Linux系统编程:编译过程以及GDB调试
编译工具链SDK(Software Development Kit)
在windows下编写程序,我们通常会用IDE,比如idea、vs等,这些工具将编译链接什么的全都暗地里解决好了我们只要写程序就行,但很明显,在Linux系统下做不到。
在Linux中,我们使用SDK来完成这些事情,共有两大派系:GCC和Clang。
工作当中一般是公司项目组选择哪个就用哪个。
其中,GCC是用的最多的。

使用GCC -v来查看版本信息,也可以用来查看自己是否安装了GCC:

其中Target: x86_64-linux-gnu表示gcc的目标平台架构。
Thread model:posix;表示gcc的线程模型遵从posix标准。
然后最下面一行:gcc version 11.2.0 (Ubuntu 11.2.0-19ubuntu1)表示gcc的版本信息。
代码执行编译过程

我们编写的.h和.c代码通过预处理后称为以.i结尾的预处理后的文件(此时依然是C语言),然后该文件经过编译成为.s汇编文件(此时就是汇编语言了),汇编文件经过汇编处理后成为目标文件(即.o文件,就是纯机器语言),最后经过OS引导和库函数链接之后称为以*号结尾的可执行文件(这是Linux系统下的文件表示)。
其中从预处理开始到成为目标文件这一段过程称为广义上的编译。
执行编译过程详解
预处理
作用:执行预处理指令
如:#include文件包含,#define M 5宏定义(简单的文本替换),#define SIZE(a)(sizeof(a)/sizeof(a[0]))宏函数等。
接下来我们介绍一些其它的预处理指令。
预处理指令,宏开关:#if [#else] #endif
我们写一个hello world:
1#include <stdio.h>
2
3 int main(){
4 #if 0
5 printf("hello world\n");
6 #else
7 printf("hello kitty\n");
8 #endif
9 return 0;
10 }
然后我们使用下面的指令来进行预处理的过程:
![]()
gcc -o是一个命令行选项,它告诉GNU编译器(gcc)将编译器输出的可执行程序文件命名为指定的名称,o是output的意思。
gcc -E是一个命令行选项,它告诉GNU编译器(gcc)只执行预处理器并输出预处理器的结果,而不进行编译、汇编和链接等操作。因此,它可以用来查看程序中的宏定义、条件编译指令等预处理指令的展开结果,以及包含文件的内容等。
gcc -E hello.c -o hello.i是一个命令行选项,它告诉GNU编译器(gcc)只执行预处理器并将预处理器的输出写入到名为hello.i的文件中。这个操作不会将源代码编译成可执行文件,而是将源代码中的宏定义、条件编译指令等预处理指令展开成实际的代码,并将所有包含的头文件内容插入到相应的位置。这个过程可以帮助开发者查看源代码的预处理结果,以便更好地理解程序的工作原理。
接下来我们就可以进hello.i文件进行查看预处理后文件是个什么样子:
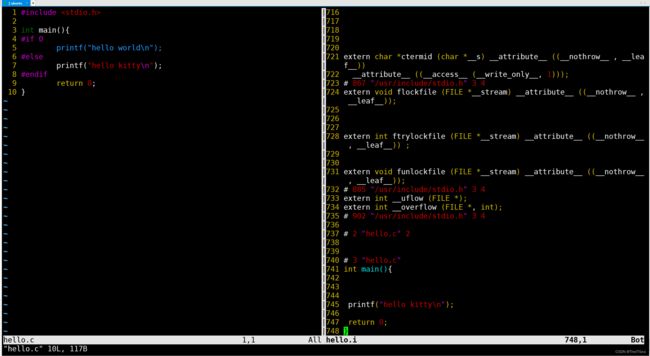
使用vim的vnew命令来左右分屏查看,用大写G命令直接切到.i文件的最后一行进行对比查看,如上图所示。
可以看到在左边.c文件中我们使用的有预处理指令 if 0 ,在预处理过程中会执行该指令,因为为0表示false所以预处理之后if 0后面的代码就不存在了,这种情况就称为宏开关。
与之类似的还有如下预处理指令,比该指令要稍微常用,通常叫条件编译:
#ifdef N [#else] #endif //else是可选的
来试一下这个事情:
1#include <stdio.h>
2
3 int main(){
4 #ifdef N
5 printf("hello world\n");
6 #else
7 printf("hello kitty\n");
8 #endif
9 return 0;
10 }
再通过上面的预处理指令来查看一下现在的情况:
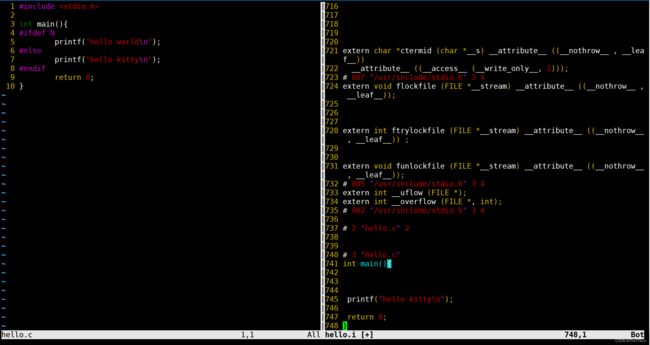
因为我们并没有定义N这个东西,所以在预处理过程中依然是只显示了“hello kitty”。
我们定义宏的时候一般不会写死这个N,往往是在预处理的中途进行该宏的定义,使用参数-D即define的意思来对N进行宏定义:
![]()
可以看见此时再查看情况就不同了:
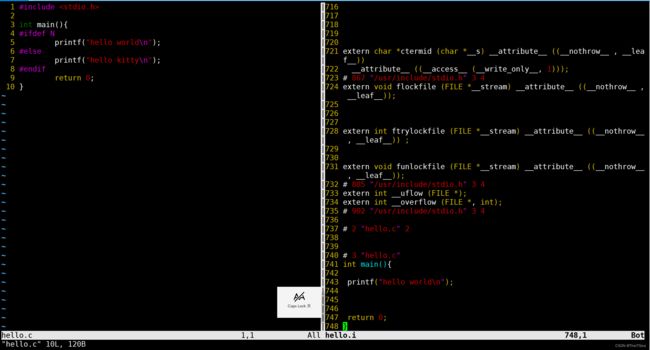
这是因为我们在预处理时进行了N的宏定义,#ifdef N 条件为真。
这样做的好处就是可以进行条件编译,为不同的目标平台生成不同的代码。
与之相同的还有ifndef:
#ifndef [#else] #endif
就是和上面ifdef相反的,即if not def。
常见的用法如下:

