Xxl-Job 初次体验
Xxl-Job 初次体验
- 一、定时任务-前置知识
- 二、演变机制
- 三、xxl-Job 设计思想
- 四、xxl-job 实战
-
- 1. 调度中心部署
- 2. 编写执行器简单使用一下
-
- 2.1. 让执行器run起来!
- 2.2. 在调度中心配置任务,调度一下!
- 3. @XxlJob 任务的生命周期
- 4. 路由策略
- 5. 父子任务
- 6. 动态任务参数
- 7. 分片任务
- 8. 日志回调
一、定时任务-前置知识
定时任务,即指定时间去执行任务。比如说小编在消息中台的设计:往往因为网络问题导致消息推送失败,立刻去重试发送是毫无意义的,因为网络不可能立马恢复。我们就可以将推送的失败的消息存入持久层或缓存(不推荐,只有可以丢失的数据放缓存),使用Xxl-Job每隔半小时去执行一次读库补发操作,保证数据不丢失!即,在传统分布式情况下,保证双方数据的一致性!(这里就是业务前台和消息中台之间)
定时任务分类
- 单机定时任务:单机容易实现,但应用于集群环境做分布式部署,就会带来重复执行。可以通过加锁方式来解决(解决的同时增加了很多非业务逻辑)
- 分布式调度:把需要处理的计划任务放入到统一平台,实现集群管理调度于分布式部署的定时任务。支持集群部署、高可用、并行调度、分片处理等。
实现定时job有哪些方案?
- Thread——Thread.sleep方法
- TimeTask——java.util
- ScheduledExecutorService,基于线程池来进行设计的定时任务类,在这里每个调度的任务都会分配到线程池里的一个线程去执行该任务,并发执行,互不影响。
- SpringBoot框架自带定时任务。
- 启动类上加上
@EnableScheduling开启定时任务 - 在定时任务类加上注解
@Component注入容器 - 在定时执行的方法加上注解
@Schedule()定时执行
- 启动类上加上
- Quartz——三方框架。
- Xxl-Job
前五种方式只可以在单jvm情况下使用,不能保证定时任务幂等性。
二、演变机制
定时任务的基本概念
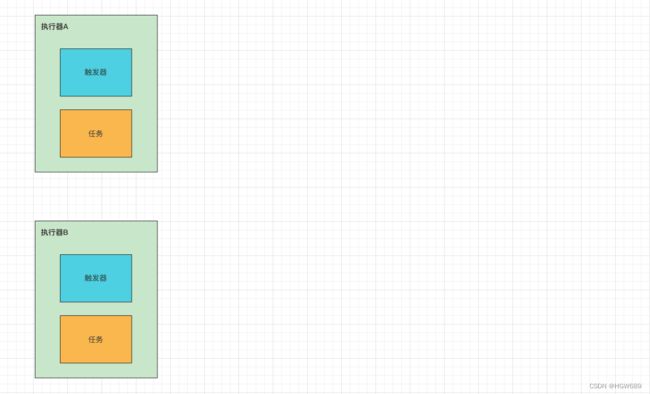
- 执行器(Executor),执行任务的机器。
- 任务(Job):业务实现。
- 触发器(Trigger):制定规则去触发任务的执行。

通常我们为了保证服务的HA(高可用),通过多个节点部署去实现。那样我们多个节点中每个节点都是有自己的触发器,这样就存在着资源竞争问题!
大家肯定就想起了通过分布式锁去解决,当然这是一种解决方法,但不是最完美的解决方法。因为在使用分布式锁的同时也会带来许多其他问题,这里就不做详细讲解。对分布式锁的实现感兴趣的同学可以瞧瞧小编的另外一篇博客Redis实现分布式锁
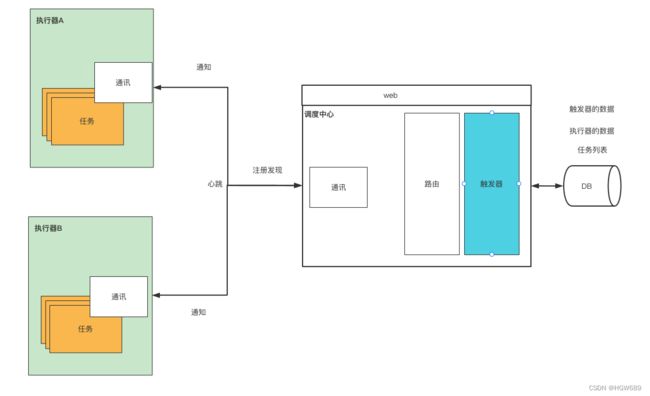
这时候我们需要引入一个调度中心的概念,此时我们就可以将执行器的调度调整到调度中心进行统一管理。
触发器实则就是一堆规则,任务也存在多个任务我们需要去标识具体的任务,以及执行器包含各种状态等数据。此时就需要引入我们的DB去支持。
那么这些数据我们怎么获取呢?最简单的就是提供一个web页面去配置。
许多执行器,我们需要去路由具体哪个执行器去执行。
各个节点需要通信,启动时需要去调度中心注册,调度中心触发执行任务时需要通知执行器执行。一个大概的分布式调度模型就出现了!
