YOLOv8最新改进系列:YOLOv8+RepViT,从ViT视角重新审视移动端CNN,有效提升模型检测效果!!!1.3ms 延迟 -清华 ICCV 2023 最新开源移动端网络架构 RepViT
YOLOv8最新改进系列
[RepViT提出的论文戳这]](https://arxiv.org/abs/2307.09283)
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
截止到发稿时,B站YOLOv8最新改进系列的源码包,已更新了29种+损失函数的改进!自己排列组合2-4种后,不考虑位置已达5万种以上改进方法!考虑位置不同后可排列上百万种!!专注AI学术,关注B站博主:AI学术叫叫兽!
YOLOv8最新改进系列:YOLOv8+RepViT,从ViT视角重新审视移动端CNN,有效提升模型检测效果!!!
- YOLOv8最新改进系列
- 一、RepViT概述
-
- 1.3 RepViT文章摘要
- 1.2 RepViT简介
- 二、实验
-
- 2.1 本文亮点(贡献)
- 2.2 方法
-
- 2.2.1 训练配方的对齐
- 2.2.2 延迟度量指标
- 2.2.3 训练策略的对齐
- 2.2.4 块设计的优化
- 2.2.5 分离 Token 混合器和通道混合器
- 2.2.6 降低扩张比例并增加宽度
- 2.2.7 宏观架构元素的优化
- 2.2.8 浅层网络使用卷积提取器
- 2.2.9 更深的下采样层
- 2.2.10 更简单的分类器
- 2.2.11 整体阶段比例
- 2.2.12 卷积核大小的选择
- 2.2.13 SE 层的位置
- 2.2.14 微观设计的调整
- 2.3 网络架构
- 三、 改进教程
-
- 3.1 修改YAML文件
- 3.2 新建SwinTransformer.py
- 3.3 修改tasks.py
- 四、验证是否成功即可
一、RepViT概述
1.3 RepViT文章摘要
近年来,与轻量级卷积神经网络(cnn)相比,轻量级视觉变压器(ViTs)在资源受限的移动设备上表现出了更高的性能和更低的延迟。这种改进通常归功于多头自注意模块,它使模型能够学习全局表示。然而,轻量级vit和轻量级cnn之间的架构差异还没有得到充分的研究。在这项研究中,我们重新审视了轻量级cnn的高效设计,并强调了它们在移动设备上的潜力。通过集成轻量级vit的高效架构选择,我们逐步增强了标准轻量级CNN的移动友好性,特别是MobileNetV3。这就产生了一个新的纯轻量级cnn家族,即RepViT。大量的实验表明,RepViT优于现有的轻型vit,并在各种视觉任务中表现出良好的延迟。在ImageNet上,RepViT在iPhone 12上以近1ms的延迟实现了超过80%的top-1精度,据我们所知,这是轻量级模型的第一次。
1.2 RepViT简介
轻量级模型研究一直是计算机视觉任务中的一个焦点,其目标是在降低计算成本的同时达到优秀的性能。轻量级模型与资源受限的移动设备尤其相关,使得视觉模型的边缘部署成为可能。在过去十年中,研究人员主要关注轻量级卷积神经网络(CNNs)的设计,提出了许多高效的设计原则,包括可分离卷积 、逆瓶颈结构 、通道打乱 和结构重参数化等,产生了 MobileNets ,ShuffleNets和 RepVGG 等代表性模型。
另一方面,视觉 Transformers(ViTs)成为学习视觉表征的另一种高效方案。与 CNNs 相比,ViTs 在各种计算机视觉任务中表现出了更优越的性能。然而,ViT 模型一般尺寸很大,延迟很高,不适合资源受限的移动设备。因此,研究人员开始探索 ViT 的轻量级设计。许多高效的ViTs设计原则被提出,大大提高了移动设备上 ViTs 的计算效率,产生了EfficientFormers ,MobileViTs等代表性模型。这些轻量级 ViTs 在移动设备上展现出了相比 CNNs 的更强的性能和更低的延迟。
轻量级 ViTs 优于轻量级 CNNs 的原因通常归结于多头注意力模块,该模块使模型能够学习全局表征。然而,轻量级 ViTs 和轻量级 CNNs 在块结构、宏观和微观架构设计方面存在值得注意的差异,但这些差异尚未得到充分研究。这自然引出了一个问题:轻量级 ViTs 的架构选择能否提高轻量级 CNN 的性能?在这项工作中,我们结合轻量级 ViTs 的架构选择,重新审视了轻量级 CNNs 的设计。我们的旨在缩小轻量级 CNNs 与轻量级 ViTs 之间的差距,并强调前者与后者相比在移动设备上的应用潜力。
