SOFAJRaft 日志复制共识算法
文章目录
-
- 基本概念说明
- 整体架构
- 请求调用流程
- 1. 核心组件
-
- 1.1 Node
- 1.2 存储
- 1.3 状态机
- 1.4 复制
- 1.5 RPC
- 2. 配置和辅助类
-
- 2.1 地址 Endpoint
- 2.2 节点 PeerId
- 2.3 配置 Configuration
- 2.4 工具类 JRaftUtils
- 2.5 回调 Closure 和状态 Status
- 2.6 任务 Task
- 3. 服务端
-
- 3.1 迭代器 Iterator
-
- Iterator 实现类 - IteratorWrapper
-
- 核心方法
-
- 获取任务数据 - getData() 方法
- Iterator 具体实现类 - IteratorImpl
-
- 核心方法
-
- 获取日志数据 - entry() & next()
- 3.2 状态机 StateMachine
- 3.3 Raft 节点 Node
- 3.4 RPC 服务
-
- RPC 服务器 - RPCServer
- RPC 服务器服务 - RaftServerService
-
- 核心方法
- RPC 服务器服务实现类 - NodeImpl
- 3.5 框架类 RaftGroupService
- 3.6 Snapshot 服务
- 4. 客户端
-
- 4.1 路由表 RouteTable
- 4.2 CLI 服务
- 4.3 RPC 服务
-
- AppendEentries RPC 请求 - AppendEntriesRequest
- RPC 客户端服务 - RaftClientService
-
- 核心方法
官网: https://www.sofastack.tech/projects/sofa-jraft/overview/
基本概念说明
- log index 提交到 raft group 中的任务都将序列化为一条日志存储下来,每条日志一个编号,在整个 raft group 内单调递增并复制到每个 raft 节点。
- term 在整个 raft group 中单调递增的一个 long 数字,可以简单地认为表示一轮投票的编号,成功选举出来的 leader 对应的 term 称为 leader term,在这个 leader 没有发生变更的阶段内提交的日志都将拥有相同的 term 编号。
整体架构

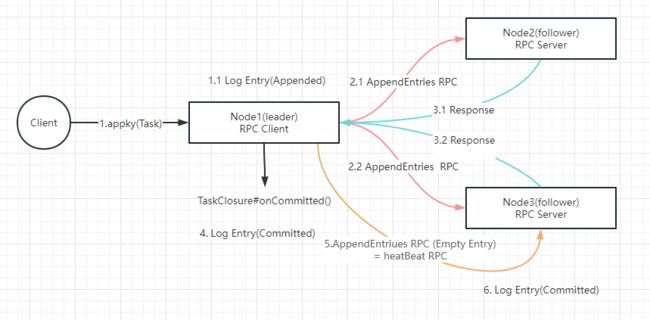
请求调用流程
1. 核心组件
1.1 Node
Raft 分组中的一个节点,连接封装底层的所有服务,用户看到的主要服务接口,特别是 apply(task) 用于向 raft group 组成的复制状态机集群提交新任务应用到业务状态机。
1.2 存储
- Log 存储,记录 raft 配置变更和用户提交任务的日志,将从 Leader 复制到其他节点上。LogStorage 是存储实现, LogManager 负责对底层存储的调用,对调用做缓存、批量提交、必要的检查和优化。
- Meta 存储,元信息存储,记录 raft 实现的内部状态,比如当前 term,、投票给哪个节点等信息。
- Snapshot 存储,,用于存放用户的状态机 snapshot 及元信息,可选。 SnapshotStorage 用于 snapshot 存储实现, SnapshotExecutor 用于 snapshot 实际存储、远程安装、复制的管理。
1.3 状态机
StateMachine: 用户核心逻辑的实现,核心是 onApply(Iterator) 方法,应用通过 Node#apply(task) 提交的日志到业务状态机。
FSMCaller: (Finite State Machine),封装对业务 StateMachine 的状态转换的调用以及日志的写入等,一个有限状态机的实现,做必要的检查、请求合并提交和并发处理等。
Finite State Machine:有限状态机,有限的状态,比如 Raft 中有三个状态,Leader、Candidate、Follower
1.4 复制
- Replicator: 用于 leader 向 follower 复制日志,也就是 raft 中的 appendEntries 调用,包括心跳存活检查等。
- ReplicatorGroup: 用于单个 RAFT Group 管理所有的 replicator,必要的权限检查和派发。
1.5 RPC
RPC 模块用于节点之间的网络通讯: 1. RPC Server: 内置于 Node 内的 RPC 服务器,接收其他节点或者客户端发过来的请求,转交给对应服务处理。 2. RPC Client: 用于向其他节点发起请求,例如投票、复制日志、心跳等。
2. 配置和辅助类
本节主要介绍 jraft 的配置和辅助工具相关接口和类。核心包括:
- Endpoint 表示一个服务地址。
- PeerId 表示一个 raft 参与节点。
- Configuration 表示一个 raft group 配置,也就是节点列表。
2.1 地址 Endpoint
Endpoint 表示一个服务地址,包括 IP 和端口, raft 节点不允许启动在 0.0.0.0 所有的 IPv4 上,需要明确指定启动的 IP 创建一个地址,绑定在 localhost 的 8080 端口上,如下例:
Endpoint addr = new Endpoint("localhost", 8080);
String s = addr.toString(); // 结果为 localhost:8080
PeerId peer = new PeerId();
boolean success = peer.parse(s); // 可以从字符串解析出地址,结果为 true
2.2 节点 PeerId
PeerId 表示一个 raft 协议的参与者(leader/follower/candidate etc.), 它由三元素组成: ip:port:index, IP 就是节点的 IP, port 就是端口, index 表示同一个端口的序列号,目前没有用到,总被认为是 0。预留此字段是为了支持同一个端口启动不同的 raft 节点,通过 index 区分。
创建一个 PeerId, index 指定为 0, ip 和端口分别是 localhost 和 8080:
PeerId peer = new PeerId("localhost", 8080);
Endpoint addr = peer.getEndpoint(); // 获取节点地址
int index = peer.getIdx(); // 获取节点序号,目前一直为 0
String s = peer.toString(); // 结果为 localhost:8080
boolean success = peer.parse(s); // 可以从字符串解析出 PeerId,结果为 true
2.3 配置 Configuration
Configuration 表示一个 raft group 的配置,也就是参与者列表:
PeerId peer1 = ...
