配对交易策略设计
可交易的一个关键要求是两个股票的对数价格序列之间存在均衡关系。
而均衡关系由两个值描述:协整系数以及均衡值。一旦确定这两个值,它们就可以用来构建两种股票的对数价格的线性组合,即所谓的价差。配对交易是对价差均值回归特性的押注。当我们确定利差已经偏离均衡值足够大时,我们就开始交易,押注价差将自行修正,价差将恢复平衡。所有如何定义“偏离均衡值”的量?
然我们看看交易策略的设计规则。如果价差的发展变化是已知的,那么我们就可以以适当的方式设计我们的交易信号。那么,我们对价差的发展变化了解多少?首先,我们可以期望它是高度均值回归的,因为这是我们最初选择配对的标准。为了便于论证,我们假设所有价差都是平稳的ARMA过程。ARMA过程本质上是均值回归的,因此不会违反我们对配对交易的基本要求。因此,价差至少是丰富的ARMA过程变体中的一种。
交易策略的设计规则中最主要的一条就是利润最大化。正确的选择可能会极大地改变利润状况。因此,有一个稳健的方法来设计交易规则是很重要的。此外,价差的发展变化具有广泛而多样的特点。在这种情况下,如果我们针对不同类型的价差采用不同的设计方法,这似乎是最合适的,不是吗?然而,情况并非如此。我们在这里提出了一种设计交易规则的方法,其主要特点是一刀切( one-size-fits-all) 。该方法可应用于所有价差,无论其发展变化如何,因此该方法非常有吸引力。
为白噪声划分价格带(band design for white noise)
当价差建模成白噪声时,我们的交易策略如何设计?价差交易的一般原则是在偏离均衡值时进行交易,并在恢复均衡时解除交易。然而实际应用中,具体的做法则有很多变化。
一方面,最一般的做法就是当价差偏离均衡值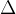 时,开始交易。当均值回归时清仓。另一方面,我们可以认为价差会在均衡值两边同样地震荡,当价差在均衡值相反方向偏离时解除交易。后一种做法减小了交易的频率(减少了一半a factor of two)。股票交易是有买卖价差(bid-ask spread)的,每次交易都会有交易下滑(trading splippage)。如果减少交易频率,则会减小这种下滑带来的影响。所以后一种做法虽然减小了交易频率,但也增加了持有时间。这也会导致mean drift,即不完美的协整性,信噪比SNR不佳。
时,开始交易。当均值回归时清仓。另一方面,我们可以认为价差会在均衡值两边同样地震荡,当价差在均衡值相反方向偏离时解除交易。后一种做法减小了交易的频率(减少了一半a factor of two)。股票交易是有买卖价差(bid-ask spread)的,每次交易都会有交易下滑(trading splippage)。如果减少交易频率,则会减小这种下滑带来的影响。所以后一种做法虽然减小了交易频率,但也增加了持有时间。这也会导致mean drift,即不完美的协整性,信噪比SNR不佳。
设计策略还要考虑持有的量(amount of inventory we are willing to hold on a spread)。一种极端做法是,我们每隔一个固定的时间观察价差,当发现有偏离均值情况出现,我们就开始交易,不管我们现在的持有量。另一种极端的做法是,我们规定只能持有1单位的价差,如果我们已经持有了1单位的价差,即使我们观察到有相同方向地偏离均值的情况,我们也不能追加持有量。然而,如果观察到有相反方向地偏离均值的情况,我们就要结束当前交易,并开始一个新的相反方向的交易。而实际的交易中的做法会在两种极端做法之间。
通常来说,不同的交易风格应该设计不同的交易策略。幸运的是,交易风格的细节跟决定能够实现利润最大化的之间没啥关系。让我们看看在价差是高斯白噪声的情况下,如何决定。
我们根据价差时序进行交易,当价差小于等于![]() 时,我们买入1份。当价差大于等于时,我们卖出1份。对于白噪声时序来说,在任意时间价差偏离量大于等于的概率是由高斯过程的积分决定,即
时,我们买入1份。当价差大于等于时,我们卖出1份。对于白噪声时序来说,在任意时间价差偏离量大于等于的概率是由高斯过程的积分决定,即![]() 。因为,在时间T内,我们期望有
。因为,在时间T内,我们期望有![]() 个实例比要大。类似的,价差偏离量小于等于
个实例比要大。类似的,价差偏离量小于等于![]() 的概率是
的概率是![]() 。由于高斯过程的对称性,
。由于高斯过程的对称性,![]() ,因此我们期望价差实例值小于等于
,因此我们期望价差实例值小于等于![]() 的数量也是等于
的数量也是等于![]() 。我们可以说,在T时间内,我们买卖价差的平均值是
。我们可以说,在T时间内,我们买卖价差的平均值是![]() 次。每次买卖的的收益是
次。每次买卖的的收益是![]() 。在时间T内的交易的收益是(每次交易的收益
。在时间T内的交易的收益是(每次交易的收益 交易的次数),即
交易的次数),即![]() 。
。
现在我们的问题变成了求一个使得![]() 最大的。如下图描述这个函数,x轴是值即关于平均值的正态密度的标准差,y轴式函数的值。最大值发生在
最大的。如下图描述这个函数,x轴是值即关于平均值的正态密度的标准差,y轴式函数的值。最大值发生在![]() ,这个值使得收益最大化。
,这个值使得收益最大化。
注意,其实这个设计方法也没有提到持有量如何设计的问题。只能作为一个设计指南参考。
价差的动态发展(Spread Dynamics)
有参数的价差建模是很复杂的。让我们来看几个例子。
1、价差建模为白噪声时序。白噪声时序是从高斯分布中抽样得到的,这个高斯分布在开盘和收盘时具有较高的标准差,而在midday则具有较低的标准差。(也就是说把价差白噪声时序当作是从时间变化,标准差/方差会改变的正态分布或者说高斯分布中抽样得形成得时序,这样更加realistic,而这就是高斯混合模型)。价差白噪声也具有GARCH性质。面对这种时序,如何处理?
