pytorch的GPU编程以及cuda,numpy与cuda数据转换方法
环境:Ubuntu 20.04 +pytorchGPU版本
- 一、GPU
-
- 1、查看CPU是否可用
- 2、查看CPU个数
- 3、查看GPU的容量和名称
- 4、清空程序占用的GPU资源
- 5、查看显卡信息
- 6、清除多余进程
- 二、GPU和CPU
-
- 1、GPU传入CPU
-
- 1.1 另一种情况
- 2、CPU传入GPU
- 3、注意数据位置对应
- 三、Numpy和Tensor(pytorch)
-
- 1、Tensor转成Numpy
- 2、Numpy转成Tensor
- 3、Cuda转成Numpy
一、GPU
1、查看CPU是否可用
print (torch.cuda.is_available())
2、查看CPU个数
torch.cuda.device_count()
3、查看GPU的容量和名称
print (torch.cuda.get_device_capability(0))
print (torch.cuda.get_device_name(0))

4、清空程序占用的GPU资源
可以和第6个一起使用,具体细节我也不太了解…
torch.cuda.empty_cache()
5、查看显卡信息
输入命令查看显卡信息,主要看的是中间的Memory-Usage,我的显卡显存是4G的。
下面的PID表示进程代码,如果程序运行完,却仍然占用大量显存,会导致CUDA分配内存不足而报错。nvidia-smi
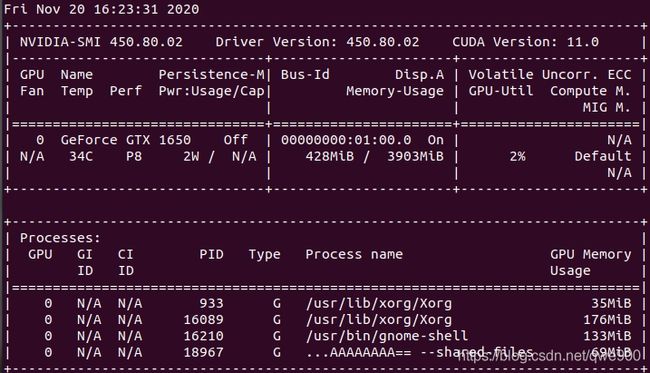
6、清除多余进程
sudo fuser -v /dev/nvidia* #查找占用GPU资源的PID

可以看到很多进程,如果想杀死该进程,需要kill+PID号
如 kill 16210
二、GPU和CPU
1、GPU传入CPU
首先,确认pytorch是GPU版本,然后编写时候传入的量应该为Tensor类型。
import torch
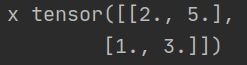
x=torch.Tensor([[2,5],[1,3]])
y=torch.Tensor([[2],[5]])
print('x',x.cuda())
print('y',y.cuda())

x.cuda()实现了将数据拷贝到GPU上,并且显示了设备deice是0号显卡
z=x.mm(y)
print('z',z)
那么z是多少呢?
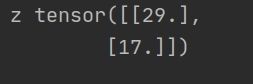
似乎是运算后的结果传入到了CPU中。(默认不显示device为CPU).
1.1 另一种情况
但也不全是这样,具体可能应该查看一下,如做QR分解:
A=torch.Tensor([[2,5],[1,3]])
print('A cpu',A)
A = A.cuda()
print('A cuda',A)
q, r = torch.qr(A)
print('q',q)
print('q',r)
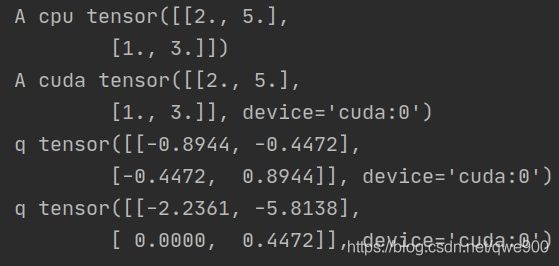
这个时候q和r在GPU里,如果想传入到CPU中,只需q=q.cpu() r=r.cpu()即可。
2、CPU传入GPU
print('x',x.cuda().cpu())
用这种方法数据就传送了回来。总结一下, .cuda() 将CPU的数据传送给GPU,而.cpu()将GPU中的数据传送给CPU
3、注意数据位置对应
如x是CPU的数据,而x_cuda是GPU的数据,因此不能相乘,需要转换。
import torch
x=torch.Tensor([[2,5],[1,3]])
x_cuda=x.cuda()
y=x_cuda.mm(x)
RuntimeError: Tensor for argument #3 ‘mat2’ is on CPU, but expected it to be on GPU (while checking arguments for addmm)
三、Numpy和Tensor(pytorch)
在传送数据的时候,要求是tensor类型,数据的类型需要进行转换。GPU的数据要都和GPU中的做运算,如果有CPU的数据应该进行转换,否则会提示
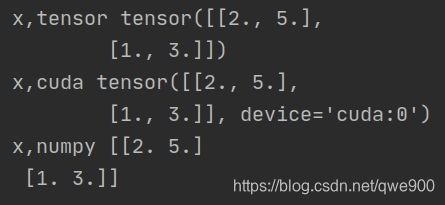
import torch
x=torch.Tensor([[2,5],[1,3]])
print('x,tensor',x)
print('x,cuda',x.cuda())
print('x,numpy',x.numpy())
1、Tensor转成Numpy
只需要x.numpy()即可
2、Numpy转成Tensor
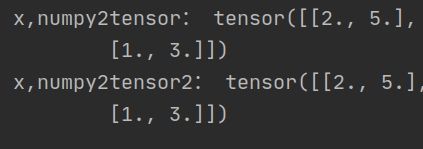
print('x,numpy2tensor:',torch.Tensor(x.numpy()))
可以使用torch.Tensor(),也可以写成torch.from_numpy
print('x,numpy2tensor2:',torch.from_numpy(x.numpy()))
3、Cuda转成Numpy
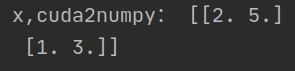
print('x,cuda2numpy:',x.cuda().numpy())

会报错,应该先转换为cpu中再转换为numpy
TypeError: can’t convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
print('x,cuda2numpy:',x.cuda().cpu().numpy())
import torch
x=torch.Tensor([[2,5],[1,3]])
print('x,tensor:',x)
print('x,cuda:',x.cuda())
print('x,numpy:',x.numpy())
print('x,numpy2tensor:',torch.Tensor(x.numpy()))
print('x,numpy2tensor2:',torch.from_numpy(x.numpy()))
print('x,cuda2numpy:',x.cuda().cpu().numpy())
print (torch.cuda.device_count())