接口测试+自动化接口测试详解
1:json模块的使用
字典是一种存储类型,json是一种格式(完全不同)
json.loads()函数是将json字符串转化为字典(dict)
json.dumps()函数是将字典转化为json字符串
json.dump()和json.load()主要用来读写json文件函数
2:接口自动化测试概叙
什么是接口测试:
前后端不分离:淘宝网站(响应的数据在页面,访问响应的数据是html的)返回的是一整个html(做接口难,需要解析数据,因为返回的是整个html代码)
前后端分离,前端和后端通过api(接口交互),返回的只是数据本身(App可能并不需要后端返回一个HTML网页)
(市面上主流项目前后端分离走json格式的)
发请求以json数据格式返回的,通过api接口协议前后端进行交互的
3:swagger工具能导出接口文档的
4:前端页面:
安卓或者ios app,网页统层为前端展示(数据展示和用户的交互),
前端框架:html,js,css,vue(展示漂亮),nodejs
5:后端:
后台数据处理,校验,下订单等等业务处理(c语言,c++,java(大型都走java),go,python)
6:前端和后端的数据交互(接口)通过接口
有些问题前端可能屏蔽,但是后端没有做限制,校验都没有做的,绕过前端,抓包发请求的方式攻破后端,项目可能出现问题
7:接口的概念
接口是应用程序之间的相互调用
接口是实体或者软件提供给外界的一种服务
软件接口:api,微信提现调用银联的接口实现数据交互
一种是内部接口:
1:方法与方法之间的交互 2:模块与模块之间的交互
一种调用对外部包装的接口
web接口:http,https,webserver(目前大多做web接口)
应用程序接口:soket接口 走的tcp/ip协议的
数据库接口:
8:常用的接口方式(协议)
1:webservice :走soap协议通过http传输,请求报文和返回报文都是xml格式的,xml格式(soapui抓包)老项目(政府和银行)
还要解析数据,麻烦,而且速度可能有降低,通信比较严格
2:http协议:超文本传输协议(百分之70-80都走的http协议) get post delete put四种主要的请求方式
3:https协议:并非是应用层的一种新协议,只是http通信接口部分用ssl和tls协议代替而已
9:什么是接口测试:
项目需需求
案例:一个登录接口
场景:产品上规定用户名6-10个字符串下划线
测试人员在前端做了校验,通过
后端开发人员没有做校验
风险:直接抓包取篡改你的接口,然后绕过验证,通过sql注入直接随意登录
危害:公司损失
接口测试是市场的主流需求
10:接口测试目标
可以发现客户端没有发现的bug,(隐藏的bug)(提交订单,前端屏蔽了后端没有,可以随便乱填的)
及早爆出风险(保证质量正常上线)
接口稳定了,前端随便改
最重要加内存系统安全性,稳定性
11:接口自动化测试概叙(怎么做) (接口跑的是协议层。ui定位的是元素)
1:项目业务(了解项目业务)
2:接口文档(api文档)
3:接口用例
4:自动化脚本(根据接口文档和接口用例)
5:pytest框架 重点
6:调试执行 重点
7:allure报告
8:结果分析
9:持续集成
12:http协议概述
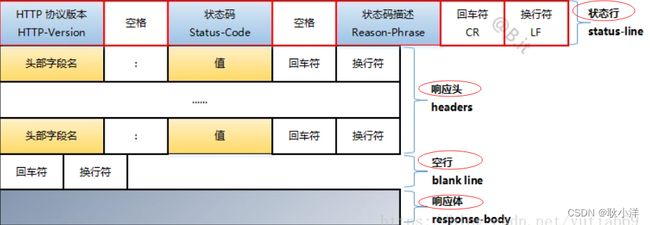
一:http响应报文包含四部分:如上图 1:请求行:主要包含信息:POST (请求方法)/search(请求url) HTTP/1.1 (http协议及版本)

二:http请求报文包含四部分:如上图
1:请求行: POST (请求方法)/search(请求url) HTTP/1.1 (http协议及版本)
2:请求头 请求头,项目可能有防爬操作,python等语言请求被屏蔽,所以可能需要加头伪装
3:请求空行
4:请求体(请求正文)
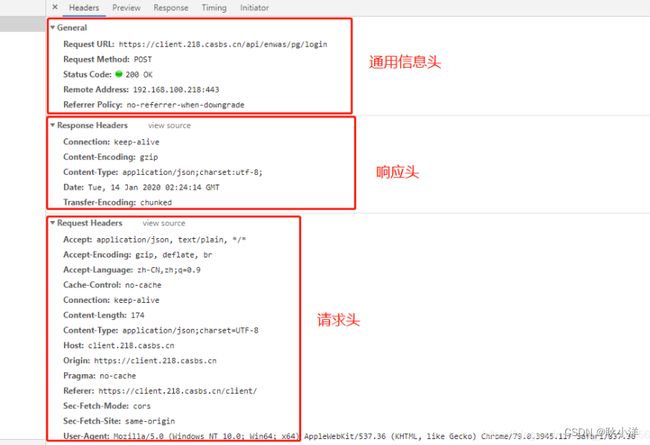
