中间件-kafka
1、简介
Kafka最初由Linkedin公司开发,是一个分布式的、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常用于web/nginx日志、访问日志、消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
kafka官网地址
1.1 kafka 特性
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒;
- 可扩展性:kafka集群支持热扩展;
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止丢失;
- 容错性:允许集群中的节点失败(若分区副本数量为n,则允许n-1个节点失败);
- 高并发:单机可支持数千个客户端同时读写;
1.2 kafka的应用场景
- 日志收集:一个公司可以用Kafka收集各种服务的log,通过kafka以统一接口开放给各种消费端,例如hadoop、Hbase、Solr等。
- 消息系统:解耦生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索记录、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。
- 流式处理
1.3 kafka 基础架构图

1.4 kafka 基础组件介绍
kafka架构中包含四大组件:生产者、消费者、kafka集群、zookeeper集群。对照1.3架构理解。
-
broker
kafka 集群包含一个或多个服务器,每个服务器节点称为一个broker。 -
topic
每条发布到kafka集群的消息都有一个类别,这个类别称为topic,其实就是将消息按照topic来分类,topic就是逻辑上的分类,同一个topic的数据既可以在同一个broker上也可以在不同的broker结点上。 -
partition
分区,每个topic被物理划分为一个或多个分区,每个分区在物理上对应一个文件夹,该文件夹里面存储了这个分区的所有消息和索引文件。在创建topic时可指定parition数量,生产者将消息发送到topic时,消息会根据 分区策略 追加到分区文件的末尾,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
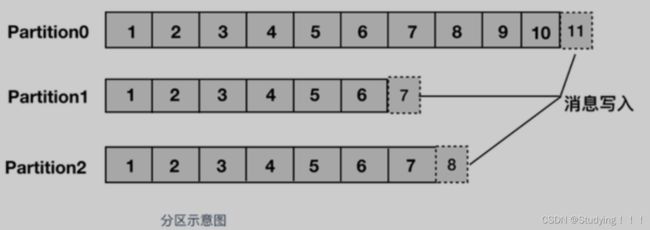
上面提到了分区策略,所谓分区策略就是决定生产者将消息发送到哪个分区的算法。Kafka 为我们提供了默认的分区策略,同时它也支持自定义分区策略。kafka允许为每条消息设置一个key,一旦消息被定义了 Key,那么就可以保证同一个 Key 的所有消息都进入到相同的分区,这种策略属于自定义策略的一种,被称作"按消息key保存策略",或Key-ordering 策略。同一主题的多个分区可以部署在多个机器上,以此来实现 kafka 的伸缩性。同一partition中的数据是有序的,但topic下的多个partition之间在消费数据时不能保证有序性,在需要严格保证消息顺序消费的场景下,可以将partition数设为1,但这种做法的缺点是降低了吞吐,一般来说,只需要保证每个分区的有序性,再对消息设置key来保证相同key的消息落入同一分区,就可以满足绝大多数的应用。
-
offset
partition中的每条消息都被标记了一个序号,这个序号表示消息在partition中的偏移量,称为offset,每一条消息在partition都有唯一的offset,消息者通过指定offset来指定要消费的消息。正常情况下,消费者在消费完一条消息后会递增offset,准备去消费下一条消息,但也可以将offset设成一个较小的值,重新消费一些消费过的消息,可见offset是由consumer控制的,consumer想消费哪一条消息就消费哪一条消息,所以kafka broker是无状态的,它不需要标记哪些消息被消费过。
-
producer
生产者,生产者发送消息到指定的topic下,消息再根据分配规则append到某个partition的末尾。 -
consumer
消费者,消费者从topic中消费数据。 -
consumer group
消费者组,每个consumer属于一个特定的consumer group,可为每个consumer指定consumer group,若不指定则属于默认的group。同一topic的一条消息只能被同一个consumer group内的一个consumer消费,但多个consumer group可同时消费这一消息。这也是kafka用来实现一个topic消息的广播和单播的手段,如果需要实现广播,一个consumer group内只放一个消费者即可,要实现单播,将所有的消费者放到同一个consumer group即可。
用consumer group还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。 -
Replica:副本Replication,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower
-
leader
每个partition有多个副本,其中有且仅有一个作为leader,leader会负责所有的客户端读写操作。 -
follower
follower不对外提供服务,只与leader保持数据同步,如果leader失效,则选举一个follower来充当新的leader。当follower与leader挂掉、卡住或者同步太慢,leader会把这个follower从ISR列表中删除,重新创建一个follower。 -
rebalance
同一个consumer group下的多个消费者互相协调消费工作,我们这样想,一个topic分为多个分区,一个consumer group里面的所有消费者合作,一起去消费所订阅的某个topic下的所有分区(每个消费者消费部分分区),kafka会将该topic下的所有分区均匀的分配给consumer group下的每个消费者,如下图,

rebalance表示"重平衡",consumer group内某个消费者挂掉后,其他消费者自动重新分配订阅主题分区的过程,是 Kafka 消费者端实现高可用的重要手段。如下图Consumer Group A中的C2挂掉,C1会接收P1和P2,以达到重新平衡。同样的,当有新消费者加入consumer group,也会触发重平衡操作。
1.5 kafka架构理解
1.5.1 简单理解
一个典型的kafka集群中包含若干producer,若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干consumer group,以及一个zookeeper集群。kafka通过zookeeper协调管理kafka集群,选举分区leader,以及在consumer group发生变化时进行rebalance。
kafka的topic被划分为一个或多个分区,多个分区可以分布在一个或多个broker节点上,同时为了故障容错,每个分区都会复制多个副本,分别位于不同的broker节点,这些分区副本中(不管是leader还是follower都称为分区副本),一个分区副本会作为leader,其余的分区副本作为follower。其中leader负责所有的客户端读写操作,follower不对外提供服务,仅仅从leader上同步数据,当leader出现故障时,其中的一个follower会顶替成为leader,继续对外提供服务。
1.5.2 相对于传统MQ的优点
- 对于传统的MQ而言,已经被消费的消息会从队列中删除,但在Kafka中被消费的消息也不会立马删除,在kafka的server.propertise配置文件中定义了数据的保存时间,当文件到设定的保存时间时才会删除,数据的保存时间(单位:小时,默认为7天)
log.retention.hours=168
因为Kafka读取消息的时间复杂度为O(1),与文件大小无关,所以这里删除过期文件与提高Kafka性能并没有关系,所以选择怎样的删除策略应该考虑磁盘以及具体的需求。
1.5.3 消费模式
-
点对点模式 VS 发布订阅模式
传统的消息系统中,有两种主要的消息传递模式:点对点模式、发布订阅模式。①点对点模式
生产者发送消息到queue中,queue支持存在多个消费者,但是对一个消息而言,只可以被一个消费者消费,并且在点对点模式中,已经消费过的消息会从queue中删除不再存储。②发布订阅模式
生产者将消息发布到topic中,topic可以被多个消费者订阅,且发布到topic的消息会被所有订阅者消费。而kafka就是一种发布订阅模式。
1.5.4 消费端的pull和push模式
-
push方式:由消息中间件主动地将消息推送给消费者;
优点:优点是不需要消费者额外开启线程监控中间件,节省开销。
缺点:无法适应消费速率不相同的消费者。因为消息的发送速率是broker决定的,而消
费者的处理速度又不尽相同,所以容易造成部分消费者空闲,部分消费者堆积,造成缓
冲区溢出。 -
pull方式:由消费者主动向消息中间件拉取消息;
优点:消费端可以按处理能力进行拉取;
缺点:消费端需要另开线程监控中间件,有性能开销;
对于Kafka而言,pull模式更合适。pull模式可简化broker的设计,Consumer可自主控制消费消息的速率,同时Consumer可以自己控制消费方式,既可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
1.5.5 kafka和rabbitMQ对比
| RabbitMQ | kafka | |
|---|---|---|
| 开发语言 | erlang | scala,Java |
| 架构模型 | ① 遵循AMQP;② 生产者、消费者、broker。③ broker由exchange、binding、queue组成;④ consumer消费位置由broker通过确认机制保存; | ① 不遵循AMQP;② 生产者、消费者、kafka集群、zookeeper集群;③ kafka集群由多个broker节点组成,消息按照topic分类,每个topic又划分为多个partition;④ broker无状态,offset由消费者指定; |
| 可靠性 | 支持事务机制,允许生产者在发送一批消息之前开启一个事务,将多个操作视为一个原子性操作,只有在所有操作成功完成后才提交事务,否则回滚事务。事务机制虽然保证了数据的一致性,但性能较差,会影响消息处理的吞吐量。 | 不支持事务机制,但通过producer的异步回调函数可以实现基于消息确认的事务控制。在生产者发送消息后,可以设置一个回调函数,当消息被成功写入Kafka集群时,回调函数将被触发,此时可以认为该消息已被成功发送。通过这种方式,使用Kafka实现事务控制可以保证高吞吐量的同时保证消息的可靠性。 |
| 高可用 | 采用镜像队列,即主从模式,数据是异步同步的,当消息过来,主从全部写完后,回ack,这样保障了数据的一致性。 | 每个分区都有一个或多个副本,这些副本保存在不同的broker上,其中有且仅有一个分区副本作为leader,其余的作为follower,当leader不可用时,会选举follower作为新leader继续提供服务。只有leader提供读写服务,follower从leader同步拉取数据然后备份。 |
