Linux:详解基础IO(重定向、静态库和动态库、ext2文件系统、软硬连接)(二)
目录
- 1.重定向
-
- 1.1 前言
- 1.2 重定向的命令符号
- 1.3 重定向的原理
- 1.4 重定向的代码实现
- 2.静态库和动态库
-
- 2.1 动态库
-
- 2.1.1 分类
- 2.1.2 动态库的编译生成
- 2.1.3 动态库的使用(场景)
- 2.1.4 动态库配合环境变量的使用
- 2.2 静态库
-
- 2.2.1 分类
- 2.2.2 静态库的编译生成
- 2.2.3 静态库的使用
- 3. ext2文件系统
-
- 3.1 存储数据的逻辑
- 3.2 获取数据的逻辑
- 3.3 相关命令语句
- 4. 软硬链接
-
- 4.1 软链接
- 4.2 硬链接
1.重定向
1.1 前言
重定向是什么呢?举个例子来看一下
我们首先创建一个不包含任何内容的文件1.txt
然后我们将ls -l的命令重定向到1.txt
查看1.txt中的内容



1.2 重定向的命令符号
>:清空重定向,将文件清空之后,再进行重定向>>:追加重定向,直接将重定向的内容放在该文件的尾部
相当于C语言fopen函数中的 w、w+ 属性。
1.3 重定向的原理
首先,我们来看一下Linux中一个程序所对应的默认的文件输出信息,在/proc/[PID]/fd路径下查看
再看看/dev/pts/0里到底是什么


那么,重定向的原理是什么呢?拿前言中的例子来说,ls命令本来是将结果输出到屏幕上,而我们使用重定向将其本要输出到屏幕上的内容转而输出到了1.txt文件中,其本质就是修改了ls命令的标准输出(fd_adday[1])的指向。
用图来解释一下就是:
①初始的时候
②当使用重定向后,将fd_array[1]的指向重新设置为fd_array[3]的指向的结构体
此时,当使用 ls 命令时,它的内容就不会输出再屏幕上,而是会输出到1.txt文件中
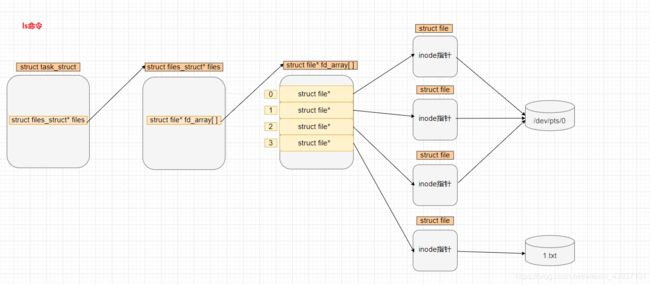

总结一下重定向的原理是:将fd_array数组中的元素struct file * 指针的指向关系进行改变,改变成为其他struct file 结构体的地址
1.4 重定向的代码实现
首先来看一个重定向的函数
int dup2(int oldfd, int newfd);
它的参数,如字面意思一样,给定两个文件描述符即可,dup2函数中也有对应的特性。我们接下来一一的进行探讨。
查看dup2函数的描述可得:
特性①:
解释:dup2的newfd是拷贝于oldfd的,也就是说,当重定向之后,oldfd的指向还是存在的,并不会随着dup2的调用而消失。举个例子来说就是dup2(0,3),相当于将 fd[3] 变为标准输入流,但是原来的 fd[0] ,还是存在的,并不会关闭。
特性②:
解释:如果必要,则在使用dup2进行重定向的时候,会先关闭newfd,(这里的必要是指:oldfd是正常的文件描述符),但是还要注意以下几点:
- note1:
解释:若oldfd不是一个有效的文件描述符,则不关闭newfd,重定向失败
- note2:
解释:若oldfd是一个有效的文件描述符,并且oldfd和newfd拥有相同的文件描述符数值,那么dup2函数什么都不干,且返回newfd

返回值:若重定向成功,则返回newfd,若失败,则返回-1。
用代码实现重定向
在实现代码之前,首先先明确该代码应该实现的功能:首先获得当前目录下一个文件的文件描述符fd,如果不存在则创建。然后调用dup2函数将标准输出的文件描述符重定向到fd,标准输出为newfd,fd为oldfd,然后通过printf函数进行打印,查看其现象。
代码如下:
代码1:
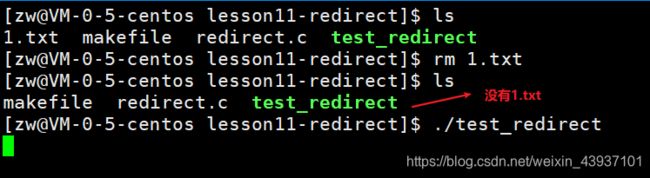
#include 结果探讨:由于是while(1)死循环,那么在重定向之后,在执行printf时,会不停的往1.txt文件中输出 It’s test to redirect !,那么结果是否是如此呢,我们来运行一下:
为了能看到程序运行的结果,我们使用
tail -f 1.txt的语句来实时查看1.txt文件当中的内容
使用tail -f 1.txt
我们发现好像并没有写入到1.txt中,为什么呢?
查看一下文件描述符,发现重定向已经成功了,但是为什么没有打印到1.txt呢?
然后过了一会,我们再使用tail -f 1.txt查看1.txt内容,发现已经写到文件中了

