select、poll和epoll的总结对比
综述
首先要搞明白两个基本概念:I/O复用和(非)阻塞机制。
I/O复用指的是允许计算机执行或者阻塞在一组数据流上,直到某个到达唤醒阻塞的进程,此时的I/O信道不仅仅是通过一个数据流,而是一组,所以是复用。
阻塞和非阻塞:拿I/O为例子,如果是阻塞模型,那么程序一直会等到有数据来的时候才会继续向下执行,否则会一直等待数据的到来;如果是非阻塞模型,如果有数据,那么直接读取数据向下执行,没有数据也会继续向下执行,不过此时可能会进行一些其他的操作,比如Linux中设置一些错误的比特位等。
select、poll和epoll这三个函数是Linux系统中I/O复用的系统调用函数。I/O复用使得这三个函数可以同时监听多个9文件描述符]()(File Descriptor, FD),因为每个文件描述符相当于一个需要 I/O的“文件”,在socket中共用一个端口。但是,三个函数的本身是阻塞的,因此即使是利用了I/O复用技术,如果程序不采用特别的措施,那么还是只能顺序处理每个文件描述符到来的I/O请求,因此这样默认服务器是串行的。而并发是把上面说的串行处理成同时或者同一时间段,本文暂时不讨论并发。
select
select是三者当中最底层的,它的事件的轮训机制是基于比特位的。每次查询都要遍历整个事件列表。
理解select,首先要理解select要处理的fd_set数据结构,每个select都要处理一个fd_set结构。fd_set简单地理解为一个长度是1024的比特位,每个比特位表示一个需要处理的FD,如果是1,那么表示这个FD有需要处理的I/O事件,否则没有。Linux为了简化位操作,定义了一组宏函数来处理这个比特位数组。
void FD_CLR(int fd, fd_set *set); // 清空fd在fd_set上的映射,说明select不在处理该fd
int FD_ISSET(int fd, fd_set *set); // 查询fd指示的fd_set是否是有事件请求
void FD_SET(int fd, fd_set *set); // 把fd指示的fd_set置1
void FD_ZERO(fd_set *set); // 清空整个fd_set,一般用于初始化
从上述可以看出,select能处理fd最大的数量是1024,这是由fd_set的容量决定的。
再看select的调用方式:
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
nfds:表示表示文件描述符最大的数目+1,这个数目是指读事件和写事件中数目最大的,+1是为了全面检查readfds:表示需要监视的会发生读事件的fd,没有设置为NULLwritefds:表示需要监视的会发生写事件的fd,没有设置为NULLexceptfds:表示异常处理的,暂时没用到。。。timeout:表示阻塞的时间,如果是0表示非阻塞模型,NULL表示永远阻塞,直到有数据来
struct timeval {
long tv_sec; /* seconds */
long tv_usec; /* microseconds */
};
有三个类型的返回值:
- 正数: 表示
readfds和writefds就绪事件的总数 - 0:超时返回0
- -1:出现错误
给出一个一般的通用模型:
int main() {
fd_set read_fs, write_fs;
struct timeval timeout;
int max_sd = 0; // 用于记录最大的fd,在轮询中时刻更新即可
/*
* 这里进行一些初始化的设置,
* 包括socket建立,地址的设置等,
* 同时记得初始化max_sd
*/
// 初始化比特位
FD_ZERO(&read_fs);
FD_ZERO(&write_fs);
int rc = 0;
int desc_ready = 0; // 记录就绪的事件,可以减少遍历的次数
while (1) {
// 这里进行阻塞
rc = select(max_sd + 1, &read_fd, &write_fd, NULL, &timeout);
if (rc < 0) {
// 这里进行错误处理机制
}
if (rc == 0) {
// 这里进行超时处理机制
}
desc_ready = rc;
// 遍历所有的比特位,轮询事件
for (int i = 0; i <= max_sd && desc_ready; ++i) {
if (FD_ISSET(i, &read_fd)) {
--desc_ready;
// 这里处理read事件,别忘了更新max_sd
}
if (FD_ISSET(i, &write_fd)) {
// 这里处理write事件,别忘了更新max_sd
}
}
}
