Apache Solr9.3 快速上手
Apache Solr
简介
Solr是Apache的顶级开源项目,使用java开发 ,基于Lucene的全文检索服务器。 Solr比Lucene提供了更多的查询语句,而且它可扩展、可配置,同时它对Lucene的性能进行了优化。
安装
- 下载 : 下载地址
- 解压 :
tar -zxvf solr-9.3.0.tgz -C . - 修改solr启动参数,取消健康检查,否则启动会报警告
cd /opt/solr/solr-9.3.0/bin/vim solr.in.sh- 修改内容
SOLR_ULIMIT_CHECKS=false
启动
solr不推荐使用root账户启动,这点与es也相同,当然可以直接用-force参数,强制启动
./solr start -force
如果需要修改端口,可以通过-p参数指定
./solr start -p 8089 -force
启动成功可以看到日志打印
➜ bin ./solr start -force
Waiting up to 180 seconds to see Solr running on port 8983 [|]
Started Solr server on port 8983 (pid=3786). Happy searching!
➜ bin
访问服务器ip:8983,可查看到solr管理界面
http://localhost:8983/solr/#/

主要概念
core
在es中有索引这个概念,相当于mysql中的表(与mysql中的索引区分开来),而在solr中称之为核心 core, 所以我们可以看到页面上有一个core admin,就是用来管理核心的,个人更喜欢将其称之为索引,与es的概念形成关联记忆。
和数据库一样,solr的数据就是由一个个core组成。
doc
doc全称document, es中也有相同的概念,相当于数据库中的一行数据,一个doc也就表示的一个core中的一条数据
Schema
Schema类似于数据库中的表结构,以schema.xml的文本形式存在于conf目录下,在添加数据到索引中时,需要配置Schema。schema中包含:字段、字段类型、唯一键
分词
举个例子,我们想要搜索查询沙县小吃,那么传统的模糊查询是使用前后模糊匹配,类似 沙县小吃 ,这样的匹配模式,但如果我们的内容只有“沙县”,没有小吃时,就会导致匹配不到我们想要的信息。而分词不同,分词首先就将我们的搜索文本分割成一个个的词组,比如:沙县、小吃,然后分别匹配这些分词在哪个数据中出现的,将其匹配出来,并计算相关度得分。
倒排索引
说明了分词,我们需要继续讲解倒排索引,也叫反向索引,来帮助大家理解solr为什么能实现毫秒级的搜索体验
如下图为普通的正向索引,一句话被对应分割成了一组分词,当我们查询"china"时,会去各个文档的分词组中查询是否存在,这样的做法需要遍历每个文档,数据量较大时,明显就很慢了

而逆向索引的处理刚好相反,以分词为存储的主键,文档ID为值,这样能直接通过分词查询出哪些文档存在该关键字,通过文档ID是顺序存储的,那么也就意味着是有压缩空间的,具体大家可以参考之前书写的关于ES的分词压缩算法,核心思想类似:浅谈倒排索引的两种压缩算法:FOR算法和RBM算法
倒排索引的存储方式,其核心优势就在于当数量特别大时,其在性能的提高和空间上的节约

