SpringBoot 搜索引擎 海量数据 Elasticsearch-7 es上手指南 毫秒级查询 包括 版本选型、操作内容、结果截图
0.开篇废话
0.1技术选型
选择 Elasticsearch-7.1.12
0.2选型背景
由于 选型的SpringCloud版本的优先级要高 所以在确定SpringCloud的版本之后
以此确定了 SpringBoot 版本、相关组件版本、Elasticsearch版本、spring-data-elasticsearch版本
0.3版本关系
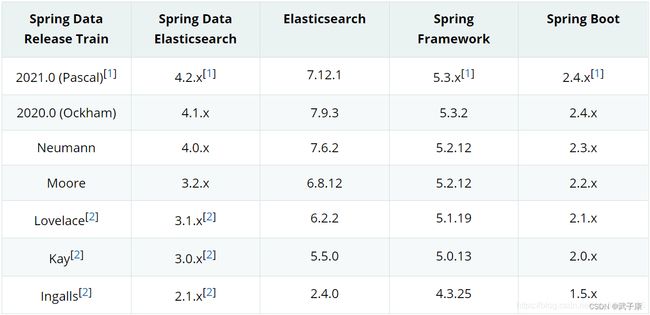
由于生产环境要求稳定 所以并没有采用最新的版本
如果你有新版本的需要 可以根据如下链接进行查找
- Spring版本选择 Spring官方
- SpringBoot版本选择 SpringBoot版本
- SpringDataElasticsearch版本选择 spring-data-elasticsearch版本
- SpringCloud版本选择 SpringCloud版本
- Maven包的POM maven包
对于当前的学习环境 采用Docker的环境搭建 减少安装的问题 避免挫败学习兴趣
0.4前置要求
- (废话) 一台Win 或 Mac 或 基Linux机器
- (强制) Java基础
- (强制) Docker
- (强制) SpringBoot基础
- (强制) 简单的shell
- (建议) Postman Postman官方地址
- (建议) SpringData基础
- (建议) 科学上网
1.安装软件
1.1 拉取镜像
docker pull elasticsearch:7.12.1
1.2 启动容器
docker run --name elasticsearch -d -e ES_JAVA_OPTS="-Xms512m -Xms512m" -e "discovery.type=single-node" -p 9200:9200 elastics
earch:7.12.1
1.3 跨域访问
配置跨域
docker exec -it elasticsearch /bin/bash
vi config/elasticsearch.yml
修改当中内容为
cluster.name: "docker-cluster"
network.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"
根据提示退出保存
1.4 重启容器
docker restart elasticsearch
1.5 访问测试
浏览器访问
http://127.0.0.1:9200
2.辅助软件
安装 head
2.1 拉取镜像
docker pull mobz/elasticsearch-head:5
2.2 启动容器
docker run --name elasticsearch-head -d -p 9100:9100 mobz/elasticsearch-head:5
2.3 访问测试
浏览器访问
http://127.0.0.1:9100
3.牛刀小试
尝试向 Elasticsearch 中 写入、读取数据
打开 Postman
3.1 写入数据
可以换不同的内容 多写入几条 方便后边的条件查询
http://127.0.0.1:9200/student/_doc/7
{
"id": 7,
"name": "wzk",
"age": "14"
}
3.2 读取数据
http://127.0.0.1:9200/student/_search
{
"query": {
"match": {
"name": "wzk"
}
}
}
4.众寻百度
本章主要是 查询、各种检索方式、检索条件、排序、分页等等
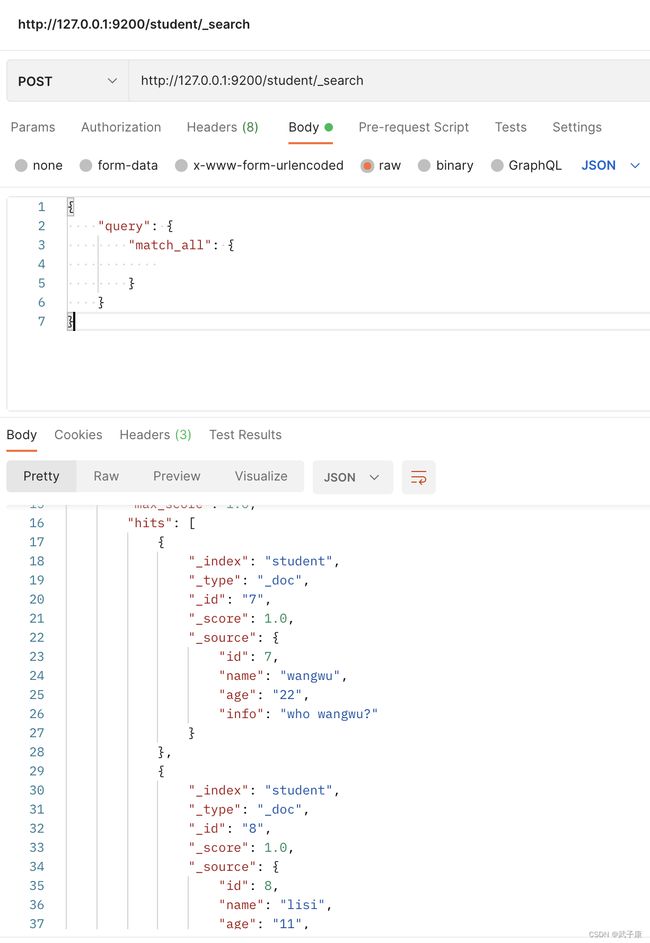
4.1 查询所有
http://127.0.0.1:9200/student/_search
{
"query": {
"match_all": {
}
}
}
4.2 全文检索
分词后进行检索
http://127.0.0.1:9200/student/_search