三、xxl-Job 设计思想
文档地址
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。
因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性;
- 调度模块(调度中心):
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover(故障转移)。 - 执行模块(执行器):
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
接收“调度中心”的执行请求、终止请求和日志请求等。
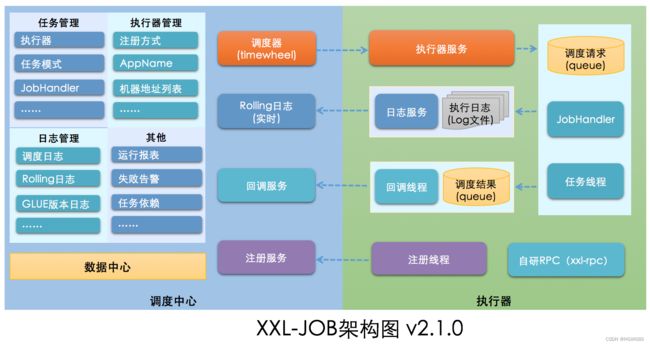
执行器就是我们的业务服务,一个执行器中存在多个任务。执行器在启动的时候通过注册信息向调度中心发送注册请求,建立心跳连接,通过执行器管理。执行器中存在多个任务,使用任务管理进行管理。
通过调度器调度具体执行器,执行器收到调度请求执行JobHandler任务处理器,实时将执行日志返回给调度中心。执行完任务将任务方法执行结果返回给调度中心。调度中心执行回调方法,写入调度日志,进行日志管理。可以生成调度的运行报表,或者调度失败进行告警等等。
特点
简单:支持通过 Web页面对任务进行 CRUD 操作,上手简单!
动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效。不需要代码中进行修改咯!
调度中心 HA(中央式)——调度采用中心式设计,“调度中心”自研调度组件并支持集群部署,可保证调度中心HA。
执行器HA(分布式)—— 任务分布式执行,任务“执行器“支持集群部署,可保证任务执行HA
注册中心——执行器会周期性自动注册任务,调度中心将会自动发现注册的任务并触发执行。同时,也支持手动录入执行器地址
自定义任务参数——支持在线配置调度任务入参,即时生效。(比如说每个月的5号发送花呗账单,要是本月执行失败了要是不改变就需要到下个月的5号。此时我们需要手动触发,自定义参数执行。)
任务依赖——支持配置子任务依赖,当父任务执行结束且执行成功后将会主动触发一次子任务的执行,多个子任务用逗号分隔。(如我们平时需要执行清洗数据任务时,需要等这一功能数据清洗完之后才能清洗下一功能的)
弹性扩容缩容——一旦有新执行器上线或者下线,下次调度时将会重新分配任务
路由策略——执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮训、随机、一次性Hash、最不经常使用、最近最久未使用、故障转移、忙碌转移等
故障转移——任务路由策略选择“故障转移”情况下,如果执行器集群中某一台机器故障,将会自动 Failover 切换到一台正常的执行器发送调度请求
阻塞处理策略——调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度
……
四、xxl-job 实战
1. 调度中心部署
仓库地址大家自行扒拉一下代码,版本择于 2.3.1
先看看源码的目录
1、初始化数据库
将数据库脚本导入数据库
数据库里面有如下几张表:

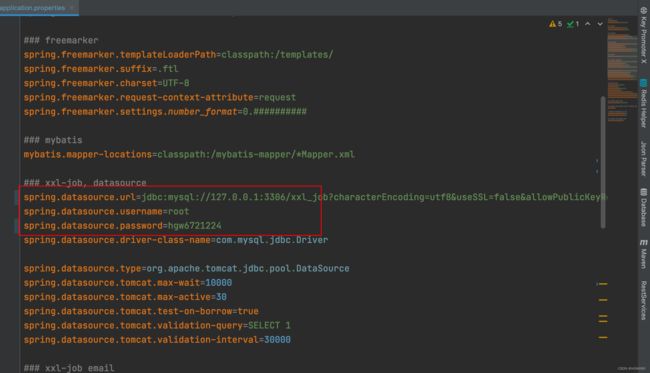
2、修改一下配置
1、修改数据库的配置信息
2、创建一个日志文件并配置
这里小编涂个方便就写在项目里面啦!(大家部署在服务器上时需指定项目外路径)

3、配置默认token
3、启动主方法
启动主方法,访问 http://127.0.0.1:8080/xxl-job-admin
我们在初始化数据库的时候会在用户表中默认生成一条username为admin,密码为123456的用户。

2. 编写执行器简单使用一下
2.1. 让执行器run起来!
