Windows控制台中文乱码问题测试、分析与解决
文章目录
- 一、测试
-
- A、Win10系统
- B、Win7 SP1系统
-
- 1.VSCode+GCC
- 2. VS2015
- 二、分析与总结
-
- 1. VS2015
- 2. MinGW
- 三、解决UTF8的乱码问题
-
- 1. 设置参数
- 2. 使用替换函数
随着Visual Studio占用的空间的越来越大,有很多东西也许我们根本就用不上。而VSCode + msys2 + Mingw也许是一个不错的选择,编写控制台类应用程序完全是可以的。但是控制台类应用程序内的中文输出会有一些问题,可能会产生乱码。
下面笔者以VSCode 1.48.0+msys2+Mingw64+gcc 10.2.0为基本环境测试在Win10与Win7下的情况。
一、测试
A、Win10系统
如果是在Windows 10 October 2018 Update (build 1809)及以后的系统中应该是没有这种问题了,笔者在Win10 1909系统中使用VSCode+msys2+MinGW+GCC测试未发现有乱码。
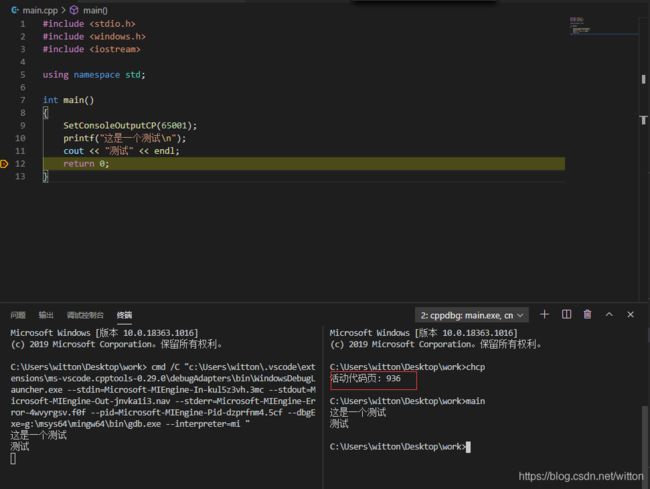
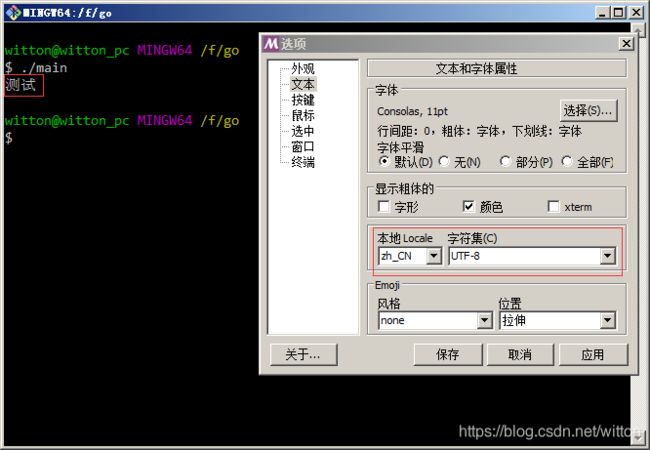
测试程序main.cpp为UTF8编码:
#include 在VSCode终端调试显示如图:
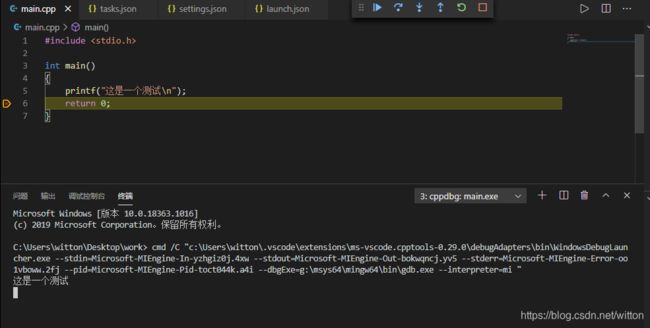
在调试终端输入chcp查看控制台CodePage为65001,即为UTF8。也就是说VSCode自动将调试终端设置为UTF8来显示输出。
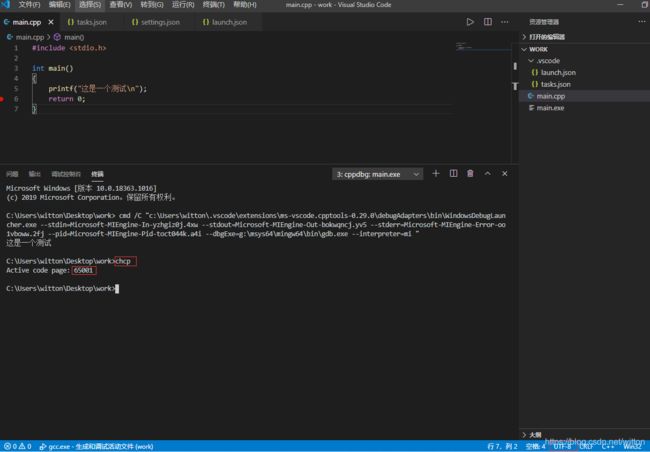
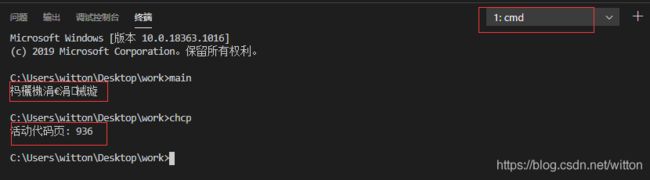
再看看默认的控制台终端,显示的乱码,因为默认控制台终端使用的活动代码页为936,即GBK编码。
使用chcp 65001手动改变代码页为UTF8编码就正常显示了。