{
"query": {
"match": {
"info": "oohohohoh"
}
}
}
4.3 短语检索
搜索条件不做任何分词
http://127.0.0.1:9200/student/_search
{
"query": {
"match_phrase": {
"info": "is"
}
}
}
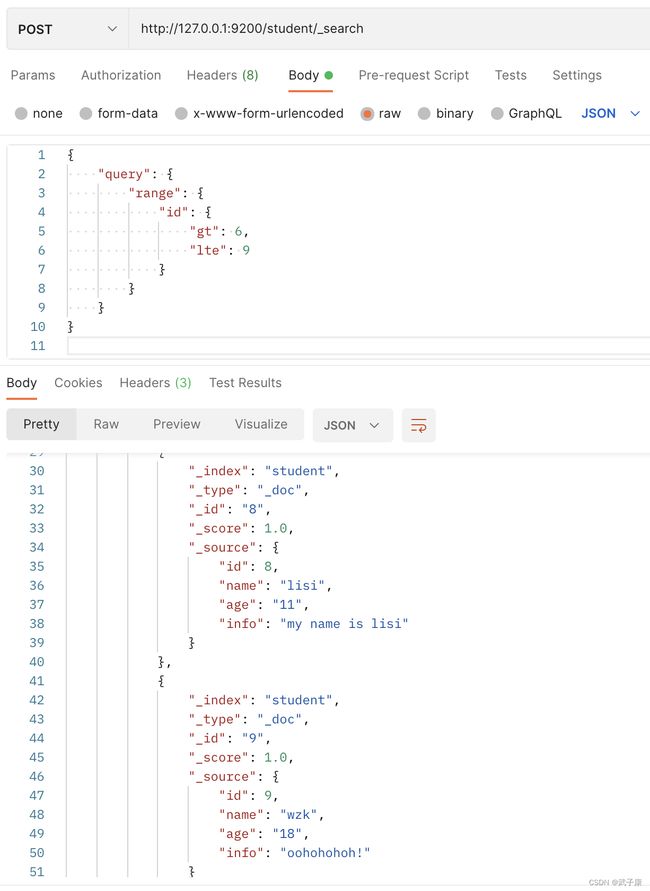
4.4 范围搜索
对数字类型的字段进行范围搜索
- gt: greater than 大于
- gte: greater than or equal 大于等于
- lt: less than 小于
- lte: less than or equal 小于等于
http://127.0.0.1:9200/student/_search
{
"query": {
"range": {
"id": {
"gt": 6,
"lte": 9
}
}
}
}
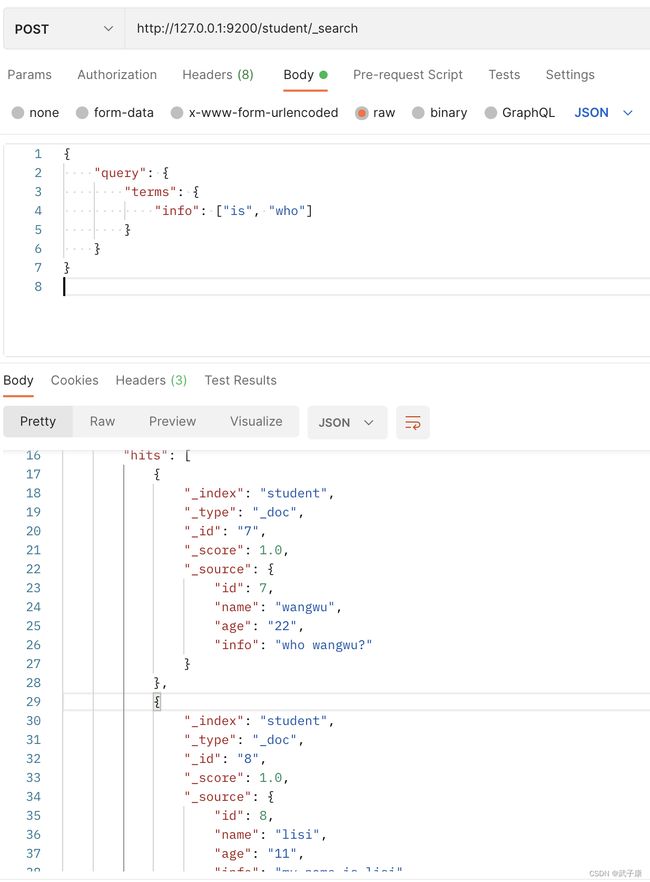
4.5 词组搜索
单词/词组搜索 搜搜条件不做任何分词解析 在搜索字段对应的倒排索引中精确匹配
http://127.0.0.1:9200/student/_search
{
"query": {
"terms": {
"info": ["is", "who"]
}
}
}
4.6 模糊搜索
在搜索时可能会出现错误 Elasticsearch 会自动纠错 进行模糊匹配
- query: 搜索条件
- fuzziness: 最多错误字符数 不能超过2
http://127.0.0.1:9200/student/_search
{
"query": {
"match": {
"info": {
"query": "liyi",
"fuzziness": 1
}
}
}
}
4.7 复合搜索
多个条件结合 搜索符合的结果
- must 必须满足的条件
- should 多个条件任意满足一个
- must_not 必须不满足的条件
http://127.0.0.1:9200/student/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"info": "my"
}
},
{
"match_phrase": {
"info": "name"
}
}
],
"should": [
{
"match_phrase": {
"info": "name"
}
}
],
"must_not": [
{
"match_phrase": {
"info": "wzk"
}
}
]
}
}
}
4.8 结果排序
对查询到的结果进行排序
由于elasticsearch对text类型字段数据会做分词处理
所以无论使用那个单词排序都是不合理的 所以默认不允许对text类型进行排序
如果要使用字符串结果排序
可以使用keyword类型的字段作为排序依据 因为keyword字段不做分词处理
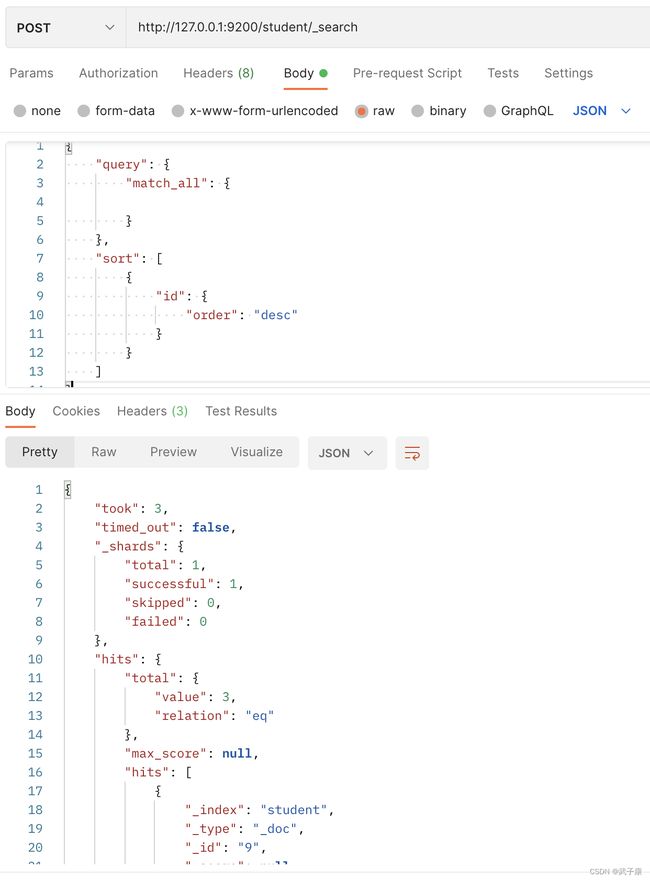
http://127.0.0.1:9200/student/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"id": {
"order": "desc"
}
}
]
}
4.9 分页查询
实际线上使用过程中 符合的结果可能很多
所以必须要对结果进行分页 提升效率
http://127.0.0.1:9200/student/_search
{
"query": {
"match_all": {
}
},
"from": 0,
"size": 2
}
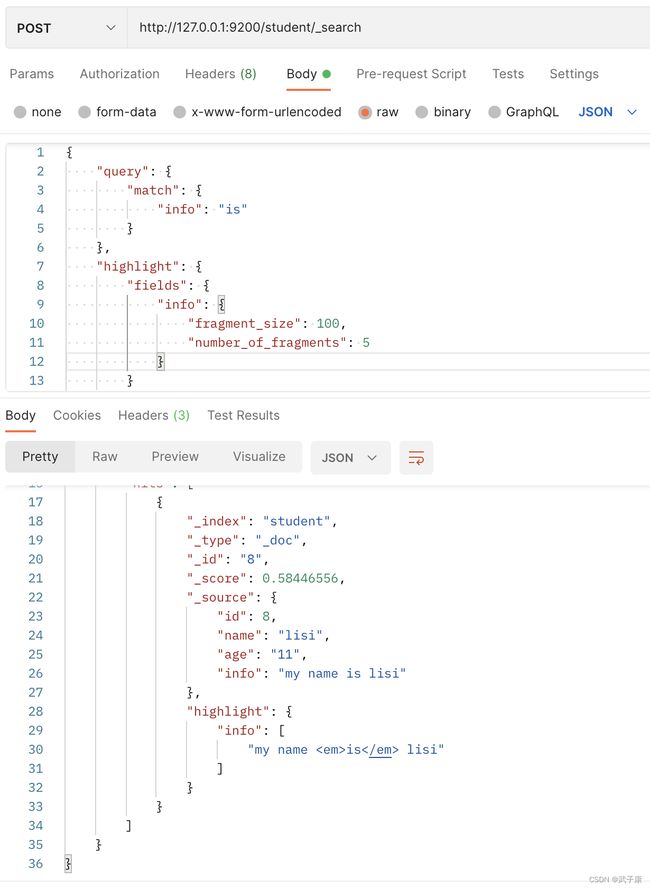
4.10 高亮查询
http://127.0.0.1:9200/student/_search
{
"query": {
"match": {
"info": "is"
}
},
"highlight": {
"fields": {
"info": {
"fragment_size": 100,