上图意思就是如果没有定义 _FOO_H_的话,那么我就执行下面的语句直到endif结束。
这种方式经常用来作防御式声明,作用是避免重复包含多个头文件,也就是上图中的形式。
(狭义)编译过程
作用:将C语言代码编译成汇编代码。
来验证这个事情,首先准备一个hello.c的简单C代码:
1 #include <stdio.h>
2
3 int main(void){
4 printf("hello world\n");
5 return 0;
6 }
下面是两种编译方式:
第一种是编译我们上面所使用过的那种先被预处理后的文件,将其编译成我们的汇编代码:

gcc -S是一个命令行选项,它告诉GNU编译器(gcc)只执行编译操作,生成汇编代码而不是可执行文件。编译器会将源代码编译成汇编代码,然后将汇编代码写入到一个文件中。在生成汇编代码后,你可以使用汇编器将其转换为机器码,然后创建可执行文件。
第二种方式是直接根据源代码编译成汇编代码:
![]()
.s就是汇编代码的文件后缀名。
然后来查看汇编代码:
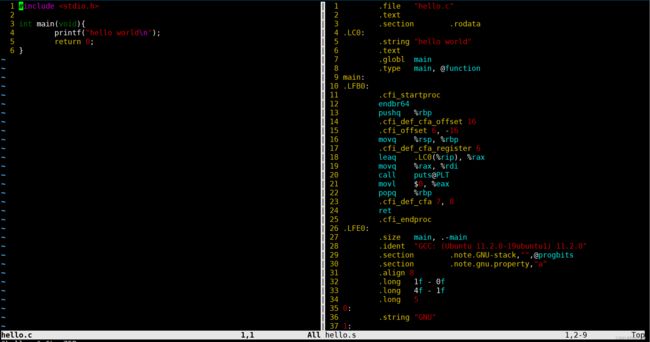
这就是一个编译过程,有时间也可以去学习一下汇编语言(狗头),然后对照着看一下就能发现底层汇编到底在干什么了。
这只是帮助我们大概了解一下。不懂也没事,不影响接下去的学习。
但上述这两种方式都是狭义上的编译,也就是从.c文件到.s汇编文件的编译。
有一种最常用的针对广义编译的命令,可以直接生成.c对应的.o目标文件:
(广义)编译命令:gcc -c
使用该命令可以直接生成.c对应的.o目标文件:
链接过程
这个不是很重要,就了解一下即可。
如果想深入了解可以看《程序员的自我修养》,它的英文版叫《Linked & Loader》。
链接做的最朴素的事情就是把调用函数的名字转换成对应的内存地址。
观察过汇编的代码就会发现在函数调用中,都是使用call指令加上函数名的方式,当call指令执行时会去分配一个对应的内存地址给该函数名,而什么时候会去分配呢?就是在链接的时候才会分配,所以链接过程必不可少。
可执行程序
在Linux系统拥有x权限的程序就是可执行程序,怎么执行呢?
只要输入其对应的路径即可,但是如果是在可执行程序所在的当前路径下的话,需要用 ./可执行程序名 来执行。
使用./的形式是为了避免其可能会与系统内部所存在的一些内置命令冲突。
库文件
库文件也就是轮子,是一种公用的工具。
可以认为这是一种特殊的.o文件,是别人写好的我们拿来用的工具。
库文件的文件名后缀为.a或者 .so,这是两种库文件,分别对应着静态库和动态库;
轮子打包到产品中,这是静态库,比如一般的汽车,轮子都是附带着一起被购买来用的。
而轮子在运行的时候才加入到产品中,就是动态库,比如F4方程式赛车,都是现场更换。
特点:
从产品大小来看,静态库比较大,动态库比较小
从部署难度说,静态库容易,动态库难
从升级角度看,静态库难,动态库容易
生成静态库
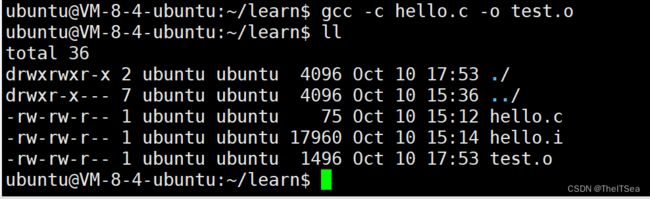
先来看这么一个例子,文件名为test.c:
1 #include <stdio.h>
2
3
4 int add(int a,int b);
5
6 int main(){
7 printf("add(3,4) = %d\n",add(3,4));
8 }
编译肯定没问题,因为我们没有语法错误,但是链接不了,因为add函数未定义:
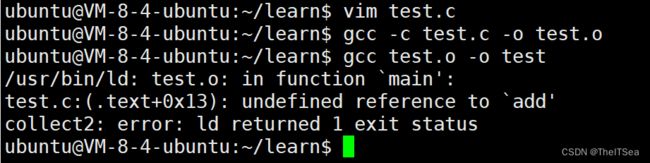
那我们在另外一个文件里写add.c:
1 int add(int a,int b){
2 return a + b;
3 }
这个文件一样可以编译,但是链接不了,因为没有main函数:

但此时我们可以将它们俩合在一起,也就是链接在一起,把两个.o文件链接在一起称为一个可执行程序:

此时test就可以运行了。
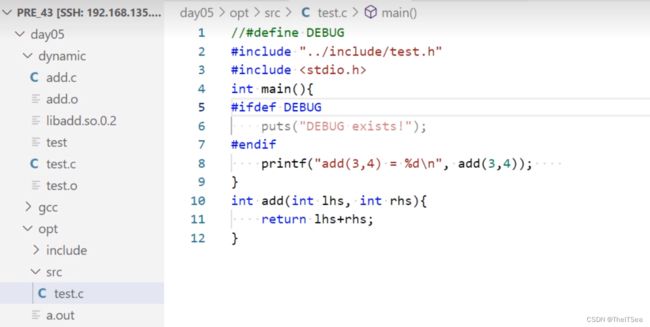
但是目前这个add.o只能我们自己用,我们想把它变成共享的,怎么做?
首先,不管怎么样做,这个add.o文件我们肯定是需要的,源码文件肯定是不公开的,我们选择分享add.o文件。
生成目标文件命令:gcc -c add.c -o add.o
然后第二件事情就是去把这个add.o文件打包成静态库,打包命令是固定的用法,直接用就可以:
ar crsv LibName.a add.o
//libName是打包后的库文件名,注意lib开头是固定的,中间add名字是可以换的,后缀为.a也是固定的,然后add.o是我们要打包的目标文件名
我们来试一下:

然后我们将该库文件移动到系统搜索目录下:/usr/lib
来试一下:

来看一下是否存在了:

现在我们进行链接就没有之前这么麻烦了,使用-l参数来指定所需的库文件就可以了,-l后面跟库文件名:

因为是静态库,所以现在哪怕将该库文件删除了,执行刚刚生成的可执行文件一样可以运行,这就是静态库。
小技巧:配置超好用Linux的vim环境
配置这个只需要装一个vimplus即可,具体可以看这个博客链接:
配置vimplus超好用c/c++编辑器
网上资源很多,这个应该搞得定吧哈哈哈。
生成动态库
之前我们已经直到单独链接test.c文件肯定是会出错的,因为main里面并没有定义add函数。
这里我们使用动态库来链接,动态库是在程序运行时才加载到内存中来运行的,动态库和静态库区别如下:
静态库是在链接阶段就链接到数据/代码段中的(这是个静态区),而动态库因为是在程序运行时才加载到内存中所以会被存放在栈空间和堆空间的某个区域,叫共享库映射区(即动态库也叫共享库),即然是共享那就意味着另外的程序事实上也可以使用该库,但此时存在一个问题就是不同的程序在加载时所在的内存地址是不一样的,可众所周知,在程序当中的各个指令的地址肯定都是相对地址不是绝对地址,即位置无关的代码,所以我们在编译动态库的时候必须加上-fpic:
-fpic 是 GCC 编译器的一个选项,表示编译生成与位置无关的代码(Position Independent Code)。这种代码可以被加载到内存的任何位置,并且不影响其正确性。这在编写共享库等时非常有用。
当使用 -fpic 选项编译时,会生成 PIC 代码。而使用 -fPIC 选项时,会生成更严格的 PIC 代码,这意味着生成的代码可以在更多的情况下使用,但可能会稍微降低性能。
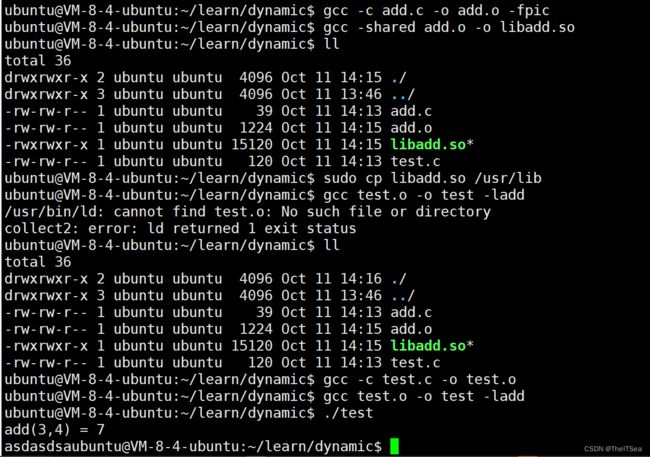
所以生成动态库步骤如下:
1、编译生成相关文件
gcc -c add.c -o add.o -fpic
2、打包
gcc -shared add.o -o libadd.so(lib前缀和.so后缀都是确定的,动态库名字是可以随意取的)
3、移动到系统库目录
sudo cp libadd.so /usr/lib
4、链接的时候加上 -ladd
gcc -test.o -o test -ladd
我们可以来试一下将我们的add.c来生成动态库:
分开编译,链接的时候要一起嗷。
还可以通过ldd命令查看动态库的链接过程:

ldd只能显示动态链接,无法显示静态链接。
对于动态库,如果将动态库删除,那么该test程序将无法执行:
![]()
如果我们将该文件又复原,会发现该程序又可以正常运行:

这说明对于动态库来说,在每次执行程序时都会去系统库函数目录下寻找它所需要的库函数,在运行时进行加载以获得运行支持。
此时若我们对add库函数文件进行更新:
1 int add(int a,int b){
2 return a + b + 1;
3 }
然后重新进行动态库生成:
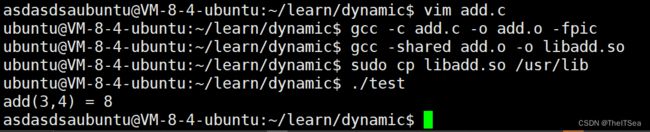
从上图可以知道我们并没有进行程序的重新链接,只是更新了对应的库函数就能够实现更新代码后的结果。
所以动态库更新是更容易的相较于静态库而言,这也就是热更新的原理。
但这种热更新会带来一个新的问题,就是万一更新完出了问题,我们怎么回滚到原来的正常运行状态呢?
这个时候一个非常好的做法是将/usr/lib文件下面我们链接时指定的文件名libadd.so文件改成软链接,让其动态的根据需要指向我们想要进行动态链接的一个真正的libadd.so:
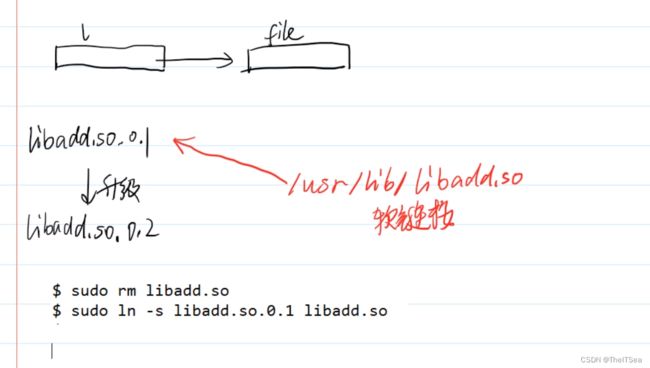
所以我们可以给每一次生成的库函数分别标上一个版本号ID,然后想用哪个版本的时候就让我们的libadd.so软链接指向它即可实现回滚的功能:

上图是我们想要更换版本了,就删除原来的软链接,再新建一个同名软链接指向我们的新版本库函数文件即可。
gcc的其它选项
-D 编译时进行宏定义
当使用gcc编译时使用该参数,就相当于是在代码中进行宏定义:
![]()
-I 编译时增加搜索路径
编译时增加搜索路径:

上面第一次编译找不到"test.h",因为这么写默认是在当前目录下进行寻找该头文件,如果不加-I也可以手动修改代码,把路径补全即可:
像上面这样也是没问题的。
-O 进行编译优化
注意该参数后面要跟数字,比如-O0,-O1等等。
该参数将进行编译优化,编译器作者会在底层进行修改顺序和内存位置,这样做结果不会改变(编译器会保证这一点)但指令数量变少了且执行速度变快,代价就是你写的代码在进行单步调试时会很麻烦,因为结构和一开始写的不一样了。
注意-O后面跟的数字越大,则意味着优化的深度越深,C和汇编的对应关系对应不上的风险大大增加(-O0表示不开优化)。
工作中用-O0和-O1都没问题,但发布产品的时候都使用-O1.
-Wall 让编译器给出编译警告
在Linux系统中,出现警告一定要重视,这往往是最后出现问题的根源。

GDB调试(必会)

GDB使用前提:
首先不能开编译优化,其次要补充调试信息,为什么要补充调试信息?
之前我们聊到汇编的时候说过,在汇编代码中变量什么的是没有名字的,但调试的时候肯定是要知道变量名字的呀,所以必须要把调试信息补充上,这一点通过-g参数可以实现。
这里我们写一个C语言文件来进行学习:
1 #include <stdio.h>
2
3 void func(int i){
4
5 printf("I am func , i = %d\n",i);
6 }
7
8 int main(){
9
10 int j = 10;
11
12 int arr[3] = {1,2,3};
13
14 int *p;
15 arr[2] = 4;
16 p = arr;
17
18 fun(j);
19
20 for(int i=0;i < 5; i++){
21 puts("hello world");
22 }
23 return 0;
24 }

