自动化测试框架——页面对象模型POM & Selenium
1 自动化测试框架
应用框架的作用:
1、降低冗余
2、便于维护和理解
3、高内聚低耦合
4、便于公司管理、便于团队管理(统一规范等)
自动化测试设计模式一般基于两种设计模式:关键字驱动、页面对象模型
页面对象模型:简称POM/PO,将系统的所有业务流程,以页面的对象进行封装和处理,在进行调用,实现业务自动化测试。
结构分层(数据与代码分离,逻辑代码和测试代码分离)
- 基类:提供基础的函数,给所有页面对象执行
- 页面对象类:封装各个页面,生成页面对象,便于调用
- 测试用例层:基于POM的所有内容实现的测试用例
- 测试数据层:提供所有测试过程中所需的数据内容
WebUI自动化测试是基于selenium来实现的
基于关键字驱动,所有元素信息保存在文件中;基于POM,所有元素信息与页面对象关联
示例
目录清单

(1)基类
class BasePage:
# 构造函数
def __init__(self,driver):
self.driver = driver
# 访问URL
def open(self, url):
self.driver.get(url)
# 退出
def quit(self):
self.driver.quit()
# 元素定位
def locator(self, loc):
return self.driver.find_element(*loc)
# 输入
def input(self, loc, text):
self.locator(loc).send_keys(text)
# 点击
def click(self, loc):
self.locator(loc).click()
(2)页面对象类
登录页面对象类
"""
登录页面对象类
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from base.base_page import BasePage
class LoginPage(BasePage):
# URL
url = "http://39.98.138.157/shopxo/index.php?s=/index/user/logininfo.html"
# 页面元素
username = (By.NAME,'accounts')
pwd = (By.NAME,'pwd')
button = (By.XPATH,'/html/body/div[4]/div/div[2]/div[2]/form/div[3]/button')
# 登录业务实现
def login(self,user,pwd):
self.open(self.url)
self.input(self.username,user)
self.input(self.pwd,pwd)
self.click(self.button)
(3)测试用例层
"""
测试用例层,将所有的测试流程以及测试用例的设计,都放置这个层级中
"""
import pytest
from selenium import webdriver
from common.yaml_util import YamlUtil
from page_object.login_page import LoginPage
class TestCases:
# 测试用例
@pytest.mark.parametrize('data', YamlUtil().get(r'../data/login.yml'))
def test_login(self, data):
driver = webdriver.Chrome(r"E:\chromedriver_win32\chromedriver.exe")
lp = LoginPage(driver)
lp.login(data['text'], data['pwd'])
if __name__ == "__main__":
pytest.main(['-vs'])
(4)测试数据层
本次用yaml文件(注意yaml语法,键值中间是冒号和空格)
-
text: 666666
pwd: 666666
-
text: 123
pwd: 666666
-
text: 666666
pwd: 123
(5)公共工具
读取yaml数据方法
import yaml
class YamlUtil:
def get(self,path):
with open(path,'r',encoding='utf-8') as f:
data=yaml.load(stream=f,Loader=yaml.FullLoader)
return data2 Selenium
谷歌浏览器驱动下载地址:ChromeDriver Mirror
简单示例
#coding = utf-8
from selenium import webdriver
browser = webdriver.Chrome("E:\chromedriver_win32\chromedriver.exe") #谷歌
# browser = webdriver.Firefox()
browser.get("http://www.baidu.com")
browser.find_element_by_id("kw").send_keys("selenium")
#通过id = kw定位百度输入框,通过键盘方法send_keys()向输入框中输入selenium。
browser.find_element_by_id("su").click()
#通过id=su定位搜索按钮,并向按钮发送单击事件click()
browser.quit()2.1 定位元素
F12右键可复制定位元素的
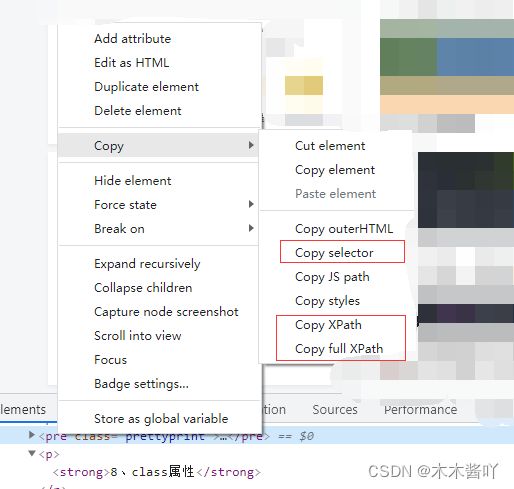
八种定位方式
find_element_ 返回匹配到的第一个元素,匹配不到则报错
find_elements_ 返回匹配到的所有元素,以列表返回,匹配不到则返回空列表
1、id
driver.find_element_by_id()
driver.find_elements_by_id()
2、name
find_element_by_name()
find_elements_by_name()
3、class name 支持多个class name,以空格隔开
