exposeProxy=true),表示对外暴露代理对象
4)用代理对象的类来调用。例如:OrderService order = (OrderService)AopContext.currentProxy(); 这样就可以使用这个代理对象来进行方法内的事务互调了。
2. 分布式事务
分布式系统经常出现的异常:机器宕机、网络异常、消息丢失、消息乱序、数据错误、不可靠TCP‘存储数据丢失’。分布式事务是企业集成中的一个技术难点,也是每一个分布式系统架构中都会涉及到的一个东西,特别是在微服务架构中,几乎可以说是无法避免。
一句话就是,一次业务操作需要垮多个数据源或需要垮多个系统进行远程调用,就会产生分布式事务问题
2.1 CAP定理与BASE理论
CAP原则又称CAP定理,指的是在一个分布式系统中:
1)一致性(Consistency):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
2)可用性(Availability):在集群中一部分节点故障后,集群整体是否还能够响应客户端的读写请求。(对数据更新具备高可用性)
3)分区容错性(Partition tolerance):大多数分布式胸膛都分布在多个子网络。每个子网络就叫做一个区(partition)。分区容错的意思是,区间通信可能失败。例如:一台服务器放在中国,另一台放在美国,这两个就是两个区,他们之间可能无法通信
CAP原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾
2.2 Base理论
是对CAP理论的延伸,思想是即使无法做到强一致性(CAP的一致性就是强一致性),但可以采用适当的采取弱一致性,即最终一致性。
Base是指:
2.2.1 基本可用(Basically Available)
基本可用是指分布式系统在出现故障的时候,允许损失大部分可用性(例如响应时间、功能上的可用性),允许损失部分可用性。需要注意的是,基本可用绝不等价于系统不可用。
1)响应时间上的损失,正常情况下搜索引擎需要在0.5秒之内返回给用户相应的查询结果,但由于出现故障(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了1-2秒。
2)功能上的损失,购入网站在购物高峰(如:双十一)时,为了保护系统的稳定性,部分消费者可能会被引导到一个降级页面。
2.2.2 软状态(Soft State)
软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据会有多个副本,允许不同副本同步的延时就是软状态的体现。mysql replication的异步复制也是一种体现。
2.2.3 最终一致性(Eventual Consistency)
最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况
2.3 强一致性、弱一致性、最终一致性
从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取额不同策略,决定了不同的一致性。对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。如果能容忍后续部分的部分或者全部访问不到,则是弱一致性。如果经过一段时间后,要求能访问到更新后的数据,则是最终一致性。
分布式事务就是讨论围绕进行怎么样的一致性来做的。
3. 分布式事务几种方案
3.1 2PC模式
数据库支持2PC(2 phase commit),又叫做XA Transactions。
mysql从5.5版本开始支持,SQL server2005开始支持,Oracle7开始支持。其中,XA是一个两阶段提交协议,该协议分为以下两个阶段:
1)第一阶段:事务协调器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交。
2)第二阶段:事务协调器要求每个数据库提交数据。
其中,如果有任何一个数据库否决此次提交,那么所欲数据库都会被要求回滚它们在此事务中的那部分信息。