1、首先创建SpringBoot项目,导入依赖 (版本选择自己运行的调度中心的版本)
<dependency>
<groupId>com.xuxueligroupId>
<artifactId>xxl-job-coreartifactId>
<version>2.3.1version>
dependency>
2、将 xxl-job 项目中 xxl-job-executor-sample-springboot 服务中的 application.propertirs、logbook.xml 配置复制过来并重写配置(小编将自己的配置贴在下面啦)
application.properties、logback.xml 详细配置文件如下~
# web port 应用的端口
server.port=8081
# no web
#spring.main.web-environment=false
# log config
logging.config=classpath:logback.xml
### 注册地址,调度中心部署根地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### 执行器通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=default_token
### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
xxl.job.executor.appname=hello-xxl-job-executor
### 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
xxl.job.executor.address=
### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
xxl.job.executor.ip=
### 执行器内部端口[选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
xxl.job.executor.port=9999
### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
xxl.job.executor.logpath=llo
### 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
xxl.job.executor.logretentiondays=30
<configuration debug="false" scan="true" scanPeriod="1 seconds">
<contextName>logbackcontextName>
<property name="log.path" value="/data/applogs/xxl-job/xxl-job-executor-sample-springboot.log"/>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%npattern>
encoder>
appender>
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${log.path}.%d{yyyy-MM-dd}.zipfileNamePattern>
rollingPolicy>
<encoder>
<pattern>%date %level [%thread] %logger{36} [%file : %line] %msg%n
pattern>
encoder>
appender>
<root level="info">
<appender-ref ref="console"/>
<appender-ref ref="file"/>
root>
configuration>
3、编写配置类
package com.hgw.executor01.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Description: XxlJob配置类
*
* @author Linhuiba-YanAn
* @date 2022/11/23 21:08
*/
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}
4、编写任务
@Component
public class HelloXxlJob {
/**
* demo-任务1
*
* @return
*/
@XxlJob(value = "taskDemo01", init = "init", destroy = "destroy")
public ReturnT taskDemo() {
System.out.println("执行调度任务——Hello:" +LocalDateTime.now().toString());
// 调度结果
return ReturnT.SUCCESS;
}
public void init() {
System.out.println("xxl-job工作线程初始化成功");
}
public void destroy() {
