【论文阅读】EasyEdit:Editing Large Language Models: Problems, Methods, and Opportunities (二)
【论文阅读】EasyEdit:Editing Large Language Models: Problems, Methods, and Opportunities
文章目录
- 【论文阅读】EasyEdit:Editing Large Language Models: Problems, Methods, and Opportunities
-
- 续
- 5. 初步实验
-
- 5.1 数据集和模型
- 5.2 基本结果
- 6. 综合研究
-
- 6.1 可移植性
-
- 6.1.1 数据集构建
- 6.1.2 结果
- 6.2 局部性
- 6.3 效率
-
- 6.3.1 时间分析
- 6.3.2 内存分析
- 6.4 批处理编辑分析
- 6.5 顺序编辑分析
续
(一)https://blog.csdn.net/qq_51392112/article/details/133748914


5. 初步实验
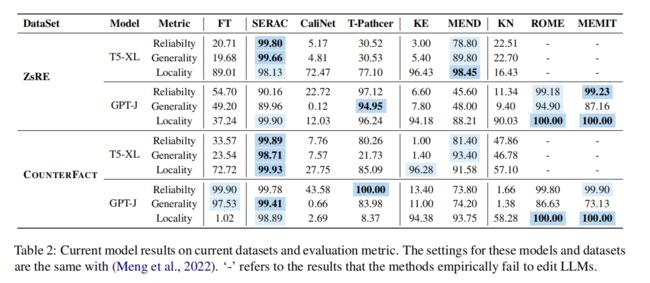
鉴于研究的流行和可用的数据集集中于事实知识,作者将其作为作者比较模型编辑技术的主要基础。通过使用如 表 2 所示的两个成熟的事实知识数据集进行初始控制实验,作者对各种方法进行了直接的比较,从而揭示了它们独特的优点和优缺点。
5.1 数据集和模型
数据集:包括 ZsRE 和 COUNTERFACT。
-
ZsRE(Levy et al.,2017)是一个问题回答(QA)数据集,使用由反向翻译生成的问题重组作为等价邻域。作者遵循之前的数据分割来评估测试集上的所有模型。对于需要训练的模型,作者利用训练集。根据之前的工作,作者使用自然问题作为范围外数据来评估位置。
-
COUNTERFACT(Meng et al.,2022)是一个更具挑战性的数据集,它解释了从一开始的反事实与正确的事实相比,得分较低。它通过将主体实体替换为共享一个谓词的近似主体实体来构造作用域外的数据。这种改变使作者能够区分表面的措辞变化和更重要的修改,对应于事实中有意义的变化。
模型:需要注意的是,以前的研究通常是在较小的语言模型(<1B)上进行实验,而忽略了语言模型(lm)中的不一致性。因此,作者选择了两个更大的模型作为基础模型: T5-XL(3B)和GPT-J(6B),包括编码器-解码器和仅解码器的架构。
-
由于一些原始的实现不支持这两种体系结构,所以作者重新实现了它们以适应这两种模型。然而,作者的实证研究结果表明,ROME和MEMIT只适用于像GPT-J这样的仅限解码器的模型,所以作者没有报道T5-XL的结果。
-
由于ZsRE数据集采用NQ数据集来评估局部性,在这里,作者使用在NQ数据集上细化的T5-XL模型(Raffel et al.,2020b)作为基线模型。至于GPT-J(Wang和小崎,2021b),作者使用原始的预训练版本来测试局部性的零样本结果。
-
除了现有的模型编辑技术之外,作者还额外检查了微调(FT)的结果,这是一种模型更新的基本方法。为了防止再训练所有模型层产生的计算费用,作者采用孟等人(2022)提出的方法对Rome识别的层进行微调。这一策略确保了与其他直接编辑方法的公平比较,加强了作者的分析的有效性。
5.2 基本结果
从表2中,作者注意到,
