【金融风险管理】python进行动态波动率的计算和时间序列的预测
文章目录
- 概述
- 一、数据整理
-
- 1.时间格式转换
- 2.训练集和测试集
- 3.原始股票对数收益率数据展示
- 二.朴素法
-
- 1.计算即可视化
- 2.RMSE检测
- 3.ADF平稳性检测
- 三. 简单平均法
-
- 1.概述
- 四.简单移动平均法
-
- 1.概述
- 2. 5日,10日,15日简单移动平均法
- 3.RMSE检验
- 4.ADF平稳性检验
- 五.指数平滑法
-
- 1.概述
- 2.一次指数平滑法
- 2.二次指数平滑法
- 3.三次指数平滑法
- 总结
概述
根据前一篇文章算计算出来的股票对数收益率,我们在这一篇文章在前文的基础上,分别用朴素法(平均法),简单移动平均法,5日简单移动平均法,10日移动平均法,15日移动平均法来,一次指数平滑法,二次指数平滑法,三次指数平滑法来预测。并且用RMSE,ADF检验对数据进行平稳性检验。
一、数据整理
1.时间格式转换
先对数据进行整体的概览:
用python中的pandas库的to_datetime()来对时间进行一个格式的转换。
#format = '%Y/%m/%d'
df.index = df.Timestamp
df_ts = df.resample('D').sum()
df_ts
on
2.训练集和测试集
#2007 年 1 月- 2007 年 12 月用作训练数据,2007 年 9 月 – 2007 年 12 月用作测试数据。
train = df_ts['2007/1/4':'2007/12/28']
test = df_ts['2007/10/1':'2007/12/28']
all = df['Count']
date = df['Datetime']
train.tail()
#print(train)
注:由于在划分的时候,数据包含了一年中每一天,而实际的股票开盘日并非每一天都有,所以存在在部分空缺值,故在后面利用dropna()来进行删除空缺行,以便后文分析。
train2 = train[train.loc[:]!= 0].dropna()
3.原始股票对数收益率数据展示
train.Count.plot(figsize=(15,8), title= 'Logarithmic yield', fontsize=14)
test.Count.plot(figsize=(15,8), title= 'Logarithmic yield', fontsize=14)
plt.show()

二.朴素法
1.计算即可视化
如果数据集在一段时间内都很稳定,我们想预测第二天的价格,可以取前面一天的价格,预测第二天的值。这种假设第一个预测点和上一个观察点相等的预测方法就叫朴素法。简而言之,朴素法就是预测值等于实际观测到的最后一个值。 由于这种局限性,和数据过于理想化,故多数情况下难以适用。
#朴素法:假设第一个预测点和上一个观察点相等的预测方法
Pu_Su = np.asarray(train['Count'])#训练组数据
y_hat = test.copy()#测试组数据
