RDD(python
RDD创建
从文件系统加载
.textFile()
- 支持本地文件系统
- 分布式文件系统HDFS
- 云端文件
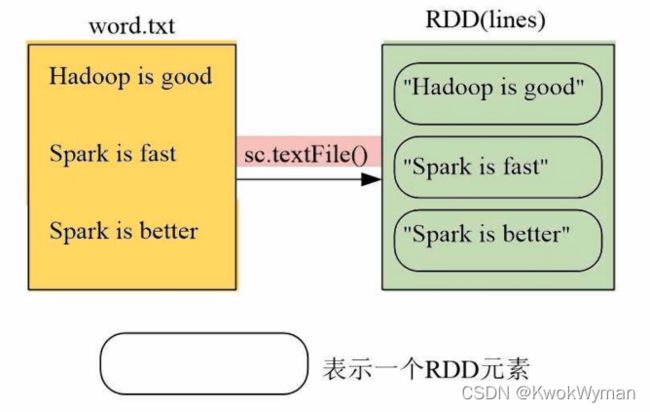
>>lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
>>lines.foreach(print)
Hadoop is good
Spark is fast
Spark is better
sc : spark context
textFile效果
分布式文件系统

通过并行集合(数组)创建RDD
.Parallelize()
>>>array = [1,2,3,4,5]
>>>rdd = sc.parallelize(array)
>>>rdd.foreach(print)
1
2
3
4
5

RDD操作
转换:并不会发生正在的计算,只是记录下这个操作,最后再输出。
- filter
- map
- flatMap

针对spark 的一次次转换操作
- filter:筛选
>>>lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
>>>linesWithSpark = lines.fliter(lambda line : "Spark" in line)//判断"spark"在不在里面
>>>linesWithSpark.foreach(print)
Spark is better
spark is fast

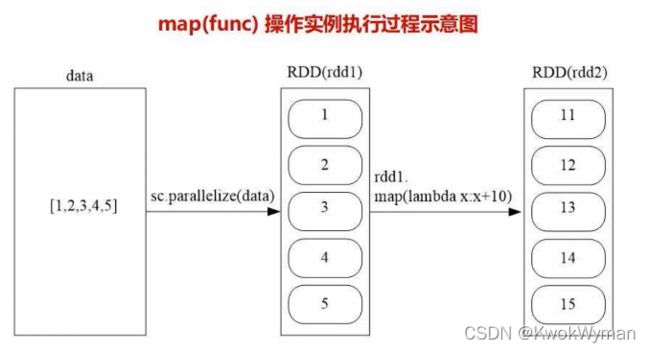
- map:一一对应
>>>data = [1,2,3,4,5]
>>>rdd1 = sc.parallelize(data)
>>>rdd2 = rdd1.map(lambda x:x+10)
>>>rdd2.foreach(print)
11
12
13
14
15
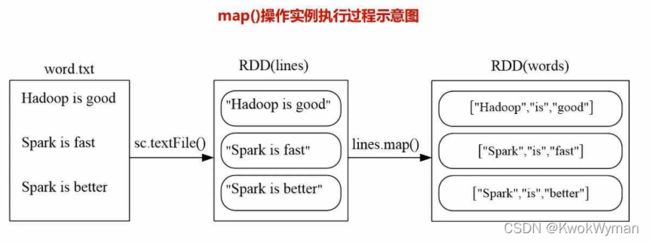
>>>lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
>>>words = lines.map(lambda line:line.split(" "))//分拆
>>>words.foreach(print)
['Hadoop','is','good']
['spark','is','fast']
['spark','is','better']
- flatMap : 得到每个单词(词频统计)
>>>lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
>>>words = lines.flatMap(lambda line:line.split(" "))

-
groupByKey:相同值的元素归到一起


-
reduceByKey



动作: -
count:返回元素个数
-
collect:以数组形式返回所有元素
-
first:返回第一个元素
-
take(n):以数组形式返回前n个元素
-
reduce(func):通过函数func(输入两个参数返回一个值)聚合数据集中的元素
-
foreach(func):将每个元素传到func中

持久化:用persist()方法标记一个RDD为持久化,保存在内存中方便重复使用
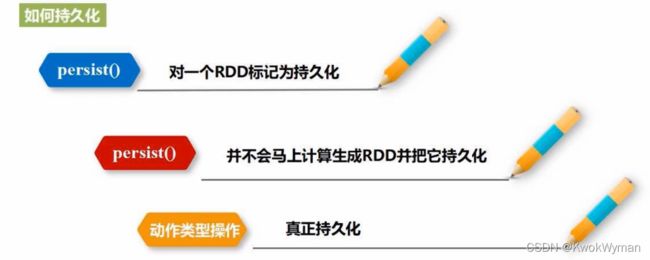
- MEMORY_ONLY = cache:内存不足,替换内容
- MEMORY_AND_DISK:内存不足,存放磁盘
unpersist:从缓存中移除持久化的RDD

分区
- 增加并行度
- 减少通信开销
分区原则

设置分区

>>>list = [1,2,3,4,5]
>>>rdd = sc.parallelize(list,2)//设置两个分区
repartition重新设置分区个数
>>>data = sc.parallelize([1,2,3,4,5],2)
>>>len(data.glom().collect())//显示分区数量
>>>rdd = data.repartition(1)//对data这个RDD重新分区
>>>len(rdd.glom().collect())//显示分区数量
自定义分区

from pyspark import SparkConf,SparkContext
//分区函数
def MyPartitioner(key):
print("MyPartitoner is running")
print('The key is %d'%key)
return key%10
def main():
print("main is running")
conf = SparkCaonf().setMaster("local`").set AppName("MyApp")
sc = SparkContext(conf = conf)
data = sc.paeallelize(range()10,5)
data.map(lambda x:(x,1)).partitionBy(10.MyPartitioner)//只接受键值对类型.map(lambda x:x[0])//取出数值.saveAsTextFile(".../rdd/partitioner")
if__name__ == '__main__':
main()


键值对RDD(pair RDD)
生成

通过并行集合生成

键值对RDD转换
- reduceByKey(func)
- groupByKey()

- keys:把键值对RDD中的key返回成一个新的RDD

- values:取出value返回成RDD
- sortByKey:根据key排序(默认升序,true)

sortBy:可根据具体的值进行排序 - mapValues(func)

- join:内连接


综合实例:key——图书名称,value——销量,计算每种图书每天的平均销量