解决方案可能是诉诸多个阈值水平,而不是一个,以最大程度地参与市场交易,无论是在高波动或低波动时。然后,我们需要估计高斯分布的成分(component),并为每个成分设计不同的阈值水平。另一种方法是使用卡尔曼滤波方法对波动率进行动态估计(dynamic estimation),并使阈值水平随时间变化。
2、价差建模为ARMA时间序列。
3、价差建模为Hidden Markov ARMA
现在就是带参数的模型,在现实使用中很复杂。实际上,只要我们能够提出合理的交易上下界限(band design),就不必一定要使用参数模型来建模。因此,我们也可以采用非参数方法,从价差样本或者说价差的历史数据中直接估计收益的分布函数。但是无参数的模型由于使用历史样本数据,会存在有偏差或者说过拟合的现象。
无参数的模型
需要大量的样本。所谓Ergodicity : A large sample size is effectively equivalent to having multiple realizations of the series of smaller sample sizes. Therefore, with large sample sizes for the spread, we can be reasonably confident that the effects of bias to the sample at hand have been
mitigated.大量样本使得样本带来的偏差影响可以忽略不计。
那没有大量的样本数据怎么办?也有方法估计收益函数的近似。为了让持怀疑态度的读者相信这种方法实际上产生了合理的结果,我们将把这种方法应用于白噪声情况。我们已经知道白噪声情况下利润的真正函数形式,因此也知道阈值的真正最优值。使用该方法估计的阈值现在可以与真实值进行比较,从而可以作为我们提出的非参数方法的验证。
我们设置几个阈值。注意,我们可以在从零到任何大正数的连续范围内的选择阈值。比如,我们选择两个比较接近的阈值。
接下来,我们能简单地计算价差超过特定阈值的次数。当阈值高于平均值时,这是价差大于阈值的次数。类似地,当阈值低于平均值时,这是价差低于阈值的次数。这种计数方法模仿了交易风格,每当我们观察到已经超过阈值时,我们就开始交易(put on a spread position),当我们达到平均值时,就平仓。如果我们假设价差的移动关于其长期平均值是对称的,那么我们可以通过对阈值的相同绝对值的正值和负值的频率计数进行平均来略微改进估计并减少偏差。
对于每个阈值,我们都可以得到这个计数值。这个计数可以与对应的阈值的收益值相乘获得原始的收益(raw profit)函数。如下图,就是通过简单地对穿过阈值(crosing)次数的计算获得收益的估计。这个例子中,价差时间序列是一个由75个数据点的白噪声。
 从计数获得的对收益的估计
从计数获得的对收益的估计
下图是根据某个特定的阈值对价差进行交易的收益,这个收益其实就是阈值本身。所以下图是一条斜率是1的直线。原始的收益是特定的阈值的收益乘以对应的计数获得的。

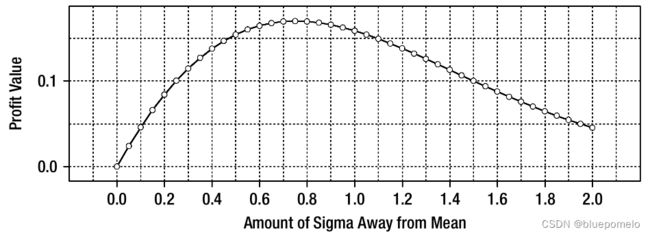
下图是由75个数据点的白噪声的原始收益。我们可以看到这个曲线是很多噪声以及锯齿状的。如果就这样使用原始曲线,那么将阈值放置在何处可能会相当难以理解。

现在我们解释为什么对收益的估计会这么多噪声。注意,我们使用很多离散的阈值,但是数据样本量很小。这样我们的计数函数(count funciton)是阶梯状(step function )的,实际上我们希望它是单调递减的。此外,需要注意的是,每当我们到一个阶梯(hit a step),收益是向上弯折的。我们把这称为离散效应(discretization effect)。为了获得单调递减的频率计数,我们需要校正这种离散化效应。我们可以通过在构成阶跃函数(step function)中两个级别的点之间执行简单的线性插值来校正离散化效果并确保函数单调递减。如下图:
 对原始计数进行调整使其单调递减
对原始计数进行调整使其单调递减
通过调整后,虽然计数已经单调递减了,但是仍然不平滑。这个时候我们需要正则化(regularization)去解决问题。经过正则化之后,得到的计数函数(count function)就可以用来计算收益概况(profit profile),并且最优阈值对应的最大收益值也可以得到了。
正则化
为了清楚起见,让我们重申一下问题。我们试图在给定一个样本的情况下估计穿过阈值的频率函数。这种涉及给定数据的函数估计的问题属于反问题理论(inverse problem theory)的一般主题领域(general subject area)。正则化是这一理论最基本的思想之一。正则化中最基本的思想涉及两种代价的估计。第一种代价衡量所计算的函数拟合数据的程度。第二种代价衡量与函数的已知性质(如平滑度)的偏差。在根据样本数据估计函数的过程中,这两种代价某种程度上是不一致的,或者说是有矛盾的。如果我们要非常拟合数据,那么就会损失平滑度。然而,如果我们需要函数很平滑,那么会牺牲函数对数据的拟合度。所以要在两种代价间找到平衡。
使用类似对数函数作为代价度量的方法通常称为最大熵方法(maximum enropy methods),简称MEM方法。如果代价度量是估计函数中相邻点之间的差的平方之和,则称为Tikhonov-Miller正则化。
所以,该选择哪种正则化的方法?也就是我们在正则化的代价衡量中希望捕获函数的什么属性?除了单调递减之外,我们希望函数是平滑的。我们可以使用Tikhonov-Miller正则化以保证结果的平滑。下面我们看看Tikhonov-Miller正则化。
给出一些数据点![]() 。其中
。其中 指阈值,
指阈值, 是阈值对应的计数。
是阈值对应的计数。![]() 是对
是对![]() 的估计函数值,那么代价函数是:
的估计函数值,那么代价函数是:

这个代价函数的第一部分是最小二乘法代价衡量,第二部分是曲线粗糙程度的惩罚。 是一个权衡因素,它衡量了我们愿意为将平滑度成本降低一个单位付出多少的拟合误差。Tikhonov-Miller正则化的问题就是求得以最小化以上代价函数。
是一个权衡因素,它衡量了我们愿意为将平滑度成本降低一个单位付出多少的拟合误差。Tikhonov-Miller正则化的问题就是求得以最小化以上代价函数。
让我们考虑我们生成的模拟白噪声样本。我们设计阈值,并对价差超过阈值的次数进行计数。本例中的计数表示为分数,通过将其除以采样点总数获得。然后我们构造与这些计数相对应的成本函数。严格地说,需要通过将计数分数锚定在0.5来对成本函数执行约束最小化。这是因为假设价差关于其平均值的的对称性;即高于和低于平均值的总计数分数可能为0.5。然而,我们在这里只做无约束的版本。
然后使用的各种值最小化刚刚展示的代价函数,以获得计数分数函数(count fraction function)的估计。拟合误差与取对数的关系图如下图:

我们会选择曲线跟部(the heel of the curve)的,因为如果取跟部的左边的,代价函数会偏向于拟合的误差,取跟部的右边的则代价函数会偏向于平滑问题。
这个值对应的调整之后的计数函数如图:
 计数正则化之后
计数正则化之后
获得正则化后的曲线,我们可以得到收益概况如下图:
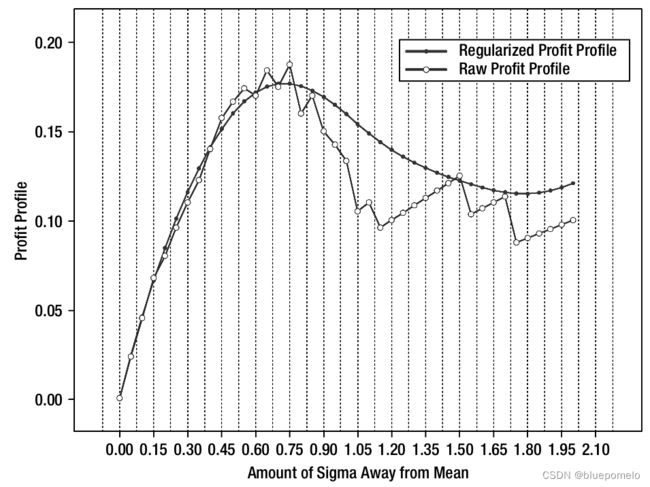 收益概况估计
收益概况估计
我们可以看到,收益最大是在0.75乘以标准差的地方,这也是理论值所在,验证了我们的方法。