PeerId peer2 = ...
PeerId peer3 = ...
// 由 3 个节点组成的 raft group
Configuration conf = new Configuration();
conf.addPeer(peer1);
conf.addPeer(peer2);
conf.addPeer(peer3);
2.4 工具类 JRaftUtils
为了方便创建 Endpoint/PeerId/Configuration 等对象, jraft 提供了 JRaftUtils 来快捷地从字符串创建出所需要的对象:
Endpoint addr = JRaftUtils.getEndpoint("localhost:8080");
PeerId peer = JRaftUtils.getPeerId("localhost:8080");
// 三个节点组成的 raft group 配置,注意节点之间用逗号隔开
Configuration conf = JRaftUtils.getConfiguration("localhost:8081,localhost:8082,localhost:8083");
2.5 回调 Closure 和状态 Status
Closure 就是一个简单的 callback 接口, jraft 提供的大部分方法都是异步的回调模式,结果通过此接口通知:
public interface Closure {
/**
* Called when task is done.
*
* @param status the task status.
*/
void run(Status status);
}
结果通过 Status 告知,Status#isOk() 告诉你成功还是失败,错误码和错误信息可以通过另外两个方法获取:
boolean success= status.isOk();
RaftError error = status.getRaftError(); // 错误码,RaftError 是一个枚举类
String errMsg = status.getErrorMsg(); // 获取错误详情
Status 提供了一些方法来方便地创建:
// 创建一个成功的状态
Status ok = Status.OK();
// 创建一个失败的错误,错误信息支持字符串模板
String filePath = "/tmp/test";
Status status = new Status(RaftError.EIO, "Fail to read file from %s", filePath);
2.6 任务 Task
Task 是用户使用 jraft 最核心的类之一,用于向一个 raft 复制分组提交一个任务,这个任务提交到 leader,并复制到其他 follower 节点, Task 包括:
- ByteBuffer data 任务的数据,用户应当将要复制的业务数据通过一定序列化方式(比如 java/hessian2) 序列化成一个 ByteBuffer,放到 task 里。
- long expectedTerm = -1 任务提交时预期的 leader term,如果不提供(也就是默认值 -1 ),在任务应用到状态机之前不会检查 leader 是否发生了变更,如果提供了(从状态机回调中获取,参见下文),那么在将任务应用到状态机之前,会检查 term 是否匹配,如果不匹配将拒绝该任务。
- Closure done 任务的回调,在任务完成的时候通知此对象,无论成功还是失败。这个 closure 将在 StateMachine#onApply(iterator) 方法应用到状态机的时候,可以拿到并调用,一般用于客户端应答的返回。
创建一个简单 Task 实例:
Closure done = ...;
Task task = new Task();
task.setData(ByteBuffer.wrap("hello".getBytes()));
task.setDone(done);
任务的 closure 还可以使用特殊的 TaskClosure 接口,额外提供了一个 onCommitted 回调方法:
public interface TaskClosure extends Closure {
/**
* Called when task is committed to majority peers of the RAFT group but before it is applied to state machine.
*
* Note: user implementation should not block this method and throw any exceptions.
*/
void onCommitted();
}
当 jraft 发现 task 的 done 是 TaskClosure 的时候,会在 RAFT 日志提交到 RAFT group 之后(并复制到多数节点),应用到状态机之前调用 onCommitted 方法。
3. 服务端
本节主要介绍 jraft 服务端编程的主要接口和类,核心是:
- 状态机 StateMachine :业务逻辑实现的主要接口,状态机运行在每个 raft 节点上,提交的 task 如果成功,最终都会复制应用到每个节点的状态机上。
- Raft 节点 Node : 表示一个 raft 节点,可以提交 task,以及查询 raft group 信息,比如当前状态、当前 leader/term 等。
- RPC 服务: raft 节点之间通过 RPC 服务通讯(选举、复制等)
- RaftGroupService:一个辅助编程框架类,方便地“组装”起一个 raft group 节点。
3.1 迭代器 Iterator
提交的 task ,在 jraft 内部会做累积批量提交,应用到状态机的是一个 task 迭代器,通过 com.alipay.sofa.jraft.Iterator 接口表示,一个典型的例子:
Iterator it = ....
//遍历迭代任务列表
while(it.hasNext()){
ByteBuffer data = it.getData(); // 获取当前任务数据
Closure done = it.done(); // 获取当前任务的 closure 回调
long index = it.getIndex(); // 获取任务的唯一日志编号,单调递增, jraft 自动分配
long term = it.getTerm(); // 获取任务的 leader term
...逻辑处理...
