Ghidra101再入门(上?)-Ghidra架构介绍
Ghidra101再入门(上?)-Ghidra架构介绍
最近有群友问我,说:“用了很多年的IDA,最近想看看Ghidra,这应该怎么进行入门?“这可难到我了。。
我发现,市面上虽然介绍Ghidra怎么用的文章和书籍很多,但是结构化介绍Ghidra本身以及它的架构的文章很少(几乎没有)。对于熟悉IDA的群友,反编译器的使用肯定不存在问题,他们需要的是更加深层的知识。
那我就小写几篇文章(希望不会挖坑不填);这一篇,就从先Ghidra的架构开始说起吧,希望能给已经熟悉或者正在研究静态逆向的朋友们些许帮助。
——————————————————————
这篇文章将讨论下面这些问题,如果有写的不清楚/不对的地方,希望大家告诉我:
- 为什么要整理这些知识?
- 什么是反编译?
- Ghidra反编译器的主要架构是什么样?
- Ghidra的主要模块有哪些,都是干啥用的?
- Ghidra这套框架牛逼在哪里?在哪里有很大的缺陷?
- Ghidra相比于IDA有什么区别/优点/缺点?
- 为什么Ghidra会设计成这个样子?
- 其它。。。。?
1、为什么要整理这方面的知识?
学习静态逆向,大家都是从使用IDA/Ghidra这类反编译器的使用开始。然后逐步的深入到各种复杂的场景。
现代静态逆向的工作越来越复杂,对抗越发深入;梳理反编译器架构的知识,学习程序分析技术,在日常工作生活中,一旦反编译器出现什么问题,能够知道如何对反编译器进行修改与优化,多一条解决问题的路子。
可惜,市面上能够供我们学习的反编译框架并不多,反编译软件开发的难度高、工作量大(IDA和Ghidra都已经持续开发了近30年),IDA对外提供的资源又非常的少。幸好Ghidra开源了,给我们提供了一个了解这方面知识的门道。
2、什么是反编译?
所谓"反编译"有广义+狭隘的两层含义;
从广义上,反编译指的是将低级语言、机器语言转换成高级语言一系列技术的集合。技术落地的产品就是"反编译器"。
当然,这篇文章中的反编译更加接地气一点;所谓反编译-~反编译~~反的是什么呢?当然是编译器啊!
所以,从狭隘的角度来看,反编译技术指的是识别编译器优化算法特征,基于程序分析技术编写反向算法,从编译产物中还原被编译器隐藏的高层次抽象。
这种反向算法的集大成者,我们就称为"反编译器"!因此,这篇文章就是参考Ghidra,介绍这一集大成者的主要架构与功能。
如果从正向写代码的角度来看,整个Ghidra对应的应该是IDE(集成开发环境),Ghidra中的反编译器对应的是gcc这类编译器。
3、Ghidra整体架构/主要模块简述
如下图,这是我大概画的Ghidra反编译器主要模块结构。
我画的比较粗糙,一定会有比较多的遗漏的点。先简单介绍一下各个子模块的作用,从上到下,从左到右:
- Ghidra反编译框架插件:可以在Ghidra的tool目录中找到这些功能,和IDA中的plugin功能类似,Ghidra提供了一套专门的脚本管理页面。
- Ghidra配套脚本:用于兼容多个平台、headless模式等等的打包后的脚本。
- Ghidra-Java-Frameword软件主程序:Ghidra的主程序,包含了绝大多数的组件。
- SoftwareModeling上层二进制抽象:Java代码中对于二进制的抽象,包括了反汇编、中间语言、函数CFG、二进制内存模型等等,逆向工程的主要工作之一,就是从二进制中还原这些上层信息。
- Ghidra-Decompiler反编译进程:Ghidra的"F5"功能,将中间语言转换为类C的伪代码,他是一个完全独立的模块,与Java主进程通过自定义的”字符流“交互。
- Ghidra-Decompiler命令行程序:Ghidra的"F5"功能完全独立,因此它可以自己以命令行形式启动并加载二进制,独立的完成反编译的工作。
- Sleigh-Processor编译器:将Sleigh编译成.sla的支持组件
- Sleigh-Processor描述模块:Ghidra的核心功能,用于支持x86、arm、mips等数十种指令集架构;GCC、MSVC、GO、Java等多种编译器的"描述模块"。
- Ghidra开发者套装:包括Sleigh以及Ghidra插件的eclipse-IDE开发支持套件,但是我用IDEA+vscode(喂喂,eclipse都啥时候的老古董了啊)