"number_of_fragments": 5
}
}
}
}
5.衣带渐宽
搭建项目 在 SpringBoot 项目中使用 Elasticsearch
采用的方案是 SpringData 上手比较简单 (对我来说 但可能不是很自由 学习足够了)
假设你已经有SpringBoot的基础啦!
下面我就快刀斩乱麻 起一个项目 (随手parent为2.2.2.RELEASE)
5.1 搭建项目
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.2.RELEASE</version>
</parent>
<dependencies>
<!-- spring-boot-web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- elasticsearch -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
<scope>provided</scope>
</dependency>
</dependencies>
5.2 基础配置
项目中新建 config 目录
新建配置类 (不要忘记 @Configuration)
@Configuration
public class ElasticSearchConfig extends AbstractElasticsearchConfiguration {
@Override
public RestHighLevelClient elasticsearchClient() {
ClientConfiguration clientConfiguration = ClientConfiguration
.builder()
.connectedTo("127.0.0.1:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}
5.3 实体类
- @Document(indexName = “student”) 索引名称是student 如果不存在则会自动创建
- @Id 为索引
- @Field(type = FieldType.Text, store = true) 字段
结构和elasticsearch你存储的对象的字段可以对应
新建model文件夹
新建Student对象
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Document(indexName = "student")
public class Student {
@Id
private Integer id;
@Field(type = FieldType.Text, store = true)
private String name;
@Field(type = FieldType.Text, store = true)
private String info;
@Field(type = FieldType.Text, store = true)
private String age;
@Field(type = FieldType.Text, store = true)
private String links;
}
5.4 创建接口
ElasticsearchRepository是基础类 继承后 有很多现成的方法
新建 dao 文件夹
新建 StudentRepository 类
public interface StudentRepository extends ElasticsearchRepository<Student, Integer> {
}
5.5 新增数据
这里为了省事 直接将逻辑放到了 Controller 上
将 StudentRepository 注入进来
SpringData 帮忙提供了很多现成的方法
@Autowired
private StudentRepository studentRepository;
@GetMapping("/addStudent")
public String addStudent() {