find_element_by_class_name()
find_elements_by_class_name()
4、tag
find_element_by_tag_name()
find_elements_by_tag_name()
5、link text 定位指定文本的超链接,全文本匹配链接文本,不支持模糊匹配
find_element_by_link_text()
find_elements_by_link_text()
6、partial link text 定位指定文本的超链接,支持模糊匹配链接文本
find_element_by_partial_link_text()
find_elements_by_partial_link_text()
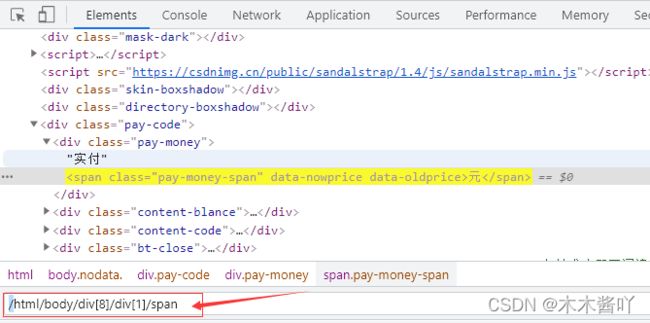
7、xpath 下拉框,没有属性,利用xpath定位,可以在标签上右键copy它的xpath,绝对路径是Copy full Xpath,相对路径是Copy Xpath,注意xpath里是第一个是从1开始
find_element_by_xpath()
find_elements_by_xpath()
8、css selector 可以在标签上右键copy它的css selector
find_element_by_css_selector()
find_elements_by_css_selector()
by定位需要需要导入By类:from selenium.webdriver.common.by import By
find_element(By.ID,"")
find_element(By.NAME,"")
find_element(By.CLASS_NAME,"")
find_element(By.TAG_NAME,"")
find_element(By.LINK_TEXT,u" ")
find_element(By.PARTIAL_LINK_TEXT,u" ")
find_element(By.XPATH,"")
find_element(By.CSS_SELECTOR,"")
常用后两种xpath和css selectorxpath语法规则
F12打开开发者工具,选择Element后,ctrl+F,可调出xpath筛选器
// 表示从根路径开始查找,从html开始
[] 添加筛选条件
@ 指定属性,支持and,or运算符
text() 通过文本查找元素,全量匹配
contains() 模糊匹配,可以通过属性或者文本查找
例如:
//*[@id="kw"] 表示从根节点出发,查找属性id为kw的所有元素(*)
//*[text()="news"] 表示从根节点出发,查找文本内容为news的所有节点
//a[contains(text(),"new")] 表示从根节点出发,查找文本包括new的a节点示例:



2.2 基本操作
注意:
元素无法正常交互的异常一般是因为当前展示的页面内容无法查找到该元素
一定要使用进行交互的元素,而不是样式元素等
常用库
- from selenium import webdriver 导入webdriver模块
- from selenium.webdriver import ActionChains 导入动作链类,动作链可以储存鼠标的动作,并一起执行
- from selenium.webdriver.common.key import Key 键盘操作使用的是Keys类,一般配合send_keys使用
- from selenium.webdriver.support.select import Select 下拉框的操作都交由Select类进行处理
- from selenium.webdriver.common.by import By
- from selenium.webdriver.support.ui import WebDriverWait
- from selenium.webdriver.support import expected_conditions as EC 显示等待使用的类
(1)浏览器相关操作
创建浏览器对象 driver = webdriver.xxx()
窗口最大化 maximize_window()
获取浏览器尺寸 get_window_size()
设置浏览器尺寸 set_window_size()
获取浏览器位置 get_window_position()
设置浏览器位置 set_window_position(x,y)
关闭当前标签/窗口 close()
关闭所有标签/窗口 quit()
(2)页面相关操作
请求某个url driver.get(url)
刷新页面操作 refresh()
回退到之前的页面 back()
前进到之后的页面 forward()
获取当前访问页面url current_url
获取当前浏览器标题 title
保存图片 get_screenshot_as_png()/get_screenshot_as_file(file)
网页源码 page_source
(3)元素的操作
点击操作 element.click()
清空输入框 element.clear()
input输入框输入数据 element.send_keys(data)
input文件上传 element.send_keys('文件路径')
获取文本内容(既开闭标签之间的内容) element.text
获取属性值(获取element元素的value属性的值) element.get_attribute(value)
(4)鼠标和键盘操作
鼠标操作需要导入类,见第一部分,然后创建对象ActionChains(driver),键盘操作导入类
鼠标右击
el = driver.find_element_by_xxx(value)
context_click(el)鼠标双击
el = driver.find_element_by_xxx(value)
ActionChains(driver).double_click(el).perform()鼠标悬停
el = driver.find_element_by_xxx(value)
ActionChains(driver).move_to_element(el).perform()常用键盘操作