我们也可以在代码中直接设置使用UTF8代码页显示:
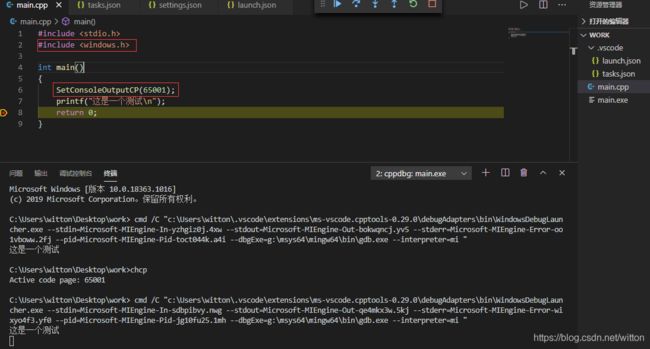
即使用:
SetConsoleOutputCP(65001);
来设置控制台输出代码页为UTF8,现在使用默认的控制台运行可以看到936代码页下也能正常显示。

我们再试试C++的cout:
可以看到一切正常。
B、Win7 SP1系统
1.VSCode+GCC
还是前面的测试程序,但是调试控制台显示的是乱码:

查看调试控制台代码页为65001,即UTF8,与Win10下的一致,但输出为乱码。
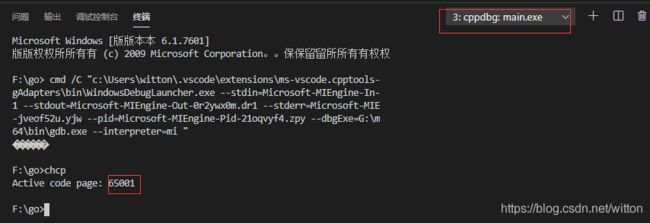
再在默认控制台终端测试,一样是乱码,不管是936,还是65001代码页。
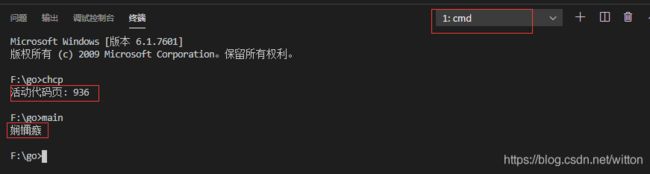

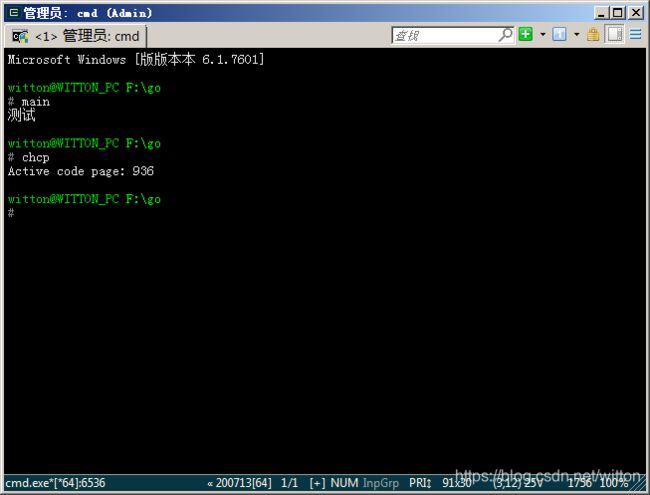
所以即使在代码中使用SetConsoleOutputCP(65001)来设置输出终端代码页为UTF8也没用,但是为了方便起见,我们后面的测试还是都使用代码设置了输出终端为UTF8的代码。

我们在Windows自带的cmd.exe中运行,一样是乱码

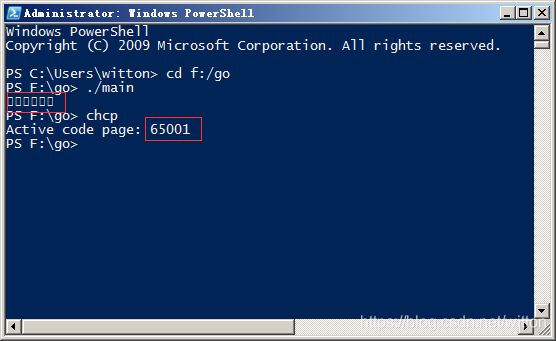
在Win7的PowerShell中运行一样是乱码。
但是在git bash中显示正常
在ConEmu壳中也是显示正常。
也许有人要说VSCode可以设置默认的终端为git bash,我们来试试:
在settings.json中添加一行
"terminal.integrated.shell.windows": "C:\\Program Files\\Git\\bin\\bash.exe",
或者执行“选择默认shell”,在弹出的选项中选择Git Bash,然后重启VSCode。
我们进行编译会失败:
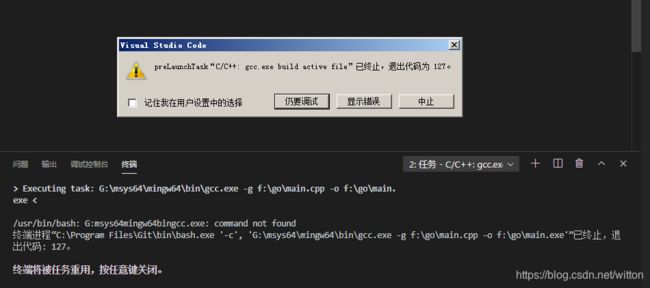
我记得VSCode1.47是可以的,估计是更新后的BUG,原因就是使用Windows的路径分隔符问题,Bash需要的是/而不是\。我们先手动编译:
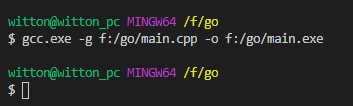
然后调试,发现调试终端依旧是乱码。
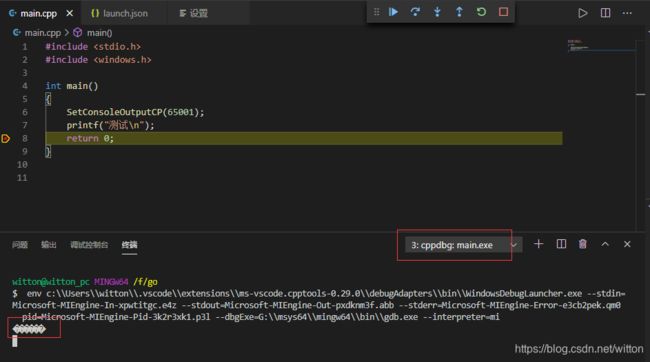
我们把在Win7下生成的exe拿到Win10下运行,也可以正常显示。
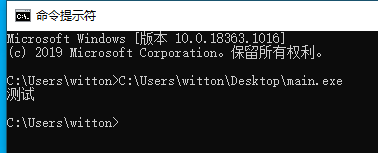
2. VS2015
VSCode+GCC的方式有问题,我们试试MSVC,笔者使用的VS2015,源文件依旧使用UTF8编码,无
/source-charset:utf-8
编译参数,控制台属性未作任何修改(如果控制台属性有修改过的话会在注册表中留下设置,会影响后面的运行显示,特别是代码页与字体)。

运行结果:
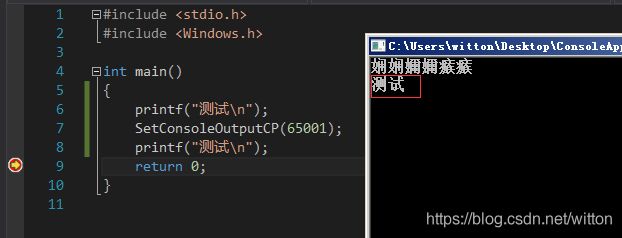
可以看到在设置输出终端代码页为UTF8之前是乱码,但是设置之后就显示正常了。
我们再看看C++的cout输出:
#include 
可以看到第三行显示的是乱码,说明cout与printf函数处理方式不一样。
二、分析与总结
通过前面的测试, 我们发现Win10上控制台对UTF8的支持比较好,毕竟是新系统,只要控制台的在输出时的编码与字符编码一致即可正常显示。
而Win7下使用Mingw进行编译后,不借助第三方软件,使用系统自带的控制台,无论怎么弄,只要是UTF8的输出都是乱码;而VS2015编译的代码,printf函数的输出只要设置为UTF8终端就可以正常显示,cout的输出一样是乱码。
我们首先想到的那肯定就是MinGW的printf函数以及VS和MinGW的cout都有问题。
1. VS2015
我们首先看一下VS2015 printf函数最后调用的输出函数为:WriteFile,它是一次性将内容写入控制台终端。
