分布式事务-Seata
章节目录:
-
- 一、本地事务
-
- 1.1 ACID特性
- 1.2 隔离级别
- 1.3 事务的传播行为
- 1.4 本地事务在分布式下的问题
- 二、分布式事务
- 三、相关概述及理论
-
- 3.1 CAP理论
- 3.2 CAP为什么不能三者兼顾?
- 3.3 Raft算法实现分布式系统一致性
- 3.4 Base理论
- 四、常见解决方案
-
- 4.1 2PC 模式
- 4.2 3PC 模式
- 4.3 柔性事务-TCC 事务补偿方案
- 4.4 柔性事务-最大努力通知方案
- 4.5 柔性事务-可靠消息+最终一致性方案(异步确保型)
- 五、分布式事务框架-Seata
-
- 5.1 核心概念及原理
- 5.2 AT模式
- 5.3 Seata 服务搭建
- 5.4 项目整合
- 5.5 更多官方示例
- 六、结束语
一、本地事务
在
JavaEE企业级开发的应用领域,为了保证数据的完整性和一致性,必须引入数据库事务的概念,所以事务管理是企业级应用程序开发中必不可少的技术。所谓本地事务,是指在单个数据源上进行数据的访问和更新,它仅在当前工程内有效。
1.1 ACID特性
-
数据库事务的四大特性:原子性(
Atomicity)、一致性(Consistency)、隔离性或独立性(Isolation) 和持久性(Durabilily),简称就是ACID。-
原子性:一系列的操作整体不可拆分,要么同时成功,要么同时失败。
-
一致性:数据在事务的前后,业务整体一致。
-
隔离性:事务之间互相隔离。
-
持久性:一旦事务成功,数据一定会落盘在数据库。
-
-
在以往的单体应用中,我们多个业务操作使用同一条连接操作不同的数据表,一旦有异常,我们可以很容易地整体回滚。就比如买东西业务,扣库存,下订单,账户扣款,是一个整体,必须同时成功或者失败。一个事务开始,代表以下的所有操作都在同一个连接里面。
1.2 隔离级别
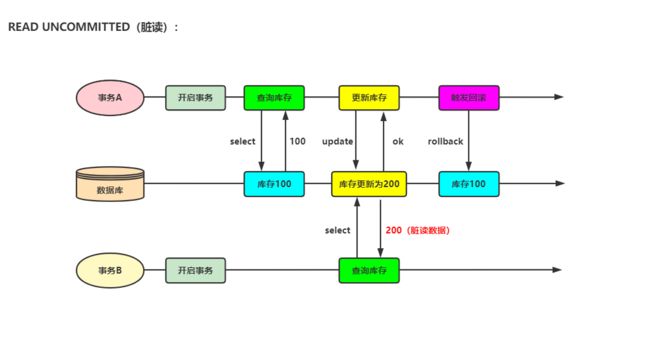
READ UNCOMMITTED(脏读):该隔离级别的事务会读到其它未提交事务的数据。
READ COMMITTED(不可重复读):一个事务可以读取另一个已提交的事务,多次读取会造成不一样的结果。Oracle和SQL Server的默认隔离级别。

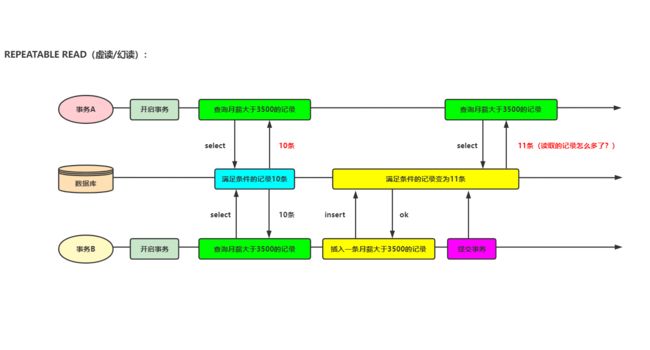
REPEATABLE READ(虚读/幻读):该隔离级别是MySQL默认的隔离级别,一个事务可以读取另一个事务已提交的数据,读取的数据前后相比多了点或者少了点。MySQL的InnoDB引擎可以通过next-key locks机制来避免幻读。
SERIALIZABLE(序列化):这是数据库最高的隔离级别,在该隔离级别下事务都是串行顺序执行的,MySQL数据库的InnoDB引擎会给读操作隐式加一把读共享锁,从而避免了脏读、不可重读复读和幻读问题,但是执行效率差,性能开销也最大,所以基本没人会用。
1.3 事务的传播行为
-
PROPAGATION_REQUIRED: :如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置。
-
PROPAGATION_SUPPORTS: :支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。
-
PROPAGATION_MANDATORY: :支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
-
PROPAGATION_REQUIRES_NEW::创建新事务,无论当前存不存在事务,都创建新事务。
-
PROPAGATION_NOT_SUPPORTED::以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
-
PROPAGATION_NEVER: :以非事务方式执行,如果当前存在事务,则抛出异常。