y_hat['naive'] = Pu_Su[len(Pu_Su) - 1]#预测组数据
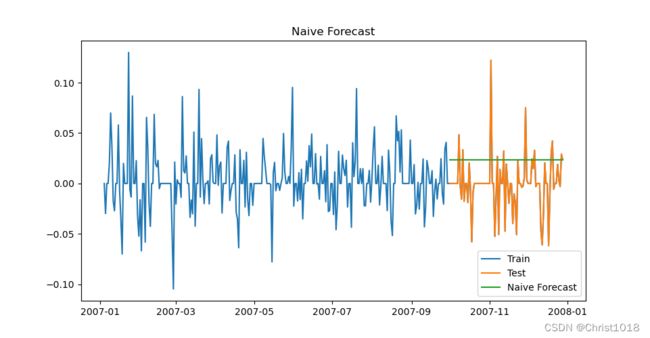
2.RMSE检测
# mean_squared_error()均方根值
rmse = sqrt(mean_squared_error(test['Count'], y_hat['naive']))
print("朴素法的RMSE:",rmse)
3.ADF平稳性检测
print("朴素法ADF检验")
adf_test(timeseries)
注:在这里先是def了一个函数adf_test用来ADF检测
三. 简单平均法
1.概述
简单平均法就是用过去所有的值的平均值来作为我们的预测值,也就是所谓的期望均值,简单易计算,但是由于方法简单,限制较少,对数据的敏感度较大,预测效果一般。
#简单平均法
y_hat_avg = test.copy()
y_hat_avg['avg_forecast'] = train['Count'].mean()
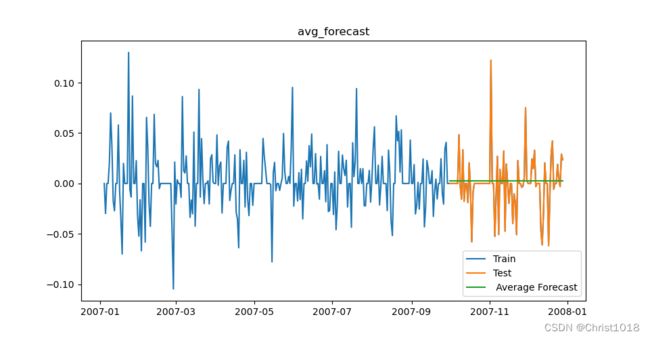
四.简单移动平均法
1.概述
移动平均法是用一组最近的实际数据值来预测未来一期或几期内公司产品的需求量、公司产能等的一种常用方法。移动平均法适用于即期预测。当产品需求既不快速增长也不快速下降,且不存在季节性因素时,移动平均法能有效地消除预测中的随机波动,是非常有用的。移动平均法根据预测时使用的各元素的权重不同,可以分为:简单移动平均和加权移动平均。
https://baike.baidu.com/item/%E7%A7%BB%E5%8A%A8%E5%B9%B3%E5%9D%87%E6%B3%95/10785547
2. 5日,10日,15日简单移动平均法
由于需要计算不同时间段的移动,需要用窗口函数rolling(window)
#利用窗口函数rolling()
#5日简单移动平均法
Five_y_hat_avg = train2.rolling(window=5).mean()
#print(Five_y_hat_avg)
#print(Five_y_hat_avg['Count'])
#10日简单移动平均法
Ten_y_hat_avg = train2.rolling(window=10).mean()
#print(Ten_y_hat_avg)
#15日简单移动平均法
Fifteen_y_hat_avg = train2.rolling(window=15).mean()

3.RMSE检验
#简单平均法的RMSE检测
rmse = sqrt(mean_squared_error(test['Count'], y_hat_avg['avg_forecast']))
print("简单移动平均法RMSE:",rmse)
4.ADF平稳性检验
print("5日简单移动平均ADF检验")
adf_test(Five_y_hat_avg2["Count"])
五.指数平滑法
1.概述
