Unicode(UTF-8, UTF-16)令人混淆的概念
部分转载自: http://www.cnblogs.com/kingcat/archive/2012/10/16/2726334.html
部分转载自:http://www.qianxingzhem.com/post-1499.html
部分转载自:http://blog.csdn.net/leftstrang/article/details/52450318
部分转载自:http://blog.csdn.net/chenzy945/article/details/51931148
部分转载自:http://blog.csdn.net/SarahZhang0104/article/details/51346999
为啥需要Unicode
我们知道计算机其实挺笨的,它只认识0101这样的字符串,当然了我们看这样的01串时肯定会比较头晕的,所以很多时候为了描述简单都用十进制,十六进制,八进制表示.实际上都是等价的,没啥太多不一样.其他啥文字图片之类的其他东东计算机不认识.那为了在计算机上表示这些信息就必须转换成一些数字.你肯定不能想怎么转换就怎么转,必须得有定些规则.于是刚开始的时候就有ASCII字符集(American Standard Code for Information Interchange, "美国信息交换标准码),它使用7 bits来表示一个字符,总共表示128个字符,我们一般都是用字节(byte,即8个01串)来作为基本单位.那么怎么当用一个字节来表示字符时第一个bit总是0,剩下的七个字节就来表示实际内容.后来IBM公司在此基础上进行了扩展,用8bit来表示一个字符,总共可以表示256个字符.也就是当第一个bit是0时仍表示之前那些常用的字符.当为1时就表示其他补充的字符.
英文字母再加一些其他标点字符之类的也不会超过256个.一个字节表示主足够了.但其他一些文字不止这么多 ,像汉字就上万个.于是又出现了其他各种字符集.这样不同的字符集交换数据时就有问题了.可能你用某个数字表示字符A,但另外的字符集又是用另外一个数字表示A.这样交互起来就麻烦了.于是就出现了Unicode和ISO这样的组织来统一制定一个标准,任何一个字符只对应一个确定的数字.ISO取的名字叫UCS(Universal Character Set),Unicode取的名字就叫unicode了.
总结起来为啥需要Unicodey就是为了适应全球化的发展,便于不同语言之间的兼容交互,而ASCII不再能胜任此任务了.
Unicode详细介绍
1.容易产生后歧义的两字节
unicode的第一个版本是用两个字节(16bit)来表示所有字符
.实际上这么说容易让人产生歧义,我们总觉得两个字节就代表保存在计算机中时是两个字节.于是任何字符如果用unicode表示的话保存下来都占两个字节.其实这种说法是错误的.
其实Unicode涉及到两个步骤,首先是定义一个规范,给所有的字符指定一个唯一对应的数字,这完全是数学问题,可以跟计算机没半毛钱关系.第二步才是怎么把字符对应的数字保存在计算机中,这才涉及到实际在计算机中占多少字节空间.
所以我们也可以这样理解,Unicode是用0至65535之间的数字来表示所有字符.其中0至127这128个数字表示的字符仍然跟ASCII完全一样.65536是2的16次方.这是第一步.第二步就是怎么把0至65535这些数字转化成01串保存到计算机中.这肯定就有不同的保存方式了.于是出现了UTF(unicode transformation format),有UTF-8,UTF-16.
2.UTF-8 与UTF-16的区别
UTF-16比较好理解,就是任何字符对应的数字都用两个字节来保存.我们通常对Unicode的误解就是把Unicode与UTF-16等同了.但是很显然如果都是英文字母这做有点浪费.明明用一个字节能表示一个字符为啥整两个啊.
于是又有个UTF-8,这里的8非常容易误导人,8不是指一个字节,难道一个字节表示一个字符?实际上不是.当用UTF-8时表示一个字符是可变的,有可能是用一个字节表示一个字符,也可能是两个,三个.当然最多不能超过3个字节了.反正是根据字符对应的数字大小来确定.
于是UTF-8和UTF-16的优劣很容易就看出来了.如果全部英文或英文与其他文字混合,但英文占绝大部分,用UTF-8就比UTF-16节省了很多空间.而如果全部是中文这样类似的字符或者混合字符中中文占绝大多数.UTF-16就占优势了,可以节省很多空间.另外还有个容错问题,等会再讲
看的有点晕了吧,举个例子.假如中文字"汉"对应的unicode是6C49(这是用十六进制表示,用十进制表示是27721为啥不用十进制表示呢?很明显用十六进制表示要短点.其实都是等价的没啥不一样.就跟你说60分钟和1小时一样.).你可能会问当用程序打开一个文件时我们怎么知道那是用的UTF-8还是UTF-16啊.自然会有点啥标志,在文件的开头几个字节就是标志.