-
PROPAGATION_NESTED: :如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与 PROPAGATION_REQUIRED 类似的操作。
-
七种事务传播机制最常用的就两种:
- REQUIRED:一个事务,要么成功,要么失败。
- REQUIRES_NEW:两个不同事务,彼此之间没有关系。一个事务失败了不影响另一个事务。
1.4 本地事务在分布式下的问题
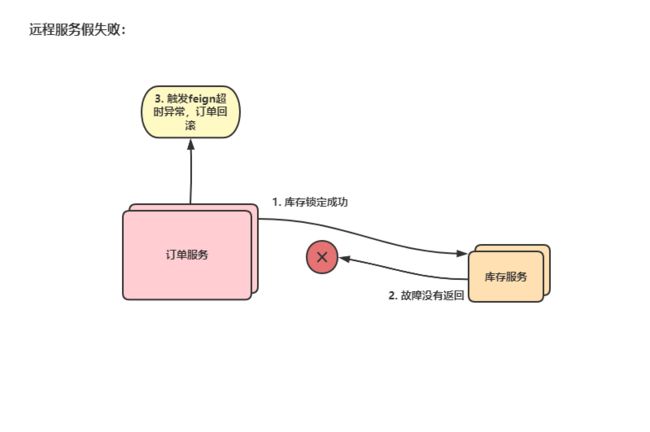
1.4.1 问题一:远程服务假失败
-
远程服务其实成功了,由于网络故障没有返回,导致订单回滚,库存却扣减。
-
假失败就是我们在订单服务调库存服务时, 库存锁定成功,然后由于服务器慢、卡顿、等故障原因,本地事务提交了之后,一直没返回到订单服务。此时再看订单服务,因为调用库存服务时间太长了,库存服务迟迟没有返回结果,可能就会触发
feign的超时机制,在调用远程服务这里抛异常:read time out读取超时,但是这个异常并不是我们手动抛的锁库存异常,而是feign的异常并且订单服务,设计的回滚机制,是只要一出现异常就会全部回滚,导致最终数据不一致。 -
示意图:
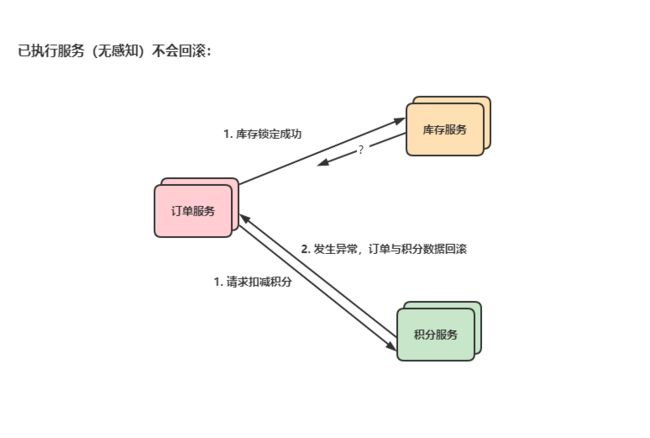
1.4.2 问题二:调用新服务出现异常之后,已经执行的服务不会回滚
-
假设库存锁定成功,将结果返回到了订单服务,我们根据结果又调用了积分服务,让它扣减积分,结果积分服务内部出现异常,积分数据回滚此时再看订单服务,订单服务感知到我们手动抛的积分异常,订单数据回滚,但是库存服务,却不会有任何感知。其结果就是积分、订单数据全部回滚,库存给锁定了,也是数据不一致。
-
示意图:
1.4.3 总结:
-
本地事务,在分布式系统,只能控制住自己的回滚,控制不了其它服务的回滚。
-
产生分布式事务问题的最大原因,就是网络问题 + 分布式机器。
二、分布式事务
假设我们有一个下单的事务场景,它会涉及调用库存、订单、会员功能。
-
在单体应用下,我们将三个功能的代码写到一个系统,而且都是连接同一数据库,这样的话很容易就能控制事务,若其中一个失败,则整个事务都会回滚。
-
而在分布式系统下,我们拆分了很多的微服务,它们都是独立部署且每个服务都有自己操作的数据库,那这样我们想要完成整个下单逻辑,我们就要远程调用这三个机器的各个方法。
-
但是,由于分布式系统会经常出现机器宕机、网络异常、消息丢失、消息乱序、数据错误、不可靠的 TCP、存储数据丢失…等异常情况。所以,分布式事务是企业集成中的一个技术难点,也是每一个分布式系统架构中都会涉及到的一个东西,特别是在微服务架构中,几乎可以说是无法避免。
三、相关概述及理论
3.1 CAP理论
CAP指的是一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。
CAP原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
- 示意图:

- 一致性(Consistency):
- 在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)。
- 比如我们有三个节点,当我给节点1保存了值,那么我再请求节点2、3的数据时,响应的数据也应该是这个最新的值。
- 可用性(Availability) :
- 在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)。
- 分区容错性(Partition Tolerance) :
- 大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition)。分区容错的意思是区间通信可能失败。比如,一台服务器放在中国,另一台服务器放在美国,这就是两个区,它们之间可能无法通信。