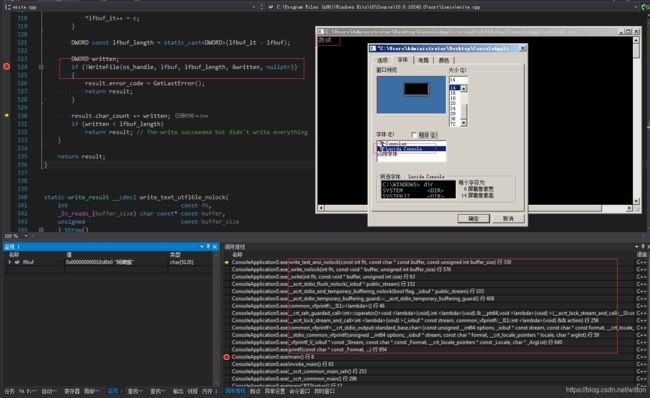
要想调试CRT源码需要使用参数:多线程调试(/MTd),源码位置:C:\Program Files (x86)\Windows Kits\10\Source\10.0.10240.0\ucrt\stdio
我们再看看cout的情况:
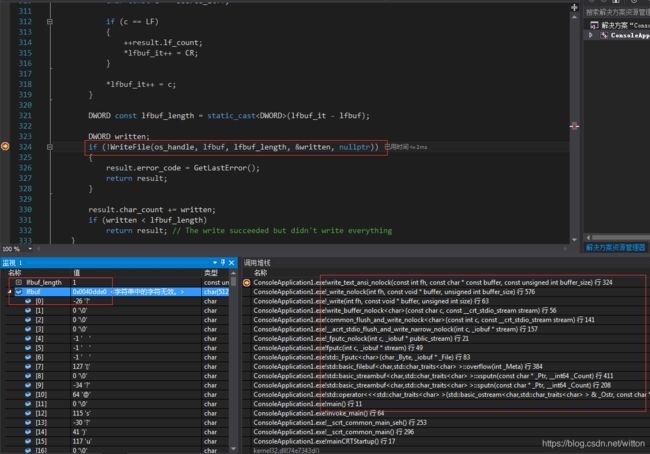
可以看到,虽然最后也是调用的WriteFile写入终端的,但是它是一个字节一个字节写入的,所以汉字就成了乱码了,从前面的图中看到“测试”这两个汉字输出了6个乱码块,因为一个汉字的UTF8编码为3个字节。
2. MinGW
我们再看看MinGW的情况:通过查找MinGW CRT的源码(Git地址:https://git.code.sf.net/p/mingw-w64/mingw-w64),发现其printf最后都是调用的fputc函数进行单个字节输出的,它的输出方式与VS下的cout一致,所以都是乱码。
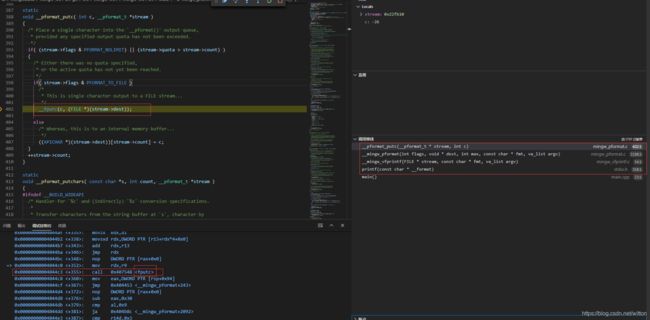
但是同样的程序在Win7下显示乱码,在Win10下却显示正常。
所以根本问题还是系统终端的问题,Win7系统对UTF8的支持不友好,而Win10要好很多。
Win7的终端不是流式设备,所以不支持流式输出,如果一个字节一个字节的输出,它是无法组成一个完整的字符来显示的,因为UTF8编码的字符串在输出的过程中需要将前面已经输出的字节删除掉,组合成一个真正的字符重新输出。
在网上搜集到了两篇文章对此作了比较深入的测试、分析与讲解:
Windows Command-Line: Unicode and UTF-8 Output Text Buffer
Properly print utf8 characters in windows console
三、解决UTF8的乱码问题
1. 设置参数
GCC编译器有两个命令行参数:
-finput-charset=XXX