二、实验
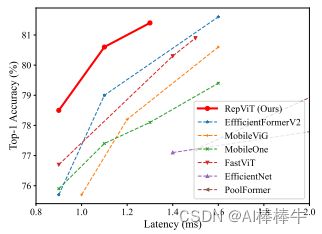
可以看出,RepViT 相比于其它主流的移动端 ViT 架构确实时很优异。接下来让我们来看下本工作做了哪些贡献:
2.1 本文亮点(贡献)
1.文中提到,轻量级 ViTs 通常比轻量级 CNNs 在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(MSHA)可以让模型学习全局表示。然而,轻量级 ViTs 和轻量级 CNNs 之间的架构差异尚未得到充分研究。
2.在这项研究中,作者们通过整合轻量级 ViTs 的有效架构选择,逐步提升了标准轻量级 CNN(特别是 MobileNetV3 的移动友好性。这便衍生出一个新的纯轻量级 CNN 家族的诞生,即RepViT。值得注意的是,尽管 RepViT 具有 MetaFormer 结构,但它完全由卷积组成。
3.实验结果表明,RepViT 超越了现有的最先进的轻量级 ViTs,并在各种视觉任务上显示出优于现有最先进轻量级ViTs的性能和效率,包括 ImageNet 分类、COCO-2017 上的目标检测和实例分割,以及 ADE20k 上的语义分割。特别地,在ImageNet上,RepViT 在 iPhone 12 上达到了近乎 1ms 的延迟和超过 80% 的Top-1 准确率,这是轻量级模型的首次突破。
2.2 方法
在 ConvNeXt 中,作者们是基于 ResNet50 架构的基础上通过严谨的理论和实验分析,最终设计出一个非常优异的足以媲美 Swin-Transformer 的纯卷积神经网络架构。同样地,RepViT也是主要通过将轻量级 ViTs 的架构设计逐步整合到标准轻量级 CNN,即MobileNetV3-L,来对其进行针对性地改造(魔改)。在这个过程中,作者们考虑了不同粒度级别的设计元素,并通过一系列步骤达到优化的目标。
详细优化步骤如下:
2.2.1 训练配方的对齐
论文中引入了一种衡量移动设备上延迟的指标,并将训练策略与现有的轻量级 ViTs 对齐。这一步骤主要是为了确保模型训练的一致性,其涉及两个概念,即延迟度量和训练策略的调整。
2.2.2 延迟度量指标
为了更准确地衡量模型在真实移动设备上的性能,作者选择了直接测量模型在设备上的实际延迟,以此作为基准度量。这个度量方法不同于之前的研究,它们主要通过FLOPs或模型大小等指标优化模型的推理速度,这些指标并不总能很好地反映在移动应用中的实际延迟。
2.2.3 训练策略的对齐
这里,将 MobileNetV3-L 的训练策略调整以与其他轻量级 ViTs 模型对齐。这包括使用 AdamW 优化器-ViTs 模型必备的优化器,进行 5 个 epoch 的预热训练,以及使用余弦退火学习率调度进行 300 个 epoch 的训练。尽管这种调整导致了模型准确率的略微下降,但可以保证公平性。
2.2.4 块设计的优化
基于一致的训练设置,作者们探索了最优的块设计。块设计是 CNN 架构中的一个重要组成部分,优化块设计有助于提高网络的性能。
2.2.5 分离 Token 混合器和通道混合器
这块主要是对 MobileNetV3-L 的块结构进行了改进,分离了令牌混合器和通道混合器。原来的 MobileNetV3 块结构包含一个 1x1 扩张卷积,然后是一个深度卷积和一个 1x1 的投影层,然后通过残差连接连接输入和输出。在此基础上,RepViT 将深度卷积提前,使得通道混合器和令牌混合器能够被分开。为了提高性能,还引入了结构重参数化来在训练时为深度滤波器引入多分支拓扑。最终,作者们成功地在 MobileNetV3 块中分离了令牌混合器和通道混合器,并将这种块命名为 RepViT 块。
2.2.6 降低扩张比例并增加宽度
在通道混合器中,原本的扩张比例是 4,这意味着 MLP 块的隐藏维度是输入维度的四倍,消耗了大量的计算资源,对推理时间有很大的影响。为了缓解这个问题,我们可以将扩张比例降低到 2,从而减少了参数冗余和延迟,使得 MobileNetV3-L 的延迟降低到 0.65ms。随后,通过增加网络的宽度,即增加各阶段的通道数量,Top-1 准确率提高到 73.5%,而延迟只增加到 0.89ms!
