更小的模型!迈向更快更环保的NLP
作者 | Manuel Tonneau
整理 | NewBeeNLP
越大的模型总是越好吗 
写在前面
长期以来,在屠虐各大排行榜的驱动下,NLP players对此问题的答案似乎是肯定的。从Google于2018年10月发布「BERT」(base版本为1.1亿个参数)到Salesforce于2019年9月发布的「CTRL」(16.3亿个参数),直到微软最近发布的「T-NLG」(170亿个参数),语言模型规模的增长似乎势不可挡。
相反地,NLP社区中也存在推动较小模型发展的趋势,其中的参与者如Hugging Face于2019年10月发布了「DistilBERT」(参数为0.66亿),Google于2019年9月发布的「ALBERT」。这不禁让我们思考,这种"David over Goliath"现象的动机是什么?
第一个主要的答案是「成本」。训练这些怪兽可能要花费数万美元,尽管大型科技公司能负担得起,而小型公司则相反。在当前对气候变化的意识提高的前提下,训练导致的环境成本也是不可忽略的。
第二个同样非常关键的原因是「速度」,谁想要在Google搜索时等待几秒钟?增加模型大小可能会导致更好的性能,但也会使模型变慢,从而引起用户的极大不满。
在这篇博客文章中,我们会讨论研究小模型的新趋势,并详细介绍了其中的三个
「DistilBERT from HuggingFace」
「PD-BERT from Google」
「BERT-of-Theseus from Microsoft Asia」
彩票假说
语言模型的参数数量之所以增长的原因是,更多的参数将包含更多的信息,这也将导致更好的模型性能。从这方面考虑,有些人可能会担心,通过从训练完好的模型中随意删除参数来达到压缩模型的效果会严重损害其性能。换句话说:对于模型预测效果而言,某些参数是否比其他参数重要?
答案是肯定的,MIT的Jonathan Frankle和Michael Carbin在2018年发表了一篇有趣的论文,The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks[1],将其概念化为「彩票假设」:在神经网络初始化期间,为网络的参数初始化值时,将随机定义模型参数。
在这个幸运大转盘中,网络的某些部分初始化的值比其他部分更"幸运"。带有幸运票的子网络具有的初始化值使它们可以更有效地进行训练,即达到最佳参数值,与网络的其余部分相比,这些参数值将在更少的时间内产生良好的结果。该论文表明,甚至可以使用相同的初始化值将这些子网络与网络的其余部分分开训练,并且在获得更少参数的同时仍可以达到相似的精度。
模型压缩实践
现在我们知道压缩模型是有道理的,那么在实践中我们该如何做呢?主要有三种常用方法可以做到这一点。
第一个称为「量化(quantization)」,其目的是降低参数精度。举个例子,当被问及柏林的温度是多少时,你可以说10摄氏度,但这并不完全准确,但为了易于使用,我们将数值取整了。对于神经网络而言,减少小数位数有助于降低计算和内存需求。
第二种方法称为「修剪(pruning )」,旨在删除模型的一部分。例如,它可以用于删除连接或神经元。
第三种方法称为「知识蒸馏(knowledge distillation )」,它意味着使用现有的预训练模型(教师模型)来训练较小的模型(学生模型)来模仿教师模型。在这种情况下,模型不会被压缩,但是要获得更小,更快的模型的目标是相同的。有关这些方法的更多信息,可以参考阅读Rasa一篇非常详尽的博客文章,Compressing BERT for faster prediction[2]。
接下来,我们关注于三个上文提及的模型,以举例说明压缩模型在实践中如何应用。
DistilBERT
「论文」:DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter[3]
「代码」:https://github.com/huggingface/transformers
在过去的几个月中,知识蒸馏受到了极大关注,特别是在Hugging Face于2019年10月发布了DistilBERT模型之后。作者将知识蒸馏应用于Google开发的著名BERT模型, DistilBERT的架构类似于原始的BERT基本架构,由12个Transformer编码器构成,但参数减少了40%。
原始的BERT模型经过了两项任务的预训练:Masked Language Model(MLM),即遮掩句子中的单词并要求模型对其进行预测;以及Next Sentence Prediction(NSP),对于两个句子A和B,预测句子B是否在句子A之后。
对于MLM,我们强制模型为实际掩盖的单词以及所有其他单词分配接近真实值的单词概率。实际上,我们最小化以下MLM损失函数:
如果我们只考虑MLM损失,那么我们基本上只会训练一个较小的学生模型,但在教师模型和学生模型之间不会有任何学习。因此,除了MLM损失外,作者还添加了具有此目的的「distillation loss」。掩盖单词时,它会迫使学生模型模仿教师模型的输出概率分布,那么具体是怎么做呢?