}
这只是一个简单的模型,有时候还可能需要使用FD_CTL和FD_SET增加或者减少fd,根据实际情况灵活处理即可。
poll
可以认为poll是一个增强版本的select,因为select的比特位操作决定了一次性最多处理的读或者写事件只有1024个,而poll使用一个新的方式优化了这个模型。
还是先了解poll底层操作的数据结构pollfd:
struct pollfd {
int fd; // 需要监视的文件描述符
short events; // 需要内核监视的事件
short revents; // 实际发生的事件
};
在使用该结构的时候,不用进行比特位的操作,而是对事件本身进行操作就行。同时还可以自定义事件的类型。具体可以参考手册。
同样的,事件默认初始化全部都是0,通过bzero或者memset统一初始化即可,之后在events上注册感兴趣的事件,监听的时候在revents上监听即可。注册事件使用|操作,查询事件使用&操作。比如想要注册POLLIN数据到来的事件,需要pfd.events |= POLLIN,注册多个事件进行多次|操作即可。取消事件进行~操作,比如pfd.events ~= POLLIN。查询事件:pfd.revents & POLLIN。
使用poll函数进行操作:
#include 参数说明:
fds:一个pollfd队列的队头指针,我们先把需要监视的文件描述符和他们上面的事件放到这个队列中nfds:队列的长度timeout:事件操作,设置指定正数的阻塞事件,0表示非阻塞模式,-1表示永久阻塞。
时间的数据结构:
struct timespec {
long tv_sec; /* seconds */
long tv_nsec; /* nanoseconds */
};
给出一个常用的模型:
// 先宏定义长度
#define MAX_POLLFD_LEN 200
int main() {
/*
* 在这里进行一些初始化的操作,
* 比如初始化数据和socket等。
*/
int rc = 0;
pollfd fds[MAX_POLL_LEN];
memset(fds, 0, sizeof(fds));
int ndfs = 1; // 队列的实际长度,是一个随时更新的,也可以自定义其他的
int timeout = 0;
/*
* 在这里进行一些感兴趣事件的注册,
* 每个pollfd可以注册多个类型的事件,
* 使用 | 操作即可,就行博文提到的那样。
* 根据需要设置阻塞时间
*/
int current_size = ndfs;
int compress_array = 0; // 压缩队列的标记
while (1) {
rc = poll(fds, nfds, timeout);
if (rc < 0) {
// 这里进行错误处理
}
if (rc == 0) {
// 这里进行超时处理
}
for (int i = 0; i < current_size; ++i) {
if (fds[i].revents == 0){ // 没有事件可以处理
continue;
}
if (fds[i].revents & POLLIN) { // 简单的例子,比如处理写事件
}
/*
* current_size 是为了降低复杂度的,可以随时进行更新
* ndfs如果要更新,应该是最后统一进行
*/
}
if (compress_array) { // 如果需要压缩队列
compress_array = 0;
for (int i = 0; i < ndfs; ++i) {
for (int j = i; j < ndfs; ++j) {
fds[i].fd = fds[j + i].fd;
}
--i;
--ndfs;
}
}
}
}
代码中涉及到了一些压缩队列的操作,也可以不用这些。。。
epoll
epoll是一个更加高级的操作,上述的select或者poll操作都需要轮询所有的候选队列逐一判断是否有事件,而且事件队列是直接暴露给调用者的,比如上面select的write_fd和poll的fds,这样复杂度高,而且容易误操作。epoll给出了一个新的模式,直接申请一个epollfd的文件,对这些进行统一的管理,初步具有了面向对象的思维模式。
还是先了解底层的数据结构:
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events;
epoll_data_t data;
};
注意到,epoll_data是一个union类型。fd很容易理解,是文件描述符;而文件描述符本质上是一个索引内核中资源地址的一个下标描述,因此也可以用ptr指针代替;同样的这些数据可以用整数代替。
再来看epoll_event,有一个data用于表示fd,之后又有一个events表示注册的事件。