- SERAC 和 Rome 在ZsRE和反事实数据集上都表现出了卓越的性能,特别是SERAC,它们在多个评估指标上获得了超过90%的结果。
- 虽然MEMIT没有表现出与 SERAC 和 Rome 相同的通用性水平,但它在可靠性和位置方面表现得令人钦佩。
- 值得注意的是,ROME和MEMIT实现了最高的局部性性能(100%),而对不相关的情况的改变最小,即使他们编辑了模型的内在参数。
- 相比之下,KE、CaliNET和KN的表现则不佳。在以前的研究中,这些模型在较小的模型上显示出了希望,但是它们在较大模型中的编辑可靠性和泛化能力仍然很平庸。
- MEND在两个数据集上表现良好,在T5上的结果达到了80%以上,尽管没有Rome和SERAC那样令人印象深刻。然而,MEND在GPT-J上的性能并不那么令人印象深刻,这可能是由于模型的大小。
- T-Patcher模型的性能在不同的模型架构和大小之间波动。例如,对于ZsRE数据集,它在T5-XL上表现不佳,而在GPT-J上表现完美。在反事实数据集的情况下,T-Patcher在T5上获得了令人满意的可靠性和局部性,但缺乏通用性。相反,在GPT-J上,该模型在可靠性和通用性方面表现突出,但在局部性方面表现不佳。这种不稳定性可以归因于模型体系结构和数据集。T-Patcher在T5的最终解码器层中添加了一个神经元;然而,编码器可能仍然保留原始知识。此外,反事实数据集的局部性性能较差可能是由于数据集的构造,包括在句子中替换主语。因此,T-Patcher可能容易受到相似但不相关的句子的影响,导致表现不佳。就FT而言,它的性能并不如罗马那么好,即使在plm中修改了同样的位置。当应用于ZsRE数据集时,FT在几个指标上的性能都不是最优的。
- 在使用GPTJ的反事实数据集上,FT的可靠性和泛化能力与Rome的数据集相匹配。然而,它的位置得分相对较低,这表明FT可能会无意中影响不相关的知识领域。这表明了FT的一个关键局限性,证明了Rome在保持模型中不相关知识的完整性方面的优越性。
6. 综合研究
鉴于上述考虑,作者认为以前的评估指标可能太严格,无法充分评估模型编辑能力,因此作者提供了关于可移植性、局部性和效率的更全面的评估。
6.1 可移植性
许多研究评估了通过反向翻译产生的样本的通用性(De Cao et al.,2021),但这往往忽略了知识编辑的影响,而不是简单的释义。这些释义的句子通常只涉及措辞的表面变化,并不反映对事实信息的重大变化。为了确保这些方法能够为现实世界的应用做好准备,确定它们是否能够解释编辑的后果是至关重要的。例如,如果作者把“瓦茨·汉弗莱是上哪所大学的?”从“三一学院”到“密歇根大学”,当被问到“瓦茨·汉弗莱在大学时,模特应该回答“密歇根州的安娜堡”,而不是“都柏林在爱尔兰”学习期间住在哪个城市?”
因此,作者引入了一种新的评估度量,称为可移植性,以评估模型编辑在将知识转移到相关内容方面的有效性,以及编辑后的语言模型将修改后的知识用于下游任务的潜力。作者将一个新的部分,P(xe,ye),合并到现有的数据集ZsRE和反事实中,当应用于P(xe,ye)中的推理示例时,可移植性被计算为编辑模型(fθe)的平均精度:

6.1.1 数据集构建
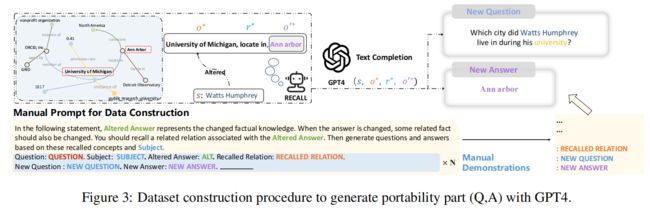
在数据集构建的过程中,作者使用GPT-4来生成相关的问题和答案(参见图3)。假设在原始编辑中,作者将关于主题s的问题的答案从o改为o∗。
- 最初,作者提示模型生成一个与修改后的答案相关联的三重∗(o∗,r∗,o ‘∗),其中s是改变后的响应。