三:通过谷歌浏览器F12分析http报文(如上图)
Host : 主机ip地址或域名
User-Agent :用户客户端,比如说操作系统或者浏览器的版本信息,
(客户端相关信息,如操作系统,浏览器信息)可能拿到User-Agent去做兼容的,
服务器拿到User-Agent服务器生成兼容客户端的文本
浏览器需要服务器发回兼容我浏览器的版本,服务器拿到信息作一个判断,
Accept: 接收的意思,指定客户端接收信息的类型,(我想接收的是一个图片还是html还是json还是一个xml文档告诉服务器,服务器对应返回)
如imag/jpg/,text/html,有时候我们一个接口给很多系统公司去用,这个系统可能想要的xml就告诉服务器你给我传递xml数据
有些公司想要的是json数据(主流都是json格式)告诉服务器你给我json
这里可以在请求头域设置Accept告诉服务器我需要的内容的格式
Accept-Charset :客户端接收的字符集,客户端接收字符集告诉服务器:如gb2312,iso-8859-1,utf-8
Accept-Encoding: 可接受内容的编码,如:gzip压缩格式, deflate
(为了方便进行内容的传输,节省传输时间,提供传输效率,可能进行一些编码和压缩,节省传输流量)
Accept-Language:接受的语言,如Accept-Language: zh-CN,zh;q=0.9 ,做国际化可以识别这里,中文环境给我中文数据
Authorization:客户端提供给服务端,进行权限认证的信息(进行权限认证的,请求的话有个鉴权的这样的功能,
不是说想什么服务器就发给什么,有可能需要进行一些基本的认证,认证信息可以放在这里)
Cookie:携带的cookie信息 非常重要的字段(我登录成功之后就会在本地保存一些cookie,保存一些文本,
下一个请求的时候直接把cookie发给服务器,告诉服务器我已经登录了,有一个证明在这里cookie携带回去)做校验的
Referer:当前文档的URL,即从哪个链接过来的(我这个请求到底从那个连接过来的)
比如:Referer: http://test.lemonban.com/ningmengban/app/login/login.html登录的这个连接
是从login/login.html从我们这个网站的首页来的,防止盗链,把这个链接盗取了用到自己网站去,
或者说可以统计我这样的一个请求到底来自于那个页面,
Content - Type:请求体内容类型,请求构建以什么形式传递参数的,如:x-www-form-urlencoded表单形式
(往服务器提交内容,告诉服务器我提交的内容是什么格式的,表单,json格式,xml格式)
Content - Length:数据长度 ,(提交内容的数据长度有多少个字节告诉服务器,防止进行请求的篡改)
Cache-Control:缓存机制,如Cache-Control:no-cache :别给我缓存 ,有些请求会缓存到本地的,
Pragma:防止页面被缓存,和Cache-Control:no-cache作用一样(1.0中间的,为了兼容和1.0)
四:cookie
第一次访问网站,如果网站有cookie机制,访问第一个请求的时候返回set-cookie
set-cookie设置cookie值,通过响应数据的头,响应头里面通过set-cookie把值给客户端,获取cookie里面对应的值
13:fiddler(抓包工具的使用)
fidder的使用技巧(能抓包,查看抓包数据):
能抓取https要设置证书
(免费的,开源的,能抓很多对应消息,app的也可以)
fidder是一款免费,灵活,操作简单,功能强大的http代理工具,是目前最常用的http抓包工具之一
可以抓取所有的http/https包,过滤会话,分析请求详细内容,伪造客户端请求,篡改服务器响应,重定向,网络限速,断点调试等功能
fiddler的工作原理:
正向代理(正向代理服务器,通过浏览器发送请求以前是直接发给服务器,fidder转发(代理服务器),
浏览器请求发给fidder代理服务器,fidder代理服务器转发给服务器,
服务器数据转发给fidder代理服务器,代理服务器发给浏览器
正向代理:
转发浏览器的请求和响应,抓包工具 对客户端透明
反向代理:
nginx——负载均衡的——性能 一个服务器
tomcat db(现在用户级别很大,一个tomcat搞不定,需要帮手,三个tomcat分担流量(怎么协调加nginx--负载均衡))
浏览器发请求过来,不知道请求发给谁,请求量很大,通过nginx把请求分发到各个tomcat里面去,避免的一个tomcat承受不住
14:接口工具对比:(掌握fidder)
fidder 免费的http查看工具,系统代理,工作在应用层 独立运行(是) 支持移动设备(是) 是否收费(否)
wireshark 网络抓包,监听网卡,工作在网络接口层 独立运行(是) 支持移动设备(否) 是否收费(否)
httpwatch 集成到IE,chrome中的网页数据分析工具 独立运行(否) 支持移动设备(否) 是否收费(基础版/专业版)
charles http代理,http监控,http反代理,查看http通讯查看信息工具 独立运行(是) 支持移动设备(是) 是否收费(是)
ByrpSuite http代理,用于工具web应用程序的集成平台, 独立运行(是) 支持移动设备(是) 是否收费(是)
包含了很多工具,抓包,漏扫,爆破,黑客必备工具之
wireshark--底层,网络层--用这个
15:websocket: (和http一样是传输协议)
websocket传输协议实时性强 使用场景: 聊天系统 股权交易 直播--部分业务
16:cookie详解
服务器发给客户端:请求的响应数据 响应头:Set-cookies 本地存放cookies攻击
cookie缓存身份的概念:a请求发给服务器,a第一个请求没有带cookie,比如登录操作一开始请求不带cookie的,服务器响应把cookie放到响应头:set-cookie
浏览器拿到set-cookie会自己进行处理,然后第二个请求发出去,就会带上cookie进行校验
浏览器访问里面自己传递,但是接口请求是不会自己带cookie的,需要提取cookie
a响应头里面把cookie拿出来,放到一个变量,下一个b请求把cookie放到请求头
不同用户的cookie不一样的,不然会冲突的
cookie里面包含很多内容:但是最常见的是sessionid(会话id)
简单项目里面有cookie就差不多了,但是有的项目里面cookie里面带token-复杂点
cookie是分站点的,站点和站点之间的cookie是相互独立的
浏览器的cookie是保存在浏览器的某个位置
服务器端可以通过:响应头中的set-cookie参数,对客户端的cookie进行管理
浏览器的每次请求,都会把该站点的cookie发送给服务器进行匹配校验
实现登录:cookie+session配合使用
cookie不是只有登录,发送请求访问首页都有cookie。
cookie放在浏览器本地的(缓存里面),sessionid放在服务器的上
sessionid必须寄生在cookie里面,搭配cookie一起使用(sessionid值一般在cookie里面传过去的)
17:sessionid:翻译为会话id
sessionid就是会话id 身份验证-存放到 服务器
session是一个对象,是服务器产生的,保存在服务器中,
session有自己的管理机制,包括session产生,销毁,超时等
session id是session对象的一个属性,是全局唯一的,永远不会重复
18:cookie和sessionid合作流程(常见的方式)
一:快速理解
用户登录成功服务器创建session,返回给客户端,客户端浏览器把session保存到它的cookie里
二:过程描述
登录成功服务器立马创建session,并通过(响应头)中的set-cookie属性把session返回给客户端