这种方式(XA协议)概述
1)XA协议比较简单,而且一旦商业数据库实现了XA协议,使用分布式事务的成本也比较低。
2)XA性能不理想,特别是在交易下单链路,往往并发量很高,XA无法满足高并发场景
3)XA目前在商业数据库支持的比较理想,在mysql数据库中支持的不太理想,mysql的XA实现,没有记录prepare阶段日志,主备切换回导致主库与备库数据不一致
4)许多nosql也没有支持XA,这让XA的应用场景变得非常狭隘
5)也有3PC,引入了超时机制(无论协调者还是参与者,在向对方发送请求后,若长时间未收到回应则做出相应处理)
3.2 柔性事务
刚性事务:遵循ACID原则,强一致性
柔性事务:遵循BASE理论,最终一致性
与刚性事务不同,柔性事务允许一定时间内,不同节点的数据不一致,但要求最终一致。
3.2.1 TCC事务补偿型方案
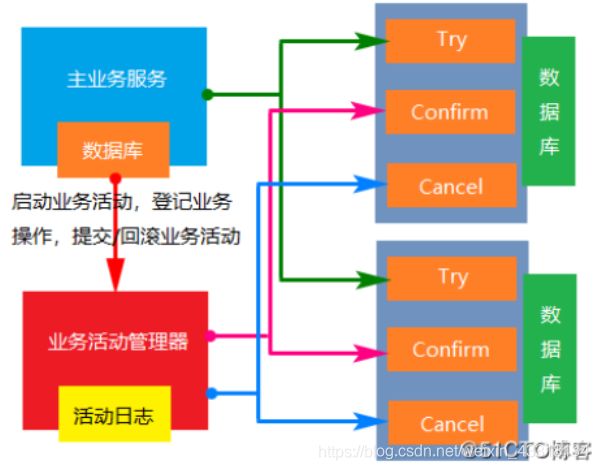
一阶段prepare行为:调用自定义的prepare逻辑。
二阶段commit行为:调用自定义的commit逻辑
二阶段rollback行为:调用自定义的rollback逻辑
所谓TCC模式,是指支持把自定义的分支事务纳入到全局事务的管理中
3.2.2 最大努力通知型方案
按规律进行通知,不保证数据一定能通知成功,但会提供可查询操作接口进行核对。这种方案主要用在与第三方系统通讯时,比如;调用微信或支付宝支付后的支付结果通知。这种方案也是结合MQ进行实现,例如;通过MQ发送http请求,设置最大通知次数。达到通知次数后即不在通知。
案例:银行通知、商户通知等(各大交易业务平台间的商户通知;多次通知、查询校对、对账文件),支付宝的支付成功异步回调等
3.2.3 可靠消息+最终一致性方案(异步确保型)
实现:业务处理服务在业务事务提交之前,向实时消息服务请求发送消息,实时消息服务只记录消息数据,而不是真正的发送。业务处理服务在业务事务提交之后,向实时消息服务确认发送。只有在得到确认发送指令后,实时消息服务才会真正发送
4. 分布式事务解决技术——Seata
Seata是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务
官方参考地址:http://seata.io/zh-cn/
4.1 一个典型的分布式事务过程
分布式事务处理过程-ID+三组件模型
Transaction ID(XID):全局唯一的事务id
三组件概念:
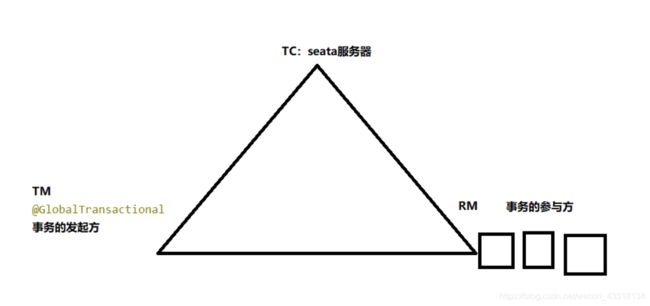
1)Transaction Coordinator(TC):事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚
2)Transaction Manager(TM):控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议(也就是添加了注解@GlobalTransactional的方法是事务发起者)
3)Resource Manager(RM):控制分支事务,负责分支注册、状态汇报,并接受事务协调的指令,驱动分支(本地)事务的提交和回滚(@GlobalTransactional方法下面需要控制的远程方法的事务)
4.2 使用步骤(使用文件方式)
注;生产都是使用db方式
4.2.1 给每个服务的每个数据库添加数据表UNDO_LOG
CREATE TABLE `undo_log` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`branch_id` BIGINT(20) NOT NULL,
`xid` VARCHAR(100) NOT NULL,
`context` VARCHAR(128) NOT NULL,
`rollback_info` LONGBLOB NOT NULL,
`log_status` INT(11) NOT NULL,
`log_created` DATETIME NOT NULL,
`log_modified` DATETIME NOT NULL,
`ext` VARCHAR(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;4.2.2 下事务协调器——seata-server
从 https://github.com/seata/seata/releases 下载
4.2.3 在项目导入seata依赖
com.alibaba.cloud
spring-cloud-starter-alibaba-seata
注意:查看引入的依赖,可以看到一个jar,如图:

该版本就是我们seata-server的版本即版本是071,对应官方版本,如图:

因此,需要下载这个版本
4.2.4 启动seata
打开刚才下载的文件,进入conf目录,可以看到两个比较重要的配置文件
1)配置中心:file.conf
2)注册中心配置:registry.conf
修改注册中心,将注册中心类型指定为nacos,并指定注册中心服务器地址。
然后,进入bin目录,根据系统选择合适的seata-server启动。例如;Windows系统,双击seata-server.bat即可,如图:
查看nacos注册中心,发现,seata成功的注册进去了,如图:
4.2.5 配置代理数据源
因为 Seata 通过代理数据源实现分支事务,如果没有注入,事务无法成功回滚
查看boot的默认的数据源配置,打开数据源自动配置类DataSourceAutoConfiguration,找到PooledDataSourceConfiguration的import,如图:

boot默认用的是Hikari数据源。
配置类如下:
package com.bjc.gulimall.order.config;
import com.zaxxer.hikari.HikariDataSource;
import io.seata.rm.datasource.DataSourceProxy;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.jdbc.DataSourceProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.util.StringUtils;
import javax.sql.DataSource;
/**
* @描述:seata的配置文件
* @创建时间: 2021/3/27
*/
@Configuration
public class MySeataConfig {
/*
* 因为DataSourceAutoConfiguration的配置依赖DataSourceProperties,该配置类定义了数据源的所有信息
* */
@Autowired
DataSourceProperties dataSourceProperties;
@Bean
public DataSource dataSource(DataSourceProperties dataSourceProperties){
/*
* 打开boot的默认数据源Hikari,可以看到 HikariDataSource dataSource = createDataSource(properties, HikariDataSource.class);
* 进入 createDataSource 方法,可以看到boot就是使用的dataSourceProperties来创建的数据源,
* properties.initializeDataSourceBuilder().type(type).build();
* */
// 也使用boot默认的数据源
Class type = HikariDataSource.class;
HikariDataSource dataSource = (HikariDataSource) dataSourceProperties.initializeDataSourceBuilder().type(type).build();
if (StringUtils.hasText(dataSourceProperties.getName())) {
dataSource.setPoolName(dataSourceProperties.getName());
}
// 将数据源用seata代理包装,返回自定义的代理数据源
DataSourceProxy dataSourceProxy = new DataSourceProxy(dataSource);
return dataSourceProxy;
}
}
4.2.6 将seata的两个配置文件都copy到每个微服务
如图:
官网警告:
file.conf 的 service.vgroup_mapping 配置必须和spring.application.name一致
在 org.springframework.cloud:spring-cloud-starter-alibaba-seata的org.springframework.cloud.alibaba.seata.GlobalTransactionAutoConfiguration类中,默认会使用 ${spring.application.name}-fescar-service-group作为服务名注册到 Seata Server上,如果和file.conf中的配置不一致,会提示 no available server to connect错误
这个地方的意思就是,在file.conf的service下的vgroup_mapping后面需要跟当前应用名称 + 【 -fescar-service-group 】,例如;
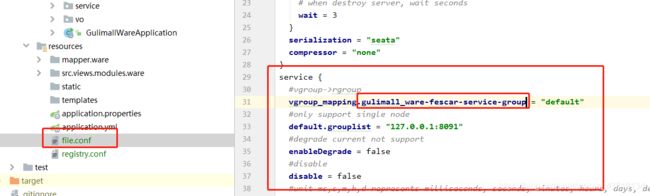
注意:也可以通过配置 spring.cloud.alibaba.seata.tx-service-group修改后缀,但是必须和file.conf中的配置保持一致
例如:在application.paoperties中配置如下内容:
spring.cloud.alibaba.seata.tx-service-group=xxx4.2.7 开启全局事务
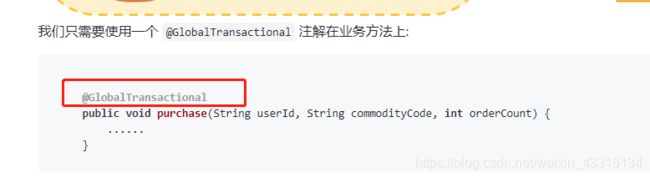
根据官方文档介绍,开启全局事务很简单,只需要使用一个 @GlobalTransactional 注解在业务方法上,官方文档如图:
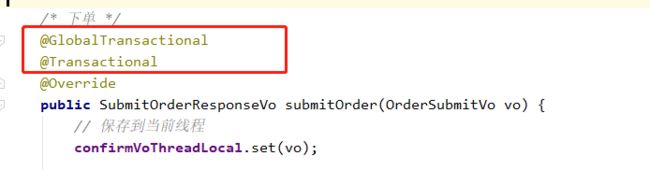
注意:该注解需要加在大事务的入口,方法上也要加上本地事务注解@Transactional,分支事务(每一个远程的小事务)只需要加上@Transactional注解即可,如图:
大事务
分支事务
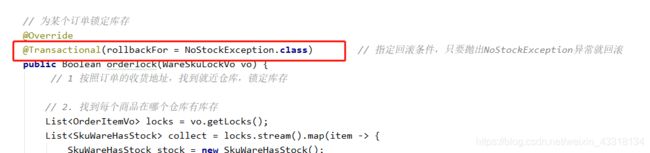
4.3 启动测试
故意在远程调用之后加上异常,如图:

调用成功,订单没插入数据,但是,库存扣减了数据,产生了数据不一致问题。加上注解 @GlobalTransactional之后,事务成功的控制住了。
5. seata详细
5.1 配置文件解释
5.1.1 注册中心配置(registry.conf)
1)registry:用于配置注册中心相关的信息
1.1 type:指定注册中心类型
1.2 nacos/eureka...:对应的注册中心的配置
1.3 file:如果type指定为file的话,这个地方就需要配置,值就是file.conf
如图:

2)config:代表seata的配置
2.1 type:指定配置中心类型。默认是file,在同类目录下有一个file.conf,该文件配置了seata的所有信息。如果将type指定为nacos,那么,可以将file.conf全部搬家到nacos
5.1.2 配置中心配置
在seata的conf目录下,有一个file.conf,该文件就是对seata的配置
1)transport:表示传输配置
1.1 type:配置传输协议类型
1.2 server:服务类型。默认是NIO
1.3 heartbeat:是否有心跳连接。默认true
1.4 thread-factory:线程工厂
2)client:客户端配置
3)store:事务日志存储配置
3.1 type:事务日志存储类型,默认是file
3.2 file:如果type=file,那么就需要指定file。
3.3 db:如果type=db,那么就需要指定数据库相关信息。包括数据库连接地址,连接池,账号密码、三张表(global_table、branch_table、lock_table)
5.2 Seata-Server安装
1)下载对应的版本
2)解压到指定目录进行相应的配置(主要修改:自定义事务组名称+事务日志存储模式为db+数据库连接,即file.conf文件的service模块与store模块)
3)数据库新建库seata
建表语句在conf目录下的db_store.sql文件,新建一个数据库作为总的数据库。例如:seata
4)启动
5.3 seata踩坑记录
5.3.1 关于配置文件
官方介绍的方式有两种,第一种是直接将seata的两个配置文件拷贝到对应的微服务,然后修改vgroup_mapping后面的key为微服务名+my_test_tx_group,但是,使用该方式,只有第一个服务启动成功,后面的全部失败了。
后来改成yml配置的方式;
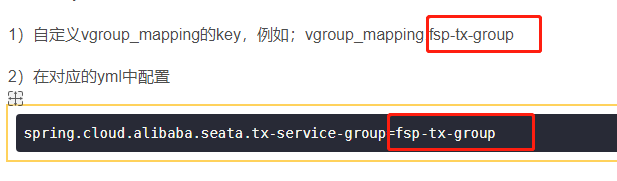
1)自定义vgroup_mapping的key,例如;vgroup_mapping.fsp-tx-group
2)在对应的yml中配置
spring.cloud.alibaba.seata.tx-service-group=fsp-tx-group注意:与file.conf的 vgroup_mapping的key的值保持一致即可,如图:
5.3.2 关于数据源
有点服务会报数据源的错误,这时候,可以在启动类上排除掉boot的自动数据源配置,使用我们自己的数据源配置,如图;
![]()
5.3.3 关于数据表
表db_undo_log是在每个数据库都需要创建一个,在seata的总表新建三张表,如图:
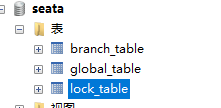
这些表也在seata的conf目录下。
注意:如果采取的file的方式,不需要这三张表
6. 采用数据库的方式
步骤与file方式一样,只是多加了几个补充步骤:
1)新建一个库,用于存放三张seata业务表

