洛谷日记 Day 1
简单模拟
Question 1:铺地毯
题目描述:
为了准备一个独特的颁奖典礼,组织者在会场的一片矩形区域(可看做是平面直角坐标系的第一象限)铺上一些矩形地毯。一共有 nn 张地毯,编号从 11 到nn。现在将这些地毯按照编号从小到大的顺序平行于坐标轴先后铺设,后铺的地毯覆盖在前面已经铺好的地毯之上。
地毯铺设完成后,组织者想知道覆盖地面某个点的最上面的那张地毯的编号。注意:在矩形地毯边界和四个顶点上的点也算被地毯覆盖。
输入输出格式
输入格式:
输入共n+2行
第一行,一个整数n,表示总共有nn张地毯
接下来的nn行中,第 i+1行表示编号ii的地毯的信息,包含四个正整数a ,b ,g ,k,每两个整数之间用一个空格隔开,分别表示铺设地毯的左下角的坐标(a,b)以及地毯在x轴和y轴方向的长度
第n+2行包含两个正整数x和y,表示所求的地面的点的坐标(x,y)
输出格式:
输出共1行,一个整数,表示所求的地毯的编号;若此处没有被地毯覆盖则输出-1
输入输出样例
输入样例#1: 复制
3 1 0 2 3 0 2 3 3 2 1 3 3 2 2
输出样例#1: 复制
3
输入样例#2: 复制
3 1 0 2 3 0 2 3 3 2 1 3 3 4 5
输出样例#2: 复制
-1
说明
【样例解释1】
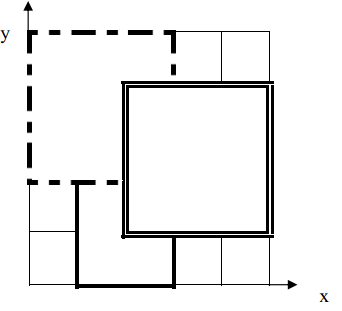
如下图,1 号地毯用实线表示,2 号地毯用虚线表示,3 号用双实线表示,覆盖点(2,2)的最上面一张地毯是 3 号地毯。
【数据范围】
对于30% 的数据,有 n ≤2;
对于50% 的数据,0 ≤a, b, g, k≤100;
对于100%的数据,有 0 ≤n ≤10,000 ,0≤a, b, g, k ≤100,000。
个人题目理解
一个简单的模拟题目,创建一个二维数组模拟输入的矩形左下和右上两个顶点,然后从最后录入的一个矩形开始查找第一个包含目标点的矩形,找到的位置就是题目要求查找的矩形,然后退出查找即可。
源码
#include//万用头文件
using namespace std;
#define ll long long
const ll MAXN=1e5+7;
ll a[MAXN][4];//用于存储矩形信息的数组
int main(){
ll n;
//数据录入
cin>>n;
for(ll j=1;j<=n;j++){
for(ll i=0;i<4;i++){
cin>>a[j][i];
}
//计算出矩形对角右上顶点
a[j][3]+=a[j][1];
a[j][2]+=a[j][0];
}
ll x,y;
//要求取的顶点
cin>>x>>y;
//从后向前倒推出一个包含(x,y)的矩形就是要求的矩形,退出循环。
ll f=n;
while(f!=-1){
if(a[f][0]<=x && a[f][1]<=y && a[f][2]>=x && a[f][3]>=y)
break;
f--;
}
cout<
Question 2:P1504机器翻译
题目描述:
题目背景
小晨的电脑上安装了一个机器翻译软件,他经常用这个软件来翻译英语文章。
题目描述
这个翻译软件的原理很简单,它只是从头到尾,依次将每个英文单词用对应的中文含义来替换。对于每个英文单词,软件会先在内存中查找这个单词的中文含义,如果内存中有,软件就会用它进行翻译;如果内存中没有,软件就会在外存中的词典内查找,查出单词的中文含义然后翻译,并将这个单词和译义放入内存,以备后续的查找和翻译。
假设内存中有MM个单元,每单元能存放一个单词和译义。每当软件将一个新单词存入内存前,如果当前内存中已存入的单词数不超过M-1M−1,软件会将新单词存入一个未使用的内存单元;若内存中已存入MM个单词,软件会清空最早进入内存的那个单词,腾出单元来,存放新单词。
假设一篇英语文章的长度为NN个单词。给定这篇待译文章,翻译软件需要去外存查找多少次词典?假设在翻译开始前,内存中没有任何单词。
输入输出格式
输入格式:
共22行。每行中两个数之间用一个空格隔开。
第一行为两个正整数M,NM,N,代表内存容量和文章的长度。
第二行为NN个非负整数,按照文章的顺序,每个数(大小不超过10001000)代表一个英文单词。文章中两个单词是同一个单词,当且仅当它们对应的非负整数相同。
输出格式:
一个整数,为软件需要查词典的次数。
输入输出样例
输入样例#1: 复制
3 7 1 2 1 5 4 4 1
输出样例#1: 复制
5
说明
每个测试点1s1s
对于10\%10%的数据有M=1,N≤5M=1,N≤5。
对于100\%100%的数据有0≤M≤100,0≤N≤10000≤M≤100,0≤N≤1000。
整个查字典过程如下:每行表示一个单词的翻译,冒号前为本次翻译后的内存状况:
空:内存初始状态为空。
1.11:查找单词1并调入内存。
2. 1 212:查找单词22并调入内存。
3. 1 212:在内存中找到单词11。
4. 1 2 5125:查找单词55并调入内存。
5. 2 5 4254:查找单词44并调入内存替代单词11。
6.2 5 4254:在内存中找到单词44。
7.5 4 1541:查找单词1并调入内存替代单词22。
共计查了55次词典。
题目理解
看到题目,就是一个简单的循环队列问题,将每次的要查找的单词在内存中查找,若存在内存中返回0次查找,如果不在内存中就对其插入在队尾之中。本题的重点就是使用循环队列来是内存处于满的状态。具体信息看代码+注释好了。
#include
using namespace std;
const int MAXN=110;//队列最大长度。
int que[MAXN];//模拟的队列。
int n,m,k;//k未队尾指针。
//使用内联函数,加快程序函数快之间的调用。
inline int search(int val){
//在内存中查找当前的单词。
for(int i=0;i>m>>n;//内存长度大小,n个单词。
int ans=0;//要查找的次数。
k=0;
int a;//输入的单词。
for(int i=0;i>a;
ans+=search(a);//对单词a进行查找。
}
cout<