| 吞吐量 | kafka更高 | |
| 是否支持事务 | 支持 | 不支持 |
| 负载均衡 | 需要外部支持才能实现(如:loadbalancer) | kafka利用zk和分区机制实现负载均衡 |
| 是否支持消费者Push | 不支持 | 支持 |
| 是否支持消费者Pull | 支持 | 支持 |
| 适用场景 | kafka的优势主要体现在吞吐量上,它主要用在高吞吐量的场景。比如日志采集。 | 具有较高的严谨性,数据丢失的可能性更小,同时具备较高的实时性,用在对实时性、可靠性要求较高的消息传递上。 |
1.5.6 kafka吞吐量为什么这么高
1、顺序读写磁盘
Kafka是将消息持久化到本地磁盘中的,一般人会认为磁盘读写性能差,可能会对Kafka性能提出质疑。实际上不管是内存还是磁盘,快或慢的关键在于寻址方式,磁盘分为顺序读写与随机读写,内存一样也分为顺序读写与随机读写。基于磁盘的随机读写确实很慢,但基于磁盘的顺序读写性能却很高,一般而言要高出磁盘的随机读写三个数量级,一些情况下磁盘顺序读写性能甚至要高于内存随机读写。
2、page cache
为了优化读写性能,Kafka利用了操作系统本身的Page Cache,就是利用操作系统自身的内存而不是JVM空间内存。这样做是因为,
JVM中一切皆对象,对象的存储会带来额外的内存消耗;
使用JVM会受到GC的影响,随着数据的增多,垃圾回收也会变得复杂与缓慢,降低吞吐量;
另外操作系统本身对page cache做了大量优化,通过操作系统的Page Cache,Kafka的读写操作基本上是基于系统内存的,读写性能也得到了极大的提升。
3、零拷贝
零拷贝是指Kafka利用 linux 操作系统的 “zero-copy” 机制在消费端做的优化。首先来看一下消费端在消费数据时,数据从broker磁盘通过网络传输到消费端的整个过程:
1、操作系统从磁盘读取数据到内核空间(kernel space)的page cache;
2、应用程序读取page cache的数据到用户空间(user space)的缓冲区;
3、应用程序将用户空间缓冲区的数据写回内核空间的socket缓冲区(socket buffer);
4、操作系统将数据从socket缓冲区复制到硬件(如网卡)缓冲区;

整个过程如上图所示,这个过程包含4次copy操作和2次系统上下文切换,而上下文切换是CPU密集型的工作,数据拷贝是I/O密集型的工作,性能其实非常低效。
零拷贝就是使用了一个名为sendfile()的系统调用方法,将数据从page cache直接发送到Socket缓冲区,避免了系统上下文的切换,消除了从内核空间到用户空间的来回复制。从上图可以看出,"零拷贝"并不是说整个过程完全不发生拷贝,而是站在内核的角度来说的,避免了内核空间到用户空间的来回拷贝。
4、分区分段
Kafka的message是按topic分类存储的,topic中的数据又是按照一个一个的partition即分区存储到不同broker节点。每个partition对应了操作系统上的一个文件夹,partition实际上又是按照segment分段存储的。这也非常符合分布式系统分区分桶的设计思想。
通过这种分区分段的设计,Kafka的message消息实际上是分布式存储在一个一个小的segment中的,每次文件操作也是直接操作的segment。为了进一步的查询优化,Kafka又默认为分段后的数据文件建立了索引文件,就是文件系统上的.index文件。这种分区分段+索引的设计,不仅提升了数据读取的效率,同时也提高了数据操作的并行度。

1.6 zk目录结构

[root@master ~]# vim /kafka-cluster/kafka1/config/server.properties
# 测试场景中配置ZK连接位置如下,则ZK中存储的Kafka元数据均位于/路径下
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
# 如果测试场景中配置ZK连接位置如下,则ZK中存储的Kafka元数据均位于/kafka路径下
zookeeper.connect=localhost:2181/kafka,localhost:2182/kafka,localhost:2183/kafka
#如果都配置好了,不推荐在进行修改。
1.6.1. /brokers
每个Broker的配置文件中都需要指定一个数字类型的id(全局不可重复),此节点为临时 Znode(EPHEMERAL)。
1.6.1.1 /brokers/ids
[zk: localhost:2181(CONNECTED) 0] ls / #由于此处未配置kafka目录,所以都在/目录下
[admin, brokers, cluster, config, consumers, controller, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /brokers
[ids, seqid, topics]
> get -s /brokers/ids/0
{
"listener_security_protocol_map": {
"PLAINTEXT": "PLAINTEXT" # 明文显示
},
"endpoints": [
"PLAINTEXT://master:9092"
],
"jmx_port": -1, # jmx端口号
"features": {},
"host": "master", # 主机名或ip地址
"timestamp": "1691651715646", # broker初始启动时的时间戳
"port": 9092, # broker的服务端端口号,由server.properties中参数port确定
"version": 5 # 版本编号默认为1,递增
}
cZxid = 0x300000071
ctime = Thu Aug 10 15:15:15 CST 2023
mZxid = 0x300000071
mtime = Thu Aug 10 15:15:15 CST 2023
pZxid = 0x300000071
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x100233882bf0008 # 临时节点标识
dataLength = 196
numChildren = 0
1.6.1.2 /brokers/topics
> ls /brokers/topics
[__consumer_offsets, hello_test]
> ls /brokers/topics/hello_test
[partitions]
> get -s /brokers/topics/hello_test
{
"removing_replicas": {},
"partitions":{"1":[0,2],"0":[1,0]}, # 同步副本组BrokerId列表(ISR)
"topic_id": "hQ7vPPgRQF2XEwhRSxO7nA",
"adding_replicas": {},
"version": 3
}
cZxid = 0x200000077
ctime = Tue Aug 08 17:45:47 CST 2023
mZxid = 0x200000077
mtime = Tue Aug 08 17:45:47 CST 2023
pZxid = 0x200000078
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 128
numChildren = 1
> ls /brokers/topics/hello_test/partitions
[0, 1]
> ls /brokers/topics/hello_test/partitions/0
[state]
> get -s /brokers/topics/hello_test/partitions/0/state
{
"controller_epoch": 3, # Kafka集群中的中央控制器选举次数
"leader": 1, # 该Partition选举Leader的BrokerId
"version": 1, # 版本编号默认为1
"leader_epoch": 3, # 该Partition Leader选举次数
"isr": [0,1] # ISR列表
}
cZxid = 0x20000007c
ctime = Tue Aug 08 17:45:47 CST 2023
mZxid = 0x30000007b
mtime = Thu Aug 10 15:15:21 CST 2023
pZxid = 0x20000007c
cversion = 0
dataVersion = 4
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 74
numChildren = 0
1.6.2 /consumers
每个Consumer都有唯一的id,用来标记消费者信息,该目录下仅展示使用ZK进行消费的 Consumers,如果之间指定Kafka节点进行消费,不会在此展示。
> ls /consumers
[console-consumer-84155, console-consumer-32194, wolves_report, console-consumer-9761, wolves_v2_gdt, console-consumer-63530, wolves, wolves_feedback, wolves_kuaishou, console-consumer-62629, ftrl1, console-consumer-56068, wolves_tuia]
> ls /consumers/wolves_report
[ids, owners, offsets]
注意事项:
使用kafka-console-consumer.sh命令创建的消费者并不会在Zookeeper的/consumers路径下创建消费者组信息,因为该命令使用的是新的消费者API,它使用了Kafka集群的元数据来管理消费者组信息,而不是使用Zookeeper。
新的消费者API不再需要将消费者组信息写入到Zookeeper中,因为Kafka集群本身就足够强大,可以自己管理消费者组信息。因此,使用kafka-console-consumer.sh创建的消费者不会在Zookeeper的/consumers路径下创建消费者组信息,而是在Kafka集群的元数据中进行管理。
Kafka的最新版本已经逐步淘汰了使用Zookeeper作为消费者元数据存储的方式,而是采用内部存储来管理消费者组信息。因此,新版本的Kafka已经不再支持使用–zookeeper参数来指定Zookeeper的连接信息。
如果你想要创建一个在Zookeeper的/consumers路径下的消费者,你需要使用旧的消费者API,而不是使用kafka-console-consumer.sh命令所使用的新的消费者API。
因此以下配置均来自旧版本Kafka。
1.6.2.1 /consumers/{groupId}/ids
> ls /consumers/wolves_report/ids
[wolves_report_node1.tc.wolves.dmp.com-1536837975646-39504764, wolves_report_node1.tc.wolves.dmp.com-1536838003051-182cc752,...]