System.out.println("xxl-job工作线程关闭成功");
}
}
5、run起来!
启动main方法注册成功!(本地demo时不推荐奖调度中心部署在云服务器上玩,除非你把本地的执行器端口内网穿透出去!)
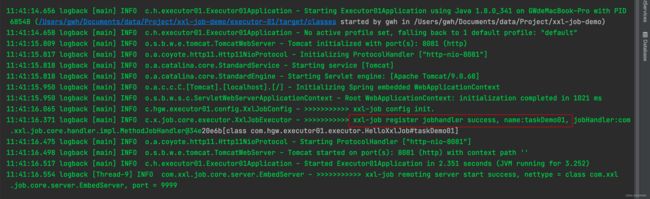
2.2. 在调度中心配置任务,调度一下!
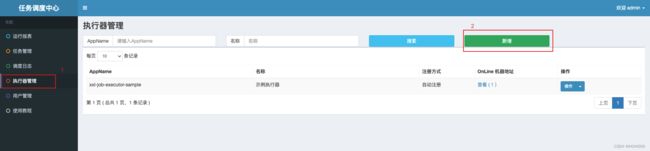
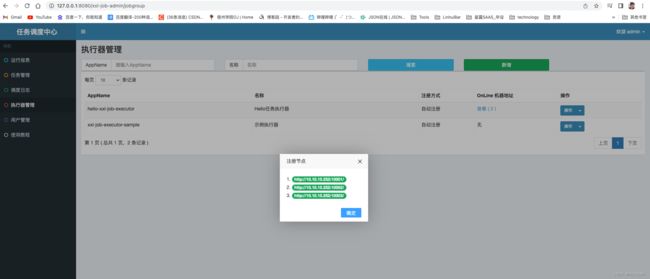
注册执行器
首先我们要在任务中心配注册执行器~
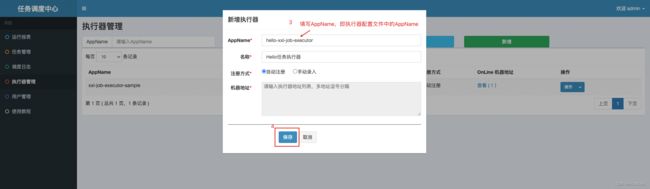
刷新一下可以看到注册机器ip
配置任务
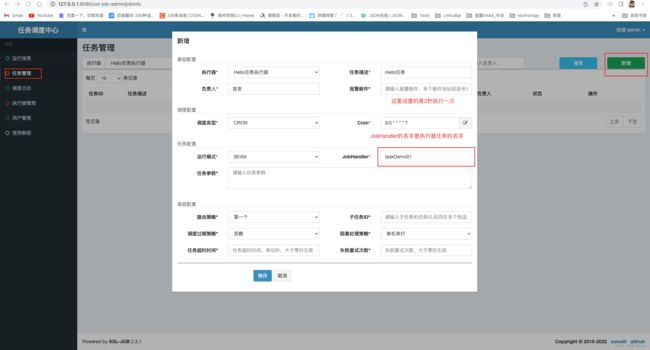
启动任务
启动任务一种有两种方式,一种是“启动”按照制定的触发规则去调度任务执行。另一种是调度执行器执行一次任务。
1、执行一次任务
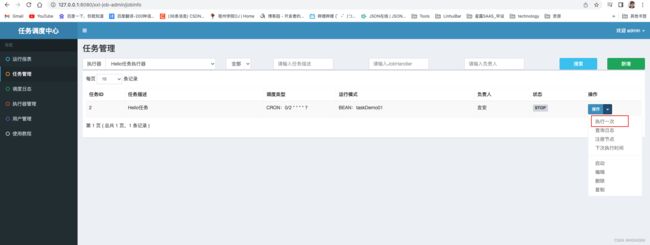
此时发现任务执行啦!
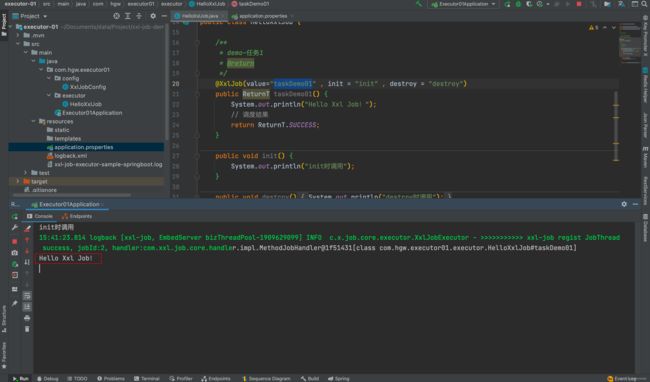
并且我们可以在调度日志中查询本次调度执行状况~
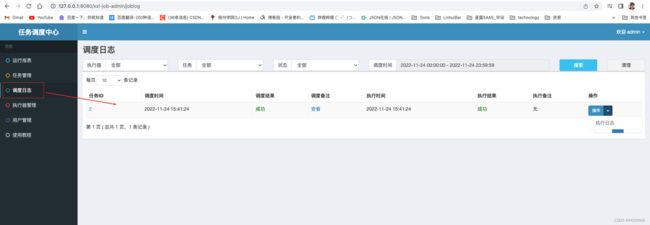
点击执行日志可以看详细的日志报告,其中包括执行器日志回调的内容(接下来会给大家演示)
2、启动任务
我们加上打印当前时间并启动任务,看看效果触发规则是不是和我们设置的一样呢~
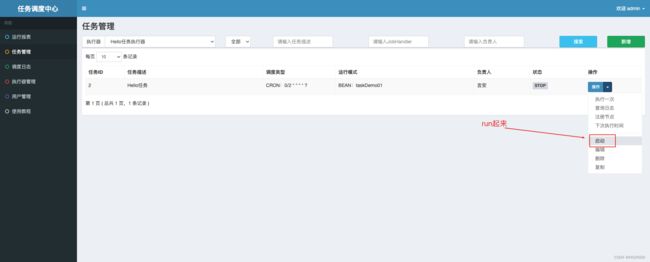
瞧!按照我们设置的触发规则每隔2秒执行一侧~
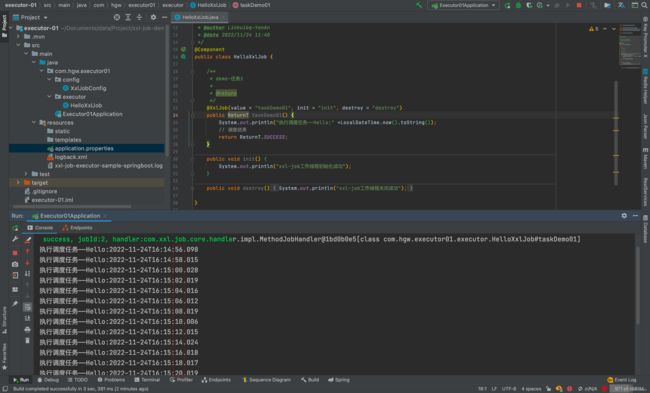
3. @XxlJob 任务的生命周期
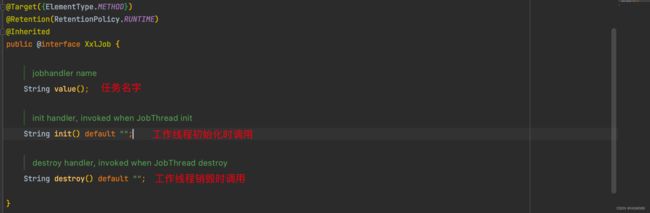
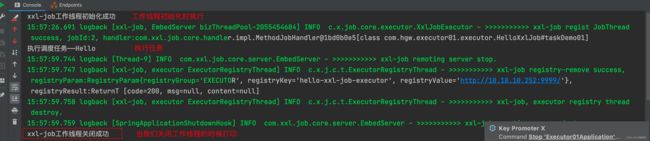
即,我们可以在init 和 destory 方法中编写每次任务执行前的初始化工作和任务执行结束后的资源释放工作~
4. 路由策略
当执行器集群部署时,提供丰富的路由策略,包括;
FIRST(第一个):固定选择第一个机器;LAST(最后一个):固定选择最后一个机器;ROUND(轮询):;RANDOM(随机):随机选择在线的机器;CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举;FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