epoll通过一组函数进行。
创建epollfd
#include size用于指定内核维护的队列大小,不过在2.6.8之后这个参数就没有实际价值了,因为内核维护一个动态的队列了。
函数返回的是一个epoll的fd,之后的事件操作通过这个epollfd进行。
还有另一个创建的函数:
#include flag==0时,功能同上,另一个选项是EPOLL_CLOEXEC。这个选项的作用是当父进程fork出一个子进程的时候,子进程不会包含epoll的fd,这在多进程编程时十分有用。
处理事件:
#include epfd是创建的epoll的fd- op表示操作的类型
EPOLL_CTL_ADD:注册事件EPOLL_CTL_MOD:更改事件EPOLL_CTL_DEL:删除事件
fd是相应的文件描述符event是事件队列
等待事件
int epoll_wait(int epfd, struct epoll_event* evlist, int maxevents, int timeout);
epfd是epoll的文件描述符evlist是发生的事件队列maxevents是队列最长的长度timeout是时间限制,正整数时间,0是非阻塞,-1永久阻塞直到事件发生。
返回就绪的个数,0表示没有,-1表示出错。
给出官网上的一个模板:
#define MAX_EVENTS 10
int main() {
struct epoll_event ev, events[MAX_EVENTS];
int listen_sock, conn_sock, nfds, epollfd;
/* Code to set up listening socket, 'listen_sock',
(socket(), bind(), listen()) omitted */
epollfd = epoll_create1(0);
if (epollfd == -1) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
ev.events = EPOLLIN;
ev.data.fd = listen_sock;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, listen_sock, &ev) == -1) {
perror("epoll_ctl: listen_sock");
exit(EXIT_FAILURE);
}
for (;;) {
// 永久阻塞,直到有事件
nfds = epoll_wait(epollfd, events, MAX_EVENTS, -1);
if (nfds == -1) { // 处理错误
perror("epoll_wait");
exit(EXIT_FAILURE);
}
for (n = 0; n < nfds; ++n) {
if (events[n].data.fd == listen_sock) {
conn_sock = accept(listen_sock, (struct sockaddr *) &addr, &addrlen);
if (conn_sock == -1) {
perror("accept");
exit(EXIT_FAILURE);
}
setnonblocking(conn_sock);
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = conn_sock;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, conn_sock, &ev) == -1) {
perror("epoll_ctl: conn_sock");
exit(EXIT_FAILURE);
}
} else {
do_use_fd(events[n].data.fd);
}
}
}
return 0;
}
epoll的ET和LT工作模式
epoll的ET模式是默认模式,这也是select和poll的模式,即只要有事件发生,那么就会被epoll_wait所捕获,如果一次读写没有完成,那么会在下一次epoll_wait调用时接着被捕获;而ET边沿触发模式是读写没完成,下次不会被捕获,之后新的数据到达时才会触发。
EPOLLONESHOT事件
epoll特有的事件,操作系统上最多触发文件描述符上注册的一个可读、可写或者异常事件,只能触发一次,除非使用epoll_ctl重置该描述符。这在多线程编程时常用到,处理完毕后需要重新复原。
总结
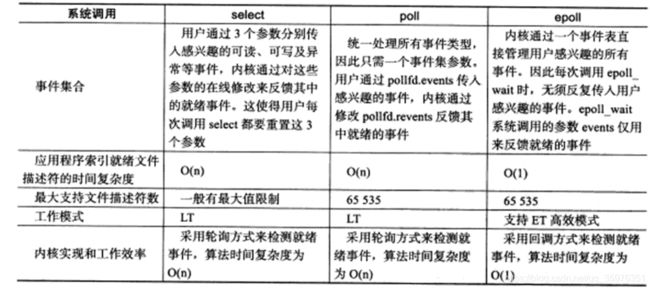
但是,如果是连接数量不是特别多,但是经常会有连接加入或者退出的时候,就要考虑poll或者select了。