分布式事务框架Seata
分布式事务框架Seata sei达
一. 分布式事务前言
1. 数据库管理系统中事务(transaction)的四个特性:简称ACID(这种特性简称刚性事物)
原子性(Atomicity):原子性是指事务是一个不可再分割的工作单元,事务中的操作要么都发生,要么都不发生。
一致性(Consistency):一致性是指在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏;这是说数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。
隔离性(Isolation):多个事务并发访问时,事务之间是隔离的,一个事务不应该影响其它事务运行效果。
持久性(Durability):持久性,意味着在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。(完成的事务是系统永久的部分,对系统的影响是永久性的,该修改即使出现致命的系统故障也将一直保持)
2. CAP理论(帽子原理)
由于对系统或者数据进行了拆分,我们的系统不再是单机系统,而是分布式系统,针对分布式系统的CAP原理包含如下三个元素:
C:Consistency 一致性:在分布式系统中的所有数据 备份,在同一时刻具有同样的值,所有节点在同一时刻读取的数据都是最新的数据副本(例如:Redis主从复制)
A:Availability 可用性:好的响应性能。完全的可用性指的是在任何故障模型下,服务都会在有限的时间内处理完成并进行响应(例如:Ngnix+tomcat负载均衡)
P: Partition tolerance 分区容忍性:尽管网络上有部分消息丢失,但系统仍然可继续工作
CAP原理指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。因此在进行分布式架构设计时,必须做出取舍。而对于分布式数据系统,分区容忍性是基本要求,否则就失去了价值,所以一般而言P是必须要满足的(即可以容忍宕机或者网络故障,因为P是大概率事件,有些情况不可避免)。因此设计分布式数据系统,就是在一致性和可用性之间取一个平衡。(分布式系统中,网络出现故障,不可能同时保持一致性+可用性)。
对于大多数web应用,其实并不需要强一致性,因此牺牲一致性而换取高可用性,是目前多数分布式数据库产品的方向。 当然,牺牲一致性,并不是完全不管数据的一致性,否则数据是混乱的,那么系统可用性再高分布式再好也没有了价值。牺牲一致性,只是不再要求关系型数据库中的强一致性,而是只要系统能达到最终一致性即可,考虑到客户体验,这个最终一致的时间窗口,要尽可能的对用户透明,也就是需要保障“用户感知到的一致性”。通常是通过数据的多份异步复制来实现系统的高可用和数据的最终一致性的,“用户感知到的一致性”的时间窗口则取决于数据复制到一致状态的时间。
3. Base理论
BASE理论是指,Basically Available(基本可用)、Soft-state( 软状态/柔性事务)、Eventual Consistency(最终一致性)。是基于CAP定理演化而来,是对CAP中一致性和可用性权衡的结果。
核心思想:即使无法做到强一致性,但每个业务根据自身的特点,采用适当的方式来使系统达到最终一致性。
① 基本可用:指分布式系统在出现故障的时候,允许损失部分可用性,保证核心可用。但不等价于不可用。比如:搜索引擎0.5秒返回查询结果,但由于故障,2秒响应查询结果;网页访问过大时,部分用户提供降级服务等。