> get /consumers/wolves_report/ids/wolves_report_node1.tc.wolves.dmp.com-1536837975646-39504764 # 旧版本下ZK命令get效果等于新版本ZK命令get -s
{
"version":1, # 版本编号默认为1
"subscription": # 订阅的Topic列表
{
"wolves-event":3 # Consumer中Topic消费者线程数
},
"pattern":"static", # 模式
"timestamp":"1537128878487" # Consumer启动时的时间戳
}
cZxid = 0x717782b21
ctime = Mon Sep 17 04:14:38 CST 2022
mZxid = 0x717782b21
mtime = Mon Sep 17 04:14:38 CST 2022
pZxid = 0x717782b21
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x36324802b64ea62
dataLength = 94
numChildren = 0
1.6.2.2 /consumers/{groupId}/owner
> ls /consumers/wolves_report/owners
[wolves-event] # topic
> ls /consumers/wolves_report/owners/wolves-event
[0, 1, 2] # partitionId
> get /consumers/wolves_report/owners/wolves-event/0
wolves_report_node1.tc.wolves.dmp.com-1536837527210-1310d8f9-0
cZxid = 0x717782ba9
ctime = Mon Sep 17 04:14:40 CST 2022
mZxid = 0x717782ba9
mtime = Mon Sep 17 04:14:40 CST 2022
pZxid = 0x717782ba9
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x26324802b69ea62
dataLength = 62
numChildren = 0
1.6.2.3 /consumers/{groupId}/offset
> ls /consumers/wolves_report/offsets
[wolves-event] # topic
> ls /consumers/wolves_report/offsets/wolves-event
[0, 1, 2] # partitionId
> get /consumers/wolves_report/offsets/wolves-event/0
48800
cZxid = 0x200e97e36
ctime = Thu Nov 23 17:22:10 CST 2022
mZxid = 0x718665858
mtime = Fri Sep 21 12:02:39 CST 2022
pZxid = 0x200e97e36
cversion = 0
dataVersion = 11910567
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 0
1.6.3 /admin
1.6.3.1 /admin/reassign_partitions
用以Partitions重分区,Reassign结束后会删除该目录。
> ls /admin/reassign_partitions
[]
1.6.3.2 /admin/preferred_replica_election
用以Partitions各副本Leader选举,副本选举结束后会删除该目录。
> ls /admin/reassign_partitions
[]
1.6.3.3 /admin/delete_topics
管理已删除的Topics,Broker启动时检查并确保存在。
> ls /admin/delete_topics
[]
1.6.4 /controller
存储Center controller中央控制器所在Kafka broker的信息。
> get -s /controller
{
"version": 2, # 版本编号默认为1
"brokerid": 1, # BrokerID
"timestamp": "1691722592052", # Broker中央控制器变更时的时间戳
"kraftControllerEpoch": -1
}
cZxid = 0x4000000de
ctime = Fri Aug 11 10:56:32 CST 2023
mZxid = 0x4000000de
mtime = Fri Aug 11 10:56:32 CST 2023
pZxid = 0x4000000de
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x10000042fff0009
dataLength = 80
numChildren = 0
1.6.5 /controller_epoch
Kafka集群中第一个Broker第一次启动时该值为1,后续只要集群中Center Controller中央控制器所在Broker变更或挂掉,就会重新选举新的Center Controller,每次Center Controller变更controller_epoch值就会自增1。
> get -s /kafka/controller_epoch
6
cZxid = 0x10000003f
ctime = Tue Aug 08 16:24:00 CST 2023
mZxid = 0x4000000de
mtime = Fri Aug 11 10:56:32 CST 2023
pZxid = 0x10000003f
cversion = 0
dataVersion = 6
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 1
numChildren = 0
2、kafka HA机制
2.1 名词解释
2.1.1 AR ISR OSR
-
AR:Assigned Replicas,某分区的所有副本(这里所说的副本包括leader和follower)统称为 AR。
-
ISR:In Sync Replicas,所有与leader副本保持"一定程度同步"的副本(包括leader副本在内)组成 ISR 。生产者发送消息时,只有leader与客户端发生交互,follower只是同步备份leader的数据,以保障高可用,所以生产者的消息会先发送到leader,然后follower才能从leader中拉取消息进行同步,同步期间,follower的数据相对leader而言会有一定程度的滞后,前面所说的"一定程度同步"就是指可忍受的滞后范围,这个范围可以通过server.properties中的参数进行配置。
-
OSR :Out-of-Sync Replied,在上面的描述中,相对leader滞后过多的follower将组成OSR 。
-
由此可见,AR = ISR + OSR,理想情况下,所有的follower副本都应该与leader 保持一定程度的同步,即AR=ISR,OSR集合为空
2.1.2 ISR 的伸缩性
leader负责跟踪维护 ISR 集合中所有follower副本的滞后状态,当follower副本"落后太多" 或 "follower超过一定时间没有向leader发送同步请求"时,leader副本会把它从 ISR 集合中剔除。如果 OSR 集合中有follower副本"追上"了leader副本,那么leader副本会把它从 OSR 集合转移至 ISR 集合。
上面描述的"落后太多"是指follower复制的消息落后于leader的条数超过预定值,这个预定值可在server.properties中通过replica.lag.max.messages配置,其默认值是4000。“超过一定时间没有向leader发送同步请求”,这个"一定时间"可以在server.properties中通过replica.lag.time.max.ms来配置,其默认值是10000,默认情况下,当leader发生故障时,只有 ISR 集合中的follower副本才有资格被选举为新的leader,而在 OSR 集合中的副本则没有任何机会(不过这个可以通过配置来改变)。
2.1.3 HW
HW (High Watermark)俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能消费HW之前的消息。
下图表示一个日志文件,这个日志文件中有9条消息,第一条消息的offset为0,最后一条消息的offset为8,虚线表示的offset为9的消息,代表下一条待写入的消息。日志文件的 HW 为6,表示消费者只能拉取offset在 0 到 5 之间的消息,offset为6的消息对消费者而言是不可见的。
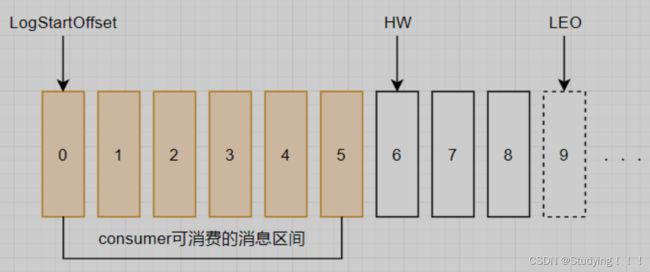
2.1.4 LEO
LEO (Log End Offset),标识当前日志文件中下一条待写入的消息的offset。上图中offset为9的位置即为当前日志文件的 LEO,分区 ISR 集合中的每个副本都会维护自身的 LEO ,而 ISR 集合中最小的 LEO 即为分区的 HW,对消费者而言只能消费 HW 之前的消息。
2.1.5 ISR 集合和 HW、LEO的关系
-
producer在发布消息到partition时,只会与该partition的leader发生交互将消息发送给leader,leader会将该消息写入其本地log,每个follower都从leader上pull数据做同步备份,follower在pull到该消息并写入其log后,会向leader发送ack,一旦leader收到了ISR中的所有follower的ack(只关注ISR中的所有follower,不考虑OSR,一定程度上提升了吞吐),该消息就被认为已经commit了,leader将增加HW,然后向producer发送ack。
-
也就是说,在ISR中所有的follower还没有完成数据备份之前,leader不会增加HW,也就是这条消息暂时还不能被消费者消费,只有当ISR中所有的follower都备份完成后,leader才会将HW后移。
-
ISR集合中LEO最小的副本,即同步数据同步的最慢的一个,这个最慢副本的LEO即leader的HW,消费者只能消费HW之前的消息。
2.2 HA策略与选举逻辑
注意:副本包括leader和follower,都叫副本,不要认为叫副本说的就是follower。
kafka在0.8以前的版本中是没有分区副本的概念的,一旦某一个broker宕机,这个broker上的所有分区都将不可用。在0.8版本以后,引入了分区副本的概念,同一个partition可以有多个副本,在多个副本中会选出一个做leader,其余的作为follower,只有leader对外提供读写服务,follower只负责从leader上同步拉取数据,已保障高可用。
2.2.1 partition副本的分配策略
每个topic有多个partition,每个partition有多个副本,这些partition副本分布在不同的broker上,以保障高可用,那么这些partition副本是怎么均匀的分布到集群中的每个broker上的呢?