EF BB BF 表示UTF-8
FE FF 表示UTF-16.
用UTF-16表示"汉"
假如用UTF-16表示的话就是01101100 01001001(共16 bit,两个字节).程序解析的时候知道是UTF-16就把两个字节当成一个单元来解析.这个很简单.
用UTF-8表示"汉"
用UTF-8就有复杂点.因为此时程序是把一个字节一个字节的来读取,然后再根据字节中开头的bit标志来识别是该把1个还是两个或三个字节做为一个单元来处理.
0xxxxxxx,如果是这样的01串,也就是以0开头后面是啥就不用管了XX代表任意bit.就表示把一个字节做为一个单元.就跟ASCII完全一样.
110xxxxx 10xxxxxx.如果是这样的格式,则把两个字节当一个单元
1110xxxx 10xxxxxx 10xxxxxx 如果是这种格式则是三个字节当一个单元.
这是约定的规则.你用UTF-8来表示时必须遵守这样的规则.我们知道UTF-16不需要用啥字符来做标志,所以两字节也就是2的16次能表示65536个字符.
而UTF-8由于里面有额外的标志信息,所有一个字节只能表示2的7次方128个字符,两个字节只能表示2的11次方2048个字符.而三个字节能表示2的16次方,65536个字符.
由于"汉"的编码27721大于2048了所有两个字节还不够,只能用三个字节来表示.
所有要用1110xxxx 10xxxxxx 10xxxxxx这种格式.把27721对应的二进制从左到右填充XXX符号(实际上不一定从左到右,也可以从右到左,这是涉及到另外一个问题.等会说.
刚说到填充方式可以不一样,于是就出现了Big-Endian,Little-Endian的术语.Big-Endian就是从左到右,Little-Endian是从右到左.
由上面我们可以看出UTF-8需要判断每个字节中的开头标志信息,所以如果一当某个字节在传送过程中出错了,就会导致后面的字节也会解析出错.而UTF-16不会判断开头标志,即使错也只会错一个字符,所以容错能力强.
Unicode版本2
前面说的都是unicode的第一个版本.但65536显然不算太多的数字,用它来表示常用的字符是没一点问题.足够了,但如果加上很多特殊的就也不够了.于是从1996年开始又来了第二个版本.用四个字节表示所有字符.这样就出现了UTF-8,UTF16,UTF-32.原理和之前肯定是完全一样的,UTF-32就是把所有的字符都用32bit也就是4个字节来表示.然后UTF-8,UTF-16就视情况而定了.UTF-8可以选择1至8个字节中的任一个来表示.而UTF-16只能是选两字节或四字节..由于unicode版本2的原理完全是一样的,就不多说了.
前面说了要知道具体是哪种编码方式,需要判断文本开头的标志,下面是所有编码对应的开头标志
EF BB BF UTF-8
FE FF UTF-16/UCS-2, little endian
FF FE UTF-16/UCS-2, big endian
FF FE 00 00 UTF-32/UCS-4, little endian.
00 00 FE FF UTF-32/UCS-4, big-endian.
其中的UCS就是前面说的ISO制定的标准,和Unicode是完全一样的,只不过名字不一样.ucs-2对应utf-16,ucs-4对应UTF-32.UTF-8是没有对应的UCS
ANSI又是啥
“ANSI编码”只存在于Windows系统。
那么Windows系统是如何区分ANSI背后的真实编码的呢?
微软用一个叫“Windows code pages”(在命令行下执行chcp命令可以查看当前code page的值)的值来判断系统默认编码,比如:简体中文的code page值为936(它表示GBK编码,win95之前表示GB2312,详见:Microsoft Windows' Code Page 936),繁体中文的code page值为950(表示Big-5编码)。
我们能否通过修改Windows code pages的值来改变“ANSI编码”呢?