String name = UUID.randomUUID().toString();
name = name.replace("-", " ");
Student student = Student
.builder()
.name(name)
.links("this is a link to " + name)
.build();
studentRepository.save(student);
return "ok";
}
5.6 查询数据
将 StudentRepository 注入进来
@Autowired
private StudentRepository studentRepository;
@GetMapping("/getStudent")
public List<Student> getStudent() {
Iterable<Student> dataList = studentRepository.findAll();
List<Student> resultList = new ArrayList<>();
for (Student student : dataList) {
resultList.add(student);
}
return resultList;
}
5.7 查询单条
将 StudentRepository 注入进来
@Autowired
private StudentRepository studentRepository;
@GetMapping("/getStudentById")
public Student getStudentById() {
Optional<Student> stuData = studentRepository.findById(11);
return stuData.orElseGet(Student::new);
}
5.8 修改数据
将 StudentRepository 注入进来
@Autowired
private StudentRepository studentRepository;
@GetMapping("/updStudent")
public String updStudent() {
String name = UUID.randomUUID().toString();
name = name.replace("-", " ");
Student student = Student
.builder()
.id(1)
.name(name)
.links("this is a link to " + name)
.build();
studentRepository.save(student);
return "ok";
}
5.9 删除数据
将 StudentRepository 注入进来
@Autowired
private StudentRepository studentRepository;
@GetMapping("/delStudent")
public String delStudent() {
studentRepository.deleteById(1);
return "ok";
}
6.灯火阑珊
第5章 我们发现 虽然SpringData帮我们提供了很多方法(通过继承的方式)
但是不够自由 当查询时条件复杂就不可以使用了
所以官方也提供了对应的解决方案
6.1 自定方法
先附上一篇 官方的对应关系
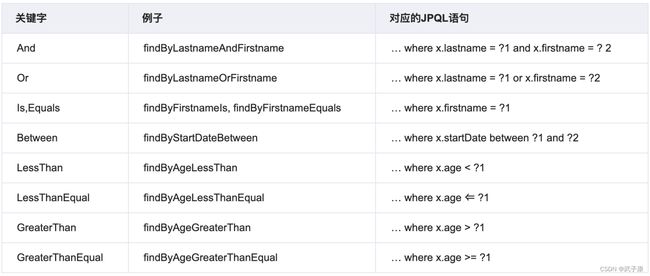

举例 根据上述规则使用一下
// 根据名字查询
List<Student> findByName(String name);
// 根据名字模糊查询
List<Student> findByNameLike(String name);
6.2 条件分页
Pageable pageable = PageRequest.of(0, 2); 即可实现分页查询
@Autowired
private StudentRepository studentRepository;
@GetMapping("/getPage")