kafka分配partition副本的算法如下,
- 将所有的broker(假设总共n个broker)和 待分配的partition排序;
- 将第i个partition分配到第(i mod n)个broker上;
- 第i个partition的第j个副本分配到第((i+j) mod n)个broker上;
2.2.2 kafka的消息传递备份策略
生产者将消息发送给分区的leader,leader会将该消息写入其本地log,然后每个follower都会从leader pull数据,follower pull到该消息并将其写入log后,会向leader发送ack,当leader收到了ISR集合中所有follower的ack后,就认为这条消息已经commit了,leader将增加HW并且向生产者返回ack。在整个流程中,follower也可以批量的从leader复制数据,以提升复制性能。
producer在发送消息的时候,可指定参数acks,表示"在生产者认为发送请求完成之前,有多少分区副本必须接收到数据",有三个可选值,0、1、all(或-1),默认为1,
- acks=0,表示producer只管发,只要发出去就认为发发送请求完成了,不管leader有没有收到,更不管follower有没有备份完成。
- acks=1,表示只要leader收到消息,并将其写入自己log后,就会返回给producer ack,不考虑follower有没有备份完成。
- acks=all(或-1),表示不仅要leader收到消息写入本地log,还要等所有ISR集合中的follower都备份完成后,producer才认为发送成功。

实际上,为了提高性能,follower在pull到消息将其保存到内存中而尚未写入磁盘时,就会向leader发送ack,所以也就不能完全保证异常发生后该条消息一定能被Consumer消费。
2.2.3 kafka中的Leader选举
kafka中涉及到选举的地方有多处,最常提及的也有:①cotroller选举 、 ②分区leader选举 和 ③consumer group leader的选举。我们在前面说过同一个partition有多个副本,其中一个副本作为leader,其余的作为follower。这里我们再说一个角色:controller!kafka集群中多个broker,有一个会被选举为controller,注意区分两者,一个是broker的leader,我们称为controller,一个是分区副本的leader,我们称为leader。
-
controller的选举【broker的leader】
- controller的选举是通过broker在zookeeper的"/controller"节点下创建临时节点来实现的,并在该节点中写入当前broker的信息 {“version”:1,”brokerid”:1,”timestamp”:”1512018424988”} ,利用zookeeper的强一致性特性,一个节点只能被一个客户端创建成功,创建成功的broker即为controller,即"先到先得"。
- 当controller宕机或者和zookeeper失去连接时,zookeeper检测不到心跳,zookeeper上的临时节点会被删除,而其它broker会监听临时节点的变化,当节点被删除时,其它broker会收到通知,重新发起controller选举。
-
leader的选举【分区副本的leader】
分区leader的选举由 controller 负责管理和实施,当leader发生故障时,controller会将leader的改变直接通过RPC的方式通知需要为此作出响应的broker,需要为此作出响应的broker即该分区的ISR集合中follower所在的broker,kafka在zookeeper中动态维护了一个ISR,只有ISR里的follower才有被选为Leader的可能。
具体过程是这样的:按照AR集合中副本的顺序 查找到 第一个 存活的、并且属于ISR集合的 副本作为新的leader。一个分区的AR集合在创建分区副本的时候就被指定,只要不发生重分配的情况,AR集合内部副本的顺序是保持不变的,而分区的ISR集合上面说过因为同步滞后等原因可能会改变,所以注意这里是根据AR的顺序而不是ISR的顺序找。
※ 对于上面描述的过程我们假设一种极端的情况,如果partition的所有副本都不可用时,怎么办?这种情况下kafka提供了两种可行的方案:
-
1、选择 ISR中 第一个活过来的副本作为Leader;
-
2、选择第一个活过来的副本(不一定是ISR中的)作为Leader;
这就需要在可用性和数据一致性当中做出选择,如果一定要等待ISR中的副本活过来,那不可用的时间可能会相对较长。选择第一个活过来的副本作为Leader,如果这个副本不在ISR中,那数据的一致性则难以保证。kafka支持用户通过配置选择,以根据业务场景在可用性和数据一致性之间做出权衡。
-
-
消费组leader的选举
组协调器会为消费组(consumer group)内的所有消费者选举出一个leader,这个选举的算法也很简单,第一个加入consumer group的consumer即为leader,如果某一时刻leader消费者退出了消费组,那么会重新 随机 选举一个新的leader。
2.3 kafka中的zookeeper结构
2.3.1 查看方式
我们知道,kafka是基于zookeeper协调管理的,那么zookeeper中究竟存储了哪些信息?另外在后面分析 broker宕机 和 controller宕机 时,我们也需要先了解zookeeper的目录结构,所以我们先学习一下怎么查看zookeeper的目录结构?
① 首先启动zookeeper客户端连接zk服务
# cd /usr/local/zookeeper-cluster/zk1/bin
# ./zkCli.sh
② 查看zk根节点的子目录
[zk: localhost:2181(CONNECTED) 0] ls /
[cluster, controller_epoch, controller, brokers, zookeeper, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, config]
③ 可以看到zk根节点下有很多子目录,以brokers为例,查看brokers的层级结构
[zk: localhost:2181(CONNECTED) 1] ls /brokers
[ids, topics, seqid]
[zk: localhost:2181(CONNECTED) 2] ls /brokers/ids
[0]
[zk: localhost:2181(CONNECTED) 3] get /brokers/ids/0
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://172.17.80.219:9092"],"jmx_port":-1,"host":"172.17.80.219","timestamp":"1584267365984","port":9092,"version":4}
cZxid = 0x300000535
ctime = Sun Mar 15 18:16:06 CST 2020
mZxid = 0x300000535
mtime = Sun Mar 15 18:16:06 CST 2020
pZxid = 0x300000535
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x20191d7053f0009
dataLength = 196
numChildren = 0
[zk: localhost:2181(CONNECTED) 4]
[zk: localhost:2181(CONNECTED) 4]
[zk: localhost:2181(CONNECTED) 4]
[zk: localhost:2181(CONNECTED) 4] ls /brokers/topics
[__consumer_offsets, first]
[zk: localhost:2181(CONNECTED) 5] ls /brokers/topics/first
[partitions]
[zk: localhost:2181(CONNECTED) 6] ls /brokers/topics/first/partitions
[0, 1]
[zk: localhost:2181(CONNECTED) 7] ls /brokers/topics/first/partitions/0
[state]
[zk: localhost:2181(CONNECTED) 8] get /brokers/topics/first/partitions/0/state
{"controller_epoch":21,"leader":0,"version":1,"leader_epoch":8,"isr":[0]}
cZxid = 0x3000003e9
ctime = Sun Mar 08 16:24:37 CST 2020
mZxid = 0x3000005cb
mtime = Sun Mar 15 18:54:09 CST 2020
pZxid = 0x3000003e9
cversion = 0
dataVersion = 10
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 73
numChildren = 0
[zk: localhost:2181(CONNECTED) 9]
可以看到,brokers下包括[ids, topics, seqid],ids里面存储了存活的broker的信息,topics里面存储了kafka集群中topic的信息。同样的方法,可以查看其余节点的结构,这里不再演示。
2.3.2 节点信息(这里只列出和HA相关的部分节点)
① controller
controller节点下存放的是kafka集群中controller的信息(controller即kafka集群中所有broker的leader)。
② controller_epoch
controller_epoch用于记录controller发生变更的次数(controller宕机后会重新选举controller,这时候controller_epoch的值会+1),即记录当前的控制器是第几代控制器,用于防止broker脑裂。
③ brokes
brokers下的ids存储了存活的broker信息,topics存储了kafka集群中topic的信息,其中有一个特殊的topic:_consumer_offsets,新版本的kafka将消费者的offset就存储在__consumer_offsets下。
2.4 broker failover
我们了解了kafka集群中zookpeeper的结构,本文的主题是kafka的高可用分析,所以我们还是结合zookpper的结构,来分析一下,当kafka集群中的一个broker节点宕机时(非controller节点),会发生什么?