② 软状态:软状态是指允许系统存在中间状态,并且该中间状态不会影响系统整体可用性。即允许系统在不同节点间副本同步的时候存在延时。
③ 最终一致性:系统中的所有数据副本经过一定时间后,最终能够达到一致的状态,不需要实时保证系统数据的强一致性。最终一致性是弱一致性的一种特殊情况。BASE理论面向的是大型高可用可扩展的分布式系统,通过牺牲强一致性来获得可用性。ACID是传统数据库常用的概念设计,追求强一致性模型。
4. 柔性事务和刚性事务
柔性事务满足BASE理论(基本可用,最终一致),刚性事务满足ACID理论。
5. 两段提交协议 - 2PC(Two-PhaseCommit)
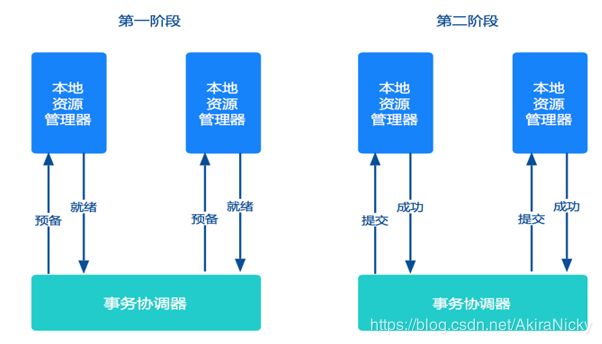
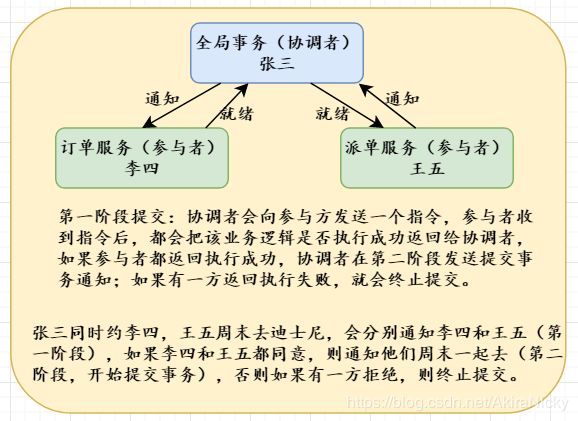
第一阶段: 准备阶段:协调者向参与者发起指令,参与者评估自己的状态,如果参与者评估指令可以完成,则会写redo(数据修改记录)或者undo(回滚)日志,然后锁定资源,执行操作,但并不提交。
第二阶段:如果每个参与者明确返回准备成功,则协调者向参与者发送提交指令,参与者释放锁定的资源,如果任何一个参与者明确返回准备失败,则协调者会发送中指指令,参与者取消已经变更的事务,释放锁定的资源。
两阶段提交方案应用非常广泛,几乎所有商业OLTP数据库都支持XA协议。但是两阶段提交方案锁定资源时间长,对性能影响很大,基本不适合解决微服务事务问题。
缺点:如果协调者宕机,参与者没有协调者指挥,则会一直阻塞。
三段提交协议 - 3PC(Three-PhaseCommit)
核心:在2pc的基础上增加了一个询问阶段(第一阶段),确认网络,避免阻塞,二三阶段就是上面的2pc
三阶段提交协议是两阶段提交协议的改进版本。它通过超时机制解决了阻塞的问题,并且把两个阶段增加为三个阶段:
询问阶段:协调者询问参与者是否可以完成指令,协调者只需回答是还是不是,而不需要做真正的操作,这个阶段超时导致中止
准备阶段:如果在询问阶段所有的参与者都返回可以执行操作,协调者向参与者发送预执行请求,然后参与者写redo和undo日志,执行操作,但是不提交操作;如果在询问阶段任何参与者返回不能执行操作的结果,则协调者向参与者发送中止请求,这里的逻辑与两阶段提交协议的的准备阶段是相似的,这个阶段超时导致成功
提交阶段:如果每个参与者在准备阶段返回准备成功,也就是预留资源和执行操作成功,协调者向参与者发起提交指令,参与者提交资源变更的事务,释放锁定的资源;如果任何一个参与者返回准备失败,也就是预留资源或者执行操作失败,协调者向参与者发起中止指令,参与者取消已经变更的事务,执行undo日志,释放锁定的资源,这里的逻辑与两阶段提交协议的提交阶段一致
二. Seata简介
Seata:简易可扩展的自治式分布式事务管理框架,其前身是fescar。是一种简单分布式事务的解决方案。
Seata给用户提供了AT、TCC、SAGA和XA事务模式,AT模式是阿里云中推出的商业版本GTS全局事务服务,目前Seata的版本已经到了1.0,我们本篇用是0.9版本。官网:GitHub - seata/seata: Seata is an easy-to-use, high-performance, open source distributed transaction solution.