public List<Student> getPage() {
Pageable pageable = PageRequest.of(0, 2);
Page<Student> page = studentRepository.findAll(pageable);
List<Student> dataList = page.getContent();
long number = page.getTotalElements();
int total = page.getTotalPages();
out.println("number: " + number);
out.println("total: "+ total);
return dataList;
}
6.3 自定分页
6.2 中使用了 Pageable 分页
我们也可以利用 6.1中的方式进行分页
在 StudentRepository 中 加入方法
// 注意 Pageable page
// 这样逻辑大约变成了(方便理解 用SQL表达一下):
// select * from student where name=#{name} limit #{page.page, page.size}
Page<Student> findByNameLike(String name, Pageable page);
@Autowired
private StudentRepository studentRepository;
@GetMapping("/findByNamePage")
public List<Student> findByNamePage() {
Pageable pageable = PageRequest.of(0, 1);
// 传参 将 条件、分页 一起传入
Page<Student> data = studentRepository.findByNameLike("2", pageable);
System.out.println(data.getTotalElements());
System.out.println(data.getTotalPages());
return data.getContent();
}
6.4 查询排序
查询时 进行排序
Sort sort = Sort.by(Sort.Direction.DESC, “id”);
@Autowired
private StudentRepository studentRepository;
@GetMapping("/findByNameOrder")
public List<Student> findByNameOrder() {
// 排序顺序、排序字段
Sort sort = Sort.by(Sort.Direction.DESC, "id");
Iterable<Student> dataList = studentRepository.findAll(sort);
List<Student> resultList = new ArrayList<>();
for (Student student : dataList) {
resultList.add(student);
}
return resultList;
}
6.5 排序分页
Pageable 中加入了 Sort 所以可以分页、排序
@Autowired
private StudentRepository studentRepository;
@GetMapping("/findByNamePageOrder")
public List<Student> findByNamePageOrder() {
Sort sort = Sort.by(Sort.Direction.ASC, "id");
// 传参 start、limit、sort规则
// 即可实现 分页 + 排序
Pageable pageable = PageRequest.of(0,2, sort);
Page<Student> page = studentRepository.findAll(pageable);
return page.getContent();
}