命令提示符下,我们可以通过chcp命令来修改当前终端的active code page,例如:
(1) 执行:chcp 437,code page改为437,当前终端的默认编码就为ASCII编码了(汉字就成乱码了);
(2) 执行:chcp 936,code page改为936,当前终端的默认编码就为GBK编码了(汉字又能正常显示了)。
上面的操作只在当前终端起作用,并不会影响系统默认的“ANSI编码”。(更改命令行默认codepage参看:设置cmd的codepage的方法)。
Windows下code page是根据当前系统区域(locale)来设置的,要想修改系统默认的“ANSI编码”,我们可以通过修改系统区域来实现(“控制面板” =>“时钟、语言和区域”=>“区域和语言”=>“管理”=>“更改系统区域设置...”):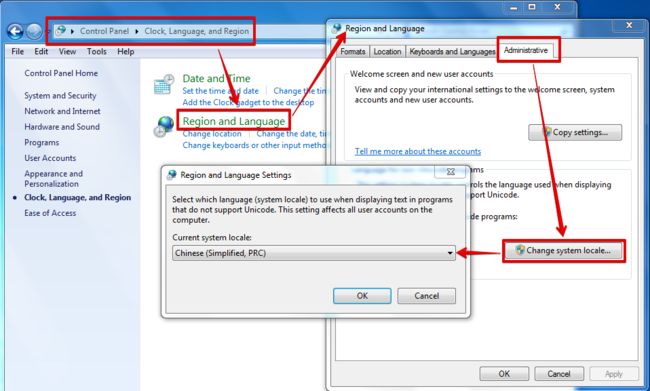
图中的系统locale为简体中文,意味着当前“ANSI编码”实际是GBK编码。当你把它改成Korean(Korea)时,“ANSI编码”实际是EUC-KR编码,“한국어”就能正常显示了;当你把它改成English(US)时,“ANSI编码”实际是ASCII编码,“汉字”和“한국어”都成乱码了。(改了之后需要重启系统的。。。)
说明:locale是国际化与本地化中重要的概念,本文不深入讲解该内容。
你上面说的都是windows的情形吧,Linux呢?
将前述内容为“汉字”的文件test.txt拷贝至Linux下,用Emacs打开: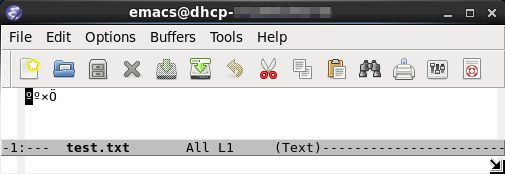
也是乱码!原因也是locale的问题: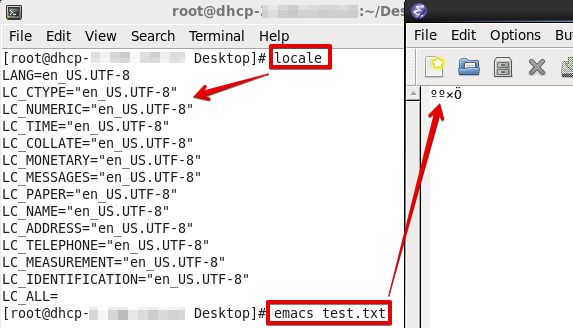
更改locale后再打开: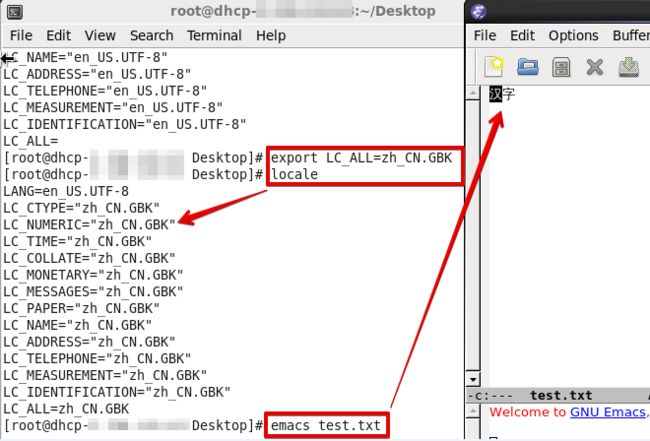
正常显示了。。。
中文编码GBK、GB2312、GB18030
等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢。于是国人就自主研发,把那些127号之后的奇异符号们直接取消掉。规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原来在127号以下的那些就叫”半角”字符了。
中国人民看到这样很不错,于是就把这种汉字方案叫做 “GB2312″。GB2312 是对 ASCII 的中文扩展。
但是中国的汉字太多了,后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是 扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK 扩成了 GB18030。从此之后,中华民族的文化就可以在计算机时代中传承了。
VC中的多字节字符集又是啥
各国在ASCII的基础上制定了自己的字符集,这些从ANSI标准派生的字符集被习惯的统称为ANSI字符集,它们正式的名称应该是 MBCS(Multi-Byte Chactacter System,即多字节字符系统) 。这些派生字符集的特点是以ASCII 127 bits为基础,兼容ASCII 127,他们使用大于128的编码作为一个Leading Byte,紧跟在Leading Byte后的第二(甚至第三)个字符与Leading Byte一起作为实际的编码。这样的字符集有很多,我们常见的GB-2312就是其中之一。C++如何创建UTF-8编码的txt
- #include
- #include
- #include
- std::string ToUTF8(const wchar_t* buffer, int len)
- {
- int size = ::WideCharToMultiByte(CP_UTF8, 0, buffer, len, NULL, 0, NULL, NULL);
- if (size == 0)
- return "";
- std::string newbuffer;
- newbuffer.resize(size);
- ::WideCharToMultiByte(CP_UTF8, 0, buffer, len,
- const_cast<char*>(newbuffer.c_str()), size, NULL, NULL);
- return newbuffer;
- }
- std::string ToUTF8(const std::wstring& str)
- {
- return ToUTF8(str.c_str(), (int) str.size());
- }
- int _tmain(int argc, _TCHAR* argv[])