3.2 CAP为什么不能三者兼顾?
-
满足一致性:假设我们有三个节点,当客户端有一个请求进来,我们所有的节点完成数据备份,此时满足了我们的一致性
C的需求。 -
可用性与一致性冲突:再次假设,当节点1向节点2、3要求同步备份数据时,此时节点3发生了网络故障,也就是分区容错性。接下来我们就会考虑,能否满足可用性?若让其满足的话(允许客户端请求负载到节点3读取数据),但是由于上次发生故障导致节点3的数据没有更新,则此时读到的数据就出现了不一致。所以当你想要满足一致性,就必须让节点3不能被访问,既然不能被访问相当于又不可用。
C和A无法同时做到。 -
在分布式系统里,因为我们这个网络肯定会出现问题,所以我们永远都要满足分区容错。则就需要在一致性与可用性做出选择。
-
选择可用性+分区容错性(
AP)的情况下,我们不去在意读到的数据是否一致,这种场景实现相对简单。 -
若选择一致性+分区容错性(
CP)的情况下,是如何保证它们之间一致的?我们在分布式系统里边一般会有一些一致性算法,典型的代表,比如说Google的Chubby分布式锁服务,采用了Paxos算法;etcd分布式键值数据库,采用了Raft算法;ZooKeeper分布式应用协调服务,Chubby的开源实现,采用ZAB算法。
3.3 Raft算法实现分布式系统一致性
-
由于
Paxos算法过于晦涩难懂且难以实现,后提出了一种更易于理解和实现并能等价于Paxos算法的共识算法 -Raft算法。 -
Raft算法有两个核心概念:-
领导选举(关注角色、心跳时间、自旋时间)-> Leader的选举过程-演示动画:https://acehi.github.io/thesecretlivesofdata-cn/raft/#election
-
日志复制 -> 日志复制过程-演示动画:https://acehi.github.io/thesecretlivesofdata-cn/raft/#replication
-
-
通过它们来保证我们整个集群的一致性,即使有分区错误,我们也能保持一致性。
3.4 Base理论
是对
CAP理论的延伸,思想是即使无法做到强一致性(CAP的一致性就是强一致性),但可以采用适当的采取弱一致性,即最终一致性。
-
强一致与弱一致是对立概念。强一致性也叫做线性一致性,除此以外,所有其它的一致性都是弱一致性的特殊情况。所谓强一致性,即数据备份是同步的,弱一致性,即数据备份是异步的。
-
基本可用(Basically Available):指分布式系统在出现故障的时候,允许损失部分可用性(例如响应时间、功能上的可用性)。需要注意的是,基本可用绝不等价于系统不可用。就比如:
- 响应时间上的损失:正常情况下搜索引擎需要在 0.5 秒之内返回给用户相应的查询结果,但由于出现故障(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了 1~2 秒(查询故障节点不行,就换其它机器进行查询,允许查询速度慢一点)。
- 功能上的损失:购物网站在购物高峰(如双十一)时,为了保护系统的稳定性,部分消费者可能会被引导到一个降级页面。
-
软状态( Soft State) :指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据会有多个副本,允许不同副本同步的延时就是软状态的体现。
MySQL Replication的异步复制也是一种体现。 -
最终一致性( Eventual Consistency):指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
四、常见解决方案
4.1 2PC 模式
2PC就是我们说的二阶段提交,又叫做XA Transactions。MySQL从 5.5 版本开始支持,SQL Server2005 开始支持,Oracle7 开始支持。
- 示意图:

-
假设我们这有一个本地资源管理器(相当于每个服务的事务管理器),一个事务管理器(相当于总的事务管理器)。
-
协调事务处理共为两个阶段:
- 第一阶段:事务协调器要求每个涉及到事务的数据库预提交(
PreCommit)此操作,并反映是否可以提交。 - 第二阶段:事务协调器要求每个数据库提交数据。
- 其中,如果有任何一个数据库否决此次提交,那么所有数据库都会被要求回滚它们在此事务中的那部分信息。
- 第一阶段:事务协调器要求每个涉及到事务的数据库预提交(
-
优点:
XA 协议比较简单,而且一旦商业数据库实现了XA 协议,使用分布式事务的成本也比较低。
-
缺点:
- 性能不理想,特别是在交易下单链路,往往并发量很高,无法满足高并发场景。
- 目前在商业数据库支持的比较理想,在 mysql 数据库中支持的不太理想,
mysql的XA实现,没有记录 prepare 阶段日志,主备切换回导致主库与备库数据不一致。 - 许多