it.next(); // 移到下一个task
}
请注意, 如果 task 没有设置 closure,那么 done 可能会是 null,另外在 follower 节点上, done 也是 null,因为 done 不会被复制到除了 leader 节点之外的其他 raft 节点。
这里有一个优化技巧,通常 leader 获取到的 done closure,可以扩展包装一个 closure 类 包含了没有序列化的用户请求,那么在逻辑处理部分可以直接从 closure 获取到用户请求,无需通过 data 反序列化得到,减少了 leader 的 CPU 开销,具体可参见 counter 例子。
Iterator 实现类 - IteratorWrapper
它属于一个装饰器(Wrapper)实现,底层会使用代理对象:IteratorImpl
核心方法
获取任务数据 - getData() 方法
@Override
public ByteBuffer getData() {
final LogEntry entry = this.impl.entry();
return entry != null ? entry.getData() : null;
}
Iterator 具体实现类 - IteratorImpl
核心方法
获取日志数据 - entry() & next()
public LogEntry entry() {
return this.currEntry;
}
/**
* Move to next
*/
public void next() {
this.currEntry = null; //release current entry
//get next entry
if (this.currentIndex <= this.committedIndex) {
++this.currentIndex;
if (this.currentIndex <= this.committedIndex) {
try {
this.currEntry = this.logManager.getEntry(this.currentIndex);
if (this.currEntry == null) {
getOrCreateError().setType(EnumOutter.ErrorType.ERROR_TYPE_LOG);
getOrCreateError().getStatus().setError(-1,
"Fail to get entry at index=%d while committed_index=%d", this.currentIndex,
this.committedIndex);
}
} catch (final LogEntryCorruptedException e) {
getOrCreateError().setType(EnumOutter.ErrorType.ERROR_TYPE_LOG);
getOrCreateError().getStatus().setError(RaftError.EINVAL, e.getMessage());
}
this.applyingIndex.set(this.currentIndex);
}
}
}
3.2 状态机 StateMachine
提交的任务最终将会复制应用到所有 raft 节点上的状态机,状态机通过 StateMachine 接口表示,它的主要方法包括:
- void onApply(Iterator iter) 最核心的方法,应用任务列表到状态机,任务将按照提交顺序应用。**请注意,当这个方法返回的时候,我们就认为这一批任务都已经成功应用到状态机上,如果你没有完全应用(比如错误、异常),将会被当做一个 critical 级别的错误,报告给状态机的 onError 方法,错误类型为 ERROR_TYPE_STATE_MACHINE **。关于故障和错误处理参见下面的第 7 节。
- void onError(RaftException e) 当 critical 错误发生的时候,会调用此方法,RaftException 包含了 status 等详细的错误信息**;当这个方法被调用后,将不允许新的任务应用到状态机,直到错误被修复并且节点被重启**。因此对于任何在开发阶段发现的错误,都应当及时做修正,如果是 jraft 的问题,请及时报告。
- void onLeaderStart(long term) 当状态机所属的 raft 节点成为 leader 的时候被调用,成为 leader 当前的 term 通过参数传入。
- void onLeaderStop(Status status) 当前状态机所属的 raft 节点失去 leader 资格时调用,status 字段描述了详细的原因,比如主动转移 leadership、重新发生选举等。
- void onStartFollowing(LeaderChangeContext ctx) 当一个 raft follower 或者 candidate 节点开始 follow 一个 leader 的时候调用,LeaderChangeContext 包含了 leader 的 PeerId/term/status 等上下文信息。并且当前 raft node 的 leaderId 属性会被设置为新的 leader 节点 PeerId。
- void onStopFollowing(LeaderChangeContext ctx) 当一个 raft follower 停止 follower 一个 leader 节点的时候调用,这种情况一般是发生了 leadership 转移,比如重新选举产生了新的 leader,或者进入选举阶段等。同样 LeaderChangeContext 描述了停止 follow 的 leader 的信息,其中 status 描述了停止 follow 的原因。
- void onConfigurationCommitted(Configuration conf) 当一个 raft group 的节点配置提交到 raft group 日志的时候调用,通常不需要实现此方法,或者打印个日志即可。
- void onShutdown() 当状态机所在 raft 节点被关闭的时候调用,可以用于一些状态机的资源清理工作,比如关闭文件等。
- onSnapshotSave 和 onSnapshotLoad Snapshot 的保存和加载,见 3.6 小节。
因为 StateMachine 接口的方法比较多,并且大多数方法可能不需要做一些业务处理,因此 jraft 提供了一个 StateMachineAdapter 桥接类,方便适配实现状态机,除了强制要实现 onApply 方法外,其他方法都提供了默认实现,也就是简单地打印日志,用户可以选择实现特定的方法:
public class TestStateMachine extends StateMachineAdapter {
private AtomicLong leaderTerm = new AtomicLong(-1);
@Override
public void onApply(Iterator iter) {
while(iter.hasNext()){
//应用任务到状态机
iter.next();
}
}
@Override
public void onLeaderStart(long term) {
//保存 leader term
this.leaderTerm.set(term);
super.onLeaderStart(term);
}
}
3.3 Raft 节点 Node
Node 接口表示一个 raft 的参与节点,他的角色可能是 leader、follower 或者 candidate,随着选举过程而转变。
Node 接口最核心的几个方法如下:
- void apply(Task task) 提交一个新任务到 raft group,此方法是线程安全并且非阻塞,无论任务是否成功提交到 raft group,都会通过 task 关联的 closure done 通知到。如果当前节点不是 leader,会直接失败通知 done closure。
- PeerId getLeaderId() 获取当前 raft group 的 leader peerId,如果未知,返回 null
- shutdown 和 join ,前者用于停止一个 raft 节点,后者可以在 shutdown 调用后等待停止过程结束。
- void snapshot(Closure done) 触发当前节点执行一次 snapshot 保存操作,结果通过 done 通知,参见 3.6 节。
其他一些方法都是查询节点信息以及变更 raft group 节点配置,参见第 6 节。
创建一个 raft 节点可以通过 RaftServiceFactory.createRaftNode(String groupId, PeerId serverId) 静态方法,其中
- groupId 该 raft 节点的 raft group Id。
- serverId 该 raft 节点的 PeerId 。
创建后还需要初始化才可以使用,初始化调用 boolean init(NodeOptions opts) 方法,需要传入 NodeOptions 配置。
NodeOptions 主要配置如下:
// 一个 follower 当超过这个设定时间没有收到 leader 的消息后,变成 candidate 节点的时间。
// leader 会在 electionTimeoutMs 时间内向 follower 发消息(心跳或者复制日志),如果没有收到,
// follower 就需要进入 candidate状态,发起选举或者等待新的 leader 出现,默认1秒。
private int electionTimeoutMs = 1000;
// 自动 Snapshot 间隔时间,默认一个小时
private int snapshotIntervalSecs = 3600;
// 当节点是从一个空白状态启动(snapshot和log存储都为空),那么他会使用这个初始配置作为 raft group
// 的配置启动,否则会从存储中加载已有配置。
private Configuration initialConf = new Configuration();
// 最核心的,属于本 raft 节点的应用状态机实例。
private StateMachine fsm;
// Raft 节点的日志存储路径,必须有
private String logUri;
// Raft 节点的元信息存储路径,必须有
private String raftMetaUri;
// Raft 节点的 snapshot 存储路径,可选,不提供就关闭了 snapshot 功能。
private String snapshotUri;
// 是否关闭 Cli 服务,参见 4.2 节,默认不关闭
private boolean disableCli = false;
// 内部定时线程池大小,默认按照 cpu 个数计算,需要根据应用实际情况适当调节。
private int timerPoolSize = Utils.cpus() * 3 > 20 ? 20 : Utils.cpus() * 3;
// Raft 内部实现的一些配置信息,特别是性能相关,参见第6节。
private RaftOptions raftOptions = new RaftOptions();
NodeOptions 最重要的就是设置三个存储的路径,以及应用状态机实例,如果是第一次启动,还需要设置 initialConf 初始配置节点列表。
然后就可以初始化创建的 Node:
NodeOptions opts = ...