下面的重心放在三个最重要的组件:Ghidra-Framework主程序、Decompiler反编译器、Sleigh-Processor指令集架构描述配置。
4、Ghidra-Framework软件主程序:
这个组件是Ghidra的主程序,使用Java编写,也就是我们反编译时所使用的Ghidra那一整套界面(Ghidra啥时候找个产品经理和设计师,把你那破UI修一下啊)
主程序的功能十分的复杂,这里只说两个关键模块:
4-1、Analysis分析器:
与IDA不同,Ghidra虽然负责载入可执行文件,但是对于函数识别、反汇编、栈平衡、指令等等解析与处理,都需要分析器完成(IDA会自动的完成这部分工作)。
可以说,Analysis模块除了不负责"F5",其它啥功能都要做;
但对于反编译器,核心的Analysis有那么几个:
- 匹配查找函数头(function start search):通过编译器的配置以及特定的二进制信息查找函数起始位置,配置文件可以在Processor中的xxxxpattern.xml中找到
- 递归下降反编译(Symbol/Disassemble/Subroutine):从已知的函数头执行递归下降的反编译,已知的函数头通过匹配查找、符号信息、start函数入口等等方法获取。
- No-Return函数处理(No-Return Function):通过规则识别并传播标记no-return函数。
- 数据引用(Reference):反编译过程中对于数据地址、字符串、常量的引用信息

4-2、SoftwareModeeling二进制抽象:
这个模块是上层java进程中的二进制抽象,所谓"二进制的抽象"指的是从二进制中还原出高层的信息,包括:二进制内存结构、函数、导入表、导出表、反汇编指令、中间语言、数据与交叉引用等等。
因此反编译器的界面和写代码时的IDE很相似(个人看法)。
5、Sleigh-Processor指令集架构描述
这个模块是Ghidra最牛逼的东西,它继承了反编译技术奠基者Cifuentes, C博士和M. Van Emmerik博士的QUBT框架。
在反编译器开发的过程总,最麻烦的事情之一,就是对不同指令集架构、编译器、ISA的适配;并且这个工作还没有讨巧的办法,就是纯纯的苦力活。
例如,在IDA中如果需要支持一个新的指令集,就必须编写一个叫做processor的模块。而在Ghidra中"不需要写代码"通过这一套描述语言实现了多架构的支持功能。
5-1、binary-rewrite技术简述
在上个世纪末,操作系统、指令集、ISA并没有现在这么统一。
那时候的程序员也遇到了多架构的麻烦:给特定平台开发的程序换个平台就用没法用了,需要重新写。
学术界就提出了"Binary-rewrite"技术,通过一套系统将程序从一个平台转换为另一个平台(例如将C语言编写的程序,转换到JVM上运行)
UQBT框架实现了将二进制转换为中间语言,再将中间语言重编译成其它平台的能力。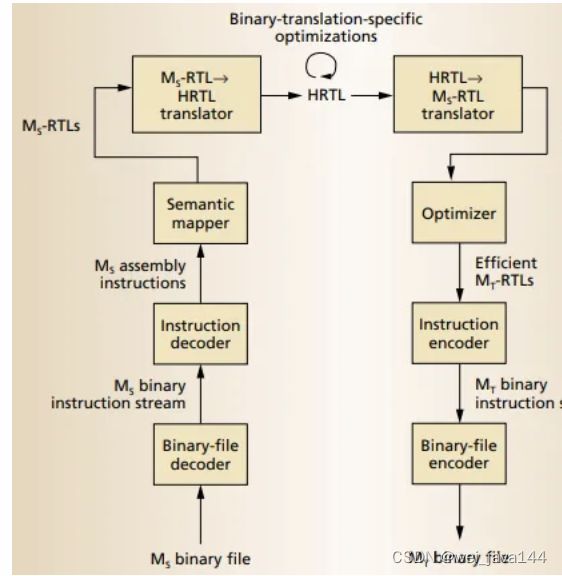
为了降低从二进制到中间语言的转换成本,UQBT框架提供了一种叫做"通用描述语言Semantic Syntax Language (SSL)"的描述类型语言
通过写对指令集、操作系统、调用约定的描述配置,不用写代码,就可以实现从二进制到中间语言的转换。
5-2、Ghidra-Sleigh描述语言概述
同样,Ghidra这套描述语言的原型来自"Binary-rewrite"技术中的SSL类描述语言。
介绍Sleigh编写与适配指令集的文章已经很多了,这里我也就简单的介绍一下,有需要可以去看Ghidra的官方文档。
总得来说,一套完整的Processor描述应该由这么几部分组成:
- 语言总描述(.ldefs):描述这是什么架构、大小端、编译器等等
- ISA描述(.slaspec/.sinc/.pspec):最主要的模块,描述指令集、寄存器、中间语言对应关系等等复杂的情况
- 编译器/调用约定描述(.cspec):主要是描述不同编译器的调用约定,比如x86就有MSVC、GCC、Go等很多种可能的编译器,不同编译器都有单独的配置。
- 函数匹配(xxxpattern.xml):二进制形式的函数匹配,一般是用于匹配函数头。
5-3、对比IDA-Processor,Sleigh的优势是什么?
