C++对象模型 第三章 数据语义学
第三章 数据语义学
文章目录
-
- 数据成员绑定时机
- 进程内存空间
- 数据成员布局
- 数据成员存取
- 单一继承下的数据成员布局
- 单类 单继承 下虚函数的数据成员布局
- 多重继承数据布局与this调整深谈 !
- 虚基类问题的提出和初探
- 两层结构时虚基类表内容分析 —— 针对 VS 2017
- 三层结构时虚基类表内容分析
- 成员变量地址、偏移、指针等重申
数据成员绑定时机
-
总结:
==编译器对 成员函数myfunc的解析,是整个A类定义完毕后才开始;==因为只有整个类A定义完毕后,
编译器参能看到类A中的myvar,才能根据时机的需要把出现myvar的场合做上述的适当的解释(成员函数中解析成类中的myvar,全局函数中解析成全局的myvar)想引用全局的 在变量名前加个 :: 两个冒号
-
**对于成员函数参数:是在编译器第一次遇到整个类型mytype的时候被决定的;**所以,mytype第一次遇到的时候,编译器只看到了
typedef string mytype,没有看到类中的typedef in mytype;
结论:为了在类中尽早的看到类型mytype,所以这种类型定义语句typedef,一定要挪到类的最开头定义。
那后边的成员函数第一次遇到这个类型mytype的时候,它就本着最近碰到的类型的原则来应用最近碰到的类型。
#include
#include
#include
using namespace std;
//string myvar= "I Love China!"; //全局量,字符串型
typedef string mytype;
//定义一个类
class A
{
typedef int mytype;
public:
//int myfunc();
///*{
// return myvar;
//}*/
//void myfunc(mytype tmpvalue) //mytype = string
//{
// m_value = tmpvalue; //出错,是把一个string类型给一个整型
//}
void myfunc(mytype tmpvalue); //string
private:
//int myvar; //同全局变量名相同,但类型不同。
mytype m_value; //int
};
void A::myfunc(mytype tmpvalue) //int
{
m_value = tmpvalue;
}
void myfunc(mytype tmpvalue) //mytype
{
string mvalue = tmpvalue;
}
//int A::myfunc()//成员函数
//{
// cout << myvar << endl; //myvar是类内定义的
// cout << ::myvar.c_str() << endl; //myvar是全局的
// return myvar; //这里还是A::myvar
//}
//int myfunc()
//{
// return myvar; //这里的myvar是全局的,是string类型,所以这里报错;
//}
int main()
{
//编译器是对成员函数myfunc的解析,是整个A类定义完毕后才开始的;
//所以,对这个myvar的解析和绑定,是在这个类定义完成后发生的。
//总结:
//编译器对 成员函数myfunc的解析,是整个A类定义完毕后才开始;因为只有整个类A定义完毕后,
//编译器参能看到类A中的myvar,才能根据时机的需要把出现myvar的场合做上述的适当的解释(成员函数中解析成类中的myvar,全局函数中解析成全局的myvar;
/*A aobj;
aobj.myvar = 15;
aobj.myfunc();*/
//对于成员函数参数:是在编译器第一次遇到整个类型mytype的时候被决定的;所以,mytype第一次遇到的时候,编译器只看到了
//typedef string mytype,没有看到类中的typedef int mytype;
//结论:为了在类中尽早的看到类型mytype,所以这种类型定义语句typedef,一定 要挪到类的最开头定义。
//那后边的成员函数第一次遇到这个类型mytype的时候,它就本着最近碰到的类型的原则来应用最近碰到的类型。
return 1;
}
进程内存空间
Linux虚拟地址空间布局以及进程栈和线程栈总结

- 不同的数据在内存中会有不同的 保存时机,保存位置
当运行一个可执行文件时,操作系统就会把这个可执行文件加载到内存;此时进程有一个虚拟的地址空间(内存空间)
linux有个nm命令:能够列出可执行文件中的全局变量存放的地址;
类的静态成员变量 存在数据段
数据成员布局
- 观察成员变量地址规律
- 边界调整,字节对齐
- 成员变量偏移值的打印
静态成员变量不占用类的空间 —— 存在 数据段中
普通成员变量的存储顺序是按照在类中的定义顺序从上到下来的