Node node = RaftServiceFactory.createRaftNode(groupId, serverId);
if(!node.init(opts))
throw new IllegalStateException("启动 raft 节点失败,具体错误信息请参考日志。");
创建和初始化结合起来也可以直接用 createAndInitRaftNode 方法:
Node node = RaftServiceFactory.createAndInitRaftNode(groupId, serverId, nodeOpts);
3.4 RPC 服务
单纯一个 raft node 是没有什么用,测试可以是单个节点,但是正常情况下一个 raft grup 至少应该是三个节点,如果考虑到异地多机房容灾,应该扩展到5个节点。
节点之间的通讯使用 bolt 框架的 RPC 服务。
首先,创建节点后,需要将节点地址加入到 NodeManager:
NodeManager.getInstance().addAddress(serverId.getEndpoint());
NodeManager 的 address 集合表示本进程提供的 RPC 服务地址列表。
其次,创建 Raft 专用的 RPCServer,内部内置了一套处理内部节点之间交互协议的 processor:
RPCServer rpcServer = RaftRpcServerFactory.createRaftRpcServer(serverId.getEndPoint());
// 启动 RPC 服务
rpcServer.init(null);
上述创建和 start 两个步骤可以合并为一个调用:
RPCServer rpcServer = RaftRpcServerFactory.createAndStartRaftRpcServer(serverId.getEndPoint());
这样就为了本节点提供了 RPC Server 服务,其他节点可以连接本节点进行通讯,比如发起选举、心跳和复制等。
但是大部分应用的服务端也会同时提供 RPC 服务给用户使用,jraft 允许 raft 节点使用业务提供的 RPCServer 对象,也就是和业务共用同一个服务端口,这就需要为业务的 RPCServer 注册 raft 特有的通讯协议处理器:
RpcServer rpcServer = ... // 业务的 RPCServer 对象
...注册业务的处理器...
// 注册 Raft 内部协议处理器
RaftRpcServerFactory.addRaftRequestProcessors(rpcServer);
// 启动,共用了端口
rpcServer.init(null);
同样,应用服务器节点之间可能需要一些业务通讯,会使用到 bolt 的 RpcClient,你也可以直接使用 jraft 内部的 rpcClient:
RpcClient rpcClient = ((AbstractBoltClientService) (((NodeImpl) node).getRpcService())).getRpcClient();
这样可以做到一些资源复用,减少消耗,代价就是依赖了 jraft 的内部实现和缺少一些可自定义配置。
如果基于 Bolt 依赖支持 raft node 之间 RPC 服务 SSL/TLS,需要下面的步骤:
- 服务端 RpcServer 配置以下环境变量:
// RpcServer init
bolt.server.ssl.enable = true // 是否开启服务端 SSL 支持,默认为 false
bolt.server.ssl.clientAuth = true // 是否开启服务端 SSL 客户端认证,默认为 false
bolt.server.ssl.keystore = bolt.pfx // 服务端 SSL keystore 文件路径
bolt.server.ssl.keystore.password = sfbolt // 服务端 SSL keystore 密码
bolt.server.ssl.keystore.type = pkcs12 // 服务端 SSL keystore 类型,例如 JKS 或者 pkcs12
bolt.server.ssl.kmf.algorithm = SunX509 // 服务端 SSL kmf 算法
// RpcServer stop
bolt.server.ssl.enable = false
bolt.server.ssl.clientAuth = false
- 客户端 RpcClient 配置环境变量如下:
// RpcClient init
bolt.client.ssl.enable = true // 是否开启客户端 SSL 支持,默认为 false
bolt.client.ssl.keystore = cbolt.pfx // 客户端 SSL keystore 文件路径
bolt.server.ssl.keystore.password = sfbolt // 客户端 SSL keystore 密码
bolt.client.ssl.keystore.type = pkcs12 // 客户端 SSL keystore 类型,例如 JKS 或者 pkcs12
bolt.client.ssl.tmf.algorithm = SunX509 // 客户端 SSL tmf 算法
// RpcClient stop
bolt.client.ssl.enable = false
其中服务端 SSL keystore 文件 bolt.pfx 和客户端 SSL keystore 文件 cbolt.pfx 按照以下步骤生成:
- 首先生成 keystore 并且导出其认证文件。
keytool -genkey -alias securebolt -keysize 2048 -validity 365 -keyalg RSA -dname "CN=localhost" -keypass sfbolt -storepass sfbolt -keystore bolt.pfx -deststoretype pkcs12
keytool -export -alias securebolt -keystore bolt.pfx -storepass sfbolt -file bolt.cer
- 接着生成客户端 keystore。
keytool -genkey -alias smcc -keysize 2048 -validity 365 -keyalg RSA -dname "CN=localhost" -keypass sfbolt -storepass sfbolt -keystore cbolt.pfx -deststoretype pkcs12
- 最后导入服务端认证文件到客户端 keystore。
keytool -import -trustcacerts -alias securebolt -file bolt.cer -storepass sfbolt -keystore cbolt.pfx
RPC 服务器 - RPCServer
RPC 服务器服务 - RaftServerService
核心方法
处理投票请求 - handleRequestVoteRequest
/**
* Handle request-vote request.
*
* @param request data of the vote
* @return the response message
*/
Message handleRequestVoteRequest(RequestVoteRequest request);
处理 AppendEntries RPC - handleAppendEntriesRequest
/**
* Handle append-entries request, return response message or
* called done.run() with response.
