六个步骤学会简单的数据清洗
在使用机器学习等各种模型来分析数据的时候,最重要的就是如何对原始数据进行清洗和加工,以下几个步骤实现最简单的数据清洗;
以下使用 kaggle 上的泰坦尼克号经典数据集为例子;
daownload link:https://link.zhihu.com/?target=https%3A//www.kaggle.com/hesh97/titanicdataset-traincsv
一、读取数据
import pandas as pd
import numpy as np
data_raw = pd.read_csv('train.csv')
data_raw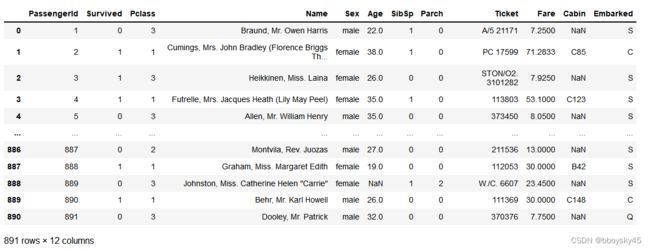
二、了解数据
1.数据整体预览
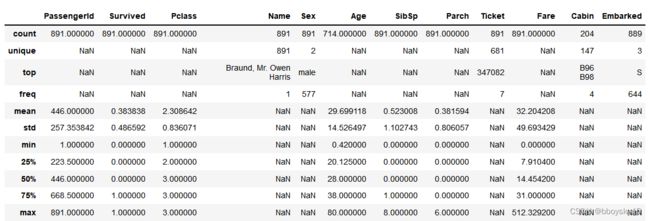
data_raw.info()
data_raw.describe(include='all')
三、检查填充数据缺失情况
data = data_raw.copy(
data.isnull().sum() 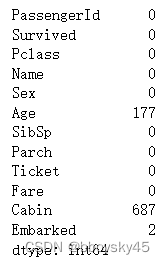
1.数据缺失情况
3种特征有null值,Age特征177个,Cabin特征687个,Embarked 2个;
总共891个数据,Cabin缺失687个,有两种解决方案;
1.是认为这个特征没用,直接去掉;
2.是对这个数据做处理(统计Nan值,或者更加关注未缺失的数据,可能有大用)
2. 填充处理
null较少的两个特征填充数据,其中Age特征是数值型(Numeric)特征,Embarked特征是类别型(Categorical)特征
数值型可以用mean,median等填充
类别型可以用.mode(),取出现次数最多的
data['Age'].fillna(data['Age'].median(), inplace = True)
data['Embarked'].fillna(data['Embarked'].mode()[0], inplace = True)
data.isnull().sum()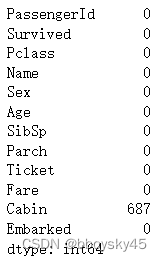
四、特征工程
1. 去除掉认为没用的特征
drop_column = ['PassengerId','Cabin', 'Ticket']
data = data.drop(drop_column, axis=1, inplace = True)2.构建新特征
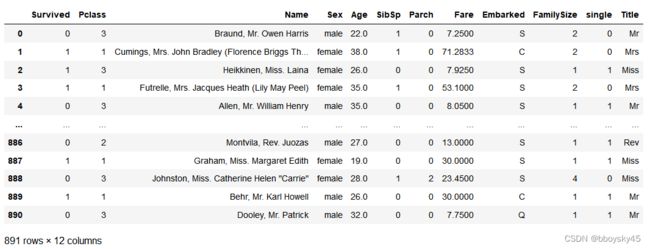
data['FamilySize'] = data['SibSp'] + data['Parch'] + 1
data['single'] = np.where(data['FamilySize'] > 1,0,1)
data['Title'] = data['Name'].str.split(", ", expand=True)[1].str.split(".", expand=True)[0]
data
3.对连续型特征做分箱处理
data['FareCut'] = pd.qcut(data['Fare'], 4)
data['AgeCut'] = pd.cut(data['Age'].astype(int), 6)
data五、对离散/文本类特征做编码处理
1. LabelEncoder方法
from sklearn.preprocessing import LabelEncoder
label = LabelEncoder()
data['Sex_Code'] = label.fit_transform(data['Sex'])
data['Embarked_Code'] = label.fit_transform(data['Embarked'])
data['Title_Code'] = label.fit_transform(data['Title'])
data['AgeBin_Code'] = label.fit_transform(data['AgeCut'])
data['FareBin_Code'] = label.fit_transform(data['FareCut'])
data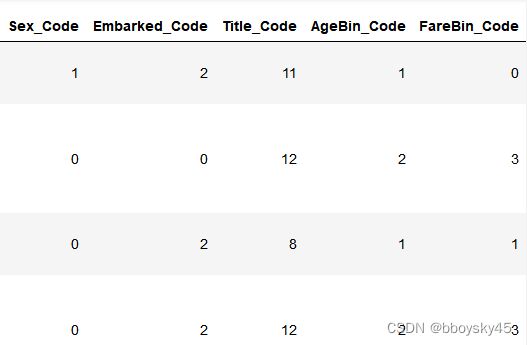
2.get_dummies方法
pd.get_dummies(data['Sex'])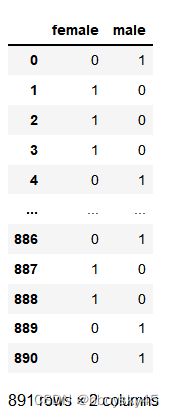
六、最后检查数据
data.info()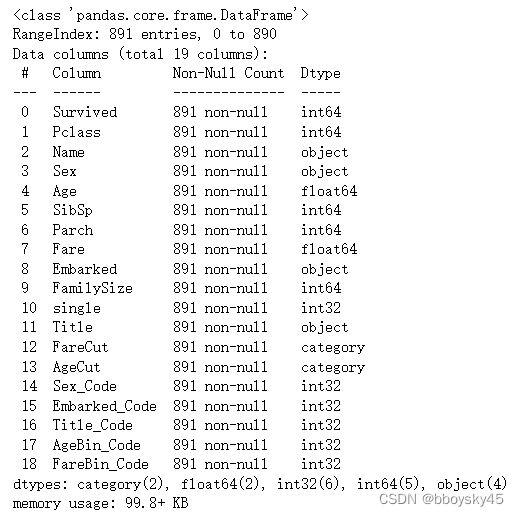
以上就完成了最简单的数据清洗,可以使用算法模型进行后续计算了