Java汉字转拼音实现方式
介绍下Java中实现汉字转拼音的实现方式。
█ Unicode

Unicode就是将各国的文字用一个唯一的不重复的2个字节16进制编码来表示,其中包含了日文、韩文与中文字等等文字。比如汉字:一,Unicode编码为:4e00。则汉字“一”唯一对应的编码为“4e00”,“4e00”唯一表示的字符也为“一”,即“一”与“4e00”是相互对应的。
Unicode字符集:
查看Unicode字符集,请戳《Unicode字符集》
中文的Unicode编码范围:4E00-9FA5
(Unicode不区分大小写,9FA5与9fa5相同)
网页截图示例:
4E00:一;4E01:丁;

█ 汉字转拼音
(1)将Unicode编码与拼音做对应关系
有了Unicode字符集,我们便很容易地就能知道每一个汉字对应的编码了,每个汉字的拼音我们也是知道的,因此便能够得出每一个编码对应的拼音,比如4E00表示汉字“一”,“一”的拼音为“yi”,因此4E00对应"yi"。同理可得4E01对应"ding"。
(2)汉字转拼音
由于Unicode中的字符编码是16进制的,因此我们需要将中文转换成16进制。使用Java提供的API可以完成转换。
①String#toCharArray,将字符串转换成char数组。
②Integer#toHexString,将char转换成16进制。
String str = "你好,中国";
char[] charArray = str.toCharArray();
StringBuilder sb = new StringBuilder();
for (char c : charArray) {
String string = Integer.toHexString(c);
sb.append(string).append(" ");
}
System.out.println("Unicode编码为:"+sb.toString());
可以验证下输出的结果是否正确,去Unicode表中查询“你好,中国”对应的编码是否为输出结果。




③找到Unicode对应的拼音
我们简单地维护下“你好中国”四个字的Unicode对应的拼音。
使用Map来维护Unicode对应的拼音,Map的key为Unicode编码,value为其对应的拼音。(这里的Unicode为全小写,转换的时候要注意对应,否则匹配不上)
public static Map map = new HashMap<>();
static {
map.put("4f60", "ni");
map.put("597d", "hao");
map.put("4e2d", "zhong");
map.put("56fd", "guo");
} String str = "你好,中国";
char[] charArray = str.toCharArray();
StringBuilder sb = new StringBuilder();
for (char c : charArray) {
// 因为我维护的Unicode编码都是小写的,所以这里统一转小写以便匹配
String unicode = Integer.toHexString(c).toLowerCase();
String pinyin = map.get(unicode);
if (pinyin != null) {// 可以查询对应的拼音
sb.append(pinyin);
} else {// 查询不到对应的拼音,比如字符不是中文等
sb.append(c);
}
}
System.out.println("拼音为:"+sb.toString());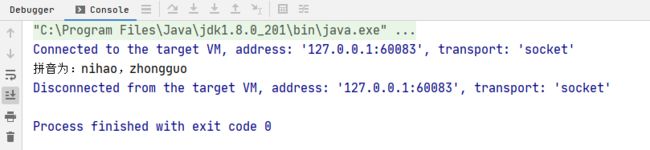
④源字符串要为UTF-8编码
对于例子中的“你好,中国”字符串,需要为UTF-8编码,否则会出现乱码,对应的Unicode值就不对的。(String对象创建时可以指定编码,不指定则使用默认编码UTF-8)
String str1 = new String("你好".getBytes());
String str2 = new String("你好".getBytes(), Charset.forName("GBK"));
System.out.println("str1="+str1);
System.out.println("str2="+str2);
char[] charArray1 = str1.toCharArray();
String str1Unicode = "";
for (char c : charArray1) {
str1Unicode+=Integer.toHexString(c);
}
System.out.println("str1 unicode="+str1Unicode);
char[] charArray2 = str2.toCharArray();
String str2Unicode = "";
for (char c : charArray2) {
str2Unicode+=Integer.toHexString(c);
}
System.out.println("str2 unicode="+str2Unicode);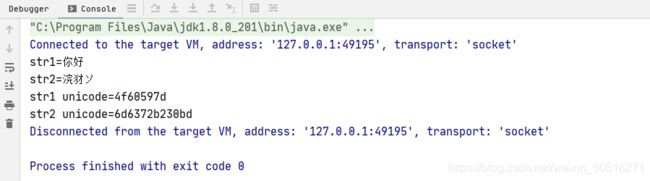
问题:
(1)对于多音字如何解决?
比如音乐、快乐。在“音乐”中,“乐”的拼音为“yue”;在“快乐”中,“乐”的拼音为“le”。乐的发音不同,如何能匹配到正确的发音对应的拼音呢?难道不会使用穷举法将多音字的所有词组的正确发音都列举出来吧,比如“音乐”记录成“yinyue”,“快乐”记录成“kuaile”。
总结:
汉字转拼音,就是借助Unicode编码,汉字与Unicode存在关系,汉字和拼音也存在关系,所以Unicode编码也与拼音存在关系。维护Unicode与拼音的对应关系。转换的时候,将汉字转Unicode,根据Unicode与拼音的对应关系可以找到其对应的拼音,这样自然就找到了汉字对应的拼音了。
推荐一个Java工具包,里面有汉字转拼音的工具类。不过它貌似也没有解决多音字的问题。
com.belerweb
pinyin4j
2.5.0
其在文件中维护了Unicode与拼音的关系,如下所示。最后的数字表示拼音的声调,比如ling2,则表示ling,第二声。
3007 (ling2)
4E00 (yi1)
4E01 (ding1,zheng1)
4E02 (kao3)
4E03 (qi1)
4E04 (shang4,shang3)
4E05 (xia4)
4E06 (none0)