send_keys(Keys.BACK_SPACE) 删除键(BackSpace)send_keys(Keys.SPACE) 空格键(Space)
send_keys(Keys.TAB) 制表键(Tab)
send_keys(Keys.ESCAPE) 回退键(Esc)
send_keys(Keys.ENTER) 回车键(Enter)
send_keys(Keys.CONTROL,‘a’) 全选(Ctrl+A)
send_keys(Keys.CONTROL,‘c’) 复制(Ctrl+C)
send_keys(Keys.CONTROL,‘x’) 剪切(Ctrl+X)
send_keys(Keys.CONTROL,‘v’) 粘贴(Ctrl+V)
(5)弹出框操作
进入到弹出框中 alert = driver.switch_to.alert()
接收警告 alert.accept()
关闭警告 alert.dismiss()
发送文本到警告框 alert.send_keys(data)
获取文本 alert.text
(6)下拉框操作
将定位到的下拉框元素传入Select类中 selobj = Select(element)
通过索引选择,index 索引从 0 开始 select_by_index()
通过值选择(option标签的一个属性值) select_by_value()
通过文本选择(下拉框的值) select_by_visible_text()
查看所有已选 all_selected_options
查看第一个已选 first_selected_option
查看是否是多选 is_multiple
查看选项元素列表 options
取消选择 deselect_by_index() / deselect_by_value() / deselect_by_visible_text()
(7)滚动条操作
js = "window.scrollTo(x,y) " x为水平拖动距离,y为垂直拖动举例
driver.execute_script(js)
js= “var q=document.documentElement.scrollTop=n” n为从顶部往下移动滚动举例
driver.execute_script(js)
(8)cookies操作
获取所有cookies get_cookies()
获取key对应的值 get_cookie(key)
设置cookies add_cookie(cookie_dict)
删除指定名称的cookie delete_cookie(name)
删除所有cookie delete_all_cookies()
(9)通过句柄切换多标签/多窗口
- 句柄概念:不同标签页通过不同字符串(理解为id,统称为句柄)来区分
- 通过selenium操作的标签页,在不切换句柄情况下,会一直停留在第一个标签页(查找元素时是在第一次的标签页上查找,因此无法在后续新的标签页上进行查找元素)
- 注意:不要一次性操作太多句柄,建议操作完一个标签页,就用driver.close()关闭当前的标签页(句柄)
获取所有窗口的句柄 handles = driver.window_handlers
通过窗口的句柄进入的窗口 driver.switch_to.window(handles[n])
(10)多表单/多框架切换、多表单/多框架切换
- iframe标签:里面可以再嵌html页面
- 如果定位到元素,检查该元素是不是在iframe标签内容,若是,则需要切换到该iframe里
- 进入到iframe里后,只能操作该iframe里的内容,如果需要跳出该iframe,使用driver.switch_to.default_content()方法
使用iframe标签的id值切换进表单 driver.switch_to.frame(id_value)
跳回最外层的页面 driver.switch_to.default_content()
定位到表单元素,再切换进入
el = driver.find_element_by_xxx(value)
driver.switch_to.frame(el)
跳回上层的页面 driver.switch_to.parent_frame()
原文链接:https://blog.csdn.net/phpwechat/article/details/112800664
2.3 等待
由于页面还未加载完,可能会导致直接查找元素报错,此时需要等待。
1、强制等待
sleep()方法,以秒为单位,容易使用,有需要时调用即可,但无法评估等待时间
2、隐式等待
driver=webdriver.Chrome()
dirver.implicitly_wait(10)
- 隐式等待必须要等待页面加载完成之后才生效,不能针对元素来等待
- 以秒为单位,隐式等待在找到元素后,等待停止;若没有找到元素则等待到指定的最大时间,然后继续执行代码
- driver的一个设置项,只需要设置一次,即可在整个dirver生命周期中生效,直至dirver.quit()结束
3、显式等待
WebDriverWait(浏览器对象,等待最长时间,查询频率时间) 返回值是等待的元素
专门针对元素来进行等待,有需要时调用即可
WebDriverWait().until() 一般用于等待元素
WebDriverWait().until_not() 一般用于等待弹框消息框消失
显示等待示例:
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
driver = webdriver.Chrome("E:\chromedriver_win32\chromedriver.exe") # 谷歌
# 窗口最大化
driver.maximize_window()
driver.get("http://www.baidu.com")
driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
el = WebDriverWait(driver, 5, 0.5).until(
lambda tmp: driver.find_element_by_xpath('//*[@id="2"]/div/div/h3/a'),
message="查找元素失败"
)
el.click()
driver.quit()