这是个很有意思的问题,我也不是编译领域的专家,如果说的不对麻烦大佬们指教指教。
在最初的binary-rewrite的QUBT论文中,作者提出了"相比于编写Processor代码,使用SSL描述语言工作量能减少一个数量级"的观点。
但是,在我把两边都尝试过之后,发现其实对于不熟悉的新手,两边的学习成本都很高。
IDA需要了解清楚Processor框架中,并且IDA的资料很少。还有一点,IDA缺少很多通用能力,比如,IDA似乎没有提供通用间接跳转处理的代码,恢复switch间接跳转的代码是非常难写的。
而Ghidra-Sleigh等于重新学习了一种语言,不过由于它和指令集架构很像,所以没有那么困难。并且Ghidra的反编译做了很多的工作,开发者不需要考虑别的,只需要”描述清楚“,剩下的交给反编译就行了。
所以,我个人觉得,在Processor编写中并不能减少什么工作量,还是一个体力工作。Sleigh的优势在于他的格式很规范,谁写都一样,因此写问题也很容易修。并且反编译器承担了很多麻烦的工作,我们只需要按部就班的"描述"就好了。
6、Decompiler反编译器
如果对反编译的实现细节有兴趣,可以先看看官方文档,(或者等我下一篇文章,但是不知道什么时候填好坑)
Ghidra提供了和IDA-F5同样的将中间语言"lift"到类C语言伪代码的功能。
但是和IDA的架构不同,Ghidra的反编译器是一个完全独立的进程,并且是一个完全独立的模块。而IDA中反编译模块是集成在主程序中。
并且Ghidra反编译器在设计时就是"架构无关"的,无论是什么指令集(哪怕是VMP),只要写好中间语言p-code的转换功能,Ghidra都能把他翻译成类C的伪代码。你看看隔壁IDA,一个指令集的F5支持都能卖个好几万。
6-1、完全独立反编译器的架构缺陷
完全独立的反编译器/进程,意思是反编译器可以独立编译并运行,上层Java应用通过开启进程并使用字符流与反编译进程进行交互。
但是,这种做法引入了很多的架构问题(我个人看法啊):
- 进程间通信会有很多额外的开销。
- 主Java程序和反编译模块
- 主Java程序和和反编译模块需要同时维护两套"二进制抽象";无法互相复用。
- 每当反编译需要上层的数据(比如我手动修改了函数签名),只能通过进程间通信获得,这使得类似功能开发十分的麻烦。
- 主Java功能和native反编译功能同时实现了一些功能类似的分析,无法重用代码。
- 无法展示反编译结果与汇编/中间语言的对应关系。
- Ghidra的字符流好奇怪,比较难看懂。
可以说,所有的麻烦,都是因为两边完全独立导致没法共享资源导致的。
6-2、从架构上对比IDA与Ghidra反编译的F5能力
个人感觉,无论是从反编译的效率还是准确率来说,毫无疑问,IDA就是这个领域的"行业标准"
但是如果需要重头支持一套新的指令集,那我一定选择Ghidra,毕竟IDA没有F5给我用。
大家都知道,IDA的反编译中层优化使用了8层转换,每向上一层中间语言就能缩减一部分,从下到上依次为:
- MMAT_GENERATED:类似于汇编
- MMAT_PREOPTIMIZED:在basic-block上构造def+use+kill关系
- MMAT_LOCOPT:在basic-block完成局部优化,构造CFG,处理基于规则的窥孔优化
- MMAT_CALLS:基于调用约定识别函数调用、参数、返回值
- MMAT_GLBOPT1:将call的各种block进行合并,全局优化,全局死代码消除
- MMAT_GLBOPT2:全局优化,全局常量传播与条件优化
- MMAT_GLBOPT3:全局窥孔优化
- MMAT_LVARS:局部变量还原
但是Ghidra不同,Ghidra将所有的优化代码全部塞到了coreation.cc一个文件里面。并且使用了类似于“不动点算法”的工作原理,不断的优化直到中间语言无法优化下去位置(不再改变)
我按照个人的经验,将Ghidra的反编译器中端从里到外、从前到后整理,依次为:
- action-base:通过流敏感技术,将机器码翻译成中间语言,识别函数,处理间接跳转等等。
- action-stackstall:抽象操作栈信息,恢复栈变量
- Varnode:还原高层变量信息
- action-rule:窥孔优化,通过预置的规则对语义进行等价还原
- typerecovery:还原类型信息
- struct: 还原控制流信息
Ghidra这种不断循环的算法,存在很大的性能问题,对于超大的函数往往会反编译超时。并且这种将优化代码全部塞到coreation.cc的做法。。。使得代码层次十分混乱。
这一篇文章就到这吧,后面是反编译器设计的内容了,再写下去太长了,留到以后的文章吧。
7、之后的内容?
如果有时间填坑?
后面将会详细说说Ghidra-decompiler反编译器F5组件的实现细节以及架构。
以及当反编译器出现问题的时候(比如花指令等混淆),如何进行修复。