nosql也没有支持XA,这让XA的应用场景变得非常狭隘。
-
总结:了解即可,使用场景非常少。
4.2 3PC 模式
三阶段提交(
3PC)是二阶段提交(2PC)的一个改良版本,引入了两个新的特性。
- 协调者和参与者均引入超时机制,通过超时机制来解决
2PC的同步阻塞问题,避免事务资源被永久锁定。 - 把二阶段演变为三阶段,二阶段提交协议中的第一阶段"准备阶段"一分为二,形成了新的
CanCommit、PreCommit、DoCommit三个阶段组成事务处理协议。 - 优点:
3PC相比较于2PC最大的优点就是降低了参与者的阻塞范围,并且能够在协调者出现单点故障后继续达成一致。 - 缺点:虽然通过超时机制解决了资源永久阻塞的问题,但是
3PC依然存在数据不一致的问题。当参与者接收到PreCommit消息后,如果网络出现分区,此时协调者与参与者无法进行正常通信,这种情况下,参与者依然会进行事务的提交。 - 总结:通过了解
2PC和3PC之后,我们可以知道这两种方案都无法彻底解决分布式下的数据一致性。
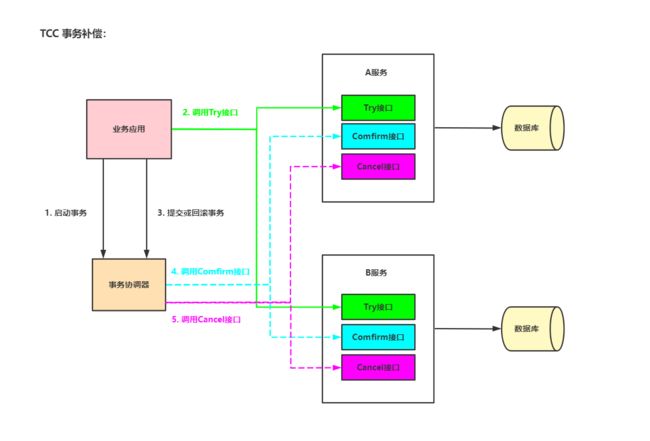
4.3 柔性事务-TCC 事务补偿方案
补偿事务
TCC,全称Try-Confirm-Cancel。
-
什么是柔性事务?
- 刚性事务:遵循
ACID原则,强一致性。 - 柔性事务:遵循
BASE理论,最终一致性。与刚性事务不同,柔性事务允许一定时间内,不同节点的数据不一致,但要求最终一致。
- 刚性事务:遵循
-
TCC核心思想:针对每个操作都要注册一个与其对应的确认(
Try)和补偿(Cancel)。- Try阶段:做一些业务检查以及一些资源预留,它需要后续的
Confirm一起才能构成一个完成的业务逻辑。 - Comfirm阶段:确认提交,
Try阶段所有分支事务执行成功后开始执行Confirm。 - Cancel阶段:业务执行出错需要回滚。
- Try阶段:做一些业务检查以及一些资源预留,它需要后续的
-
示意图:
- 总结:
2PC通常是在跨库DB里,而TCC是在应用层面。TCC每个业务逻辑代码都要实现Try、Confirm、Cacnel接口,开发难度大,所以所对应用的倾入性非常强。
4.4 柔性事务-最大努力通知方案
方案主要用在与第三方系统通讯时,比如:调用微信或支付宝支付后的支付结果通知。这种 方案也是结合
MQ进行实现,例如:通过MQ发送http请求,设置最大通知次数,达到通知次数后即不再通知。
- 应用场景:银行通知、商户通知等(各大交易业务平台间的商户通知:多次通知、查询校对、对 账文件),支付宝的支付成功异步回调。
- 案例说明:我们现在有一个大业务,调用了积分、库存和订单业务。当订单和库存都执行结束,但是在做用户积分扣减时失败了,然后订单模块就会发送一条消息给
MQ。接下来由订阅了消息队列的订单及库存服务接收消息,当它们都收到消息后,库存服务就会解锁库存,订单服务就会解锁订单,完成事务的回滚。既然是最大努力通知,期间就会不断发送业务处理失败的消息,直至对应业务返回处理成功的消息,就不再进行通知了。
4.5 柔性事务-可靠消息+最终一致性方案(异步确保型)
-
实现:业务处理服务在业务事务提交之前,向实时消息服务请求发送消息,实时消息服务只记录消息数据,而不是真正的发送。业务处理服务在业务事务提交之后,向实时消息服务确认发送。只有在得到确认发送指令后,实时消息服务才会真正发送。
-
关键点(防止消息丢失):
- 做好消息确认机制
Publisher,Consumer手动ack。 - 每一个发送的消息都在数据库做好记录,定期将失败的消息再次发送一遍。
- 做好消息确认机制
-
消息记录表:
CREATE TABLE `mq_message` (
`message_id` CHAR ( 32 ) NOT NULL,
`content` text,
`to_exchane` VARCHAR ( 255 ) DEFAULT NULL,
`routing_key` VARCHAR ( 255 ) DEFAULT NULL,
`class_type` VARCHAR ( 255 ) DEFAULT NULL,
`message_status` INT ( 1 ) DEFAULT '0' COMMENT '0-新建 1-已发送 2-错误抵达 3-已抵达',
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY ( `message_id` )
) ENGINE = INNODB DEFAULT CHARSET = utf8mb4
五、分布式事务框架-Seata
Seata是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata将为用户提供了AT、TCC、SAGA和XA事务模式,为用户打造一站式的分布式解决方案。
5.1 核心概念及原理