在讲之前,我们再来回顾一下brokers的结构
※ 当非controller的broker宕机时,会执行如下操作,
- 1、controller会在zookeeper的 " /brokers/ids/" 节点注册一个watcher(监视器),当有broker宕机时,zookeeper会触发监视器(fire watch)通知controller。
- 2、controller 从 “/brokers/ids” 节点读取到所有可用的broker。
- 3、controller会声明一个set_p集合,该集合包含了宕机broker上所有的partition。
- 4、针对set_p中的每一个partition,
- ① 从 "/state"节点 读取该partition当前的ISR;
- ② 决定该partition的新leader:如果该分区的 ISR中有存活的副本,则选择其中一个作为新leader;如果该partition的ISR副本全部挂了,则选择该partition的 AR集合 中任一幸存的副本作为leader;如果该partition的所有副本都挂,则将分区的leader设为-1;
- ③ 将新 leader、ISR、controller_epoch 和 leader_epoch 等信息写入 state 节点;
- 5、通过RPC向set_p相关的broker发送LeaderAndISR Request命令。
2.5 controller failover
当 controller 宕机时会触发 controller failover。每个 broker 都会在 zookeeper 的 “/controller” 节点注册 watcher(监听器),当 controller 宕机时 zookeeper 中的临时节点消失,所有存活的 broker 收到 fire 的通知,每个 broker 都尝试创建新的临时节点,只有一个会创建成功并当选为 controller。
当新的 controller 当选时,会回调KafkaController的onControllerFailover()方法,在这个方法中完成controller的初始化,controller 在初始化时,首先会利用 ZK 的 watch 机制注册很多不同类型的监听器,主要有以下几种:
- 监听 /admin/reassign_partitions 节点,用于分区副本迁移的监听;
- 监听 /isr_change_notification 节点,用于 Partition Isr 变动的监听;
- 监听 /admin/preferred_replica_election 节点,用于 Partition 最优 leader 选举的监听;
- 监听 /brokers/topics 节点,用于 topic 新建的监听;
- 监听 /brokers/topics/TOPIC_NAME 节点,用于 Topic Partition 扩容的监听;
- 监听 /admin/delete_topics 节点,用于 topic 删除的监听;
- 监听 /brokers/ids 节点,用于 Broker 上下线的监听;
除了注册多种监听器外,controller初始化时还做以下操作,
- initializeControllerContext()
初始化controller上下文,设置当前所有broker、topic、partition的leader、ISR等; - replicaStateMachine.startup()
- partitionStateMachine.startup()
启动状态机; - brokerState.newState(RunningAsController)
将 brokerState 状态设置为 RunningAsController; - sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq)
把partition leadership信息发到所有brokers; - autoRebalanceScheduler.startup()
如果打开了autoLeaderRebalance,则启动"partition-rebalance-thread"线程; - deleteTopicManager.start()
如果delete.topic.enable=true,且 /admin/delete_topics 节点下有值,则删除相应的topic;
上面是onControllerFailover()方法的源码过程。
zk检查哪个broker是当前的controller
#登录zookeeper的bin目录下
cd /usr/local/zookeeper-cluster/zk1/bin
./zkCli.sh
[zk: localhost:2181(CONNECTED) 15] ls /controller
[zk: localhost:2181(CONNECTED) 16] get -s /controller #获取controller信息,brokerid=0为controller
{"version":2,"brokerid":0,"timestamp":"1693406623952","kraftControllerEpoch":-1}
cZxid = 0x20000007b
ctime = Wed Aug 30 22:43:43 CST 2023
mZxid = 0x20000007b
mtime = Wed Aug 30 22:43:43 CST 2023
pZxid = 0x20000007b
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x100001862f00001
dataLength = 80
numChildren = 0
3、kafka集群部署
3.1 部署zk集群
参考伪集群部署与jdk环境部署章节
3.2 部署kafka集群
- 部署前请参考3.1 检查zk集群正常
3.2.1 下载安装包
kafka官网

3.2.2 新建部署文件夹
# 新建一个kafka-cluster目录,将安装包上传到kafka-cluster目录下
# cd /usr/local/
# mkdir kafka-cluster
3.2.3 解压安装包
# cd /usr/local/kafka-cluster
# tar -zxvf kafka_2.12-2.4.0.tgz
# mv kafka_2.12-2.4.0 kafka1
3.3.4 修改配置文件
cd /usr/local/kafka-cluster/kafka1/config/
vi server.properties
#主要配置项
# 集群内不同实例的broker.id必须为不重复的数字
broker.id=0
# listeners配置kafka的host和port【同样使用内网IP】
listeners=PLAINTEXT://localhost:9092 #此处部署伪集群,所以使用的localhost,真实生产需要换成实际机器ip
# kafka数据和log的存放目录
log.dirs=/usr/local/kafka-cluster/kafka1/logs
# zookeeper集群的ip和端口,端口一定要确认对,用英文逗号分隔
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
# 在配置文件中添加如下配置,表示允许删除topic
delete.topic.enable=true
3.3.5 配置kafka2
# 将kafka1拷一份,修改相关配置
cp -r kafka1 kafka2
cd kafka2/config/
vi server.properties
broker.id=1
listeners=PLAINTEXT://localhost:9093
log.dirs=/usr/local/kafka-cluster/kafka2/logs
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
delete.topic.enable=true
3.3.6 配置kafka3
# 将kafka1拷一份,修改相关配置
cp -r kafka1 kafka2
cd kafka2/config/
vi server.properties
broker.id=2
listeners=PLAINTEXT://localhost:9094
log.dirs=/usr/local/kafka-cluster/kafka3/logs
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
delete.topic.enable=true
3.3.7 启动kafka集群
- 可以发现在窗口启动之后是一个阻塞进程,会阻塞当前窗口,我们可以重新打开一个窗口进行接下来的操作,或者在启动kafka的时候使用 -daemon 参数将它声明为守护进程后台运行。
# 启动kafka1,如果不带-daemon参数,关掉这个窗口,kafka1就是停止服务
cd /usr/local/kafka-cluster/kafka1/bin/
./kafka-server-start.sh ../config/server.properties
# 启动kafka1
cd /usr/local/kafka-cluster/kafka1/bin/
./kafka-server-start.sh -daemon ../config/server.properties
#启动kafka2
cd /usr/local/kafka-cluster/kafka2/bin/
./kafka-server-start.sh -daemon ../config/server.properties
#启动kafka3
cd /usr/local/kafka-cluster/kafka3/bin/
./kafka-server-start.sh -daemon ../config/server.properties
- 启动的时候可能会报错"Cannot allocate memory"
这是因为单机上搭建伪集群内存不够导致的,我们可以修改启动脚本,将heap内存改小些,默认为1G,可以改为512M,如果还是不够再修改为256M。
vi bin/kafka-server-start.sh


3.3.8 检查kafka是否启动
1、jps
jps执行会有3个对应的kafka进程
jps -ml 查看具体信息
2、通过查看是否监听kafka 的9092 9093 9094 端口
netstat -antlp | grep ":9092"
3、 lsof
lsof -i :9092 #端口自行修改

4、kafka简单使用(低于2.2版本)
创建一个topic,实现生产者向topic写数据,消费者从topic拿数据。
4.1 创建topic
cd /usr/local/kafka-cluster/kafka1/bin
./kafka-topics.sh --create --zookeeper 172.17.80.219:2181 --replication-factor 2 --partitions 2 --topic first
# 参数解释
# 172.17.80.219:2181 ZK的服务IP:端口号
# --replication-factor 2 分区的副本数为2
# --partitions 2 分区数为2
# --topic first topic的名字是first
# 在创建topic时指定的副本数不能大于可用的集群结点数。创建完成后,我们看一下logs目录,
cd /usr/local/kafka-cluster/kafka1/logs/
# 可以看到,logs下有两个目录:first-0、first-1,这就是我们创建的topic的两个分区(我们定义的分区副本是2,这是分区0和1的其中一个副本)
#再进入kafka2和kafka3的logs目录,
cd /usr/local/kafka-cluster/kafka2/logs/
ll #first-1 kafka2实例的logs下是分区first-1的副本
cd /usr/local/kafka-cluster/kafka3/logs/
ll #first-0 kafka3实例的logs下是分区first-0的副本
# 分区0和1的另外一个副本在kafka2和kafka3节点上。
4.2 查看topic
./kafka-topics.sh --list --zookeeper localhost:2181
![]()
./kafka-topics.sh -zookeeper 172.17.80.219:2181 -describe -topic first
# 结果解释:
# 第1行表示:topic的名字、分区数、每个分区的副本数
# 第2和第3行,每行表示一个分区的信息,以第2行为例,
# Topic: first Partition: 0 Leader: 2 Replicas: 2,0 Isr: 2,0
# 表示topic为first,0号分区,Replicas表示分区的副本分别在broker.id为0和2的机器上, Leader表示分区的leader在broker.id=2的实例上,Isr是在投票选举的时候用的,哪个分区副本的数据和leader数据越接近,这个分区所在的broker.id就越靠前,当leader挂掉时,就取Isr中最靠前的一个broker来顶替leader。
![]()
4.3 发送消息
./kafka-console-producer.sh --broker-list 172.17.80.219:9092 --topic first
#参数解释:172.17.80.219:9092 Kafka服务IP:端口
#说明:我们知道,kafka集群中,只有leader负责读和写,其他flower节点只同步信息,不提供服务,在leader宕机时,flower会顶替leader,继续向外提供服务。我们发送消息的时候,如果指定的结点是flower,flower会将该请求转发到leader。
4.4 另外开窗口启动消费者
./kafka-console-consumer.sh --zookeeper 172.17.80.219:2181 --from-beginning --topic first【0.8版本以前的写法,现在推荐下面那种写法】
./kafka-console-consumer.sh --bootstrap-server 172.17.80.219:9092 --from-beginning --topic first
在生产端输入一些字符,可以在消费端看到已获取到这些字符


说明:新版的kafka消费者在消费的时候,使用的是–bootstrap-server,不再是–zookeeper,这是因为在0.8版本以前,offset维护在zookeeper中,而数据维护在kafka broker中,所以消费者在读取数据的时候先要和zookeeper通信获取到offset,然后再和broker通信去获取数据。但是在0.8版本以后,kafka将offset维护到了kafka的broker中,kafka会自动创建一个topic:"_consumer_offsets"来保存offset的信息,消费者在消费的时候只需要和broker进行一次通信,从而提高了效率。