-fexec-charset=XXX
我们可以设置在Windows下的-fexec-charset=GBK,如果源码为UTF8编码,设置-finput-charset=UTF-8,这样编译器会自动把字符串转为GBK编码,控制台下可以正常显示,但是VSCode的调试终端还是会是乱码,因为VSCode的调试终端的编码为UTF8。
另外,如果项目换成Clang编译器的话,目前Clang编译还不支持除UTF-8外的其它编码,不管是-finput-charset还是-fexec-charset。
所以设置参数的方式不通用。
2. 使用替换函数
根据文章中的测试与我们发现的特点,我们可以在Win7中尝试使用一次性写入终端的函数来输出。我们先使用puts函数来输出:
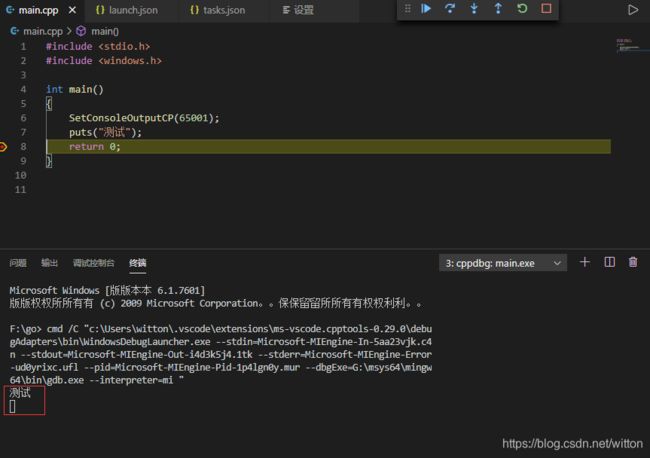
可以看到正常显示了,但是有一个换行符,MSDN中的说明,该函数会把字符串结束符\0换成换行符\n来输出。
为了不让puts画蛇添足进行换行,我们换一种方式:使用snprintf+fputs,可以看到是原样输出了。
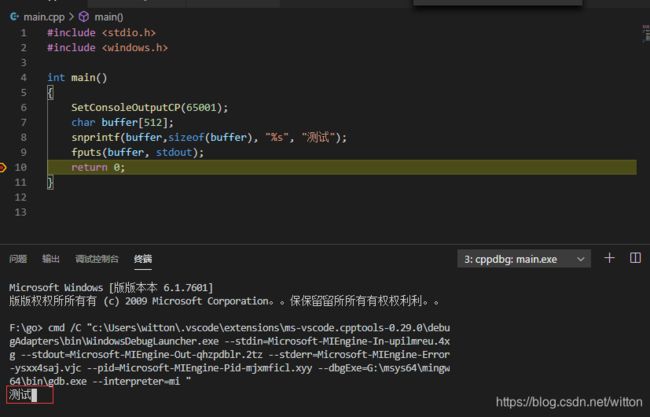
为了实现Win7与Win10一致体验,我们完全可以使用自定义的函数来代替Mingw CRT中的printf函数,最简单直接的方式就是定义一个printf宏了。
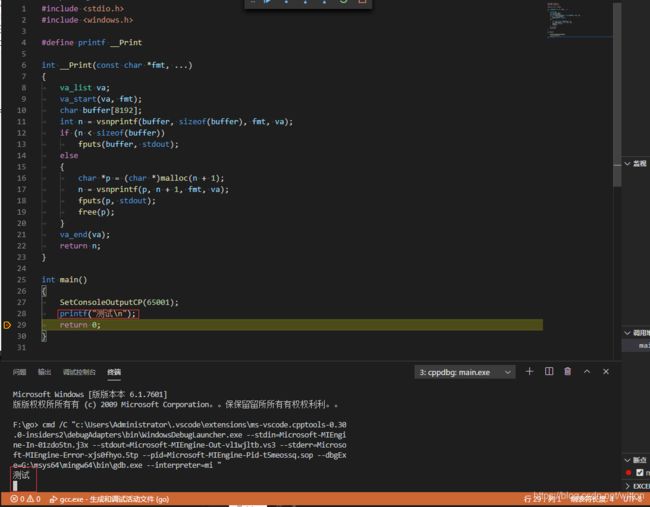
#define printf __Print
int __Print(const char *fmt, ...)
{
va_list va;
va_start(va, fmt);
char buffer[8192];
int n = vsnprintf(buffer, sizeof(buffer), fmt, va);
if (n < sizeof(buffer))
fputs(buffer, stdout);
else
{