*
* @param request data of the entries to append
* @param done callback
* @return the response message
*/
Message handleAppendEntriesRequest(AppendEntriesRequest request, RpcRequestClosure done);
RPC 服务器服务实现类 - NodeImpl
处理 AppendEntries RPC - handleAppendEntriesRequest
主要执行逻辑
- 节点状态检查
if (!this.state.isActive()) {
LOG.warn("Node {} is not in active state, currTerm={}.", getNodeId(), this.currTerm);
return RpcFactoryHelper //
.responseFactory() //
.newResponse(AppendEntriesResponse.getDefaultInstance(), RaftError.EINVAL,
"Node %s is not in active state, state %s.", getNodeId(), this.state.name());
}
- 请求服务器 ID 检查
final PeerId serverId = new PeerId();
if (!serverId.parse(request.getServerId())) {
LOG.warn("Node {} received AppendEntriesRequest from {} serverId bad format.", getNodeId(),
request.getServerId());
return RpcFactoryHelper //
.responseFactory() //
.newResponse(AppendEntriesResponse.getDefaultInstance(), RaftError.EINVAL,
"Parse serverId failed: %s.", request.getServerId());
}
- 请求任期与当前节点任期检查
// Check stale term
if (request.getTerm() < this.currTerm) {
LOG.warn("Node {} ignore stale AppendEntriesRequest from {}, term={}, currTerm={}.", getNodeId(),
request.getServerId(), request.getTerm(), this.currTerm);
return AppendEntriesResponse.newBuilder() //
.setSuccess(false) //
.setTerm(this.currTerm) //
.build();
}
- 请求 Leader ID 与当前节点 Leader ID 检查
// Check term and state to step down
checkStepDown(request.getTerm(), serverId);
if (!serverId.equals(this.leaderId)) {
LOG.error("Another peer {} declares that it is the leader at term {} which was occupied by leader {}.",
serverId, this.currTerm, this.leaderId);
// Increase the term by 1 and make both leaders step down to minimize the
// loss of split brain
stepDown(request.getTerm() + 1, false, new Status(RaftError.ELEADERCONFLICT,
"More than one leader in the same term."));
return AppendEntriesResponse.newBuilder() //
.setSuccess(false) //
.setTerm(request.getTerm() + 1) //
.build();
}
- Install Snapshot 状态检查
// Check term and state to step down
checkStepDown(request.getTerm(), serverId);
if (!serverId.equals(this.leaderId)) {
LOG.error("Another peer {} declares that it is the leader at term {} which was occupied by leader {}.",
serverId, this.currTerm, this.leaderId);
// Increase the term by 1 and make both leaders step down to minimize the
// loss of split brain
stepDown(request.getTerm() + 1, false, new Status(RaftError.ELEADERCONFLICT,
"More than one leader in the same term."));
return AppendEntriesResponse.newBuilder() //
.setSuccess(false) //
.setTerm(request.getTerm() + 1) //
.build();
}
- 请求最后日志任期与当前节点对比检查
final long prevLogIndex = request.getPrevLogIndex();
final long prevLogTerm = request.getPrevLogTerm();
final long localPrevLogTerm = this.logManager.getTerm(prevLogIndex);
if (localPrevLogTerm != prevLogTerm) {
final long lastLogIndex = this.logManager.getLastLogIndex();
LOG.warn(
"Node {} reject term_unmatched AppendEntriesRequest from {}, term={}, prevLogIndex={}, prevLogTerm={}, localPrevLogTerm={}, lastLogIndex={}, entriesSize={}.",
getNodeId(), request.getServerId(), request.getTerm(), prevLogIndex, prevLogTerm, localPrevLogTerm,
lastLogIndex, entriesCount);
return AppendEntriesResponse.newBuilder() //
.setSuccess(false) //
.setTerm(this.currTerm) //
.setLastLogIndex(lastLogIndex) //
.build();
}
- 判断是否为心跳检测
if (entriesCount == 0) {
// heartbeat or probe request
final AppendEntriesResponse.Builder respBuilder = AppendEntriesResponse.newBuilder() //
.setSuccess(true) //
.setTerm(this.currTerm) //
.setLastLogIndex(this.logManager.getLastLogIndex());
doUnlock = false;
this.writeLock.unlock();
// see the comments at FollowerStableClosure#run()
this.ballotBox.setLastCommittedIndex(Math.min(request.getCommittedIndex(), prevLogIndex));
return respBuilder.build();
}
关键调用 setLastCommittedIndex
/**
* Called by follower, otherwise the behavior is undefined.
* Set committed index received from leader
*
* @param lastCommittedIndex last committed index
* @return returns true if set success
*/
public boolean setLastCommittedIndex(final long lastCommittedIndex) {
boolean doUnlock = true;
final long stamp = this.stampedLock.writeLock();
try {
if (this.pendingIndex != 0 || !this.pendingMetaQueue.isEmpty()) {
Requires.requireTrue(lastCommittedIndex < this.pendingIndex,
"Node changes to leader, pendingIndex=%d, param lastCommittedIndex=%d", this.pendingIndex,
lastCommittedIndex);
return false;
}
if (lastCommittedIndex < this.lastCommittedIndex) {
return false;
}
if (lastCommittedIndex > this.lastCommittedIndex) {
this.lastCommittedIndex = lastCommittedIndex;
this.stampedLock.unlockWrite(stamp);
doUnlock = false;
this.waiter.onCommitted(lastCommittedIndex);
}
} finally {
if (doUnlock) {
this.stampedLock.unlockWrite(stamp);
}
}
return true;
}
当 RPC 请求中的 lastCommittedIndex 大于内存中的 this.lastCommittedIndex 时,将调用 FSMCaller waiter 对象中 的 onCommitted 方法。
com.alipay.sofa.jraft.core.FSMCallerImpl#onCommitted
@Override
public boolean onCommitted(final long committedIndex) {
return enqueueTask((task, sequence) -> {
task.type = TaskType.COMMITTED;
task.committedIndex = committedIndex;
});
}
private boolean enqueueTask(final EventTranslator<ApplyTask> tpl) {
if (this.shutdownLatch != null) {
// Shutting down
LOG.warn("FSMCaller is stopped, can not apply new task.");
return false;
}
this.taskQueue.publishEvent(tpl);
return true;
}
当 onCommitted 调用后,会给 taskQueue 发送事件,即 Task 类型变成 TaskType.COMMITTED 状态,事件监听者将处理该事件
this.disruptor.handleEventsWith(new ApplyTaskHandler());
this.disruptor.setDefaultExceptionHandler(new LogExceptionHandler<Object>(getClass().getSimpleName()));
this.taskQueue = this.disruptor.start();
taskQueue 事件监听器为 ApplyTaskHandler
private class ApplyTaskHandler implements EventHandler<ApplyTask> {
boolean firstRun = true;
// max committed index in current batch, reset to -1 every batch
private long maxCommittedIndex = -1;
@Override
public void onEvent(final ApplyTask event, final long sequence, final boolean endOfBatch) throws Exception {
setFsmThread();
this.maxCommittedIndex = runApplyTask(event, this.maxCommittedIndex, endOfBatch);
}
private void setFsmThread() {
if (firstRun) {
fsmThread = Thread.currentThread();
firstRun = false;
}
}
}
调用 com.alipay.sofa.jraft.core.FSMCallerImpl#runApplyTask 方法
@SuppressWarnings("ConstantConditions")
private long runApplyTask(final ApplyTask task, long maxCommittedIndex, final boolean endOfBatch) {
CountDownLatch shutdown = null;
if (task.type == TaskType.COMMITTED) {
if (task.committedIndex > maxCommittedIndex) {
maxCommittedIndex = task.committedIndex;
}
task.reset();
} else {
...