-
普通成员变量的存储顺序 是按照在类中的定义顺序从上到下来的;
比较晚出现的成员变量在内存中有更高的地址; (后面的只需要增加地址即可访问到)
类定义中pubic,private,protected的数量,不影响类对象的sizeof; -
边界调整,字节对齐
某些因素会导致成员变量之间排列不连续,就是边界调整(字节对齐),调整的目的是提高效率,编译器自动调整;
调整:往成员之间填补一些字节,使用类对象的sizoef字节数凑成 一个4的整数倍,8的整数倍;为了统一字节对齐问题,引入一个概念叫一字节对齐(不对齐);
有虚函数时,编译器往类定义中增加vptr虚函数表指针:内部的数据成员。
#pragma pack(1) 1字节对齐(不对齐)
#pragma pack() 取消指定对齐,恢复缺省对齐;
- 成员变量偏移值的打印
成员变量偏移值,就是这个成员变量的地址,离对象首地址偏移多少;
许多计算机系统对基本数据类型的合法地址做出了一些限制,要求某种类型对象的地
**(址必须是某个值 K(通常是 2、4 或 8)的倍数。(首地址)**这种对齐限制简化了形成处理器和内存系统
之间接口的硬件设计。例如,假设一个处理器总是从内存中取 8 个字节,则地址必须为 8
的倍数。如果我们能保证将所有的 double 类型数据的地址对齐成 8 的倍数,那么就可以
j用一个内存操作来读或者写值了。否则,我们可能需要执行两次内存访问,因为对象可能
被分放在两个 8 字节内存块中。
- 偏移值
//成员变量指针
int MYACLS::*mypoint = &MYACLS::m_n; // 或者直接使用 &MYACLS::m_n 打印
printf("pmyobj->m_n偏移值 = %d\n", mypoint);
数据成员存取
一:静态成员变量的存取
//静态成员变量,可以当做一个全局量,但是他只在类的空间内可见;引用时用 类名::静态成员变量名
//静态成员变量只有一个实体,保存在可执行文件的数据段的;
MYACLS myobj;
MYACLS *pmyobj = new MYACLS();
cout << MYACLS::m_si << endl; // 理论上应该这样访问
cout << myobj.m_si << endl; // 只是语法支持
cout << pmyobj->m_si << endl;
二:非静态成员变量的存取(普通的成员变量),存放在类的对象中。存取通过类对象(类对象指针)
pmyobj->myfunc();
编译器角度:MYACLS::myfunc(pmyobj)
MYACLS::myfunc(MYACLS *const this)
{
this->m_i = 5;
this->m_j = 5;
}
对于普通成员的访问,编译器是把类对象的首地址加上成员变量的偏移值;
&myobj + 4 = &myobj.m_j
单一继承下的数据成员布局
//(1)一个子类对象,所包含的内容,是他自己的成员,加上他父类的成员的总和;
//(2)从偏移值看,父类成员先出现,然后才是孩子类成员。
FAC facobj;
MYACLS myaclobj; //子类对象中实际上是包含着父类子对象的
class Base //sizeof = 8字节; 字节对齐 —— 最后一地址空间不可用
{
public:
int m_i1;
char m_c1;
char m_c2;
char m_c3;
};
- 引入继承关系后,可能会带来内存空间的额外增加。
class Base1
{
public:
int m_i1;
char m_c1;
};
class Base2 :public Base1
{
public:
char m_c2;
};
class Base3 :public Base2
{
public:
char m_c3;
};
Windows VS上的内存布局
Base 1、Base 2、Base 3
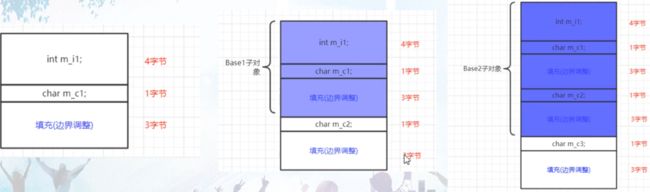
linux g++ 5.4上的内存布局
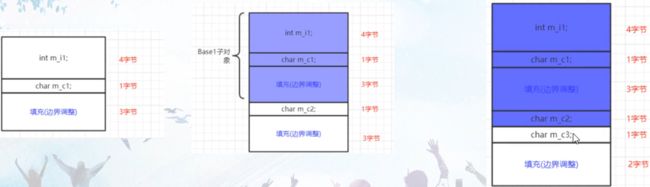
//linux上windows上数据布局不一样,说明:
//a)编译器在不断的进步和优化;
//b)不同厂商编译器,实现细节也不一样;
//c)内存拷贝就要谨慎;
Base2 mybase2obj;
Base3 mybase3obj;
//你就不能用memcpy内存拷贝把Base2内容直接Base3里拷贝;
单类 单继承 下虚函数的数据成员布局
类中引入虚函数时,会有额外的成本付出
-
(1)编译的时候,编译器会产生虚函数表,参考三章五节
-
(2)对象中会产生 虚函数表指针vptr,用以指向虚函数表的
-
(3)增加或者扩展构造函数,增加给虚函数表指针vptr赋值的代码,让vptr指向虚函数表;(程序运行时期)
-
(4)如果多重继承,比如你继承了2个父类,每个父类都有虚函数的话,每个父类都会有vptr,那继承时,子类就会把这两根vptr都继承过来,