在配置store的时候,数据库连接信息就是用的这个库
2)修改file.conf配置文件的store配置,如图:

3)将数据源配置改成德鲁伊
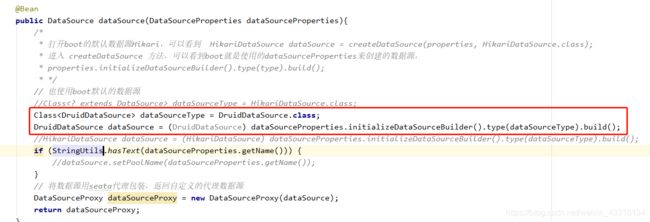
其他的步骤与file的一模一样
注意:生产上一般用1.0以上的版本
7. seata工作流程
seata有四大工作模式,默认使用的是就是无侵入自动补偿的事务模式(AT模式)
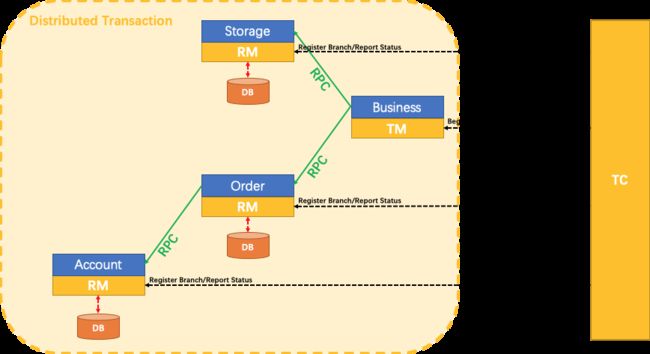
1)TM开启分布式事务(TM向TC注册全局事务记录)
2)按业务场景,编排数据库、服务等事务中资源(RM向TC会报资源准备状态)
3)TM结束分布式事务,事务一阶段结束(TM通知TC提交/回滚分布式事务)
4)TC汇总事务信息,决定分布式事务是提交还是回滚
5)TC通知所有RM提交/回滚资源,事务二阶段结束
从工作流程可以知道seata的工作流程可以简单的概括为TC——> TM ——> RM
关系可以用如下图表示:
AT模式如何做到对业务的无侵入的?
一阶段:业务数据和回滚日志记录(我们在每个库中建立的表undo_log)在同一个本地事务中提交,释放本地锁和连接资源(lock_table、branch_table、global_table)
在一阶段,seata会拦截“业务SQL”:
1)解析SQL语义,找到“业务SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”
2)执行“业务SQL”更新业务数据,在业务数据更新之后,将其保存成“after image”,最后生成行锁。
以上操作全部在一个数据事务内完成,这样保证了一阶段操作的原子性

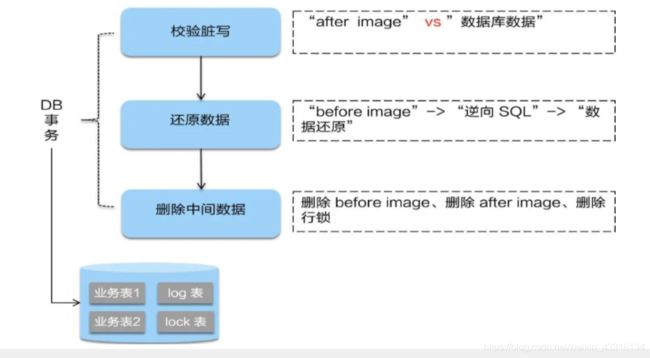
二阶段:
1)提交异步化,非常快速的完成。
二阶段如果是顺利提交的话,因为“业务SQL”在一阶段已经提交至数据库,所以seata框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。

2)二阶段回滚,回滚通过一阶段的回滚日志进行反向补偿
二阶段如果是回滚到话,seata就需要回滚一阶段已经执行的“业务SQL”,还原业务数据。回滚方式便是用“before image”还原业务数据;但在还原前首先要校验脏写,对比“数据库当前业务数据”和‘after image’,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理
总结:seata工作原理就是spring的AOP思想+回退反写机制