4.5 删除topic
./kafka-topics.sh --zookeeper localhost:2181 --delete --topic first
5、kafka简单使用(高于2.2版本)
- 本文使用的是3.4.1的版本,所以低于2.2的版本不适用上面的命令。
- kafka版本过高所致,2.2+=的版本,已经不需要依赖zookeeper来查看/创建topic,新版本使用 --bootstrap-server替换老版本的 --zookeeper-server。
- –bootstrap-server kafkahost:9092
5.1 kafka不同脚本介绍
Kafka可执行目录下存在多个脚本控制文件,常用的有topic、producer、consumer、consumer group四种,其他仅做了解即可。
[root@zhy /usr/local/kafka-cluster/kafka1]# cd bin/
[root@zhy /usr/local/kafka-cluster/kafka1/bin]# ll
total 164
-rwxr-xr-x 1 root root 1423 May 26 09:40 connect-distributed.sh
-rwxr-xr-x 1 root root 1396 May 26 09:40 connect-mirror-maker.sh
-rwxr-xr-x 1 root root 1420 May 26 09:40 connect-standalone.sh
-rwxr-xr-x 1 root root 861 May 26 09:40 kafka-acls.sh
-rwxr-xr-x 1 root root 873 May 26 09:40 kafka-broker-api-versions.sh
-rwxr-xr-x 1 root root 860 May 26 09:40 kafka-cluster.sh
-rwxr-xr-x 1 root root 864 May 26 09:40 kafka-configs.sh
-rwxr-xr-x 1 root root 945 May 26 09:40 kafka-console-consumer.sh
-rwxr-xr-x 1 root root 944 May 26 09:40 kafka-console-producer.sh
-rwxr-xr-x 1 root root 871 May 26 09:40 kafka-consumer-groups.sh
-rwxr-xr-x 1 root root 948 May 26 09:40 kafka-consumer-perf-test.sh
-rwxr-xr-x 1 root root 871 May 26 09:40 kafka-delegation-tokens.sh
-rwxr-xr-x 1 root root 869 May 26 09:40 kafka-delete-records.sh
-rwxr-xr-x 1 root root 866 May 26 09:40 kafka-dump-log.sh
-rwxr-xr-x 1 root root 863 May 26 09:40 kafka-features.sh
-rwxr-xr-x 1 root root 865 May 26 09:40 kafka-get-offsets.sh
-rwxr-xr-x 1 root root 870 May 26 09:40 kafka-leader-election.sh
-rwxr-xr-x 1 root root 863 May 26 09:40 kafka-log-dirs.sh
-rwxr-xr-x 1 root root 881 May 26 09:40 kafka-metadata-quorum.sh
-rwxr-xr-x 1 root root 873 May 26 09:40 kafka-metadata-shell.sh
-rwxr-xr-x 1 root root 862 May 26 09:40 kafka-mirror-maker.sh
-rwxr-xr-x 1 root root 959 May 26 09:40 kafka-producer-perf-test.sh
-rwxr-xr-x 1 root root 874 May 26 09:40 kafka-reassign-partitions.sh
-rwxr-xr-x 1 root root 874 May 26 09:40 kafka-replica-verification.sh
-rwxr-xr-x 1 root root 10884 May 26 09:40 kafka-run-class.sh
-rwxr-xr-x 1 root root 1376 May 26 09:40 kafka-server-start.sh
-rwxr-xr-x 1 root root 1361 May 26 09:40 kafka-server-stop.sh
-rwxr-xr-x 1 root root 860 May 26 09:40 kafka-storage.sh
-rwxr-xr-x 1 root root 945 May 26 09:40 kafka-streams-application-reset.sh
-rwxr-xr-x 1 root root 863 May 26 09:40 kafka-topics.sh
-rwxr-xr-x 1 root root 879 May 26 09:40 kafka-transactions.sh
-rwxr-xr-x 1 root root 958 May 26 09:40 kafka-verifiable-consumer.sh
-rwxr-xr-x 1 root root 958 May 26 09:40 kafka-verifiable-producer.sh
-rwxr-xr-x 1 root root 1714 May 26 09:40 trogdor.sh
drwxr-xr-x 2 root root 4096 May 26 09:40 windows
-rwxr-xr-x 1 root root 867 May 26 09:40 zookeeper-security-migration.sh
-rwxr-xr-x 1 root root 1393 May 26 09:40 zookeeper-server-start.sh
-rwxr-xr-x 1 root root 1366 May 26 09:40 zookeeper-server-stop.sh
-rwxr-xr-x 1 root root 1019 May 26 09:40 zookeeper-shell.sh
5.1.1 Topic
[root@zhy bin]# sh kafka-topics.sh --help #help查看其他的,此处只列举常用的
常见参数说明:
- bootstrap-server
- zookeeper
- topic
- create:创建;
- delete:删除;
- alter:修改;
- list:列表查看;
- describe:查看详细信息;
- partitions
- replication-factor :设置副本数;
- config
5.1.2 Producer
获取参数帮助信息方法:
[root@zhy bin]# sh kafka-console-producer.sh --help
常见参数说明:
- bootstrap-server
- bootstrap-server
- producer.config
- zookeeper
- topic
5.1.3 Consumer
获取参数帮助信息方法:
[root@zhy bin]# sh kafka-console-consumer.sh --help
常见参数说明:
- bootstrap-server
- zookeeper
- consumer.config
- topic
- from-beginning:消费历史信息;
- whitelist
- partition
- offset
- max-messages
5.1.4 Consumer group
获取参数帮助信息方法:
[root@zhy bin]# sh kafka-consumer-groups.sh --help
常见参数说明:
- bootstrap-server
- delete:删除消费者组;
- delete-offsets:删除到指定offset;
- describe:查看详细信息;
- execute:立刻执行;
- group
- list:列表查看;
- offsets:指定offset(最新为latest);
- reset-offsets:重置offset到某个时刻;
- to-datetime
- by-duration
- to-earliest:恢复到当前保留的最早offset;
- to-latest:恢复到最新的offset;
- to-offset
- topic
5.2 创建topic
cd /usr/local/kafka-cluster/kafka1/bin
./kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 2 --partitions 2 --topic first
Created topic first. #执行结果
./kafka-topics.sh --bootstrap-server localhost:9092 --list
first #执行结果
./kafka-topics.sh --bootstrap-server localhost:9092 --describe
#执行结果
Topic: first TopicId: 1qoFHvoRTKuLhsa6rGi7Bg PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: first Partition: 0 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: first Partition: 1 Leader: 0 Replicas: 0,2 Isr: 0,2
# 表头介绍:
# Topic:主题名称
# TopicId:主题ID
# PartitionCount:分区总数
# ReplicationFactor:副本数
# Configs:主题配置
# 数据列:主题名称、分区编号、Leader分区在哪个Broker、副本分布在哪个Broker、ISR列表

5.3 发送消息即生产者
说明:
- 新版的kafka消费者在消费的时候,使用的是–bootstrap-server,不再是–zookeeper,这是因为在2.2版本以前,offset维护在zookeeper中,而数据维护在kafka broker中,所以消费者在读取数据的时候先要和zookeeper通信获取到offset,然后再和broker通信去获取数据。但是在2.2 版本以后,kafka将offset维护到了kafka的broker中,kafka会自动创建一个topic:"_consumer_offsets"来保存offset的信息,消费者在消费的时候只需要和broker进行一次通信,从而提高了效率。
#生成数据
./kafka-console-producer.sh --broker-list localhost:9092 --topic first
![]()
5.4 消费数据
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic first

![]()
5.5 Consumer group
# 查看消费者组
[root@master kafka-cluster]# sh kafka1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --list
console-consumer-11605
# 查看详细信息
[root@master kafka-cluster]# sh kafka1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group console-consumer-11605 --describe
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
console-consumer-11605 test001 0 - 0 - console-consumer-401f8ac4-932d-4a18-97ea-45677d9d2f2d /9.134.244.180 console-consumer
console-consumer-11605 test001 1 - 9 - console-consumer-401f8ac4-932d-4a18-97ea-45677d9d2f2d /9.134.244.180 console-consumer
console-consumer-11605 test001 2 - 0 - console-consumer-401f8ac4-932d-4a18-97ea-45677d9d2f2d /9.134.244.180 console-consumer
# 表头介绍:
# GROUP:消费者组的名称
# TOPIC:消费者组订阅的主题名称
# PARTITION:主题的分区编号
# CURRENT-OFFSET:消费者组当前的偏移量(offset),即该分区下一个将要被消费的消息的偏移量
# LOG-END-OFFSET:该分区最新一条消息的偏移量
# LAG:消费者组滞后的消息数量,即当前的偏移量与最新一条消息的偏移量之间的差值
# CONSUMER-ID:消费者客户端的唯一标识符
# HOST:消费者客户端所在的主机名称或 IP 地址
5.6 分区与副本调整
# 准备topic
[root@master kafka_cluster]# sh kafka1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --topic hello_test --partitions 2 --replication-factor 2
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic hello_test.
[root@master kafka_cluster]# ./kafka1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic hello_test --describe
Topic: hello_test TopicId: hQ7vPPgRQF2XEwhRSxO7nA PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: hello_test Partition: 0 Leader: 0 Replicas: 1,0 Isr: 0,1