-
TC - 事务协调者:维护全局和分支事务的状态,驱动全局事务提交或回滚。
-
TM - 事务管理器:定义全局事务的范围(开始全局事务、提交或回滚全局事务)。
-
RM - 资源管理器:管理分支事务处理的资源,与 TC 交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
-
工作原理:
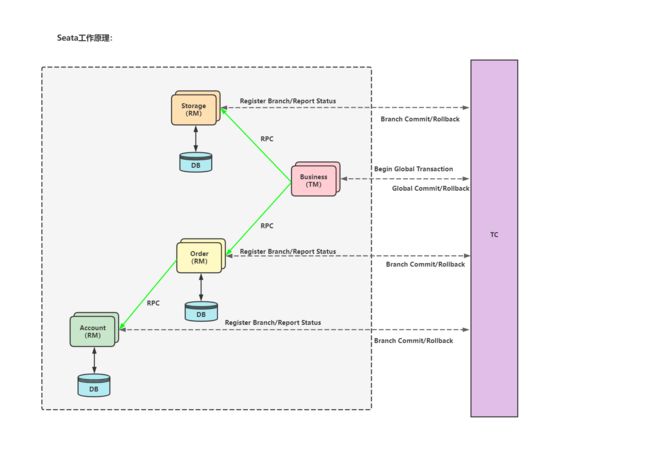
- 流程描述:
- 假设我们现在要执行一个大的下单业务 Business,大业务的
TM(事务管理器)先会告诉TC(事务协调者)它要准备跨服开启一个全局事务。 - 开始全局事务后,接下来它调用第一个微服务的事务方法的时候,Storage 服务就会在
TC(事务协调者)注册一下,我们称为分支事务。相当于它的RM(资源管理器)会告诉TC(事务协调者),它有一个分支事务,并且它要实时汇报它的事务状态,它这个分支是提交成功还是失败回滚,TC(事务协调者)都能实时的知道。 - 接下来调我们第二个远程服务 Order,及第三个远程服务 Account也是同理注册分支事务,并且实时汇报状态。
- 大事务只要一开启,每调一个小事务,
TC(事务协调者)都知道这个小事务成了还是败了。 - 假设其中最后一个分支事务失败了,需要进行回滚。这个时候,
TC(事务协调者)知道我们的大事务,已经调成功两个了,并且前两个事务都已经提交了,但是第三个事务给回滚了,TC(事务协调者)就会命令前两个事务也回滚。
- 假设我们现在要执行一个大的下单业务 Business,大业务的
5.2 AT模式
5.2.1 相关概念:
AT模式(自动事务Auto Transaction)是Seata最主推的分布式事务解决方案,它是基于XA演进而来。AT模式是一种无侵入的分布式事务解决方案,也就是说我们不需要再编写多余的代码来实现这个模式,只需要在方法中添加上指定的注解即可。- 在 AT 模式下,用户只需关注自己的“业务
SQL”,用户的 “业务SQL” 作为一阶段,Seata框架会自动生成事务的二阶段提交和回滚操作。 - AT模式支持的数据库有:
MySQL、Oracle、PostgreSQL和TiDB。
5.2.2 模式概述:
- 前提:我们如果要使用该模式,那么每一个要使用分布式事务的数据库都需要一个
UNDO_LOG表(即回滚日志表)。 - 效果:该模式下
TC(事务协调者) 只要调分支事务,成功之后就会提交事务,但是如果有一个分支事务失败了,失败的这个可以自己进行回滚。 - 处理逻辑:
- 某个服务除了它常规的业务表以外,我们会额外去创建一个回滚日志表。它是在
RM(资源管理器)部分完成的,会在每一个数据库单元处理时均会生成一条log数据。 - 对于已提交的事务要进行回滚,它会利用魔改数据库进行反向补偿。比如:我们这有条加二的记录,原来它的值是八,加二以后变成十,结果被人给回滚了。
- 它先在
UNDO_LOG里面记录了一下这条记录没改变之前的值。如果它失败回滚了,那它就回过头把我们数据库里边的这个十再改回去,改成八。所以,它相当于在我们事务执行之前,它先读取一下这个状态是几,最后再改回来。
- 某个服务除了它常规的业务表以外,我们会额外去创建一个回滚日志表。它是在
5.3 Seata 服务搭建
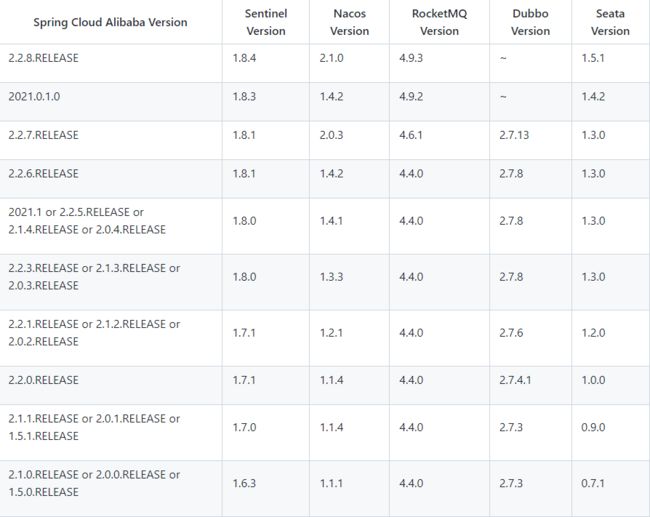
5.3.1 组件版本关系:
每个
Spring Cloud Alibaba版本及其自身所适配的各组件对应版本如下表所示(避免版本不兼容带来未知问题)。
5.3.2 Docker下安装 Seata:
# 1.下载镜像(注意:此处版本号请参考组件版本关系图!)。
$ docker pull seataio/seata-server:1.2.0
# 2.启动容器。
$ docker run -d --name seata-server -p 8091:8091 seataio/seata-server:1.2.0
# 3.创建存放配置的文件夹。
mkdir -p /home/seata/config
# 4.拷贝配置文件。
$ docker cp seata-server:/seata-server/resources /home/seata/config
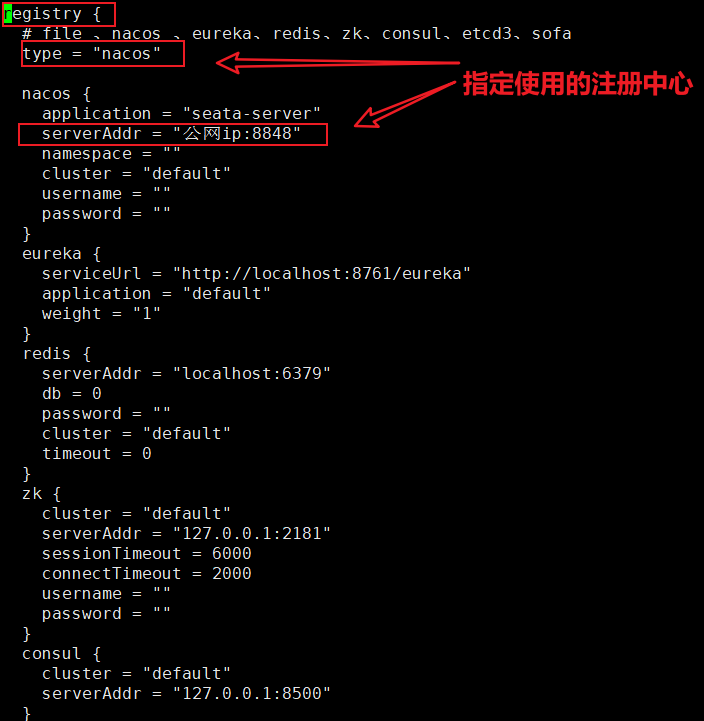
# 5.编辑配置文件(参考下面截图)。
$ cd /home/seata/config/resources
$ vim registry.conf