简单实践一下
我们在本地起了三个服务,来看看效果如何~
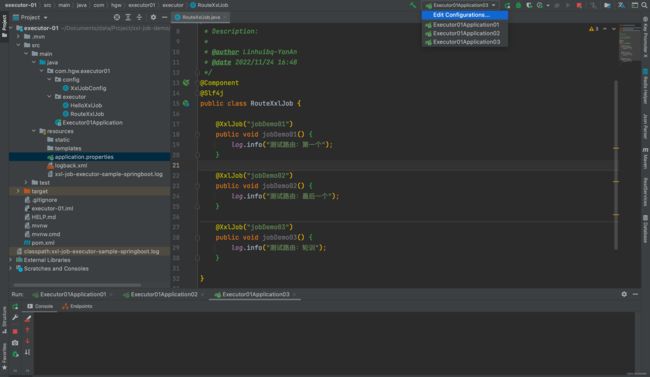
创建三个任务选择不同的路由策略和JobHandler
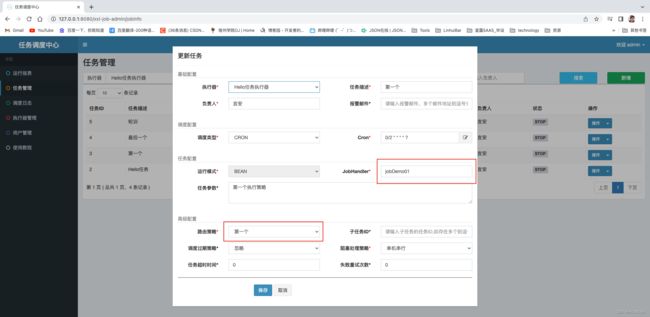
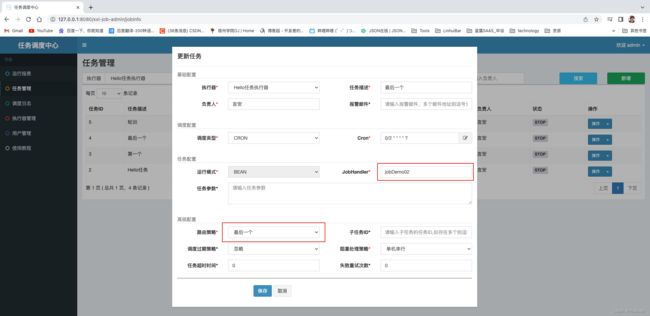
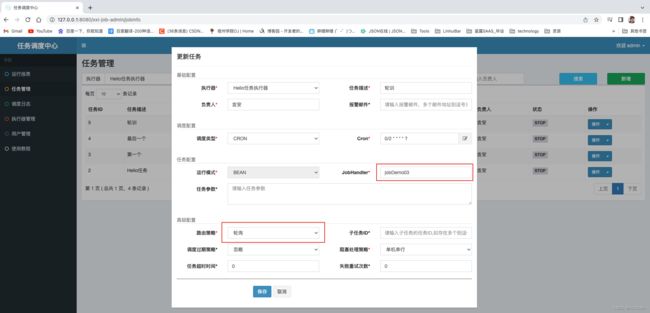
验证路由 第一个
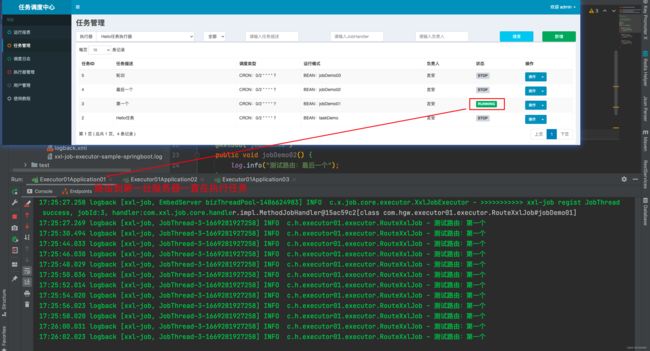
验证路由 最后一个
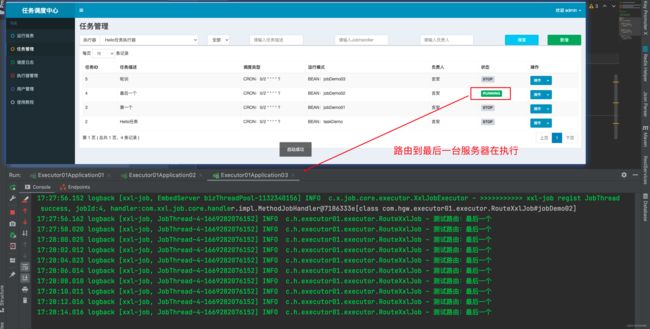
验证路由 轮训
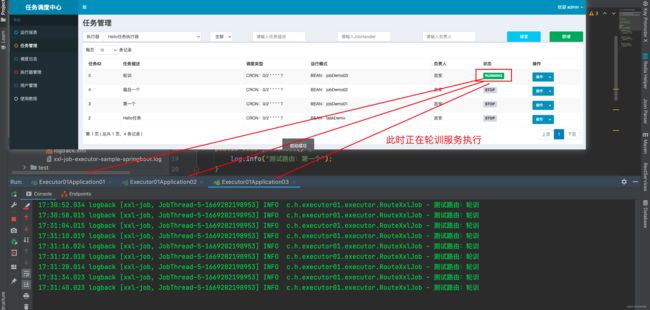
5. 父子任务
父子任务就帮我们解决了许多问题,比如说我们清洗数据的时候B业务清洗数据需建立A业务数据清洗完之后执行,此时就可以使用父子任务啦。
废话不说,上实例!
编写任务方法
@Component
@Slf4j
public class ParentXxlJob {
@XxlJob("parentJob")
public void parentJob() {
log.info("父任务执行了");
}
@XxlJob("childrenJob1")
public void childrenJob1() {
log.info("子任务1执行了");
}
@XxlJob("childrenJob2")
public void childrenJob2() {
log.info("子任务2执行了");
}
@XxlJob("childrenJob3")
public void childrenJob3() {
log.info("子任务3执行了");
}
}
配置父子任务
首先编写三个子任务~
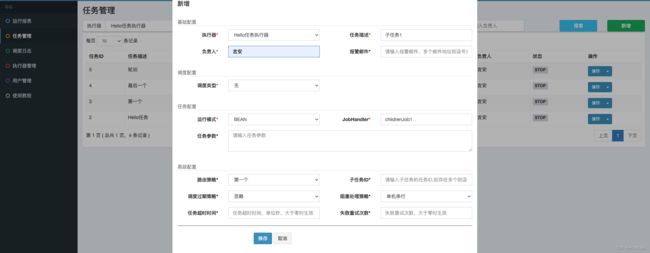
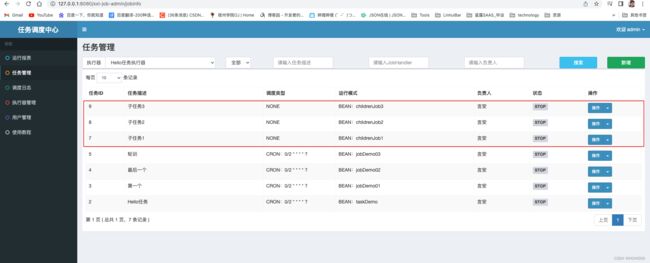
最后创建父任务并配置
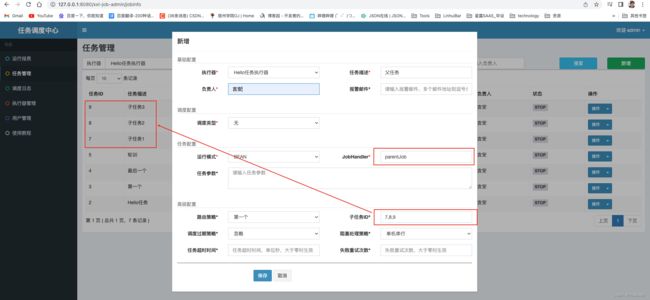
让我们执行一下父任务trytry~我们会发现执行完父任务后,按照子任务id的顺序执行子任务

6. 动态任务参数
Xxl-job支持在线配置调度任务入参,即时生效。我们可以在任务接收到调度参数后,进行相应的业务逻辑处理~(不过小编发现这里输入框只是个文本输入框,大家如果有比较复杂的逻辑的话介意序列化成JSON配置并在任务中解析)
任务方法中获取动态参数进行相关的业务处理
@Slf4j
@Component