现在编译完成,启动gdb进行调试:
使用gdb加文件名的方式启动调试,如上图所示,这就表示进入了gdb命令行的意思。
list或l命令打印源码语句
注意list命令后面可以跟数字参数表示从第几行开始展示,每次展示十行:
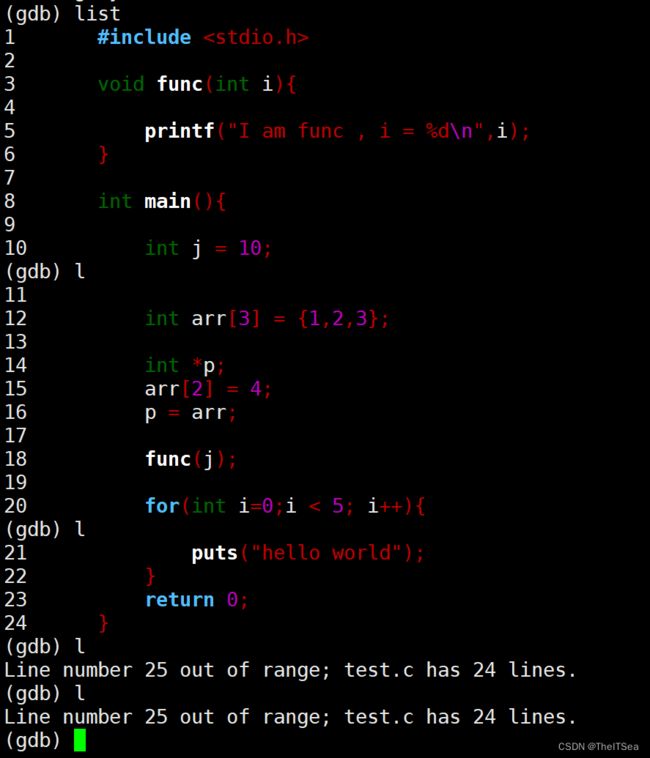
除了可以跟行号,list命令后面还可以跟文件名冒号行号,这可以在多文件gdb调试中用来切换所要调试的文件:
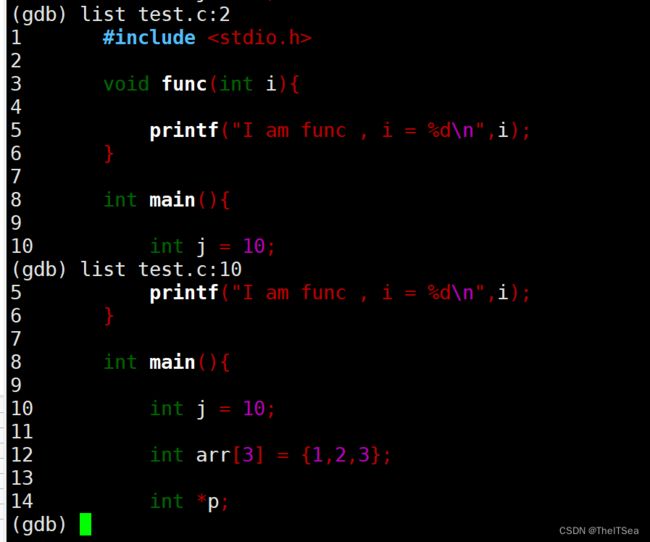
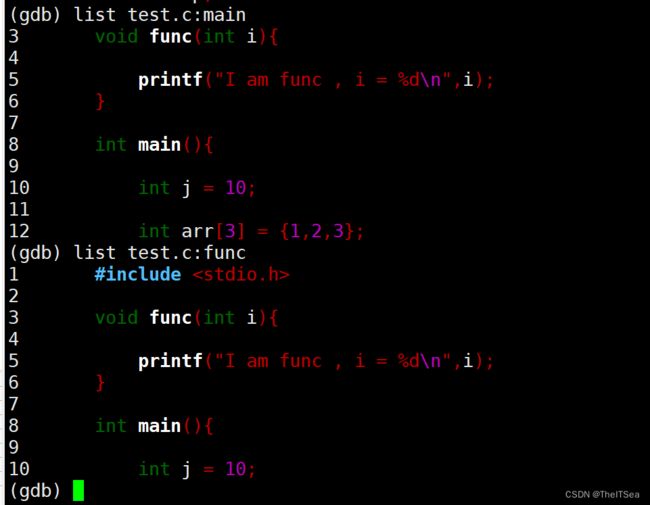
也可以后面跟函数名,就可以定位到函数名位置:
run或者r运行程序
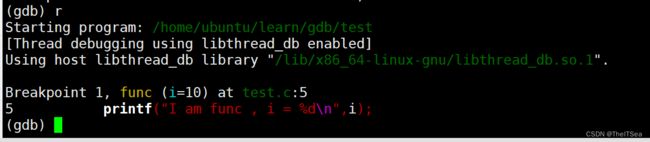