char *p = (char *)malloc(n + 1);
n = vsnprintf(p, n + 1, fmt, va);
fputs(p, stdout);
free(p);
}
va_end(va);
return n;
}
前面只处理了printf,还有cout,下面把最终版本的源码附上:
#define printf(fmt, ...) __fprint(stdout, fmt, ##__VA_ARGS__ )
int __vfprint(FILE *fp, const char *fmt, va_list va)
{
char buffer[8192];
int n = vsnprintf(buffer, sizeof(buffer), fmt, va);
if (n < sizeof(buffer))
fputs(buffer, fp);
else
{
char *p = (char *)malloc(n + 1);
n = vsnprintf(p, n + 1, fmt, va);
fputs(p, fp);
free(p);
}
return n;
}
int __fprint(FILE *fp, const char *fmt, ...)
{
va_list va;
va_start(va, fmt);
int n = __vfprint(fp, fmt, va);
va_end(va);
return n;
}
std::ostream &operator<<(std::ostream &out, const char *str)
{
__fprint(stdout, str);
return out;
}
需要注意的是:如果是在MSVC 2015及以后版本,强烈建议使用
/utf-8
编译参数,让编译器把源码与运行期都处理成UTF8编码。如果源码是老项目,以前都是GBK编码,可以分开使用下面两个参数:
/source-charset:gbk
/execution-charset:utf-8
你的关注、点赞、打赏是我写作的动力