CLICKHOUSE
一、交互能力
从交互式的用户体验来说
页面拖拽的方式能够给分析师展示不同的指标,查询模式比较多变,并且有一些查询的 DSL 描述,也不好用现成的 SQL 去表示,这就需要 engine 有比较好的定制能力。
二、数据量
用户的上报日志分析,面临不少技术挑战
在用 ClickHouse 做一些简单的 POC 工作,我就拿着 ClickHouse 按需求开始定制了。
三、总结:
综合来说,我们希望在头条内部把 ClickHouse 打造成为支持数据中台的查询引擎,
3.1、满足交互式行为的需求分析,
3.2、能够支持多种数据源,
3.3、整个数据链路对业务做到透明

四、困难
4.1、数据源到 ClickHouse 服务化
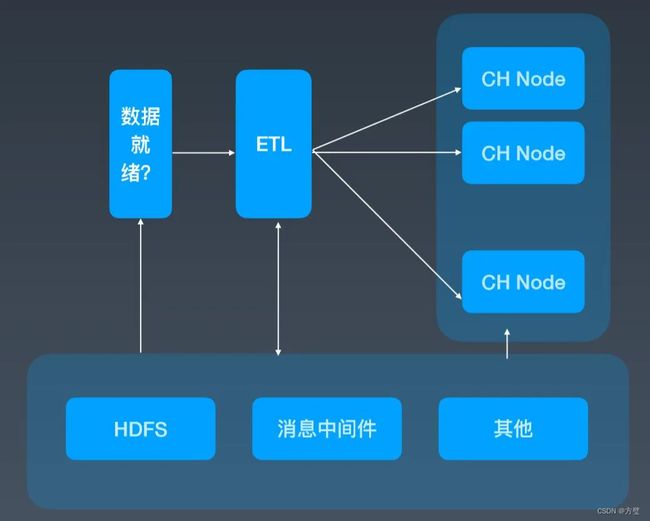
我们在做 ClickHouse 服务化的过程中,第一步就是如何把数据落到 ClickHouse 集群中。原生的 ClickHouse 没有 HDFS 访问能力,我们同时还需要保证对用户透明,就可能存在几个问题:
4.1.1、怎么访问离线数据?
4.1.2、ClickHouse 没有事务支持,如果在数据导入过程中发生了 Fail,如何做 Fail over?
4.1.3、ClickHouse 数据就绪速度。
我们整个数据就绪的压力很大,上游就绪的时间比较晚,每天早上就会有一些分析师在 ClickHouse 上看指标,整个数据落到 ClickHouse 留给我们的空挡可能不是太长。
4.1.4、解决方案
1、从 HAWQ 上移植过来 HDFS client,让 ClickHouse 能够直接访问数据
2、我们的 ETL 服务实际上维护了一套外部事务的逻辑,然后做数据一致性的保证;
3、为了保证就绪时间,我们充分利用各个节点的计算能力和数据的分布式能力,实际上最终都会在外围服务把数据作一些 Repartition,直接写入各个节点本地表。另外,我们还有一些国际化的场景,像 TikTok、Musical.ly 等,数据就绪和分析师分析的时间是有重叠的,数据写和查询交互的影响还是有一些。我们最近也在尝试把数据构建和查询分离出来,并开发相应的 Feature,但是还没有上线,从 Demo 来看,这条路是行得通的。
4.2、Map 数据类型:动态 Schema
我们在做整个框架的过程中发现,有时候产品存在动态 Schema 的需求。我们当时增加了 Map 的数据类型,主要解决的问题是产品支持的 APP 很多,上报的 Model 也是多变的,它跟用户的日志定义有关,有很多用户自定义参数,就相当于动态的 Schema。从数据产品设计的角度来看又需要相对固定的 Schema,二者之间就会存在一定的鸿沟。最终我们是通过 Map 类型来解决的。
实现 Map 的方式比较多,最简单的就是像 LOB 的方式,或者像 Two-implicit column 的方式。当时产品要求访问 Map 单键的速度与普通的 column 速度保持一致,那么比较通用的解决方案不一定能够满足我们的要求。当时做的时候,从数据的特征来看,我们发现虽然叫 Map,但是它的 keys 总量是有限的,因为依赖于用户自定义的参数不会特别多,在一定的时间范围内,Keys 数量会是比较固定的。而 ClickHouse 有一个好处:它的数据在局部是自描述的,Part 之间的数据差异自动能够 Cover 住。
最后我们采用了一个比较简单的展平模型,在我们数据写入过程中,它会做一个局部打平。以图 3 为例,表格中两行总共只有三个 key,我们就会在存储层展开这三列。这三列的描述是在局部描述的,有值的用值填充,没有值就直接用 N 填充。现在 Map 类型在头条 ClickHouse 集群的各种服务上都在使用,基本能满足大多数的需求。

另外,为了满足访问 key 的高效性,我们在执行层做自动改写,key 的访问会直接改写成对隐私列的访问。这样架构会有一个比较大的问题,它对于 Map 列的全值访问代价比较大,需要从隐式列反构建出全值列。对于这个问题,我们也没有很好地解决,因为实际上在很多时候我们只关心 key 的访问效率。
4.3、大数据量和高可用
不知道大家在使用 ClickHouse 的过程中有没有一个体会,它的高可用方案在大的数据量下可能会有点问题。主要是 zookeeper 的使用方式可能不是很合理,也就是说它原生的 Replication 方案有太多的信息存在 ZK 上,而为了保证服务,一般会有一个或者几个副本,在头条内部主要是两个副本的方案。
我们当时有一个 400 个节点的集群,还只有半年的数据。突然有一天我们发现服务特别不稳定,ZK 的响应经常超时,table 可能变成只读模式,发现它 znode 的太多。而且 ZK 并不是 Scalable 的框架,按照当时的数据预估,整个服务很快就会不可用了。
我们分析后得出结论,实际上 ClickHouse 把 ZK 当成了三种服务的结合,而不仅把它当作一个 Coordinate service,可能这也是大家使用 ZK 的常用用法。ClickHouse 还会把它当作 Log Service,很多行为日志等数字的信息也会存在 ZK 上;还会作为表的 catalog service,像表的一些 schema 信息也会在 ZK 上做校验,这就会导致 ZK 上接入的数量与数据总量会成线性关系。按照这样的数据增长预估,ClickHouse 可能就根本无法支撑头条抖音的全量需求。
社区肯定也意识到了这个问题,他们提出了一个 mini checksum 方案,但是这并没有彻底解决 znode 与数据量成线性关系的问题。所以我们就基于 MergeTree 存储引擎开发了一套自己的高可用方案。我们的想法很简单,就是把更多 ZK 上的信息卸载下来,ZK 只作为 coordinate Service。只让它做三件简单的事情:行为日志的 Sequence Number 分配、Block ID 的分配和数据的元信息,这样就能保证数据和行为在全局内是唯一的。
关于节点,它维护自身的数据信息和行为日志信息,Log 和数据的信息在一个 shard 内部的副本之间,通过 Gossip 协议进行交互。我们保留了原生的 multi-master 写入特性,这样多个副本都是可以写的,好处就是能够简化数据导入。图 6 是一个简单的框架图。
以这个图为例,如果往 Replica 1 上写,它会从 ZK 上获得一个 ID,就是 Log ID,然后把这些行为和 Log Push 到集群内部 shard 内部活着的副本上去,然后当其他副本收到这些信息之后,它会主动去 Pull 数据,实现数据的最终一致性。我们现在所有集群加起来 znode 数不超过三百万,服务的高可用基本上得到了保障,压力也不会随着数据增加而增加。