如果子类还有自己额外的虚函数的话,子类与第一个基类共用一个vptr(三章四节); -
单个类带虚函数的数据成员布局

- 单一继承父类带虚函数的数据成员布局
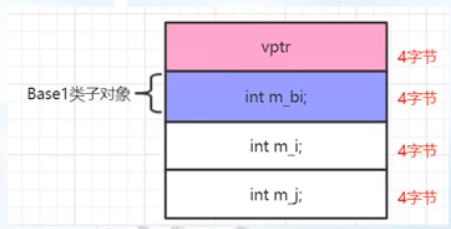
- 单—继承父类不带虚函数的数据成员布局
cout << sizeof(MYACLS) << endl;
printf("MYACLS::m_bi = %d\n", &MYACLS::m_bi);
printf("MYACLS::m_i = %d\n", &MYACLS::m_i);
printf("MYACLS::m_j = %d\n", &MYACLS::m_j);
MYACLS myobj;
myobj.m_i = 3;
myobj.m_j = 6;
myobj.m_bi = 9;
打印的是左边的图,实际测试(运行时测试,看地址空间变化时是右边的)

多重继承数据布局与this调整深谈 !

//一:单一继承数据成员布局this指针偏移知识补充
//一章三节 :this指针调整
//二:多重继承且父类都带虚函数的数据成员布局
//(1)通过this指针打印,我们看到访问Base1成员不用跳 ,访问Base2成员要this指针要偏移(跳过)8字节;
//(2)我们看到偏移值,m_bi和m_b2i偏移都是4;
//(3)this指针,加上偏移值 就的能够访问对应的成员变量,比如m_b2i = this指针+偏移值
//我们学习得到一个结论:
//我们要访问一个类对象中的成员,成员的定位是通过:this指针(编译器会自动调整)以及该成员的偏移值,这两个因素来定义;
//这种this指针偏移的调整 都需要编译器介入来处理完成;
- 得到一个结论:
我们要访问一个类对象中的成员,成员的定位是通过:this指针(编译器会自动调整)以及该成员的偏移值,这两个因素来定义;
这种this指针偏移的调整 都需要编译器介入来处理完成;
this偏移 + 成员偏移

Base2 *pbase2 = &myobj; //this指针调整导致pbase2实际是向前走8个字节的内存位置的
//myobj = 0x0093fad0,经过本语句以后,pbase2 = 0x0093fad8
//站在编译器视角,把上边这行语句进行了调整
//Base2 *pbase2 = (Base2 *)(((char *)&myobj) + sizeof(Base1));
Base1 *pbase1 = &myobj; //这里不用偏移了
Base2 *pbase2 = new MYACLS(); //父类指针new子类对象 ,这里new出来的是24字节
MYACLS *psubobj = (MYACLS *)pbase2; //比上边地址少了8字节(偏移)
//delete pbase2; //报异常。所以我们认为pbase2里边返回的地址不是分配的首地址,而是偏移后地址。
//而真正分配的首地址应该是在psubobj里边的这个地址
delete psubobj;
更复杂的继承 布局
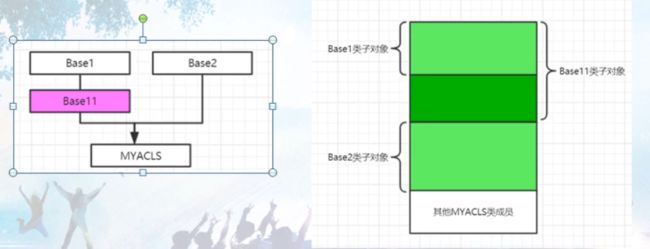
虚基类问题的提出和初探
class Grand //爷爷类
{
public:
int m_grand;
};
class A1 : virtual public Grand
{
public:
int m_a1;
};
class A2 : virtual public Grand
{
public:
int m_a2;
};
class C1 :public A1, public A2
{
public:
int m_c1;
};
- 虚基类(虚继承/虚派生)问题的提出
传统多重继承造成的:空间问题,效率问题,二义性问题;
虚基类,让 爷爷类 只被继承一次;
//二:虚基类初探
//两个概念:(1)虚基类表 vbtable(virtual base table).(2)虚基类表指针 vbptr(virtual base table pointer)
//空类sizeof(Grand) ==1好理解;
//virtual虚继承之后,A1,A2里就会被编译器插入一个虚基类表指针,这个指针,有点成员变量的感觉
//A1,A2里因为有了虚基类表指针,因此占用了4个字节
A1 a1;
A2 a2;
//虚基类表指针,用来指向虚基类表(后续谈)。
A1,A2里因为有了虚基类表指针,因此占用了4个字节
C1 里只有一个 虚基类表指针
对象布局

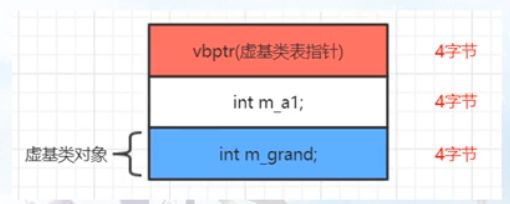
两层结构时虚基类表内容分析 —— 针对 VS 2017
- //一:虚基类表内容之5-8字节内容分析
//虚基类表 一般是8字节,四个字节为一个单位。每多一个虚基类,虚基类表会多加4个字节
//编译器因为有虚基类,会给A1,A2类增加默认的构造函数,并且这个默认构造函数里,会被编译器增加进去代码,