}
try {
if (endOfBatch && maxCommittedIndex >= 0) {
this.currTask = TaskType.COMMITTED;
doCommitted(maxCommittedIndex);
maxCommittedIndex = -1L; // reset maxCommittedIndex
}
this.currTask = TaskType.IDLE;
return maxCommittedIndex;
} finally {
if (shutdown != null) {
shutdown.countDown();
}
}
}
当批量事件处理结束,即 endOfBatch == true,关键调用 doCommitted 方法。
private void doCommitted(final long committedIndex) {
if (!this.error.getStatus().isOk()) {
return;
}
final long lastAppliedIndex = this.lastAppliedIndex.get();
// We can tolerate the disorder of committed_index
if (lastAppliedIndex >= committedIndex) {
return;
}
this.lastCommittedIndex.set(committedIndex);
final long startMs = Utils.monotonicMs();
try {
final List<Closure> closures = new ArrayList<>();
final List<TaskClosure> taskClosures = new ArrayList<>();
final long firstClosureIndex = this.closureQueue.popClosureUntil(committedIndex, closures, taskClosures);
// Calls TaskClosure#onCommitted if necessary
onTaskCommitted(taskClosures);
Requires.requireTrue(firstClosureIndex >= 0, "Invalid firstClosureIndex");
final IteratorImpl iterImpl = new IteratorImpl(this, this.logManager, closures, firstClosureIndex,
lastAppliedIndex, committedIndex, this.applyingIndex);
while (iterImpl.isGood()) {
final LogEntry logEntry = iterImpl.entry();
if (logEntry.getType() != EnumOutter.EntryType.ENTRY_TYPE_DATA) {
if (logEntry.getType() == EnumOutter.EntryType.ENTRY_TYPE_CONFIGURATION) {
if (logEntry.getOldPeers() != null && !logEntry.getOldPeers().isEmpty()) {
// Joint stage is not supposed to be noticeable by end users.
this.fsm.onConfigurationCommitted(new Configuration(iterImpl.entry().getPeers()));
}
}
if (iterImpl.done() != null) {
// For other entries, we have nothing to do besides flush the
// pending tasks and run this closure to notify the caller that the
// entries before this one were successfully committed and applied.
iterImpl.done().run(Status.OK());
}
iterImpl.next();
continue;
}
// Apply data task to user state machine
doApplyTasks(iterImpl);
}
if (iterImpl.hasError()) {
setError(iterImpl.getError());
iterImpl.runTheRestClosureWithError();
}
long lastIndex = iterImpl.getIndex() - 1;
final long lastTerm = this.logManager.getTerm(lastIndex);
setLastApplied(lastIndex, lastTerm);
} finally {
this.nodeMetrics.recordLatency("fsm-commit", Utils.monotonicMs() - startMs);
}
}
- 高可用状态检查
// fast checking if log manager is overloaded
if (!this.logManager.hasAvailableCapacityToAppendEntries(1)) {
LOG.warn("Node {} received AppendEntriesRequest but log manager is busy.", getNodeId());
return RpcFactoryHelper //
.responseFactory() //
.newResponse(AppendEntriesResponse.getDefaultInstance(), RaftError.EBUSY,
"Node %s:%s log manager is busy.", this.groupId, this.serverId);
}
- 日志条目追加
// Parse request
long index = prevLogIndex;
final List<LogEntry> entries = new ArrayList<>(entriesCount);
ByteBuffer allData = null;
if (request.hasData()) {
allData = request.getData().asReadOnlyByteBuffer();
}
final List<RaftOutter.EntryMeta> entriesList = request.getEntriesList();
for (int i = 0; i < entriesCount; i++) {
index++;
final RaftOutter.EntryMeta entry = entriesList.get(i);
final LogEntry logEntry = logEntryFromMeta(index, allData, entry);
if (logEntry != null) {
// Validate checksum
if (this.raftOptions.isEnableLogEntryChecksum() && logEntry.isCorrupted()) {
long realChecksum = logEntry.checksum();
LOG.error(
"Corrupted log entry received from leader, index={}, term={}, expectedChecksum={}, realChecksum={}",
logEntry.getId().getIndex(), logEntry.getId().getTerm(), logEntry.getChecksum(),
realChecksum);
return RpcFactoryHelper //
.responseFactory() //
.newResponse(AppendEntriesResponse.getDefaultInstance(), RaftError.EINVAL,
"The log entry is corrupted, index=%d, term=%d, expectedChecksum=%d, realChecksum=%d",
logEntry.getId().getIndex(), logEntry.getId().getTerm(), logEntry.getChecksum(),
realChecksum);
}
entries.add(logEntry);
}
}
final FollowerStableClosure closure = new FollowerStableClosure(request, AppendEntriesResponse.newBuilder()
.setTerm(this.currTerm), this, done, this.currTerm);
this.logManager.appendEntries(entries, closure);
// update configuration after _log_manager updated its memory status
checkAndSetConfiguration(true);
success = true;
return null;
关键调用点 - com.alipay.sofa.jraft.storage.impl.LogManagerImpl#appendEntries
@Override
public void appendEntries(final List<LogEntry> entries, final StableClosure done) {
assert(done != null);
Requires.requireNonNull(done, "done");
if (this.hasError) {
entries.clear();
ThreadPoolsFactory.runClosureInThread(this.groupId, done, new Status(RaftError.EIO, "Corrupted LogStorage"));
return;
}
boolean doUnlock = true;
this.writeLock.lock();
try {
if (!entries.isEmpty() && !checkAndResolveConflict(entries, done, this.writeLock)) {
// If checkAndResolveConflict returns false, the done will be called in it.