- 随后,GPT-4基于原始查询中的主题(∗,∗,∗)提出一个问题。值得注意的是,如果该模型能够回答这个新问题,这就意味着它具有预先存在的三重知识(o∗,r∗,o 0∗)。
- 因此,作者过滤掉了模型不熟悉的三元组。
- 具体来说,作者将o∗和r∗作为输入,并指导模型预测o’∗。如果模型成功地生成o‘∗,作者推断它拥有三重的知识。
- 最后,作者让人类评估者来验证三重体和问题的准确性。
- 为了指导GPT-4生成所需的问题和答案,作者使用了几个镜头的演示作为一种教学方法。更多详情请见附录B。
6.1.2 结果
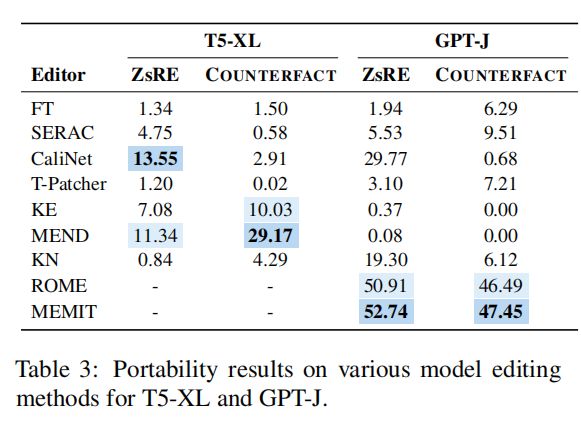
作者根据新提出的评价度量进行了实验,结果如表3所示。如表所示,当前的模型编辑方法在可移植性方面的性能有些次优。大多数的编辑方法,包括KE、KN、MEND 和 CaliNET,都无法将改变后的知识转移到相关的事实中。尽管 ERAC 在之前的指标上显示出了完美的结果,但在可移植性方面的准确率低于10%。这些结果似乎是合理的,因为分类器努力有效地将句子分类为反事实模型,而原始模型中的知识保持不变。如果分类器能够识别出修改后的句子,次要的反事实模型,受到其弱推理能力的限制,可能仍然缺乏必要的相关信息。出乎意料的是,ROME和MEMIT在可移植性方面表现出了相对值得称赞的性能(在ZsRE上超过50%,在反事实上超过45%)。它们不仅能够编辑原始的案例,而且还能够在某些方面修改与它们相关的事实。它们令人印象深刻的可携性进一步证明了它们的定位方法的有效性和实用性,因为该模型将在需要时使用这些知识。MEMIT 比罗马性能更好的一个原因是它编辑了更多的层,使知识在应用程序中被使用的机会更大。
- 综上所述,目前的模型编辑方法在准确回答有关相关主题的问题方面仍然不足,其答案已被编辑示例的内容所暗示。这是一个需要在未来进行进一步探索的领域。
6.2 局部性
- COUNTERFACT 和 ZsRE 从不同的角度度量模型编辑的局部性。

COUNTERFACT 利用与目标知识相同分布的三元组,而 ZsRE 使用来自不同分布的问题,即自然问题任务。除了其他知识之外,技能神经元(Wang et al.,2022)表明,llm中的前馈网络具有特定任务知识的能力,这引发了新的挑战,特别是模型编辑是否会影响其他任务的表现。具体地说,模型编辑对模型的影响是多方面的,具有挑战性。因此,评估模型编辑的局部性需要考虑模型的主要目的以及预期的编辑范围,如图4所示。
- 首先,编辑器不应该编辑来自相同发行版的信息。如图所示,在编辑“唐纳德·特朗普”的位置时,“唐纳德·特朗普”的其他特征,比如公共时间,不应该改变。与此同时,与“总统”具有相似特征的“国务卿”等其他实体也不应受到影响。
- 其次,对于针对特定任务的任务的模型,作者可能只需要考虑它们对目标任务的影响,而不考虑其他能力。
- 更重要的是,对于任务不可知的模型,考虑它们对来自不同分布和不同任务的知识的表现是至关重要的。
- 请注意,一些方法,如MEND,在局部数据集上使用KL散度来训练模型。这也可以将模型的焦点限制在目标数据上,而不涉及局部性的其他方面。这也是一个在未来需要进行进一步探索的领域。
6.3 效率
尽管这些方法取得了成功,但考虑模型编辑的效率也至关重要对于实际应用。一个高效的模型编辑器应该在不影响模型性能的情况下,最小化计算和评估编辑所需的时间和内存。
6.3.1 时间分析