# 提示:
# 可以在registry.conf指定seata配置的位置(config {type = "nacos"})。
# 可以在file.conf中指定事务日志存储类型(store {mode = "db"}),若使用mysql-8版本则需要额外修改以下两项配置,否则报错。
# driverClassName = "com.mysql.cj.jdbc.Driver"
# url = "jdbc:mysql://127.0.0.1:3306/seata?serverTimezone=UTC"
# 6.停止容器。
$ docker stop seata-server
# 7.移除旧容器。
$ docker rm seata-server
# 8.启动新容器并挂载配置。
$ docker run -d \
--name seata-server \
-p 8091:8091 \
-e SEATA_IP=yourIp(公网IP) \
-v /home/seata/config/resources:/seata-server/resources \
seataio/seata-server:1.2.0
# 设置开机自启。
$ docker update seata-server --restart=always
5.3.3 验证Seata服务启动成功:
- 查看容器日志(Server started …):
$ docker logs seata-server
- 访问注册中心后台(成功注册):
http://yourIp:8848/nacos
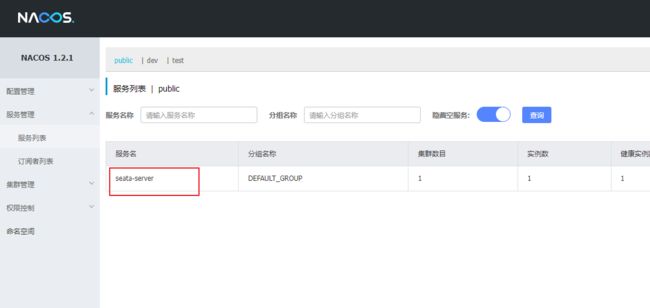
5.4 项目整合
5.4.1 数据库添加 UNDO_LOG 表:
每一个要使用分布式事务的数据库都需要一个
UNDO_LOG表。
CREATE TABLE `undo_log` (
`id` BIGINT ( 20 ) NOT NULL AUTO_INCREMENT,
`branch_id` BIGINT ( 20 ) NOT NULL,
`xid` VARCHAR ( 100 ) NOT NULL,
`context` VARCHAR ( 128 ) NOT NULL,
`rollback_info` LONGBLOB NOT NULL,
`log_status` INT ( 11 ) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` VARCHAR ( 100 ) DEFAULT NULL,
PRIMARY KEY ( `id` ),
UNIQUE KEY `ux_undo_log` ( `xid`, `branch_id` )
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
branch_id:分支事务ID。xid:全局事务ID(Seata服务端地址+ ID)。context:回滚信息序列化和压缩格式。rollback_info:回滚信息。log_status:日志状态(0表示正常,1表示全局已完成)。log_created:创建时间。log_modified:修改时间。
5.4.2 依赖引入:
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-seataartifactId>
dependency>
5.4.3 配置代理数据源:
配置代理数据源实现分支事务,如果没有注入,事务无法成功回滚。
@Configuration
public class MySeataConfig {
@Autowired
DataSourceProperties dataSourceProperties;
/**
* 需要将 DataSourceProxy 设置为主数据源,否则事务无法回滚。
*
* @param dataSourceProperties 数据源属性配置。
* @return {@link DataSource}
*/
@Bean
public DataSource dataSource(DataSourceProperties dataSourceProperties) {
HikariDataSource dataSource = dataSourceProperties.initializeDataSourceBuilder()
.type(HikariDataSource.class).build();
if (StringUtils.hasText(dataSourceProperties.getName())) {
dataSource.setPoolName(dataSourceProperties.getName());
}
return new DataSourceProxy(dataSource);
}
}
5.4.4 微服务中添加配置文件:
方式一(此处使用):每个要使用分布式事务的微服务服务中(
src/main/resources/),都要添加这两个文件(registry.conf、file.conf)。方式二:也可以将