创建Core
通过管理画面http://ip:8983/solr的core Admin模块进行创建会失败,提示在新创建的core目录\conf\下找不到solrconfig.xml和managed-schema.xml,所以我们采用命令行的方式来创建Core。
PS D:\Apache\solr-9.3.0\solr-9.3.0\bin> .\solr.cmd create -c core_test1
WARNING: Using _default configset with data driven schema functionality. NOT RECOMMENDED for production use.
To turn off: bin\solr config -c core_test1 -p 8983 -action set-user-property -property update.autoCreateFields -value false
Created new core 'core_test1'
PS D:\Apache\solr-9.3.0\solr-9.3.0\bin>
- Overview: 概览,一些核心/索引的统计信息
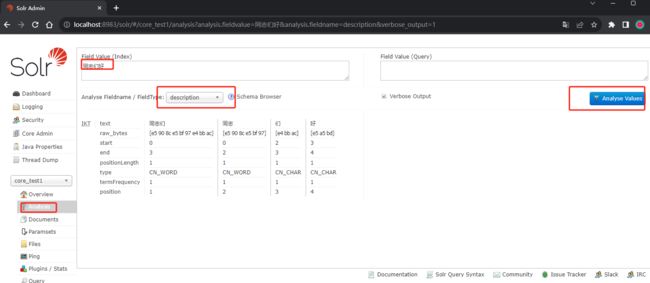
- Analysis: 分词查询,如果想知道某个查询词会被分词成什么样,可在这里操作,类似es中的_analyze语句
- DataImport: 数据同步,分为增量同步和全量同步
- Documents: 数据新增或更新、删除,新增和更新用的都是/update,id存在则更新,不存在则新增
- Files: 配置文件信息,也提供了上传或下载文件到solr服务的功能,可以通过此自定义查询组件
- Ping: 用于测试与solr服务器之前的连接是否正常
- Plugins/Stats:插件管理页面,可以查看、启用、禁用已经安装了的solr插件
- Query:查询页面,提供在线查询solr数据的页面
- Replication:管理solr分片配置
- Schema:管理solr索引结构
- Segments info:查看solr索引的段信息,了解索引大小、文档数量、字段等信息

配置solr字段
添加字段有2种方法,可以通过web页面添加,也可以直接修改schema文件添加。
| 属性 | 说明 | 取值 | 默认值 |
|---|---|---|---|
| stored | 是否存储,一个字段是否被存储,取决于你是否想在solr的查询结果中得到它,也就是说你是否想在查询结果中看到它,它将会消耗cpu和io和磁盘空间等资源。 | true/false | true |
| indexed | 字段是否创建索引,索引的字段是在搜索的时候可以用它来查询或排序,在lucene中,被索引的字段将会建立倒排表。 | true/false | true |
| uninvertible | 如果为 true,则表示一个 indexed=“true” docValues=“false” 字段在查询时可以用“un-inverted”构建大内存数据结构以代替 DocValues。 出于历史原因,默认为 true,但强烈建议用户将其设置 false 以保持稳定性,并据需要使用 docValues=“true”。 | true/false | true |
| docValues | 字段的值是否放在面向列的 DocValues 结构中 | true/false | false |
| multiValued | 设置为true表示此字段可以存储多个值,意思是这个字段在一个文档中可以存储多个值的内容。 | true/false | false |
| required | 是否必须。如果为 true,则 Solr 拒绝任何添加没有此字段的文档。 | true/false | false |
| default | 字段的默认值,经常用在字段是必须的,但是有时候又无法提供的情况,solr就会用默认值替代。如: |
修改managed-schema
在core的conf下的managed-schema文件中增加字段配置
<field name="dd" type="string" indexed="true" stored="true"/>
<field name="age" type="pint" indexed="true" stored="true" />
<field name="description" type="text_ik" indexed="true" stored="true" />
<field name="createTime" type="pdate" indexed="true" stored="true" />
<field name="updateTime" type="pdate" indexed="true" stored="true" />
添加后到“Core Admin”中刷新一下核即可
添加数据
现在core已经建好了,但是里面还没有数据,这里我们使用json添加以便快速演示(支持 JSON,、CSV、XML等格式),一般生产环境下都是从数据库访问。
准备json数据:
{"id": "11","age": 40,"name": "李白","description": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"},
{"id": "12","age": 31,"name": "杜甫","description": "唐代伟大的现实主义文学作家,唐诗思想艺术的集大成者"}
找到该core的Documents菜单,选择文档类型未JSON,把刚才准备的数据粘贴进来,确认无误提交

查询
现在验证一下查询一下
安装中文分词器
下载地址
将ik-analyzer-8.5.0.jar放入solr目录下
存放于 *solr-9.1.0\server\solr-webapp\webapp\WEB-INF\lib* 目录下
编辑 D:\Apache\solr-9.3.0\solr-9.3.0\server\solr\core_test1\conf\managed-schema.xml

查询
到core的分词菜单中验证一下description字段是否按中文分词了,可以看到一件按照中文的分词习惯进行了分词。