public class DynamicParameterXxlJob {
@XxlJob("dynamicParameterJob")
public void job() {
String user = "admin";
// 获取调度器传递的参数
String param = XxlJobHelper.getJobParam();
if (StrUtil.isNotBlank(param)) {
user = param;
}
log.info("当前操作人为:{}",user);
}
}
配置任务
here
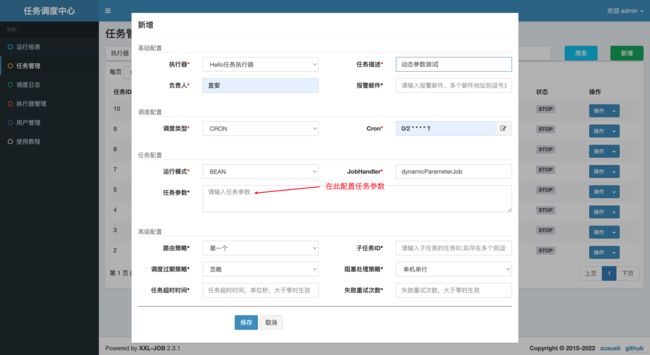
又或者 here
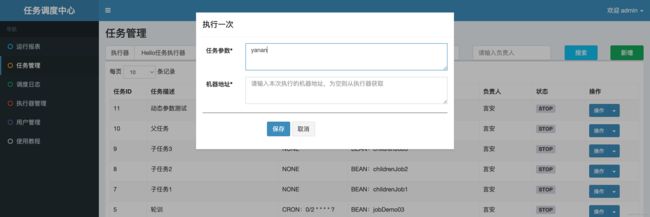
首先我们先不配置参数执行一次,这里可以看到按照逻辑当前的操作人应该是默认的admin。接下来在执行一次中配置动态参数~
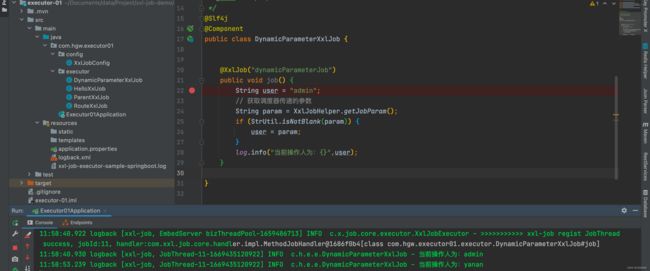
源码小探究~
小编猜底层应该是维护了一个ThreadLocalMap,将调度请求信息封装在中,然后从中获取~
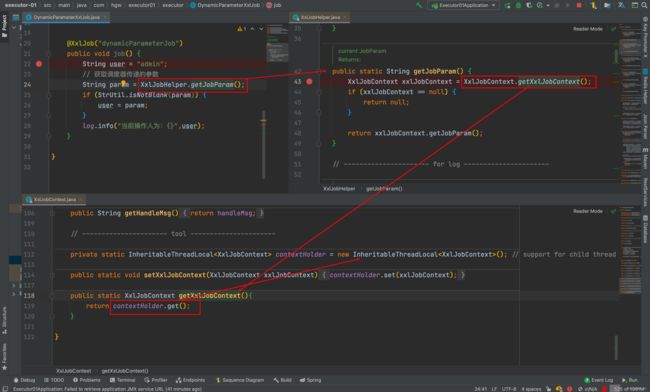
由此我们可以看出在 XxlJobContext中维护了一个 InheritableThreadLocal 类,InheritableThreadLocal 继承自 ThreadLocal ,其绑定的是当前线程以及当前线程的子线程。InheritableThreadLocal详解
Map 的 value 存放的是 XxlJobContext封装着 动态参数~
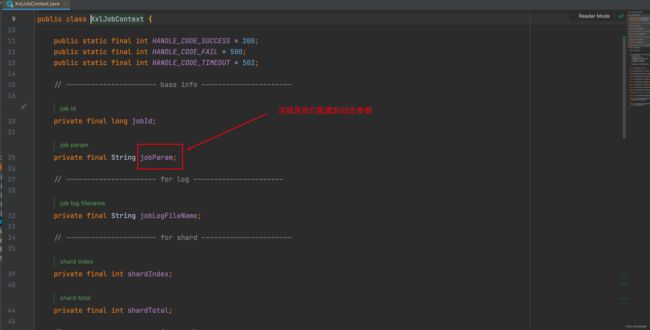
7. 分片任务
分片任务是指会对所有的执行器广播这个任务,所有的执行器都会接收到调用请求。每个执行器可以根据总分片数及当前执行器的索引进行相关业务处理。
模拟一下10w条数据,由3个执行器执行~
-
总分片数
-
当前分片索引【索引从0开始】
-
每个分片,平均处理的数据量: 任务数据数量【10w】/总分片数
-
每个分片处理的范围:
- 开始索引:当前分片索引 * 平均处理的数据量 + 1
- 结束索引:(当前分片索引+1)* 平均处理的数据量 【最后一个分片】
@Slf4j
@Component
public class ShardTaskXxlJob {
@XxlJob("shardTaskJob")
public void ShardTaskJob() {
// 获取分片总数
int shardTotal = XxlJobHelper.getShardTotal();