Nacos作为统一配置中心,去配置Seata的file.conf各项参数,实现集群的配置共享,并结合application.properties/yml+registry.conf完成微服务整合。
registry.conf
# ---注册中心配置---
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
# 指定类型为nacos注册中心(根据项目所使用的注册中心进行选择),默认是"file"。
type = "nacos"
nacos {
serverAddr = "localhost:8848"
namespace = "public"
cluster = "default"
}
eureka {
serviceUrl = "http://localhost:1001/eureka"
application = "default"
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = "0"
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
# ---配置中心---
config {
# file、nacos 、apollo、zk、consul、etcd3
# 指定seata配置的位置,默认"file"。
type = "file"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
consul {
serverAddr = "127.0.0.1:8500"
}
apollo {
app.id = "seata-server"
apollo.meta = "http://192.168.1.204:8801"
}
zk {
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
etcd3 {
serverAddr = "http://localhost:2379"
}
file {
# 关联 `file.conf` 文件中配置的seata参数。
name = "file.conf"
}
}
file.conf
# ---网络传输配置---
transport {
# tcp udt unix-domain-socket
type = "TCP"
#NIO NATIVE
server = "NIO"
#enable heartbeat
heartbeat = true
#thread factory for netty
thread-factory {
boss-thread-prefix = "NettyBoss"
worker-thread-prefix = "NettyServerNIOWorker"
server-executor-thread-prefix = "NettyServerBizHandler"
share-boss-worker = false
client-selector-thread-prefix = "NettyClientSelector"
client-selector-thread-size = 1
client-worker-thread-prefix = "NettyClientWorkerThread"
# netty boss thread size,will not be used for UDT
boss-thread-size = 1
#auto default pin or 8
worker-thread-size = 8
}
shutdown {
# when destroy server, wait seconds
wait = 3
}
serialization = "seata"
compressor = "none"
}
# ---当前微服务在seata服务器中注册的信息配置---
service {
# 事务分组,默认:${spring.applicaiton.name}-fescar-service-group。
vgroup_mapping.applicaiton-name-fescar-service-group = "default"
# 仅支持单节点,不要配置多地址,这里的default要和事务分组的值一致。
default.grouplist = "127.0.0.1:8091"
# 降级,当前不支持。
enableDegrade = false
# 禁用全局事务。
disable = false
#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanent
max.commit.retry.timeout = "-1"
max.rollback.retry.timeout = "-1"
}
# ---客户端相关工作的机制---
client {