break或者b打断点
可以选择在第几行打,也可以选择在哪个函数位置打:

现在我们再运行程序就会运行到我们所打的断点位置停下:
continue或者c继续运行程序
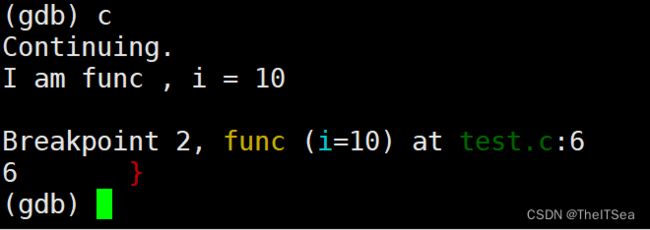
step/s 单步调试无法跳过函数调用
我们来使用step,发现会下一步会进入到puts函数调用:
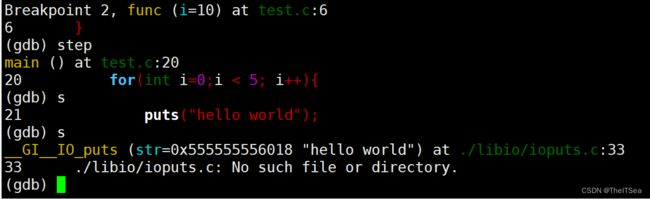
finish直接让程序运行到该函数运行完为止

next/n 单步调试会将下次函数调用跳过
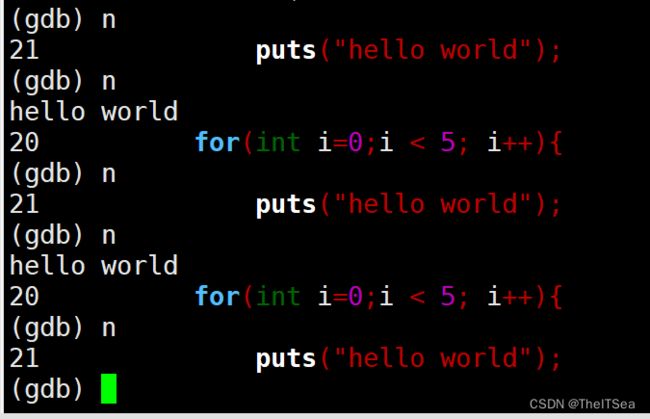
可以看见直接跳过了puts函数的深层调用,就可以清晰的看见循环过程。
info break / i b查看断点信息