其中, 表示由教师模型 得到的masked token为词表中第 个单词的概率; 表示由学生模型 得到的masked token为词表中第 个单词的概率;
这样,通过最小化这种损失,学生模型的概率分布将趋向于来自老师的模型。最后的训练目标是MLM loss和distillation loss的线性组合。
关于训练数据的选择,DistilBERT是在BERT基础训练集中的子集上进行训练的。然而,谷歌最近发表的一篇论文表明,即使教师给出无意义的句子(随机单词列表)进行训练也足以使学生获得良好的表现,因为教师模型通过其输出概率分布所提供的信息足够强大。例如,如果训练句子是“love trash guitar”,而被掩盖的单词是“trash”,则训练后的模型可能会预测“playing”,而不是“trash”,这是学生模型将学习的合理预测结果。需要注意,这仅适用于蒸馏损失,而不适用于MLM损失,因为对于后者,这等同于训练模型使其无意义。
PD-BERT
「论文」:Well-Read Students Learn Better: On the Importance of Pre-training Compact Models[4]
「代码」:https://github.com/google-research/bert
DistilBERT很好地说明知识蒸馏可以帮助构建性能令人满意的小模型。但是,这是否意味着废弃BERT之类良好的旧式预训练模式?并不,根据谷歌最近的一篇论文,直接对小模型进行预训练而无需从较大模型进行初始化会带来较好的效果,并显著提高速度。
作者称之为 pre-trained distillation(PD)的新方法过程如下。像大模型一样,对BERT模型的小版本进行随机初始化和训练,并使用上述的MLM方法。然后,作者以与DistilBERT相同的方式应用知识蒸馏,以帮助较小的模型向较大的模型学习。最后可以根据标记的数据集对生成的学生模型进行微调,从而使其专注于特定任务(例如情感分析)。本文的价值还在于,比较了不同的方法(使用和不使用蒸馏的预训练和微调)。作者表明,虽然较小模型的经典预训练和微调已经比DistilBERT产生了更好的结果,但在预训练和微调之间添加蒸馏有助于达到更好的结果。
学生模型未使用教师部分初始化的原因是使模型大小具有更大的灵活性。作者总共发布了4个模型,所有模型均小于BERT基准。其中最小的模型,即BERT Tiny,仅有440万个参数,比DistilBERT小15倍,比BERT-base小25倍。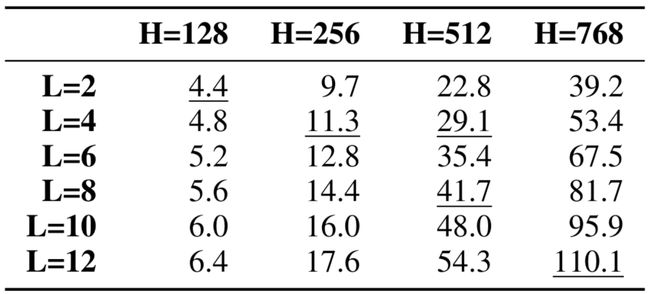 与诸如BERT Large之类的大型体系结构相比,这可以将训练时间加速多达65倍,并且我们可以想象到,尽管作者没有提及,推理速度也会优化很多。
与诸如BERT Large之类的大型体系结构相比,这可以将训练时间加速多达65倍,并且我们可以想象到,尽管作者没有提及,推理速度也会优化很多。
BERT-of-Theseus
「论文」:BERT-of-Theseus: Compressing BERT by Progressive Module Replacing[5]
「代码」:https://github.com/JetRunner/BERT-of-Theseus
如果不是让学生模型在老师模型学习之后进行模仿,而是让学生和老师同时学习,并且让学生逐步取代老师,会怎么样?这是微软亚研院于2020年2月发布的最新模型BERT-of-Theseus的设想。 研究者受到著名哲学思想实验「忒修斯之船」的启发:如果船上的木头逐渐被替换,直到所有的木头都不是原来的木头,那这艘船还是原来的那艘船吗?