async.commit.buffer.limit = 10000
lock {
retry.internal = 10
retry.times = 30
}
report.retry.count = 5
}
# ---事务日志存储配置---
# 注意:该部分配置仅在seata-server中使用,如果选择db请配合seata.sql使用。
## transaction log store
store {
## store mode: file、db
mode = "file"
## file store
file {
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
max-branch-session-size = 16384
# globe session size , if exceeded throws exceptions
max-global-session-size = 512
# file buffer size , if exceeded allocate new buffer
file-write-buffer-cache-size = 16384
# when recover batch read size
session.reload.read_size = 100
# async, sync
flush-disk-mode = async
}
## database store
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "dbcp"
## mysql/oracle/h2/oceanbase etc.
db-type = "mysql"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "mysql"
password = "mysql"
min-conn = 1
max-conn = 3
global.table = "global_table"
branch.table = "branch_table"
lock-table = "lock_table"
query-limit = 100
}
}
lock {
## the lock store mode: local、remote
mode = "remote"
local {
## store locks in user's database
}
remote {
## store locks in the seata's server
}
}
recovery {
committing-retry-delay = 30
asyn-committing-retry-delay = 30
rollbacking-retry-delay = 30
timeout-retry-delay = 30
}
transaction {
undo.data.validation = true
undo.log.serialization = "jackson"
}
## metrics settings
metrics {
enabled = false
registry-type = "compact"
# multi exporters use comma divided
exporter-list = "prometheus"
exporter-prometheus-port = 9898
}
5.4.5 添加全局事务注解:
-
主业务方法添加全局事务注解:
@GlobalTransactional -
分支业务方法添加本地事务注解:
@Transactional
@GlobalTransactional
public void purchase(String userId, String commodityCode, int orderCount) {
......
}
5.5 更多官方示例
# 整合 nacos
https://github.com/seata/seata-samples/tree/master/springcloud-nacos-seata
# 整合 jpa
https://github.com/seata/seata-samples/tree/master/springcloud-jpa-seata
# 整合 dubbo
https://github.com/seata/seata-samples/tree/master/springboot-dubbo-seata
# 整合 ShardingSphere
https://github.com/seata/seata-samples/tree/master/springboot-shardingsphere-seata
六、结束语
“-------怕什么真理无穷,进一寸有一寸的欢喜。”
微信公众号搜索:饺子泡牛奶。