2.2.7 宏观架构元素的优化
在这一步,本文进一步优化了MobileNetV3-L在移动设备上的性能,主要是从宏观架构元素出发,包括 stem,降采样层,分类器以及整体阶段比例。通过优化这些宏观架构元素,模型的性能可以得到显著提高。
2.2.8 浅层网络使用卷积提取器
ViTs 通常使用一个将输入图像分割成非重叠补丁的 “patchify” 操作作为 stem。然而,这种方法在训练优化性和对训练配方的敏感性上存在问题。因此,作者们采用了早期卷积来代替,这种方法已经被许多轻量级 ViTs 所采纳。对比之下,MobileNetV3-L 使用了一个更复杂的 stem 进行 4x 下采样。这样一来,虽然滤波器的初始数量增加到24,但总的延迟降低到0.86ms,同时 top-1 准确率提高到 73.9%。
2.2.9 更深的下采样层
在 ViTs 中,空间下采样通常通过一个单独的补丁合并层来实现。因此这里我们可以采用一个单独和更深的下采样层,以增加网络深度并减少由于分辨率降低带来的信息损失。具体地,作者们首先使用一个 1x1 卷积来调整通道维度,然后将两个 1x1 卷积的输入和输出通过残差连接,形成一个前馈网络。此外,他们还在前面增加了一个 RepViT 块以进一步加深下采样层,这一步提高了 top-1 准确率到 75.4%,同时延迟为 0.96ms。
2.2.10 更简单的分类器
在轻量级 ViTs 中,分类器通常由一个全局平均池化层后跟一个线性层组成。相比之下,MobileNetV3-L 使用了一个更复杂的分类器。因为现在最后的阶段有更多的通道,所以作者们将它替换为一个简单的分类器,即一个全局平均池化层和一个线性层,这一步将延迟降低到 0.77ms,同时 top-1 准确率为 74.8%。
2.2.11 整体阶段比例
阶段比例代表了不同阶段中块数量的比例,从而表示了计算在各阶段中的分布。论文选择了一个更优的阶段比例 1:1:7:1,然后增加网络深度到 2:2:14:2,从而实现了一个更深的布局。这一步将 top-1 准确率提高到 76.9%,同时延迟为 1.02 ms。
2.2.12 卷积核大小的选择
众所周知,CNNs 的性能和延迟通常受到卷积核大小的影响。例如,为了建模像 MHSA 这样的远距离上下文依赖,ConvNeXt 使用了大卷积核,从而实现了显著的性能提升。然而,大卷积核对于移动设备并不友好,因为它的计算复杂性和内存访问成本。MobileNetV3-L 主要使用 3x3 的卷积,有一部分块中使用 5x5 的卷积。作者们将它们替换为3x3的卷积,这导致延迟降低到 1.00ms,同时保持了76.9%的top-1准确率。
2.2.13 SE 层的位置
自注意力模块相对于卷积的一个优点是根据输入调整权重的能力,这被称为数据驱动属性。作为一个通道注意力模块,SE层可以弥补卷积在缺乏数据驱动属性上的限制,从而带来更好的性能。MobileNetV3-L 在某些块中加入了SE层,主要集中在后两个阶段。然而,与分辨率较高的阶段相比,分辨率较低的阶段从SE提供的全局平均池化操作中获得的准确率提升较小。作者们设计了一种策略,在所有阶段以交叉块的方式使用SE层,从而在最小的延迟增量下最大化准确率的提升,这一步将top-1准确率提升到77.4%,同时延迟降低到0.87ms。
注意!【这一点其实百度在很早前就已经做过实验比对得到过这个结论了,SE 层放置在靠近深层的地方效果好】
2.2.14 微观设计的调整
RepViT 通过逐层微观设计来调整轻量级 CNN,这包括选择合适的卷积核大小和优化挤压-激励(Squeeze-and-excitation,简称SE)层的位置。这两种方法都能显著改善模型性能。
2.3 网络架构
最终,通过整合上述改进策略,我们便得到了模型RepViT的整体架构,该模型有多个变种,例如RepViT-M1/M2/M3。同样地,不同的变种主要通过每个阶段的通道数和块数来区分。
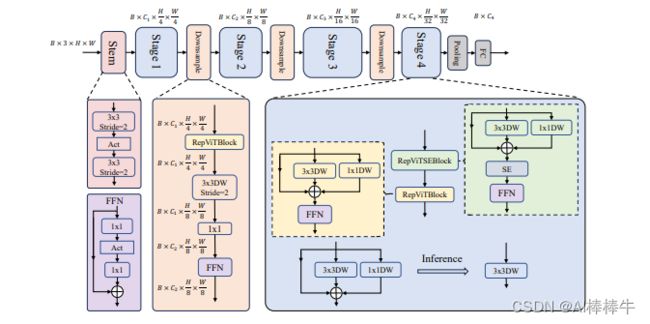
三、 改进教程
3.1 修改YAML文件
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
3.2 新建SwinTransformer.py
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
3.3 修改tasks.py
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
四、验证是否成功即可
执行命令
python train.py
改完收工!
关注B站:AI学术叫叫兽
从此走上科研快速路
遥遥领先同行!!!!
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!