Topic: hello_test Partition: 1 Leader: 0 Replicas: 0,2 Isr: 0,2
# 编辑需要修改的topic(注意文件内容为json格式)
[root@master kafka-cluster]# vim topic_change.json
{"topics":[{"topic":"hello_test"}],"version":1}
# 使用重新分配分区脚本生成分配计划
[root@master kafka-cluster]# ./kafka1/bin/kafka-reassign-partitions.sh --bootstrap-server 127.0.0.1:9092 --topics-to-move-json-file ./topic_change.json --generate --broker-list "0,1,2"
Current partition replica assignment # 当前分区配置
{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[1,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":1,"replicas":[0,2],"log_dirs":["any","any"]}]}
Proposed partition reassignment configuration # 推荐的分区配置
{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":1,"replicas":[2,0],"log_dirs":["any","any"]}]}
# 将推荐的分配计划保存在本地新文件内
[root@master kafka-cluster]# vim replication-factor.json
{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":1,"replicas":[2,0],"log_dirs":["any","any"]}]}
# 使用重新分配分区脚本执行分配计划
[root@master kafka-cluster]# ./kafka1/bin/kafka-reassign-partitions.sh --bootstrap-server 127.0.0.1:9092 --reassignment-json-file ./replication-factor.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[1,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":1,"replicas":[0,2],"log_dirs":["any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for hello_test-0,hello_test-1 # 成功启动分区标识
# 验证分配计划是否执行成功
[root@master kafka_cluster]# ./kafka-1/bin/kafka-reassign-partitions.sh --bootstrap-server 127.0.0.1:9092 --reassignment-json-file ./replication-factor.json --verify
Status of partition reassignment:
Reassignment of partition hello_test-0 is completed. # 重新分配分区完成标识
Reassignment of partition hello_test-1 is completed.
Clearing broker-level throttles on brokers 0,1,2
Clearing topic-level throttles on topic hello_test
# 查看topic详情
[root@master kafka_cluster]# ./kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic hello_test --describe
Topic: hello_test TopicId: hQ7vPPgRQF2XEwhRSxO7nA PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: hello_test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: hello_test Partition: 1 Leader: 0 Replicas: 2,0 Isr: 0,2
5.6.1 分区扩容
[root@master kafka-cluster]# ./kafka1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic hello_test --describe
Topic: hello_test TopicId: hQ7vPPgRQF2XEwhRSxO7nA PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: hello_test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: hello_test Partition: 1 Leader: 0 Replicas: 2,0 Isr: 0,2
# 使用topic脚本可以直接扩容分区,但不支持缩容(缩容需要使用分配计划修改)
[root@master kafka-cluster]# ./kafka1/bin/kafka-topics.sh --alter --bootstrap-server 127.0.0.1:9092 --topic hello_test --partitions 8
[root@master kafka-cluster]# ./kafka1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic hello_test --describe
Topic: hello_test TopicId: hQ7vPPgRQF2XEwhRSxO7nA PartitionCount: 8 ReplicationFactor: 2 Configs:
Topic: hello_test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: hello_test Partition: 1 Leader: 0 Replicas: 2,0 Isr: 0,2
Topic: hello_test Partition: 2 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: hello_test Partition: 3 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: hello_test Partition: 4 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: hello_test Partition: 5 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: hello_test Partition: 6 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: hello_test Partition: 7 Leader: 2 Replicas: 2,1 Isr: 2,1
5.6.2 副本扩容
# 生成分配计划
[root@master kafka-cluster]# ./kafka-1/bin/kafka-reassign-partitions.sh --bootstrap-server 127.0.0.1:9092 --topics-to-move-json-file ./topic_change.json --generate --broker-list "1,2"
Current partition replica assignment
{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":1,"replicas":[2,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":2,"replicas":[0,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":3,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":4,"replicas":[2,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":5,"replicas":[0,1],"log_dirs":["any","any"]},{"topic":"hello_test","partition":6,"replicas":[1,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":7,"replicas":[2,1],"log_dirs":["any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[2,1],"log_dirs":["any","any"]},{"topic":"hello_test","partition":1,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":2,"replicas":[2,1],"log_dirs":["any","any"]},{"topic":"hello_test","partition":3,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":4,"replicas":[2,1],"log_dirs":["any","any"]},{"topic":"hello_test","partition":5,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":6,"replicas":[2,1],"log_dirs":["any","any"]},{"topic":"hello_test","partition":7,"replicas":[1,2],"log_dirs":["any","any"]}]}
# 保存分配计划
[root@master kafka-cluster]# vim replication-factor.json #这里的文件可以通过jq工具先解析,然后将副本0 和对应的log_dirs都输入一份,然后再执行扩容计划
{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"topic":"hello_test","partition":1,"replicas":[1,2,0],"log_dirs":["any","any","any"]},{"topic":"hello_test","partition":2,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"topic":"hello_test","partition":3,"replicas":[1,2,0],"log_dirs":["any","any","any"]},{"topic":"hello_test","partition":4,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"topic":"hello_test","partition":5,"replicas":[1,2,0],"log_dirs":["any","any","any"]},{"topic":"hello_test","partition":6,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"topic":"hello_test","partition":7,"replicas":[1,2,0],"log_dirs":["any","any","any"]}]}
# 立即执行
[root@master kafka-cluster]# ./kafka-1/bin/kafka-reassign-partitions.sh --bootstrap-server 127.0.0.1:9092 --reassignment-json-file ./replication-factor.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":1,"replicas":[2,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":2,"replicas":[0,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":3,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":4,"replicas":[2,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":5,"replicas":[0,1],"log_dirs":["any","any"]},{"topic":"hello_test","partition":6,"replicas":[1,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":7,"replicas":[2,1],"log_dirs":["any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for hello_test-0,hello_test-1,hello_test-2,hello_test-3,hello_test-4,hello_test-5,hello_test-6,hello_test-7
# 验证结果
[root@master kafka-cluster]# ./kafka-1/bin/kafka-reassign-partitions.sh --bootstrap-server 127.0.0.1:9092 --reassignment-json-file ./replication-factor.json --verify
Status of partition reassignment:
Reassignment of partition hello_test-0 is completed.