指数平滑法实际上是一种特殊的加权移动平均法。其特点是: 第一,指数平滑法进一步加强了观察期近期观察值对预测值的作用,对不同时间的观察值所赋予的权数不等,从而加大了近期观察值的权数,使预测值能够迅速反映市场实际的变化。权数之间按等比级数减少,此级数之首项为平滑常数a,公比为(1- a)。第二,指数平滑法对于观察值所赋予的权数有伸缩性,可以取不同的a 值以改变权数的变化速率。如a取小值,则权数变化较迅速,观察值的新近变化趋势较能迅速反映于指数移动平均值中。因此,运用指数平滑法,可以选择不同的a 值来调节时间序列观察值的均匀程度(即趋势变化的平稳程度)。
- 一次,二次,三次区别;
- 1 一次平滑法针对没有趋势和季节性的序列
- 2 二次平滑法针对有趋势但没有季节的序列(此次所选取的数据较为合适)
- 3 三次平滑法针对有趋势和有季节性的序列
https://baike.baidu.com/item/%E6%8C%87%E6%95%B0%E5%B9%B3%E6%BB%91%E6%B3%95/8726217
2.一次指数平滑法
y_hat_avg = test.copy()
fit = SimpleExpSmoothing(np.asarray(train['Count'])).fit(smoothing_level=0.6, optimized=False)
y_hat_avg['SES'] = fit.forecast(len(test))
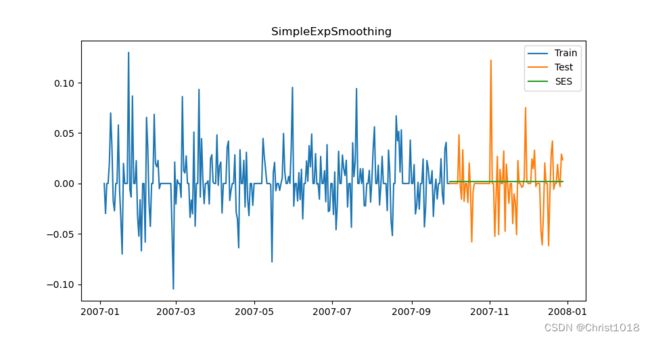
2.二次指数平滑法
y_hat_avg = test.copy()
fit = Holt(np.asarray(train['Count'])).fit(smoothing_level=0.3, smoothing_slope=0.1)
y_hat_avg['Holt_linear'] = fit.forecast(len(test))
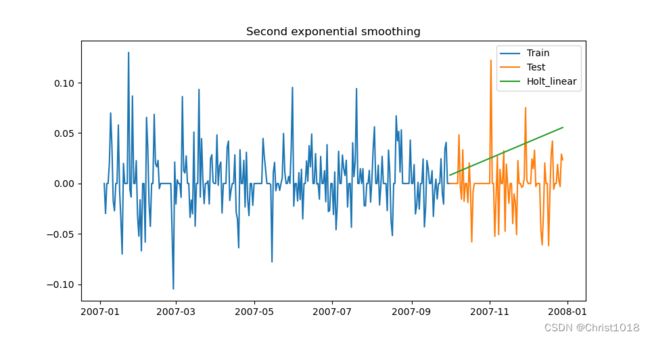
3.三次指数平滑法
y_hat_avg = test.copy()
fit1 = ExponentialSmoothing(np.asarray(train['Count']), seasonal_periods=7, trend='add', seasonal='add', ).fit()
y_hat_avg['Holt_Winter'] = fit1.forecast(len(test))
在二次和三次之前,先使用:
sm.tsa.seasonal_decompose(train['Count']).seasonal
将时间序列分解,从而得到以下图形:
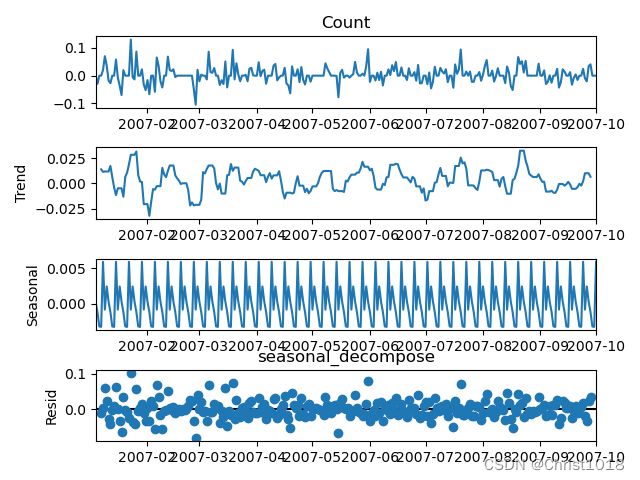
从上到下依次是:原始数据、趋势数据、周期性数据、随机变量(残差值)

由于此数据主要来自于一年时间,季节性参数不好找。
总结
由于python第三方库的强大,在此次的运算中主要运用了,rolling(),to_datetime(),seasonal(),statsmodels.tsa.api