Seata由3部分组成:
1.事务协调器(TC):维护全局事务和分支事务的状态,驱动全局提交或回滚,相当于LCN的协调者。
2.事务管理器(TM):定义全局事务的范围:开始全局事务,提交或回滚全局事务,相当于LCN中发起方。
3.资源管理器(RM):管理分支事务正在处理的资源,与TC进行对话以注册分支事务并报告分支事务的状态,并驱动分支事务的提交或回滚,相当于是LCN中的参与方。
白话文分析Seata实现原理:(与LCN基本一致,LCN前面博客有讲)
1. 发起方(TM)和我们的参与方(RM)项目启动之后和协调者TC保持长连接;
2. 发起方(TM)调用接口之前向 TC 获取一个全局的事务的id 为xid,注册到Seata中.Aop实现
3. 使用Feign客户端调用接口的时候,Seata重写了Feign客户端,在请求头中传递该xid。
4. 参与方(RM)从请求头中获取到该xid,方法执行完后不会立马提交,而是等待发起方调完接口后将状态提交到协调者,由协调者再告知参与方状态。
三. Seata环境搭建
下载对应Jar包并解压 
首先在订单库和派单库(三中的业务库)分别导入conf目录下的undo_log.sql(专门做回滚用的),新建一个seata库,并把db_store.sql导入到seata库,该库主要是存放seata服务端的一些信息。
接下来修改register.conf,type改为nacos,nacos里面localhost后面加上:8848,详细如下图:

最后修改file.conf,store里面mode值改为db,并修改MySQL连接信息,注意库为上面建立的seata库:

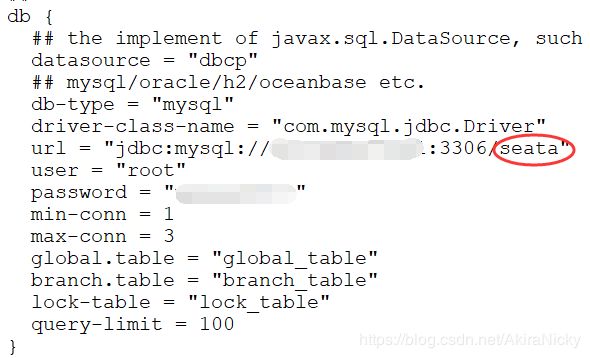
双击bin目录下的seata-server.bat,启动成功如下:(需先启动Nacos)

四. 客户端整合SeataServer
分布式事务解决方案有很多,如RabbitMQ最终一致性,RocketMQ事务消息,开源框架LCN,以及阿里Seata等。
业务场景:与前面博客RocketMQ解决分布式事务场景一致:
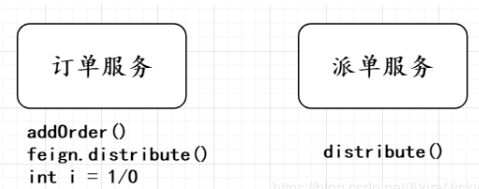
如图所示,相信我们都定过外卖,当提交订单后会在数据库生成一条订单,然后等待分配骑手送餐。
该业务在SpringCloud微服务架构拆分为两个服务,订单服务service-order和派单服务service-distribute,订单服务添加订单后,通过feign客户端调用派单服务的接口进行分配骑手,那么分布式事务问题就来了,当订单服务调用完第二行代码,派单接口执行完毕,咔嚓,第三行报了个错,那么订单接口会回滚,而派单则已提交事务,那么就造成数据不一致问题,故分布式事务问题,本文我们用Seata框架解决。
准备工作:分别建立订单表(左:order_table),派单表(右:distribute_table)


由于我们是SpringCloudAlibaba系列串讲,在前面博客建立好的service-impl添加如下依赖:
mysql
mysql-connector-java
com.alibaba.cloud
spring-cloud-alibaba-seata
2.1.1.RELEASE
org.mybatis.spring.boot
mybatis-spring-boot-starter
1.3.4
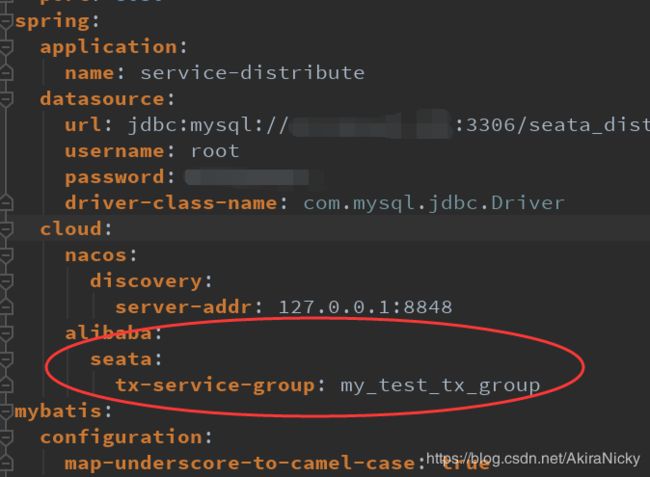
application.yml或者bootstrap.yml 添加Seata配置,且将上面修改好的file.conf和registry.conf拷贝到resources目录下:
订单服务,派单服务启动类分别移除默认DataSource配置:
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)在订单服务和派单服务分别建立配置文件:
package com.xyy.config;
import com.alibaba.druid.pool.DruidDataSource;
import io.seata.rm.datasource.DataSourceProxy;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.transaction.SpringManagedTransactionFactory;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
@Configuration
public class DataSourceProxyConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource dataSource() {
return new DruidDataSource();
}
@Bean
public DataSourceProxy dataSourceProxy(DataSource dataSource) {
return new DataSourceProxy(dataSource);
}
@Bean
public SqlSessionFactory sqlSessionFactoryBean(DataSourceProxy dataSourceProxy) throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSourceProxy);
sqlSessionFactoryBean.setTransactionFactory(new SpringManagedTransactionFactory());
return sqlSessionFactoryBean.getObject();