- {
- std::ofstream test_file;
- test_file.open("d:\\test.txt", std::ios::out | std::ios::binary);
- std::wstring text =
- L"中文字符";
- std::string outtext = ToUTF8(text);
- test_file << outtext;
- test_file.close();
- return 0;
- }
字符串处理函数常用函数对照
| ANSI | UNICODE | 通用 | 说明 |
| 数据类型 | |||
| (char.h) | (wchar.h) | (tchar.h) | |
| char | wchar_t | TCHAR | |
| char * | wchar_t * | TCHAR* | |
| LPSTR | LPWSTR | LPTSTR | |
| LPCSTR | LPCWSTR | LPCTSTR | |
| 字符串转换 | |||
| atoi | _wtoi | _ttoi | 把字符串转换成整数(int) |
| atol | _wtol | _ttol | 把字符串转换成长整型数(long) |
| atof | _wtof | _tstof | 把字符串转换成浮点数(double) |
| itoa | _itow | _itot | 将任意类型的数字转换为字符串 |
| 字符串操作 | |||
| strlen | wcslen | _tcslen | 获得字符串的数目 |
| strcpy | wcscpy | _tcscpy | 拷贝字符串 |
| strncpy | wcsncpy | _tcsncpy | 类似于strcpy/wcscpy,同时指定拷贝的数目 |
| strcmp | wcscmp | _tcscmp | 比较两个字符串 |
| strncmp | wcsncmp | _tcsncmp | 类似于strcmp/wcscmp,同时指定比较字符字符串的数目 |
| strcat | wcscat | _tcscat | 把一个字符串接到另一个字符串的尾部 |
| strncat | wcsncat | _tcsnccat | 类似于strcat/wcscat,而且指定粘接字符串的粘接长度. |
| strchr | wcschr | _tcschr | 查找子字符串的第一个位置 |
| strrchr | wcsrchr | _tcsrchr | 从尾部开始查找子字符串出现的第一个位置 |
| strpbrk | wcspbrk | _tcspbrk | 从一字符字符串中查找另一字符串中任何一个字符第一次出现的位置 |
| strstr | wcsstr/wcswcs | _tcsstr | 在一字符串中查找另一字符串第一次出现的位置 |
| strcspn | wcscspn | _tcscspn | 返回不包含第二个字符串的的初始数目 |
| strspn | wcsspn | _tcsspn | 返回包含第二个字符串的初始数目 |
| strtok | wcstok | _tcstok | 根据标示符把字符串分解成一系列字符串 |
| wcswidth | 获得宽字符串的宽度 | ||
| wcwidth | 获得宽字符的宽度 | ||
| 字符串测试 | |||
| isascii | iswascii | _istascii | 测试字符是否为ASCII 码字符, 也就是判断c 的范围是否在0 到127 之间 |
| isalnum | iswalnum | _istalnum | 测试字符是否为数字或字母 |
| isalpha | iswalpha | _istalpha | 测试字符是否是字母 |
| iscntrl | iswcntrl | _istcntrl | 测试字符是否是控制符 |
| isdigit | iswdigit | _istdigit | 测试字符是否为数字 |
| isgraph | iswgraph | _istgraph | 测试字符是否是可见字符 |
| islower | iswlower | _istlower | 测试字符是否是小写字符 |
| isprint | iswprint | _istprint | 测试字符是否是可打印字符 |
| ispunct | iswpunct | _istpunct | 测试字符是否是标点符号 |
| isspace | iswspace | _istspace | 测试字符是否是空白符号 |
| isupper | iswupper | _istupper | 测试字符是否是大写字符 |
