408复习笔记(一):经典数据结构和算法PART1(线性表、栈和队列、数组和特殊矩阵、串、树)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、线性表
- 1.单链表
- 2.双链表
- 3.循环链表
- 4.静态链表
- 二、操作受限的线性表——栈和队列
-
- 1.顺序栈
- 2.链栈
- 3.共享栈
- 4.队列的顺序存储
- 5.循环队列
- 6.链式队列
- 7.双端队列、输入受限的双端队列、输出受限的双端队列
- 8.应用
- 三、数组和特殊矩阵
-
- 1.对称矩阵
- 2.三角矩阵
- 3.三对角矩阵(带状矩阵)
- 4.稀疏矩阵
- 四、KMP算法(字符串模式匹配,即s2在s1中首次出现的位置)
-
- 1.求next数组
- 2.KMP算法
- 五、树
-
- 1.二叉树的性质
- 2.存储结构与二叉树的遍历
- 3.遍历生成线索二叉树
- 4.几种特殊的二叉树
- 5.平衡二叉树(AVL树)的构造
-
-
- 1)定义
- 2)插入时如何调整
- 3)删除时如何调整
- 4)例子
-
- 6.哈夫曼树的构造
-
-
- 1)定义
- 2)构造
- 3)应用
-
- 7.树、森林与二叉树的转换
-
-
- 1)树转为二叉树
- 2)森林转为二叉树
- 3)二叉树转为树
- 4)二叉树转为森林
-
- 8.红黑树
-
-
- 1)红黑树和平衡二叉树的区别:
- 2)红黑树和b树的区别:
-
- 9.并查集
-
-
- 1)定义
- 2)并查集的数组存储(逻辑上是树的结构)
-
- 附(树的习题,主要是哈夫曼树相关)
前言
利用暑假时间快速复习一下408~
本文记录需要熟练掌握的数据结构和算法。主要目的是了解算法的思想,对于实现暂时不做要求。
一、线性表
①定义:线性表是具有相同数据类型的n个元素的有限序列。除第一个元素外,每个元素有且仅有一个直接前驱;除最后一个元素外,每个元素有且仅有一个直接后继。
②实现:顺序表(数组)、链表(单链表、双链表、循环链表、静态链表)
1.单链表
struct LinkNode{
ElemType data; //值
LinkNode *next; //指向下一个节点的指针
};
2.双链表
struct DoubleLinkNode{
ElemType data; //值
LinkNode *next; //指向下一个节点的指针
LinkNode *prior;//指向上一个节点的指针
};
3.循环链表
最后一个结点的next指针不指向NULL,而指向头结点(头结点没有数据)
4.静态链表
借助数组实现的链式存储结构,结点也是data域和next域,指针是数组下标(也称游标)。
struct StaticLinkNode{
ElemType data;//值
int next;//下标
}
StaticLinkNode StaticLink[MaxSize];

二、操作受限的线性表——栈和队列
栈只允许在一端进行插入和删除(后进先出);队列只允许在表的一端插入,在另一端删除(先进先出)。
1.顺序栈
只在数组末尾进行插入和删除
2.链栈
只在链表的头结点后进行插入和删除
3.共享栈
两个顺序栈共享一个一位数组空间,两个栈底分别在数组左右,插入和删除时向数组中间延伸。
4.队列的顺序存储
队首在index=0处,队尾在后面;
两个指针front和rear分别指向队首元素和队尾元素的下一个元素(不重要定义罢了),出队和入队指针都需要+1
可能会出现假溢出的情况,因此引入循环队列。