}
}接下来编写核心业务,首先编写派单服务:
public interface DistributeService {
@RequestMapping("/distributeOrder")
String distributeOrder(@RequestParam("orderNumber") String orderNumber);
}@RestController
public class DistributeServiceImpl implements DistributeService {
@Autowired
private DispatchMapper dispatchMapper;
@Override
public String distributeOrder(String orderNumber) {
DispatchEntity dispatchEntity = new DispatchEntity(orderNumber,136L);
dispatchMapper.insertDistribute(dispatchEntity);
return "派单成功";
}
}@Mapper
public interface DispatchMapper {
// 新增派单任务
@Insert("insert into distribute_table values (null,#{orderNumber},#{userId})")
@Options(useGeneratedKeys=true)
int insertDistribute(DispatchEntity distributeEntity);
}接下来编写订单服务:
@RestController
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private DistributeServiceFeign distributeServiceFeign;
@RequestMapping("/insertOrder")
@GlobalTransactional
public String insertOrder(int age) {
String orderNumber = UUID.randomUUID().toString(); // 用uuid暂时代替雪花算法
OrderEntity orderEntity = createOrder(orderNumber);
// 1.向订单数据库表插入数据
int result = orderMapper.insertOrder(orderEntity);
if (result < 0) {
return "插入订单失败";
}
// 2.调用派单服务,实现对该笔订单派单 远程调用派单接口
String resultDistribute = distributeServiceFeign.distributeOrder(orderNumber);
// 判断调用接口失败的代码...
int i = 1 / age;
return resultDistribute;
}
public OrderEntity createOrder(String orderNumber) {
OrderEntity orderEntity = new OrderEntity();
orderEntity.setOrderName("腾讯视频vip-年费");
orderEntity.setCreateTime(new Date());
orderEntity.setOrderMoney(new BigDecimal(300));
orderEntity.setOrderStatus(0); // 未支付
orderEntity.setGoodsId(101L); // 模拟商品id为101
orderEntity.setOrderNumber(orderNumber);
return orderEntity;
}
}
@FeignClient("service-distribute")
public interface DistributeServiceFeign extends DistributeService {
}@Mapper
public interface OrderMapper {
@Insert("insert into order_table values (null,#{orderNumber}, #{orderName}, #{orderMoney}, #{orderStatus}, #{goodsId},#{createTime})")
@Options(useGeneratedKeys=true)
Integer insertOrder(OrderEntity orderEntity);
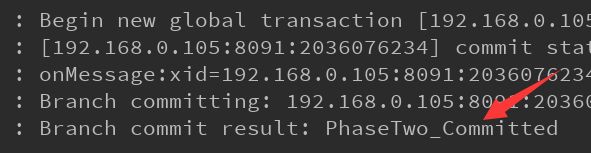
}分别启动Nacos,Seata,service-order,service-distribute,正常访问订单接口,则订单,派单表分别新增一条数据:



且两个控制台都会打印Commited日志:
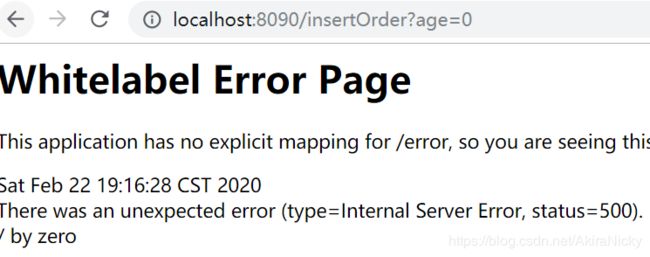
异常访问订单接口,则订单,派单表事务都会回滚,都不会新增数据,控制台都会打印Rollbacked:
【总结】:目前主流分布式事务解决方案有很多,如RabbitMQ最终一致性,RocketMQ事务消息,LCN假关闭,阿里Seata,可以根据业务合理选择解决方案,毕竟先把技术Get到,项目技术选型也会多一种选择
RabbitMQ实现分布式事务博客:2个服务分别建立消息表,记录是否消费
通过RabbitMQ实现分布式事务_郑..方..醒的博客-CSDN博客