浏览器把响应头中的set-cookie内容保存起来,存在浏览器自己的cookie中
以后浏览器每次发送请求时,都会把该站点的全部cookie封装到请求头中,传递给服务器
19:tooken:令牌
token:
令牌(令牌代表身份信息,身份标识----身份校验(数据库db校验,每发个请求就需要校验很麻烦,避免频繁访问数据库,token就表示身份))
cookie和token(cookie里面最关键的就是session id值)
cookie里面有时候有sessionid和token值
一般为了减少对数据库的访问,校验,数据库的账号密码,
做个令牌:token需要身份校验,账号密码校验,获取token值(返回token字符串))
token也是由服务器参数的,存在服务器的内存或者硬盘中
有一套产生规则,会涉及到加密算法
用token来实现登录
开发提供一个获取token接口,根据用户名+密码,获取一个token值--返回一个token(字符串)
token值服务器通过什么发给客户端
通过响应头传给客户端 次要
通过响应消息体传给客户端 主要
通过cookie传递给客户端 很少
token使用场景:
服务器访问的同时,vip学员访问服务器,怎么保证vip学员的权限,普通用户也能访问,vip学员的访问的时候加一个验证,vip访问的同时加个验证,
访问网站同时校验身份,必须去vip官网去认证,通过vip账号密码拿到token值,去访问服务器时候时候token带上。
做二次校验,身份的校验,不是每个人都能访问这个网站,只有vip学员才可以,
访问之前vip学员拿vip账号去网站认证一下,获取到token值然后每次访问都带上这个token就可以了,
这个token可以在cookie里面,token放头headers里面和cookie里面都可以,这时候token值,cookie里面自行加token值,自行组装
额外增加某些校验参数,cookie里面可以加一些值,如token值,自行封装cookie
认证的时候token身份二次校验,token放cookie里面和头里面都行(校验是不是vip学员)
20:json格式详解
对象:大括号表示,对象由属性组成,属性由键值对组成,键和值对之间用冒号隔开,属性之间用逗号隔开,另外键必须双引号
{"姓名":"姚明","年龄":38}
数组:用中括号表示
["小明","小李","小百"]
[{"姓名":"姚明","年龄":38}]
嵌套:对象中可以再嵌套对象和数组
{"姓名":"姚明","年龄":38,"家禽":["小明","小李","小百"]}
21:测试用例的设计
大部分是功能的用例:中文描述很多,用例为人设计,前置条件---步骤--预取结果--实际结果 自动化用例设计不同 用例为代码设计(代码好处理才行) 用例需要数据分离 用例设计需要了解功能,有哪些模块得知道,
22:自动化测试用例设计:代码好处理,接口来说,需要
1:url
2:body
3:预期结果
4:请求方式
5:路径
6:接口名称
7:用例名称
8:模块
9:用例id
10:请求参数类型
11:请求参数)
代码构建请求可能用到的,自动化测试用例要让代码容易解读,
为什么需要用例名称:如果一个模块有很多接口,比如新增,列出,删除课程,一般按照顺序来测试,
如果不按照顺序(有名称可以自动识别用例模块,那个接口的,接口用例写的时候打乱,有用例名称
可以自己识别组装成列表)---一般接口用例按照模块顺序写,方便
23:接口用例
最关键的用例多少个取决于请求body不同,请求body里有必填,可选填,每个参数有指定的类型和长度
比如:要求name必须中文的,必填参数,不能有非法字符,有位数,个数,长度,编码设置(int,字符串都有现在)等限制
我们做用例很多时候针对接口用例的数据一般写字典,方便(data和json都能传字典,不需要代码里再转换)
swager框架可以导出对应的接口文档,没有可以导出来--(如果什么都没有,自己写文档,)