entries.clear();
return;
}
for (int i = 0; i < entries.size(); i++) {
final LogEntry entry = entries.get(i);
// Set checksum after checkAndResolveConflict
if (this.raftOptions.isEnableLogEntryChecksum()) {
entry.setChecksum(entry.checksum());
}
if (entry.getType() == EntryType.ENTRY_TYPE_CONFIGURATION) {
Configuration oldConf = new Configuration();
if (entry.getOldPeers() != null) {
oldConf = new Configuration(entry.getOldPeers(), entry.getOldLearners());
}
final ConfigurationEntry conf = new ConfigurationEntry(entry.getId(),
new Configuration(entry.getPeers(), entry.getLearners()), oldConf);
this.configManager.add(conf);
}
}
if (!entries.isEmpty()) {
done.setFirstLogIndex(entries.get(0).getId().getIndex());
this.logsInMemory.addAll(entries);
}
done.setEntries(entries);
doUnlock = false;
if (!wakeupAllWaiter(this.writeLock)) {
notifyLastLogIndexListeners();
}
// publish event out of lock
this.diskQueue.publishEvent((event, sequence) -> {
event.reset();
event.type = EventType.OTHER;
event.done = done;
});
} finally {
if (doUnlock) {
this.writeLock.unlock();
}
}
}
将 AppendEntries RPC 中的 LogEntry 列表追加到内存中:this.logsInMemory.addAll(entries);
同时给 diskQueue 发布事件,会触发事件处理器的实现
@Override
public boolean init(final LogManagerOptions opts) {
this.writeLock.lock();
try {
...
this.disruptor.handleEventsWith(new StableClosureEventHandler());
this.disruptor.setDefaultExceptionHandler(new LogExceptionHandler<Object>(this.getClass().getSimpleName(),
(event, ex) -> reportError(-1, "LogManager handle event error")));
this.diskQueue = this.disruptor.start();
...
} finally {
this.writeLock.unlock();
}
return true;
}
即 StableClosureEventHandler
private class StableClosureEventHandler implements EventHandler<StableClosureEvent> {
LogId lastId = LogManagerImpl.this.diskId;
List<StableClosure> storage = new ArrayList<>(256);
AppendBatcher ab = new AppendBatcher(this.storage, 256, new ArrayList<>(),
LogManagerImpl.this.diskId);
@Override
public void onEvent(final StableClosureEvent event, final long sequence, final boolean endOfBatch)
throws Exception {
...
if (endOfBatch) {
this.lastId = this.ab.flush();
setDiskId(this.lastId);
}
}
}
调用 com.alipay.sofa.jraft.storage.impl.LogManagerImpl.AppendBatcher#flush 方法,会调用日志存储追加日志条目方法,this.logStorage.appendEntries
LogId flush() {
if (this.size > 0) {
this.lastId = appendToStorage(this.toAppend);
...
}
...
}
private LogId appendToStorage(final List<LogEntry> toAppend) {
LogId lastId = null;
if (!this.hasError) {
...
final int nAppent = this.logStorage.appendEntries(toAppend);
...
} finally {
this.nodeMetrics.recordLatency("append-logs", Utils.monotonicMs() - startMs);
}
}
return lastId;
}
3.5 框架类 RaftGroupService
总结下上文描述的创建和启动一个 raft group 节点的主要阶段:
- 实现并创建状态机实例
- 创建并设置好 NodeOptions 实例,指定存储路径,如果是空白启动,指定初始节点列表配置。
- 创建 Node 实例,并使用 NodeOptions 初始化。
- 创建并启动 RpcServer ,提供节点之间的通讯服务。
如果完全交给应用来做会相对麻烦,因此 jraft 提供了一个辅助工具类 RaftGroupService 来帮助用户简化这个过程:
String groupId = "jraft";
PeerId serverId = JRaftUtils.getPeerId("localhost:8080");
NodeOptions nodeOptions = ... // 配置 node options
RaftGroupService cluster = new RaftGroupService(groupId, serverId, nodeOptions);
Node node = cluster.start();
// 使用 node 提交任务
Task task = ....
node.apply(task);
在 start 方法里会帮助你执行 3 和 4 两个步骤,并返回创建的 Node 实例。
RaftGroupService 还有其他构造函数,比如接受一个业务的 RpcServer 共用等:
public RaftGroupService(String groupId, PeerId serverId, NodeOptions nodeOptions, RpcServer rpcServer)
这个传入的 RpcServer 必须调用了 RaftRpcServerFactory.addRaftRequestProcessors(rpcServer) 注册了 raft 协议处理器。
3.6 Snapshot 服务
当一个 raft 节点重启的时候,内存中的状态机的状态将会丢失,在启动过程中将重放日志存储中的所有日志,重建整个状态机实例。这就导致 3 个问题:
- 如果任务提交比较频繁,比如消息中间件这个场景,那么会导致整个重建过程很长,启动缓慢。
- 如果日志很多,节点需要存储所有的日志,这对存储是一个资源占用,不可持续。
- 如果增加一个节点,新节点需要从 leader 获取所有的日志重放到状态机,这对 leader 和网络带宽都是不小的负担。
因此,通过引入 snapshot 机制来解决这 3 个问题,所谓 snapshot 就是为当前状态机的最新状态打一个”镜像“单独保存,在保存成功后,在这个时刻之前的日志就可以删除,减少了日志存储占用;启动的时候,可以直接加载最新的 snapshot 镜像,然后重放在此之后的日志即可,如果 snapshot 间隔合理,那么整个重放过程会比较快,加快了启动过程。最后,新节点的加入,可以先从 leader 拷贝最新的 snapshot 安装到本地状态机,然后只要拷贝后续的日志即可,可以快速跟上整个 raft group 的进度。
启用 snapshot 需要设置 NodeOptions 的 snapshotUri 属性,也就是 snapshot 存储的路径。默认会启动一个定时器自动做 snapshot,间隔通过 NodeOptions 的 snapshotIntervalSecs 属性指定,默认 3600 秒,也就是一个小时。
用户也可以主动触发 snapshot,通过 Node 接口的
Node node = ...