Reassignment of partition hello_test-1 is completed.
Reassignment of partition hello_test-2 is completed.
Reassignment of partition hello_test-3 is completed.
Reassignment of partition hello_test-4 is completed.
Reassignment of partition hello_test-5 is completed.
Reassignment of partition hello_test-6 is completed.
Reassignment of partition hello_test-7 is completed.
Clearing broker-level throttles on brokers 0,1,2
Clearing topic-level throttles on topic hello_test
# 查看详情
[root@master kafka-cluster]# ./kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic hello_test --describe
Topic: hello_test TopicId: hQ7vPPgRQF2XEwhRSxO7nA PartitionCount: 8 ReplicationFactor: 3 Configs: Topic: hello_test Partition: 0 Leader: 1 Replicas: 2,1,0 Isr: 1,2,0 Topic: hello_test Partition: 1 Leader: 0 Replicas: 1,2,0 Isr: 0,2,1
Topic: hello_test Partition: 2 Leader: 0 Replicas: 2,1,0 Isr: 0,2,1
Topic: hello_test Partition: 3 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: hello_test Partition: 4 Leader: 2 Replicas: 2,1,0 Isr: 2,0,1
Topic: hello_test Partition: 5 Leader: 0 Replicas: 1,2,0 Isr: 0,1,2
Topic: hello_test Partition: 6 Leader: 1 Replicas: 2,1,0 Isr: 1,0,2
Topic: hello_test Partition: 7 Leader: 2 Replicas: 1,2,0 Isr: 2,1,0
jq工具使用参考
5.6.3 缩容
5.7 消息积压清理
使用Kafka自带的测试工具进行测试。
# 创建一个测试topic
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --topic test --partitions 5 --replication-factor 2
Created topic test.
# 生产者
[root@master kafka_cluster]# sh kafka-1/bin/kafka-producer-perf-test.sh --topic test --num-records=100000000 --producer-props bootstrap.servers=127.0.0.1:9092 batch.size=10000 --throughput -1 --record-size 100
1502928 records sent, 300585.6 records/sec (28.67 MB/sec), 566.8 ms avg latency, 1350.0 ms max latency.
~
100000000 records sent, 555632.726768 records/sec (52.99 MB/sec), 538.13 ms avg latency, 3616.00 ms max latency, 489 ms 50th, 824 ms 95th, 1240 ms 99th, 3300 ms 99.9th. # 传输完成标识,展示了每秒发送的消息数、吞吐量、平均延时,以及几个分位数,重点关注末尾的分位数,3300 ms 99.9th表示99.9%的消息延时都在3300 ms之内
# --num-records=100000000:将要发送的消息数量
# batch.size=10000:批处理大小
# --throughput -1:设置生产者的期望吞吐量。"-1"表示生产者将尽可能快地发送消息
# --record-size 100:每条消息的大小为100字节
# 消费者
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-perf-test.sh --topic test --broker-list 127.0.0.1:9092 --messages=100000000 --num-fetch-threads 1 --fetch-size=1000
WARNING: option [threads] and [num-fetch-threads] have been deprecated and will be ignored by the test
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2023-08-30 19:33:27:781, 2023-08-30 19:36:27:457, 9536.7437, 53.0774, 100000014, 556557.4367, 351, 179325, 53.1813, 557646.8089 # 完成标识
# --messages=100000000:指定测试消息的总数
# --num-fetch-threads 1:指定拉取消息的线程数为1个
# --fetch-size=1000:指定每次拉取消息的大小为1000字节
# 查看消息积压
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --list
perf-consumer-63840
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --describe --group perf-consumer-99520
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
perf-consumer-99520 test 0 3596220 4426920 830700 perf-consumer-client-f7810e67-2129-44e4-aabd-1f1789119c04 /9.134.244.180 perf-consumer-client
perf-consumer-99520 test 1 3104236 4129066 1024830 perf-consumer-client-f7810e67-2129-44e4-aabd-1f1789119c04 /9.134.244.180 perf-consumer-client
perf-consumer-99520 test 4 3104522 4129172 1024650 perf-consumer-client-f7810e67-2129-44e4-aabd-1f1789119c04 /9.134.244.180 perf-consumer-client
perf-consumer-99520 test 3 3596115 4426905 830790 perf-consumer-client-f7810e67-2129-44e4-aabd-1f1789119c04 /9.134.244.180 perf-consumer-client
perf-consumer-99520 test 2 5437555 5465005 27450 perf-consumer-client-f7810e67-2129-44e4-aabd-1f1789119c04 /9.134.244.180 perf-consumer-client
# LAG越大积压越多
# 恢复到最新的offset,LAG = 0,未消费的数据将直接被放弃消费,从最新offset继续开始进行消费
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group perf-consumer-99520 --reset-offsets --topic test --to-latest --execute
GROUP TOPIC PARTITION NEW-OFFSET
perf-consumer-99520 test 0 25377165
perf-consumer-99520 test 1 27216340
perf-consumer-99520 test 4 27214992
perf-consumer-99520 test 3 25377341
perf-consumer-99520 test 2 32609516
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --describe --group perf-consumer-99520
Consumer group 'perf-consumer-99520' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
perf-consumer-99520 test 0 25377165 25377165 0 - - -
perf-consumer-99520 test 1 27216340 27216340 0 - - -
perf-consumer-99520 test 4 27214992 27214992 0 - - -
perf-consumer-99520 test 3 25377341 25377341 0 - - -
perf-consumer-99520 test 2 32609516 32609516 0 - - -
5.8 重新选举leader主分区
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --describe --topic test
Topic: test TopicId: 2_bqk7HcTzWIDNAqkNondQ PartitionCount: 5 ReplicationFactor: 2 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: test Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: test Partition: 2 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: test Partition: 3 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: test Partition: 4 Leader: 0 Replicas: 0,2 Isr: 0,2
# 指定topic与partition
[root@master kafka_cluster]# sh kafka-1/bin/kafka-leader-election.sh --bootstrap-server 127.0.0.1:9092 --topic test --partition 1 --election-type preferred
Valid replica already elected for partitions test-1
# "preferred"或者"unclean"分别表示优先选举副本、或者允许选举副本状态不一致的节点作为Leader
# 使用json文件
[root@master kafka_cluster]# cat replica-election.json
{"partitions": [{"topic": "test","partition": 0},{"topic": "test001","partition": 1}]}
[root@master kafka_cluster]# sh kafka-1/bin/kafka-leader-election.sh --bootstrap-server 127.0.0.1:9092 --path-to-json-file ./replica-election.json --election-type UNCLEAN
Valid replica already elected for partitions test-1, test-0
5.9 删除topic
./kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic first
./kafka-topics.sh --bootstrap-server localhost:9092 --list #删除后列出