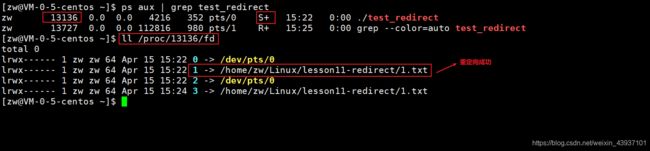

那这到底为什么会这样呢?为什么一开始并不会向1.txt中写入文件,而是过一会才写入文件中呢?
解答:C库函数写入文件时是全缓冲的,而在写入显示器时是行缓冲的。
- 当写入文件时,’\n’就不管用了,需要搭配fflush() 函数来强制刷新缓存区(或者等待程序结束时的强制刷新)
- ‘\n’ ,只对行缓冲区有用
因此,解决该问题有两种办法
- 规定循环次数(循环结束,程序结束,会自动刷新缓冲区)
- 使用fflush函数强制刷新缓冲区
代码改进:
#include 这次我们再来看一下结果
发现可以输出是和我们的猜想一致,很完美!!

2.静态库和动态库
2.1 动态库
2.1.1 分类
- Windows操作系统下:若文件的后缀为
.dll,则表明该文件为动态库 - Linux操作系统下:若文件的后缀为
.so,前缀为lib,则表明该文件为动态库
2.1.2 动态库的编译生成
命令: gcc/g++
必选命令行参数:
- -shared:生成的动态库
- -fPIC:生成与位置无关的代码(该参数会计算出程序的相对位置)
命令范式:
gcc/g++ [soure code] -shared -fPIC -o lib[动态库名称].so
举个例子:

注意:生成的动态库中不能包含main函数!!!
使用动态库的原因:
防止源码泄漏,因为动态库是编译
.c文件生成的二进制文件,因此当要发布产品时,只需要将动态库和其对应的.h文件发布即可,这就实现了我能知道这个代码各个函数能实现什么功能,但是不知道其内部的具体实现,封装性极强,可以极大的防止源码泄漏。
2.1.3 动态库的使用(场景)
本质上是想要使用动态库产生一个可执行的程序
参数:
- L+ [动态库所在路径]-l+ [动态库名称](注意:这里的动态库名称是指,去掉前缀和后缀之后的名称)
命令范式:
gcc/g++ [source code] -o [可执行程序] -L [动态库所在路径] -l[动态库的名称]
举个例子:

ldd + [可执行程序]:可以查看当前可执行程序所有依赖的动态库的名称

该命令很是重要,在以后实战中可能会经常遇到
2.1.4 动态库配合环境变量的使用
若是我不小心将当前目录下的动态库给移走了,那么此时程序还能正常运行吗?

那么问题来了:如何让可执行程序能够找到依赖的动态库在哪里
解决方案:配合环境变量LD_LIBRARY_PATH进行使用
LD_LIBRARY_PATH:是动态库的搜索的环境变量PATH:是可执行程序的搜索的环境变量
将动态库所在位置,放入系统的环境变量中即可解决该问题。

2.2 静态库
2.2.1 分类
- Windows操作系统下:若文件的后缀为
.lib,则表明该文件为静态库 - Linux操作系统下:若文件的后缀为
.a,前缀为lib,则表明该文件为静态库
2.2.2 静态库的编译生成
命令范式:
ar -rc lib[静态库名称].a [依赖的文件]
这里依赖的文件是指整个汇编过程完成之后的文件,即.o文件
步骤:
- 先将要编译静态库的代码,编译到汇编阶段
- 使用
ar -rc生成静态库(二进制代码文件)
举个例子:

2.2.3 静态库的使用
命令范式:
gcc [soure code] -o [可执行程序] -L [静态库路径] -l[静态库名称]
这里的静态库名称和动态库一样,都是去掉前缀和后缀之后的名称
注:若可执行程序依赖静态库编译成功的,会将静态库的内容直接打包到可执行程序中。并且ldd命令是查看不到其依赖关系的。
举个例子:
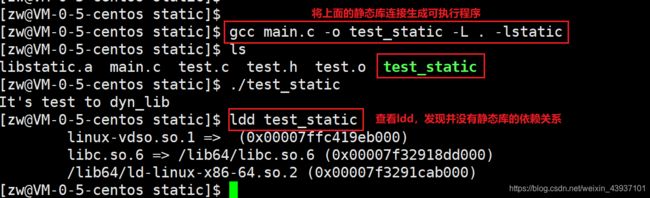
扩展:
- 一个程序依赖动态库或者依赖静态库生成可执行程序时,动态库或静态库是不会干扰到链接方式的(此处的链接方式指得是静态链接和动态链接)
- 在编译可执行程序时,使用
gcc/g++编译时,默认不增加命令行参数-static,则表明该链接为动态链接,反之,则为静态链接- 静态链接就是在编译时,主动加上
-static参数的程序,这时候用ldd命令查看会什么也查不到,因为他会将所有依赖的文件全部封装到可执行程序中去,相对于的可执行程序会异常的大
再看看它的文件大小


碎片知识:动态库是不能用静态链接的生成可执行程序(静态库是可以的),但是这种情况只是指自己编译的动态库是不行的。而操作系统的动态库是可以静态链接的
3. ext2文件系统
众所周知,系统的磁盘是分为好几个区的,如C区、D区等等,每个区或许都有它对应的文件系统,本节我们就着重讲讲ext2文件系统。
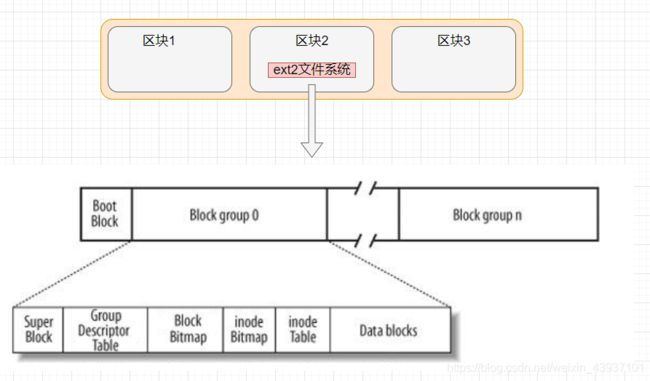
Linux ext2文件系统,上图为磁盘文件系统图(内核内存映像肯定有所不同),磁盘是典型的块设备,硬盘分区被划分为一个个的block。一个block的大小是由格式化的时候确定的,并且不可以更改。上图中启动块(Boot Block)的大小是确定的。
- Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。相当于政府管理各区的例子
- 超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。
- GDT,Group Descriptor Table:块组描述符,描述块组属性信息。
- Block Bitmap:块的位图,描述每一个块的使用情况,若使用则比特位为1,反之为0。
- inode Bitmap:它描述了inode结点的使用情况,即描述了inode table中,哪一个inode结点被使用,哪一个inode结点没有被使用
- inode Table:里面存放了inode的结点
inode结点: 用来描述文件存储的信息以及对应的文件元信息。
- Data blocks:反映了块的使用情况,即Block Bitmap中保存的结果是根据Data blocks的存储信息得来的。
3.1 存储数据的逻辑
① 从block Bitmap当中查找到空闲的Data block块,将文件分成不同的块存储在不同的block中。
② 从inode Bitmap中查找空闲的inode结点,将文件信息保存在inode中,其中文件信息包括文件在哪些block块中存储,位均名称,文件大小,文件权限,文件访问时间,文件修改时间,文件修改属性时间,文件拥有者,文件所属组。
③将文件的名称和inode结点号,作为目录的目录项保存下来。
3.2 获取数据的逻辑
①通过目录项当中的文件名称找到对应的inode结点号。
②通过inode节点号,找到对应的inode结点,通过inode结点找到文件的元信息。
③通过文件元信息,找到文件存储的block块,将文件内容组合起来。
④展示给用户,文件的元信息以及文件的内容
3.3 相关命令语句
df -h命令可以查看磁盘的情况(分区、大小)
如下:

ll -i可以查看inode的结点号

stat [文件名称]:查看文件详细信息(文件的元信息)

4. 软硬链接
4.1 软链接
概念:
软链接就是给文件创建了一个快捷 方式
创建:
使用
ln -s [原文件] [创出的软链接名称]命令

软链接探讨
① 对比inode结点号
发现软链接的inode号和源文件的inode号是不一样的,但是它们所指向的block是一样的

② 当删除源文件时,软链接的状态
再重新创建一个test.c的文件,查看其状态


发现软链接又重新指向test.c文件,但是其中的内容发生了改变,不在是以前的test.c文件。
总结:修改源文件会影响软链接文件,修改软链接文件也会影响源文件,因此,在删除源文件的时候,一定要把软链接文件也给删除掉
4.2 硬链接
概念:
硬链接相当于文件的一个备份(拷贝)
创建:
使用
ln [源文件] [硬连接文件]命令
硬连接具有和源文件相同的inode结点号,并且是一个普通的文件,生成硬链接后,对应的硬链接文件数也变为 2。