Closure done = ...
node.snapshot(done);
结果将通知到 closure 回调。
状态机需要实现下列两个方法:
// 保存状态的最新状态,保存的文件信息可以写到 SnapshotWriter 中,保存完成切记调用 done.run(status) 方法。
// 通常情况下,每次 `onSnapshotSave` 被调用都应该阻塞状态机(同步调用)以保证用户可以捕获当前状态机的状态,如果想通过异步 snapshot 来提升性能,
// 那么需要用户状态机支持快照读,并先同步读快照,再异步保存快照数据。
void onSnapshotSave(SnapshotWriter writer, Closure done);
// 加载或者安装 snapshot,从 SnapshotReader 读取 snapshot 文件列表并使用。
// 需要注意的是:
// 程序启动会调用 `onSnapshotLoad` 方法,也就是说业务状态机的数据一致性保障全权由 jraft 接管,业务状态机的启动时应保持状态为空,
// 如果状态机持久化了数据那么应该在启动时先清除数据,并依赖 raft snapshot + replay raft log 来恢复状态机数据。
boolean onSnapshotLoad(SnapshotReader reader);
更具体的实现请参考counter 例子。
4. 客户端
在构建完成 raft group 服务端集群后,客户端需要跟 raft group 交互,本节主要介绍 jraft 提供的一些客户端服务。
4.1 路由表 RouteTable
首先要介绍的是 RouteTable 类,用来维护到 raft group 的路由信息。使用很简单,它是一个全局单例,参见下面例子:
// 初始化 RPC 服务
CliClientService cliClientService = new BoltCliClientService();
cliClientService.init(new CliOptions());
// 获取路由表
RouteTable rt = RouteTable.getInstance();
// raft group 集群节点配置
Configuration conf = JRaftUtils.getConfiguration("localhost:8081,localhost:8082,localhost:8083");
// 更新路由表配置
rt.updateConfiguration("jraft_test", conf);
// 刷新 leader 信息,超时 10 秒,返回成功或者失败
boolean success = rt.refreshLeader(cliClientService, "jraft_test", 10000).isOk();
if(success){
// 获取集群 leader 节点,未知则为 null
PeerId leader = rt.selectLeader("jraft_test");
}
应用如果需要向 leader 提交任务或者必须向 leader 查询最新数据,就需要定期调用 refreshLeader 更新路由信息,或者在服务端返回 redirect 重定向信息(自定义协议,参见 counter 例子)的情况下主动更新 leader 信息。
RouteTable 还有一些查询和删除配置的方法,请直接查看接口注释。
4.2 CLI 服务
CLI 服务就是 Client CommandLine Service,是 jraft 在 raft group 节点提供的 RPC 服务中暴露了一系列用于管理 raft group 的服务接口,例如增加节点、移除节点、改变节点配置列表、重置节点配置以及转移 leader 等功能。
具体接口都比较明显,不重复解释了:
public interface CliService extends Lifecycle<CliOptions> {
// 增加一个节点到 raft group
Status addPeer(String groupId, Configuration conf, PeerId peer);
// 从 raft group 移除一个节点
Status removePeer(String groupId, Configuration conf, PeerId peer);
// 平滑地迁移 raft group 节点列表
Status changePeers(String groupId, Configuration conf, Configuration newPeers);
// 重置某个节点的配置,仅特殊情况下使用,参见第 4 节
Status resetPeer(String groupId, PeerId peer, Configuration newPeers);
// 让leader 将 leadership 转给 peer
Status transferLeader(String groupId, Configuration conf, PeerId peer);
// 触发某个节点的 snapshot
Status snapshot(String groupId, PeerId peer);
// 获取某个 replication group 的 leader 节点
Status getLeader(final String groupId, final Configuration conf, final PeerId leaderId);
// 获取某个 replication group 的所有节点
List<PeerId> getPeers(final String groupId, final Configuration conf);
// 获取某个 replication group 的所有存活节点
List<PeerId> getAlivePeers(final String groupId, final Configuration conf);
// 手动负载均衡 leader 节点
Status rebalance(final Set<String> balanceGroupIds, final Configuration conf, final Map<String, PeerId> balancedLeaderIds);
}
使用例子,首先是创建 CliService 实例:
// 创建并初始化 CliService
CliService cliService = RaftServiceFactory.createAndInitCliService(new CliOptions());
// 使用CliService
Configuration conf = JRaftUtils.getConfiguration("localhost:8081,localhost:8082,localhost:8083");
Status status = cliService.addPeer("jraft_group", conf, new PeerId("localhost", 8083));
if(status.isOk()){
System.out.println("添加节点成功");
}
4.3 RPC 服务
客户端的通讯层都依赖 Bolt 的 RpcClient,封装在 CliClientService 接口中,实现类就是 BoltCliClientService 。 可以通过 BoltCliClientService 的 getRpcClient 方法获取底层的 bolt RpcClient 实例,用于其他通讯用途,做到资源复用。
RouteTable 更新 leader 信息同样需要传入 CliClientService 实例,用户应该尽量复用这些底层通讯组件,而非重复创建用。
AppendEentries RPC 请求 - AppendEntriesRequest
RPC 客户端服务 - RaftClientService
核心方法
发送投票请求 RPC - requestVote
/**
* Sends a request-vote request and handle the response with done.
*
* @param endpoint destination address (ip, port)
* @param request request data
* @param done callback
* @return a future with result
*/
Future<Message> requestVote(final Endpoint endpoint, final RpcRequests.RequestVoteRequest request,
final RpcResponseClosure<RpcRequests.RequestVoteResponse> done);
执行 AppendEntries RPC - appendEntries
/**
* Sends a append-entries request and handle the response with done.
*
* @param endpoint destination address (ip, port)
* @param request request data
* @param done callback
* @return a future with result
*/
Future<Message> appendEntries(final Endpoint endpoint, final RpcRequests.AppendEntriesRequest request,
final int timeoutMs, final RpcResponseClosure<RpcRequests.AppendEntriesResponse> done);