编辑时间是指执行模型编辑过程所需的持续时间,其中包括更新模型的参数,以反映所需的更改。从表4中,作者注意到一旦得到训练好的超网络,KE和MEND要快得多。SERAC还可以快速编辑知识,用5秒钟进行10次编辑。但是,这些方法需要每天数小时的额外培训费用。在作者的实验中,
- 使用ZsRE数据集训练MEND需要超过7小时,而使用3×V100训练SERAC需要超过36小时。
- 其他方法,如KN、CaliNET、ROME和MEMIT,都低于MEDN,但在编辑前不需要训练。
- CaliNET很快,但结果正常,而罗马和MEMIT可能需要更多的时间,但取得优秀的性能。
- T-Patcher是最慢的方法,因为它需要为每次编辑训练神经元。

6.3.2 内存分析
此外,考虑模型编辑对模型存储所需空间的影响是至关重要的。作者在图5中展示了每个方法的内存 Vram 使用消耗量。从图中,作者可以看到,大多数方法消耗的内存量大致相同。引入额外参数的方法会产生一些额外的计算开销。总之,一个高效的模型编辑器应该在模型性能、推理速度和存储空间需求之间取得平衡。

6.4 批处理编辑分析
作者进一步进行批编辑分析,因为许多研究通常最多只能更新几十个事实,或只关注单个编辑案例。通常,作者需要同时使用多个知识片段来修改模型。在这里,作者将集中研究支持批处理编辑的方法(包括FT、SERAC、MEND和MEMIT),并在图6中绘制了性能。在这种情况下,作者不评估KE和CaliNET,因为它们在llm上的单一编辑性能是次优的。
作者注意到,MEMIT是一种独特的方法,能够支持对llm的大量知识编辑。它可以同时编辑数百甚至数千个事实,而同时需要最小的时间和内存成本。即使进行多达1000次编辑,这两个指标的性能都保持稳定和优秀(原始论文表示MEMIT可以同时编辑超过10,000个案例)。此外,MEMIT在同时执行广泛的知识编辑时,保持了较高的局部性和通用性。其他方法也支持批处理编辑,但需要大量的内存来处理更多的情况,这超出了作者目前的能力。因此,对于这些方法,作者将批编辑测试限制在100个。SERAC可以支持多达100次的多次编辑,并保持良好的性能,因此作者将作者的测试限制在这个数字上。其余两种方法,FT和MEND,在批处理编辑中表现不佳。随着编辑次数的增加,模型的性能迅速下降。此外,除了性能之外,MEND和SERAC还需要为每批编辑训练一个独特的模型,这在实际上是不可行的。

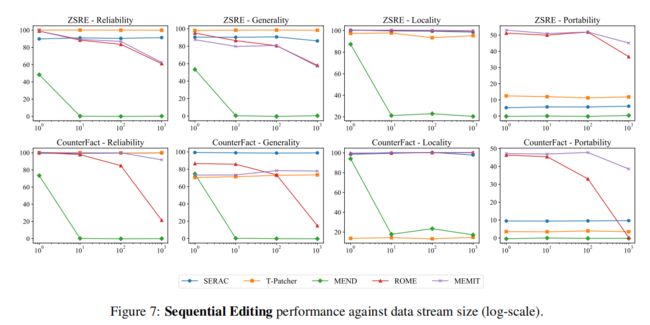
6.5 顺序编辑分析
除了同时进行多次编辑外,按顺序进行编辑的能力也是模型编辑的一个基本特征(Huang et al.,2023)。在实际设置中,在执行新的编辑时,模型应该保留来自以前编辑的更改。为此,分析时,作者在数据流(x1、y1)、(x2、y2)、…,(xs、ys)中编辑模型,在其中模型依次执行编辑。图7中绘制了性能与编辑次数的关系。在本节中,作者将选择具有可靠的单次编辑性能的模型来评估它们在顺序编辑中的能力。结果表明,SERAC和T-Patcher在连续编辑过程中表现出了良好且一致的性能。实际上,冻结模型参数和使用外部参数进行模型编辑的方法在顺序编辑中通常显示出稳定的性能。罗马在达到n = 10时表现良好,但在n = 100时开始退化。MEMIT超过100人的表现也下降了,但不如罗马那么多。类似地,MEND在n = 1时表现令人钦佩,但在n = 10时迅速下降。改变模型参数的方法需要进行顺序编辑,因为它们的编辑算法是基于初始模型的。随着编辑过程的继续,模型越来越偏离初始状态,导致其性能次优。