从上图可以看到,两个断点都分别命中了一次。
delete num 删除指定断点,num是对应的断点信息

如果delete后面不跟参数,那就是默认删除所有断点。
ignore [bpNum] [ignoreTimes]忽略某断点多少次
如果当我们遇到了循环次数很大的这种情况使用单步调试的话手都会按断,所以ignore可以帮我们忽略掉循环次数。
bpNum是断点编号,ignoreTimes是忽略次数。
在GDB当中去查看监视
print 或者 p打印数据
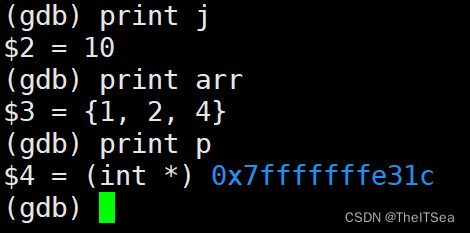
事实上print可以打印任意的合法表达式:
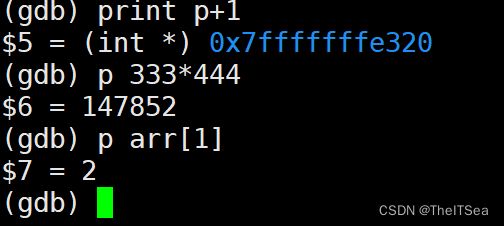
有了print命令我们就可以结合next命令实现一步一打印的效果,但是这样太繁琐了,所以我们这里有个新的命令用来代替这种繁琐的事情。
display 自动打印
display后面跟一个表达式,表示需要开启自动打印的内容:

那开启了怎么关呢?首先我们需要先打印一下display的信息。
info display 展示display信息

undisplay dNo 停止自动打印
dNo表示需要停止的内容编号:
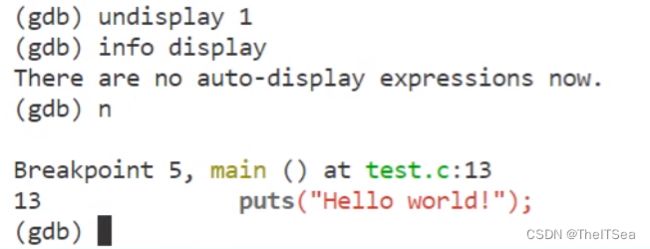
可以看到后面就不再有自动打印了。
在GDB中去查看内存
在gdb中查看内存借助x指令:
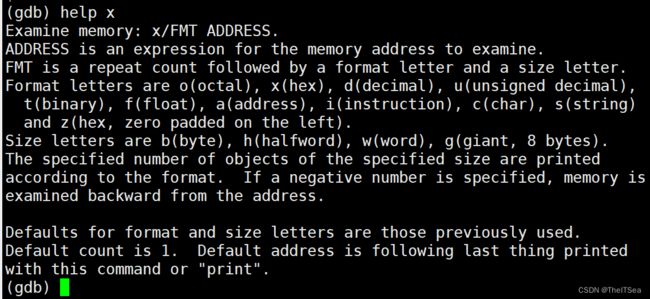
看完上图大致能得出几个结论。
首先查看内存的命令形式:x/FMT address.
所谓的FMT就是有三个部分组成的:
第一个部分是repeat count是个数字,第二个是个format letter字母格式,第三个是个大小字母。
即第一个部分数字表示看多少个单位;
第二个字母格式表示用什么进制格式来查看,o表示八进制,x表示十六进制,d表示十进制,u表示无符号十进制。
第三个大小则表示每个单位的大小,b表示字节,h表示两个字节,w表示四个字节,g表示八个字节。
查看数组arr的内存信息:
![]()
这表示看3个单位的arr数组的内存信息,然后每个单位的内存内容用二进制来表示,每段二进制用四个字节来展示。
正好展示的内容就是数组arr的内容{1,2,4}
在GDB中检查崩溃的程序
core文件:程序中的“黑匣子”
core文件存储了当程序崩溃时整个程序运行的内存的堆栈情况。
来写段会崩溃的代码试一下,使用quit命令可以退出gdb:
1 int main(){
2
3 int* p = 0 ;
4 //这里没有给指针具体的地址
5 //就进行解引用的操作是肯定报错的
6 *p=1;
7
8 }
然后我们去编译运行这段代码:

可以看见段发生错误然后core dumped,表示core文件已经存储起来了。
但是我们这里现在看不到,因为在Linux中OS会限制这个core file的一个大小,因为往往这个文件都会非常非常大,我们可以用ulimit -a来查看当前系统中的所有被限制了的内容:
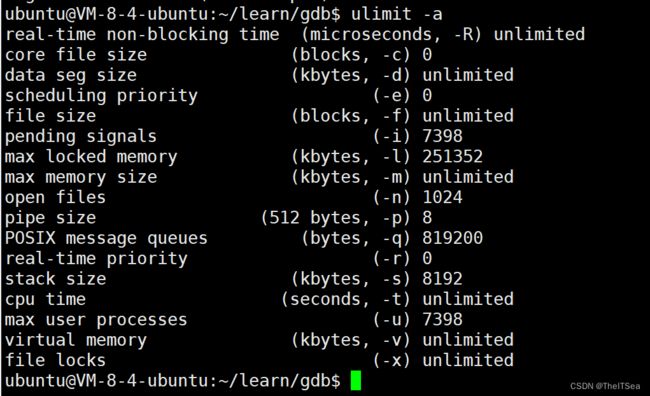
可以看到core file size 大小默认为0,当然看不到了,所以我们将其设置一下改为无限大:
![]()
注意这个大小的设置是临时的只能影响到当前终端,哪怕换个终端那么这个设置也就失效了,重新登录自然也是会失效的。
如果进行该操作之后发现还是无法生成core文件的话,就进行下面的操作:

注意上面是切换成了root用户才进行的该操作嗷,那么现在我们再执行报错的程序来看是否存在core文件了(注意要切换回普通用户再执行嗷):

可以看见此时的core文件已经出现。
这个时候就可以使用下面的命令进行gdb的查看:

可以清楚的看见是在第六行*p=1这一行出错了。
同时我们也可以使用bt命令去查看堆栈的情况:

GDB打印命令行参数
我们经常会按如下方式启动程序:
1 #include <stdio.h>
2
3 int main(int argc,char* argv[]){
4
5 printf("argc = %d\n",argc);
6
7 for(int i=0;i<argc; i++){
8 puts(argv[i]);
9 }
10 }
编译运行如下:
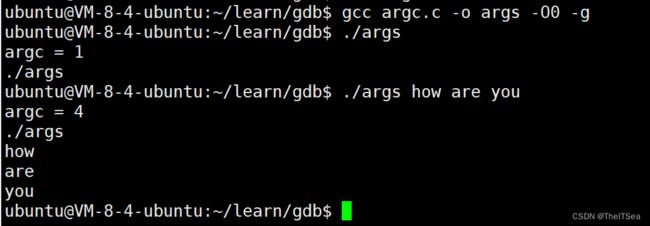
在第一次调用中,因为没有其它的命令行参数,所以命令行参数只有./args(也就是它自己)。
在第二次调用中我们设置了how are you 三个参数,所以打印如上图所示,这就是打印命令行参数。
用gdb启动也是类似:
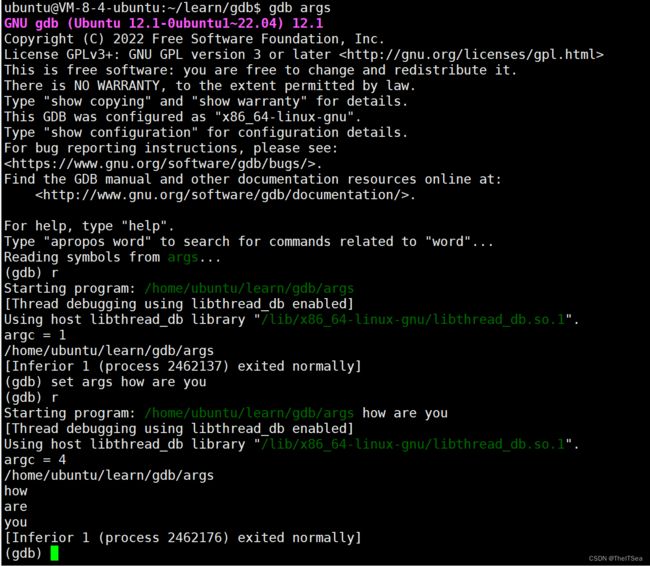
除了可以用set去设置命令行参数,也可以用show args去显示命令行参数信息:

总结
本文简述了程序编译链接运行的流程,然后学习了GDB调试,后面这个GDB调试非常重要,必须要很熟嗷。