// 当前分片索引
int shardIndex = XxlJobHelper.getShardIndex();
// 模拟的总任务数据量
int total = 10 * 10000;
// 分片平均处理的数据量
int size = total / shardTotal;
// 分片的开始索引和结束索引
int startIndex = shardIndex * size + 1;
int endIndex = (shardIndex + 1) * size;
if (shardIndex == (shardTotal - 1)) {
// 当是最后一个分片时候结束索引是总任务数据量
endIndex = total;
}
log.info("当前分片:{},分片总数:{},当前分片执行范围:{}~{}", shardIndex, shardTotal, startIndex, endIndex);
}
}
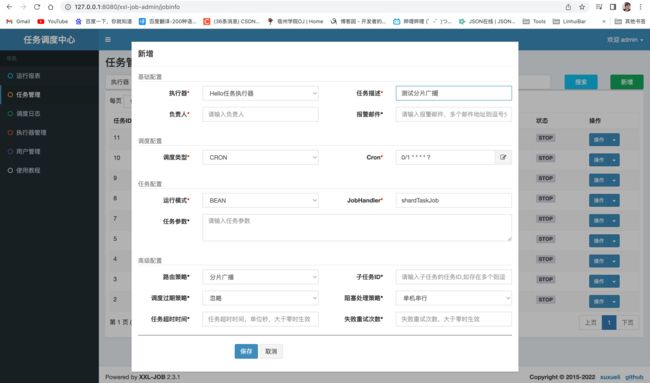
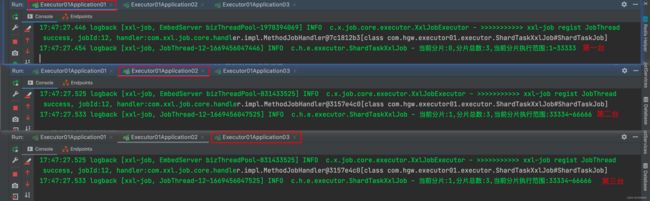
当我们有一个任务需要大批量的去处理时,就可以采用分片广播的模式去执行~
8. 日志回调
日志回调是指执行器在执行任务时可以将执行日志传递给调度中心,即使任务没有执行完成,调度中心也可以看到回调的调度日志内容,便于开发这能够更细化的分析任务的执行情况。
@Slf4j
@Component
public class LogCallbackXxlJob {
@XxlJob("logCallbackTask")
public ReturnT logCallbackTask() {
try {
XxlJobHelper.log("阶段一执行成功");
Thread.sleep(3000);
XxlJobHelper.log("阶段二执行成功");
Thread.sleep(3000);
XxlJobHelper.log("阶段三执行成功");
Thread.sleep(3000);
XxlJobHelper.log("任务执行完毕");
} catch (InterruptedException e) {
e.printStackTrace();
}
return ReturnT.SUCCESS;
}
}
配置完任务后,我们执行任务~
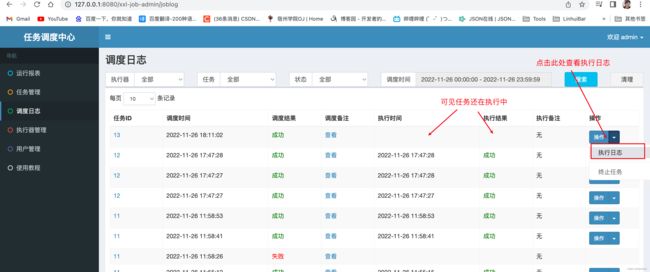
可以看到在我们执行器中执行的日志全部返回至调度中心~

写在最后~
本篇博客初次体验一下Xxl-Job啦,定时任务就到此为止了嘛?
当然不会,让我们在下一篇博客借助源码深入探索其思想吧!从源码角度解读xxl-job的工作流程