| isxdigit | iswxdigit | _istxdigit | 测试字符是否是十六进制的数字 |
| 大小写转换 | |||
| tolower | towlower | _totlower | 把字符转换为小写 |
| toupper | towupper | _totupper | 把字符转换为大写 |
| 字符比较 | |||
| strcoll | wcscoll | _tcscoll | 比较字符串 |
| 日期和时间转换 | |||
| strftime | wcsftime | _tcsftime | 根据指定的字符串格式和locale设置格式化日期和时间 |
| strptime | 根据指定格式把字符串转换为时间值, 是strftime的反过程 | ||
| 打印和扫描字符串 | |||
| printf | wprintf | _tprintf | 使用vararg参量的格式化输出到标准输出 |
| fprintf | fwprintf | _ftprintf | 使用vararg参量的格式化输出 |
| scanf | wscanf | _tscanf | 从标准输入的格式化读入 |
| fscanf | fwscanf | _ftscanf | 格式化读入 |
| sprintf | swprintf | _stprintf | 根据vararg参量表格式化成字符串 |
| sscanf | swscanf | _stscanf | 以字符串作格式化读入 |
| vfprintf | vfwprintf | _vftprintf | 使用stdarg参量表格式化输出到文件 |
| vprintf | 使用stdarg参量表格式化输出到标准输出 | ||
| vsprintf | vswprintf | _vstprintf | 格式化stdarg参量表并写到字符串 |
| sprintf_s | swprintf_s | _stprintf_s | 格式化字符串 |
| 数字转换 | |||
| strtod | wcstod | _tcstod | 把字符串的初始部分转换为双精度浮点数 |
| strtol | wcstol | _tcstol | 把字符串的初始部分转换为长整数 |
| strtoul | wcstoul | _tcstoul | 把字符串的初始部分转换为无符号长整数 |
| _strtoi64 | _wcstoi64 | _tcstoi64 | |
| 输入和输出 | |||
| fgetc | fgetwc | _fgettc | 从流中读入一个字符并转换为宽字符 |
| fgets | fgetws | _fgetts | 从流中读入一个字符串并转换为宽字符串 |
| fputc | fputwc | _fputtc | 把宽字符转换为多字节字符并且输出到标准输出 |
| fputs | fputws | _fputts | 把宽字符串转换为多字节字符并且输出到标准输出串 |
| getc | getwc | _gettc | 从标准输入中读取字符, 并且转换为宽字符 |
| getchar | getwchar | _gettchar | 从标准输入中读取字符 |
| putc | putwc | _puttc | 标准输出 |
| putchar | putwchar | _puttchar | 标准输出 |
| ungetc | ungetwc | _ungettc | 把一个字符放回到输入流中 |
VS中读写TXT
可参考:http://blog.csdn.net/shufac/article/details/51829267
Linux中读写TXT
宽字节转码
#include
mbstowcs:把多字节字符转换成宽字符
wcstombs:把宽字符把转换成多字节字符串
宽字节,即wchar_t 类型采用Unicode编码方式,在Windows中为utf-16(2字节),在Linux中为utf-32(4字节)
而多字节则可能是其他很多编码方式,如utf-8、GB232....
因此,需要指定多字节编码类型,才能进行正常的转换过程。很可惜这个编码类型并没有体现在函数的参数列表里,而是隐含依赖全局的 locale 。更加不幸的是,全局 locale 默认没有使用系统当前语言,而是设置为没什么用处的 "C" locale。
在调用 mbstowcs 或使用它的函数之前,先用 setlocale 将全局默认 locale 设为当前系统默认 locale :
#include
setlocale(LC_ALL, "");
如果是在非中文系统上转 GBK 编码,就需要指定中文 locale :
setlocale(LC_ALL, "chs"); // chs 是 VC 里简中的 locale 名字