5.循环队列
对于出队和入队指针移动时+1并%MaxSize
6.链式队列
一个同时带有队首指针和队尾指针的单链表
7.双端队列、输入受限的双端队列、输出受限的双端队列
双端队列是指两端都可以进行进出操作的队列,
如果一端可以进出,但另一端限制只能进or出,就形成输出受限的双端队列or输入受限的双端队列
8.应用
①栈的应用:递归(可以借助栈将递归算法转为非递归算法)、括号匹配、表达式求值
②队列的应用:树的层次遍历(根结点进队后,出一个结点,其全部孩子进队,再出再进,直至队空);计算机系统中的应用(作业调度先进先出)
7.23更新==
三、数组和特殊矩阵
特殊矩阵可以用数组来进行压缩存储
1.对称矩阵
aij=aji,存储时只存下三角(含主对角线元素)
2.三角矩阵
包括上三角矩阵和下三角矩阵,只有一半有元素需要存储,剩下一半是常量
3.三对角矩阵(带状矩阵)
所有非零元素集中在主对角线为中心的三条对角线区域,其他区域元素均为0,带状区域按行从上到下依次存入数组。

4.稀疏矩阵
矩阵中非零元素个数<<矩阵元素个数
可以用三元组(i,j,value)或十字链表法存储
=7.24更新=
四、KMP算法(字符串模式匹配,即s2在s1中首次出现的位置)
1.求next数组
①先给每个元素从1开始标号,这个标号可以唯一标志它,这很关键!
②设next(1)=0,next(2)=1,形成标号、元素、next的三层表格
③对于下一个元素,不断比较其前一个元素与前一个元素的next值指向的元素(指向编号,不断向前),直到两个元素相等或后者next值等于0(即已经向前到第一个元素),如果一次比较就成功,next值为前者的next值+1,否则next值为后者的next值+1
例如:
对于下一个元素【7】,
比较其前一个元素【6】与【6】的next值(next[6]=3)指向的元素【3】,【3】=a,【6】=c,不等,继续比较;
第一个元素【6】不变,第二个元素变为【3】的next值(next[3]=1)指向的元素【1】,【1】=a,【6】=c,不等,但已经到了第一个元素,即next[1]已经等于0;
next值为后者的next值+1,即next[7]=next[1]+1=1

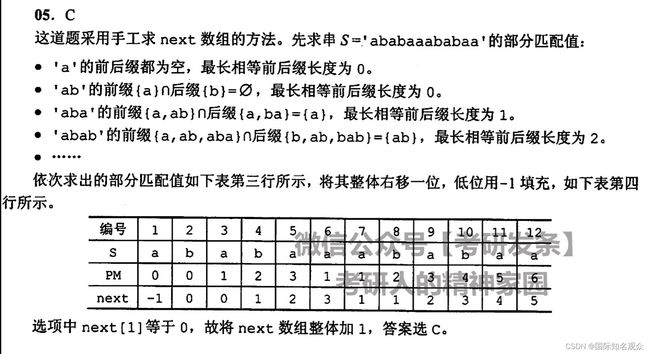
下面介绍一个手工求next数组的方法,更快,适用于长字符串:
依次求出从头到每个元素为止的字符串的最长相等前后缀长度(求出所有前缀集合和所有后缀集合,交集的长度就为最长相等前后缀长度,也可以用观察法,开头左到右和末尾左到右相等的最大字符串的长度,注意都是顺序的),然后整体右移一位,低位用-1填充,就可以得到next数组
例如
2.KMP算法
关键点在于,
①当匹配过程中发生失配时,主串指针i不动,模式字符串中的指针j移到next【j】位置继续匹配
②当指针j为0时,与匹配成功的情况一样,指针i和j同时加一