研究者受到著名哲学思想实验「忒修斯之船」的启发:如果船上的木头逐渐被替换,直到所有的木头都不是原来的木头,那这艘船还是原来的那艘船吗?
该方法逐步将 BERT 的原始模块替换成参数更少的替代模块。研究者将原始模型叫做「前辈」(predecessor),将压缩后的模型叫做「接替者」(successor),分别对应 KD 中的教师和学生。工作流程如下图所示:首先为每个前辈模块(即前辈模型中的模块)指定一个替代(接替者)模块;然后在训练阶段中以一定概率用替代模块随机替换对应的前辈模块,并按照新旧模块组合的方式继续训练;模型收敛后,将所有接替者模块组合成接替者模型,进而执行推断。这样,就可以将大型前辈模型压缩成紧凑的接替者模型了。
轻量化、快速化
这是一份不同模型的时间对比, 从性能上看,DistilBERT保留了BERT-base性能的97%,而参数却减少了40%,而Theseus-BERT保留了98.35%,参数也减少了40%。关于推理速度,就推理速度而言,DistilBERT和Theseus-theseus的速度分别比BERT基于基础的速度高1.6倍和1.94倍。Theseus-BERT提供了一些其他优点。像PD-BERT一样,它与模型无关,也可以应用于其他基于神经网络的模型。训练更快,成本更低,因为它仅依赖于微调,这比DistilBERT所需的从头开始进行预训练要便宜得多。
从性能上看,DistilBERT保留了BERT-base性能的97%,而参数却减少了40%,而Theseus-BERT保留了98.35%,参数也减少了40%。关于推理速度,就推理速度而言,DistilBERT和Theseus-theseus的速度分别比BERT基于基础的速度高1.6倍和1.94倍。Theseus-BERT提供了一些其他优点。像PD-BERT一样,它与模型无关,也可以应用于其他基于神经网络的模型。训练更快,成本更低,因为它仅依赖于微调,这比DistilBERT所需的从头开始进行预训练要便宜得多。
最后,Theseus-BERT似乎是明显的赢家,尽管必须指出,它是在DistilBERT之后4个月和PD-BERT之后6个月出版的。值得一提的是DistilBERT,它也是该研究领域的先驱模型之一,专注于较小的模型,并且很有可能会影响研究人员朝这个方向探索。
结论
在这篇文章中,我们介绍了三个最近的模型,分别是DistilBERT,PD-BERT和Theseus-BERT,这些模型比其原始的BERT-base模型小,并且速度显著提高,在大多数任务上的表现都差不多。回到文章开篇我们讨论的话题,由于目标不同,两种研究趋势(大模型和小模型)并存的可能性更高,大型科技公司将继续努力使用大量资源寻求最佳模型,而其他较小的公司及其研究团队将更多地关注可用于解决业务问题的较小模型。在理想的世界中,我们甚至可以设想较小的模型比大型模型的性能要好,Google的ALBERT就是一个例子。
本文参考资料
[1]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks: https://arxiv.org/abs/1803.03635
[2]Compressing BERT for faster prediction: https://blog.rasa.com/compressing-bert-for-faster-prediction-2/
[3]DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter: https://arxiv.org/abs/1910.01108
[4]Well-Read Students Learn Better: On the Importance of Pre-training Compact Models: https://arxiv.org/abs/1908.08962
[5]BERT-of-Theseus: Compressing BERT by Progressive Module Replacing: https://arxiv.org/abs/1908.08962
- END -

个人微信:加时请注明 (昵称+公司/学校+方向)