//给vbptr虚基类表指针赋值。
虚基类表 存的是相对于 虚基类表指针的偏移量
“虚基类表指针”成员变量的首地址 + 这个偏移量 就等于 虚基类对象首地址。跳过这个偏移值,我们就能够访问到虚基类对象;
偏移量(虚基类表) + 虚基类表指针 + 类成员的偏移量 = 访问的成员 地址
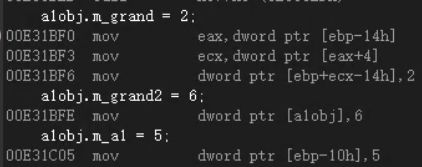
a1obj.m_grand = 2; —— 爷爷类 虚基类
ptr —— 就是虚基类表指针 的首地址
第一步 —— 加载 虚基类表指针的地址
第二步 —— 加载 偏移量(虚基类表) (地址为 eax + 4)这里的 虚基类表为8个直接,只用了4个字节
第三步 —— 赋值(偏移量(虚基类表) + 虚基类表指针 + 类成员的偏移量(0))
-
只有对虚基类成员进行处理比如赋值的时候,才会用到虚基类表,取其中的偏移,参与地址的计算
-
// project100.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。 // #include "pch.h" #include#include #include #include using namespace std; class Grand //爷爷类 { public: int m_grand; }; class Grand2 //爷爷类 { public: int m_grand2; //int m_grand2_1; }; class A1 : virtual public Grand,virtual public Grand2 { public: int m_a1; }; class A2 : virtual public Grand//, virtual public Grand2 { public: int m_a2; }; class C1 :public A1, public A2 { public: int m_c1; }; int main() { //一:虚基类表内容之5-8字节内容分析 //虚基类表 一般是8字节,四个字节为一个单位。每多一个虚基类,虚基类表会多加4个字节 //编译器因为有虚基类,会给A1,A2类增加默认的构造函数,并且这个默认构造函数里,会被编译器增加进去代码, //给vbptr虚基类表指针赋值。 cout << sizeof(Grand) << endl; cout << sizeof(A1) << endl; cout << sizeof(A2) << endl; cout << sizeof(C1) << endl; A1 a1obj; a1obj.m_grand = 2; a1obj.m_grand2 = 6; //a1obj.m_grand2_1 = 7; a1obj.m_a1 = 5; //“虚基类表指针”成员变量的首地址 + 这个偏移量 就等于 虚基类对象首地址。跳过这个偏移值,我们就能够访问到虚基类对象; //二:继续观察各种形色的继承 //a)虚基类表 现在是3项, +4,+8,都是通过取得虚基类表中的偏移值来赋值的 //b)虚基类表中的偏移量是按照继承顺序来存放的; //c)虚基类子对象一直放在最下边; //三:虚基类表内容之1-4字节内容分析 //虚基类表指针成员变量的首地址 ,和本对象A1首地址之间的偏移量 也就是:虚基类表指针 的首地址 - A1对象的首地址 //结论:只有对虚基类成员进行处理比如赋值的时候,才会用到虚基类表,取其中的偏移,参与地址的计算; return 1; }
三层结构时虚基类表内容分析
虚基类表是编译的时候生成好的
通过 C1孙子 指针 访问 grand —— 没有用到vbptr2,只用到了vbptr1
通过 A2指针 访问 grand —— 没有用到vbptr1,只用到了vbptr2
A2 *pa2 = &c1obj;
pa2->m_grand = 8;
加载 pa2 指针(虚基表指针 地址)
加载 虚基类表 地址
访问 虚基类表的偏移量
赋值 成员变量 m_grand (成员变量地址为 eax + edx,赋值内容为8)
虚基类表首地址的内容


// project100.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include "pch.h"
#include
#include
#include
#include
using namespace std;
class Grand //爷爷类
{
public:
int m_grand;
};
class A1 : virtual public Grand
{
public:
int m_a1;
};
class A2 : virtual public Grand
{
public:
int m_a2;
};
class C1 :public A1, public A2
{
public:
int m_c1;
};
int main()
{
//一:三层结构时虚基类表内容分析
cout << sizeof(Grand) << endl;
cout << sizeof(A1) << endl;
cout << sizeof(A2) << endl;
cout << sizeof(C1) << endl;
//A1 a1obj;
//a1obj.m_grand = 2;
//a1obj.m_grand2 = 6;
a1obj.m_grand2_1 = 7;
//a1obj.m_a1 = 5;
C1 c1obj;
c1obj.m_grand = 2;
c1obj.m_a1 = 5;
c1obj.m_a2 = 6;
c1obj.m_c1 = 8;
//C1 c2obj;
//没有用到vbptr2,只用到了vbptr1
//二:虚基类为什么这么设计
//为什么这么设计,是个很难回答的问题;
//A2 *pobja2 = new C1();
A2 *pa2 = &c1obj;
pa2->m_grand = 8;
pa2->m_a2 = 9;
return 1;
}
成员变量地址、偏移、指针等重申
#include
#include
#include
#include
using namespace std;
class MYACLS
{
public:
int m_i;
int m_j;
int m_k;
};
void myfunc(int MYACLS::*mempoint, MYACLS &obj)
{
obj.*mempoint = 260; //注意写法
}
int main()
{
//一:对象成员变量内存地址及其指针
MYACLS myobj;
myobj.m_i = myobj.m_j = myobj.m_k = 0;
printf("myobj.m_i = %p\n", &myobj.m_i); //对象的成员变量是有真正的内存地址的;
MYACLS *pmyobj = new MYACLS();
printf("pmyobj->m_i = %p\n", &pmyobj->m_i);
printf("pmyobj->m_j = %p\n", &pmyobj->m_j);
int *p1 = &myobj.m_i;
int *p2 = &pmyobj->m_j;
*p1 = 15;
*p2 = 30;
printf("p1地址=%p,p1值=%d\n", p1,*p1);
printf("p2地址=%p,p2值=%d\n", p2, *p2);
//二:成员变量的偏移值及其指针(和具体对象是没有关系的)
cout << "打印成员变量偏移值----------------" << endl;
printf("MYACLS::m_i偏移值 = %d\n",&MYACLS::m_i); //打印偏移值,这里用的%d
printf("MYACLS::m_j偏移值 = %d\n", &MYACLS::m_j);
//用成员变量指针来打印偏移值也可以,看写法
//大家要知道,成员变量指针里边保存的 实际上是个偏移值(不是个实际内存地址)。
int MYACLS::*mypoint = &MYACLS::m_j;
printf("MYACLS::m_j偏移地址 = %d\n",mypoint);
mypoint = &MYACLS::m_i; //这里注意,单独使用时直接用名字,定义时才需要加MYACLS::
printf("MYACLS::m_i偏移地址 = %d\n", mypoint);
//三:没有指向任何数据成员变量的指针
//通过 一个对象名或者对象指针后边跟 成员变量指针 来访问某个对象的成员变量:
myobj.m_i = 13;
myobj.*mypoint = 22;
pmyobj->*mypoint = 19;
myfunc(mypoint, myobj);
myfunc(mypoint, *pmyobj);
cout << "sizeof(mypoint) =" << sizeof(mypoint) << endl; //也是个4字节;
int *ptest = 0;
int MYACLS::*mypoint2;
mypoint2 = 0; //成员变量指针
mypoint2 = NULL; //0xffffffff 自动赋值为-1,-1 表示 指向的不是(有意义的)成员变量
printf("mypoint2 = %d\n", mypoint2);
//if(mypoint2 == mypoint) //不成立
int MYACLS::*mypoint10 = &MYACLS::m_i;
if (mypoint == mypoint10) //成立的
{
cout << "成立" << endl;
}
//mypoint2 += 1; // 不允许运算
//mypoint2++;
//mypoint2 = ((&MYACLS::m_i) + 1);
return 1;
}