7.25更新=
五、树

1.二叉树的性质
①n0 = n2 + 1(重)
②第i层最多 2^(i-1) 个结点
③高度为h 最多 2^h -1 个结点
2.存储结构与二叉树的遍历
①顺序存储(完全二叉树或者满二叉树比较合适,因为根据下标就可以定位位置)
②链式存储(left、right、root)
**遍历方法:**先序、中序、后序、层次
由二叉树的先序序列和中序序列、后和中、层序和中序可以唯一确定一个二叉树:
3.遍历生成线索二叉树
根据一定的遍历规则对二叉树进行遍历时,如果遇到空的指针,就指向此次遍历的前驱或后继结点(左孩子指向前驱,右孩子指向后继)。
线索是遍历中前驱结点和后续节点的指针,他不浪费多余的空间,只是合理利用原先的空指针。
引入线索二叉树的目的是加快查找结点前驱或后继的速度。
4.几种特殊的二叉树
①满二叉树:树中每层都含有最多的结点
②完全二叉树:满二叉树从最后一层右边往左删掉部分结点
③二叉排序树(二叉搜索树):左子树结点值都小于根结点值,右子树结点值都大于根结点值
④平衡二叉树:在构造二叉排序树的同时进行调整,使树上任一结点的左子树和右子树高度之差不超过1
====7.26更新
5.平衡二叉树(AVL树)的构造
1)定义
①定义:左子树和右子树高度之差的绝对值不超过1;
②平衡因子:结点的左子树高度-右子树高度称为该结点的平衡因子(平衡二叉树的平衡因子只能是0、-1、1)。若子树为空,高度记为0.叶子结点的平衡因子一定为0
③为什么是AVL?
二叉搜索(排序)树一定程度上可以提高搜索效率,但是当原序列有序时,依据此序列构造的二叉搜索树为右斜树或者左斜树,同时二叉树退化成单链表,搜索效率降低为 O(n)。
二叉搜索树的查找效率取决于树的高度,因此保持树的高度最小,即可保证树的查找效率。因此就有了AVL树。
2)插入时如何调整
①找到插入节点后导致不平衡的最小子树的根:找距离插入节点最近的一个、平衡因子绝对值大于一的结点
②对该最小子树(只能有3个结点,一般都是根+儿子+孙子)进行平衡调整:
LL型——R (不平衡根的左孩子的左孩子导致不平衡,整体右转
RR型——L (不平衡根的右孩子的右孩子导致不平衡,整体左转
LR型——LR (不平衡根的左孩子的右孩子导致不平衡,先两个孩子左转,成为LL型,然后整体右转)
RL型——RL(不平衡根的右孩子的左孩子导致不平衡,先两个孩子右转,成为RR型,然后整体左转)
③整理一下,继续插入下一个结点
3)删除时如何调整
①叶子结点直接删除
②被删结点只有左or右子树,孩子顶上
③被删结点左右子树都有:找右子树的最左结点(建议)或左子树的最右节点提上去
(原理:也就是中序遍历的前驱或后继元素)
4)例子
【二叉平衡树AVL平衡调整数据结构-哔哩哔哩】 https://b23.tv/RkSwYB0 空降11:27
6.哈夫曼树的构造
1)定义
①哈夫曼树(最优二叉树):给定若干带权结点,使他们作为叶节点,构成带权路径长度最短的二叉树。
②结点的带权路径长度:从根到该结点的路径长度与该结点权值的乘积
③树的带权路径长度:各叶子结点的带权路径长度之和

2)构造
①寻找集合T中权值最小的两个节点;
②使用两个权值最小的节点构建新的节点加入集合T,新节点权值为两个结点权值之和,删除①中的两个结点
③重复①②直至集合T为空
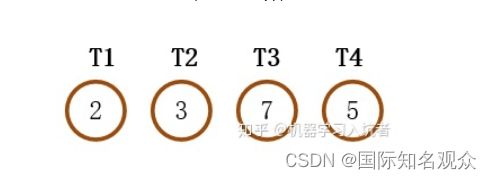

3)应用
哈夫曼树可用来构造最优编码,用于信息传输,数据压缩等方面。
如下图所示,将字符作为叶子结点,将其出现的频率作为权重,构造哈夫曼树,就能使出现次数多的字符编码短:

7.树、森林与二叉树的转换
1)树转为二叉树
转化后,某结点的左孩子是其原长子,右孩子是其原右邻兄弟(也就是说,转化后的根结点一定没有右孩子)
①树中所有相邻兄弟间加一条连线
②每个结点只保留和长子的连线,删除和其他孩子的连线
③以跟结点为中心顺时针旋转45°
2)森林转为二叉树
①森林中每棵树都转化为二叉树
②从第2个二叉树开始,依次把根结点作为前一棵树根的右孩子结点
3)二叉树转为树
每个结点的左孩子不变,右孩子还原成他的右兄弟结点
4)二叉树转为森林
①抹掉二叉树根结点右链上的所有“父节点-右孩子”关系,得到若干二叉树
②将二叉树还原为树
8.红黑树
1)红黑树和平衡二叉树的区别:
https://blog.csdn.net/weixin_44780082/article/details/112239269
2)红黑树和b树的区别:
①策略不一样,红黑树属于内排序,b树属于外排序,它们复杂度相同或者相近的排序方法虽然有很多种,但是这些排序方法依然是不同的排序算法;
②黑树是二叉树的变种, b树一个节点代表数据的集合或者范围;
③从应用层面看,红黑树适合小数据范围内的快速查找,然而b树适合大范围数据查找
7.27更新==
9.并查集
1)定义
并查集是一种简单的集合表示,一个树表示一个子集,森林表示所有子集的集合。他可以支持查(查找任一个元素的祖先(即根结点))和并(这里指求不相交的集合的并集,将两棵子树合并,一棵子树的根结点变为另一颗子树的孩子)两种操作。
2)并查集的数组存储(逻辑上是树的结构)
①并查集通常用数组存储,每个元素的下标就是结点编号,而元素的值有不同的含义。树的根结点元素对应的值一般是负数,其绝对值代表这棵树的结点个数;其他节点元素对应的值代表森林中这棵子树的编号(兄弟间编号是相同的)。如:

第一棵树,结点0为根,data【0】=-4,代表0是根结点且此树中有四个元素;date【6】、date【7】、date【8】都是0,表示其根结点下标是0.
第二棵树,结点1为根,data【1】=-3,代表1是根结点且此树中有三个元素;date【4】、date【9】都是1,表示其根结点下标是1.
第三棵树,结点2为根,data【2】=-3,代表2是根结点且此树中有三个元素;date【3】、date【5】都是2,表示其根结点下标是2.
②初始化时,将所有值设置为-1,即将集合S中的n个元素初始化为n个只有一个元素的集合。如:

#define SIZE 100
int UFSets[SIZE];
void Initial(int S[]){
for(int i = 0; i < size; i++){
S[i] = -1; //每个元素自成集合
}
}
③查找Find(S, x):查找集合S中元素x的根结点的标号。(是负数)
void Find(int S[], int x){
while(S[x] > 0){//循环寻找x的根
x = S[X];
}
return x;//根的S[]<0
}
④Union(S, Root1, Root2):把子集合Root2并入子集合Root1。(两个集合互不相交)(此处的ROOT2、ROOT1都是指结点下标)
将root2的根结点的S【】变为Root1的下标

void Union(int S[], int Root1, int Root2){
S[Root2] = Root1;
}
附(树的习题,主要是哈夫曼树相关)
①对于任意一个树,度数+1=节点数
②树的路径长度是根结点到各个结点的路径长度的总和
③二叉树的性质的笔记有空可以看看,但面试应该不会问
④哈夫曼树没有度为1的结点,又由于度为2的结点个数是度为0的结点个数+1,故节点总数是2*N0-1
⑤**前缀码:**任何一个字符的编码都不能是其他字符编码的前缀。哈夫曼编码是前缀码,因为没有一片树叶是另一片树叶的祖先, 所以每个叶子结点的编码就不可能是其它叶子结点编码的前缀。
⑥一组权值构造的哈夫曼树通常不唯一,因为左右子树没有规定
后续见:408复习笔记(二):经典数据结构和算法PART2(图、查找、排序)